




 本文聚焦于使用TensorFlow和Keras构建U-Net架构。先介绍U-Net架构及其组件,接着阐述构建U-Net的步骤,包括配置定义、构建模块等,还涉及训练流程,如初始化模型、加载数据集、数据预处理等,最后提到可通过预训练提高模型性能。
本文聚焦于使用TensorFlow和Keras构建U-Net架构。先介绍U-Net架构及其组件,接着阐述构建U-Net的步骤,包括配置定义、构建模块等,还涉及训练流程,如初始化模型、加载数据集、数据预处理等,最后提到可通过预训练提高模型性能。
原文地址:building-a-u-net-with-tensorflow-and-keras
2024 年 4 月 11 日
计算机视觉有几个子学科,图像分割就是其中之一。如果您要分割图像,则需要在像素级别决定图像中可见的内容(执行分类时),或者从像素级别的图像中推断相关的实值信息(执行回归时)。
图像分割社区中最著名的架构之一是U-Net。全卷积架构以其形状命名,首先收缩图像,然后扩展为结果。虽然此收缩路径构建了学习特征的层次结构,但跳跃连接有助于将这些特征转换回扩展路径中的相关模型输出。
虽然您可以通过单击此链接了解有关 U-net 架构的更多信息,但本文重点介绍实际实现。我们将学习从头开始构建U-Net架构。将使用 TensorFlow 和 Keras 来完成此操作。首先,我们将简要介绍 U-Net 的高层组件。接下来是实施 U-Net 的分步教程。最后,我们将从头开始在 Oxford-IIIT Pet 数据集上训练网络,展示可以实现的目标以及如何进一步改进。
所以,读完本教程后,您将了解:
- U-Net 架构是什么以及它的组件是什么。
- 如何使用 TensorFlow 和 Keras 自行构建 U-Net。
- 通过实施您可以实现哪些绩效以及如何进一步改进。
什么是 U-网络?
当你向计算机视觉工程师询问图像分割问题时,很可能会在他们的解释中提到 U-Net 这个术语。U-Net 因其形状而得名,是一种卷积架构,最初由 Ronneberger 等人(2015 年)提出,用于生物医学领域。更具体地说,它用于细胞分割,与该领域以前使用的方法相比,效果非常好。
U-Net 由三个组件组组成:
- 收缩路径。在下图左侧可以看到,卷积层和池化层用于对图像进行缩样,有时甚至可以将图像缩小一半。收缩路径学习不同粒度的特征层次。
- 扩展路径在右侧,你会看到一组上采样层(无论是简单的插值层还是转置卷积层),它们会对输入图像的分辨率进行上采样。换句话说,网络会尝试从缩小的输入构建更高分辨率的输出。
- 跳过连接 除了将低层特征图作为上采样过程的输入外,U-Net 还接收来自收缩路径同层的信息。这样做是为了缓解 U 网最底层的信息瓶颈,如果不通过跳转连接使用,就可以有效地 "丢弃 "来自高层特征的信号。
请注意,在最初的 U-Net 架构中,输出的宽度和高度低于输入的宽度和高度(572x572 像素对 388x388 像素)。这种情况源于架构,可以通过使用其他默认架构(如 ResNet)作为主干架构来避免。
有了 U-Net 这样的架构,就可以学习对特定图像重要的特征,同时利用这些信息生成更高分辨率的输出。代表像素级类别索引的地图就是这样的输出。通过进一步阅读,你将学会如何构建 U-Net!
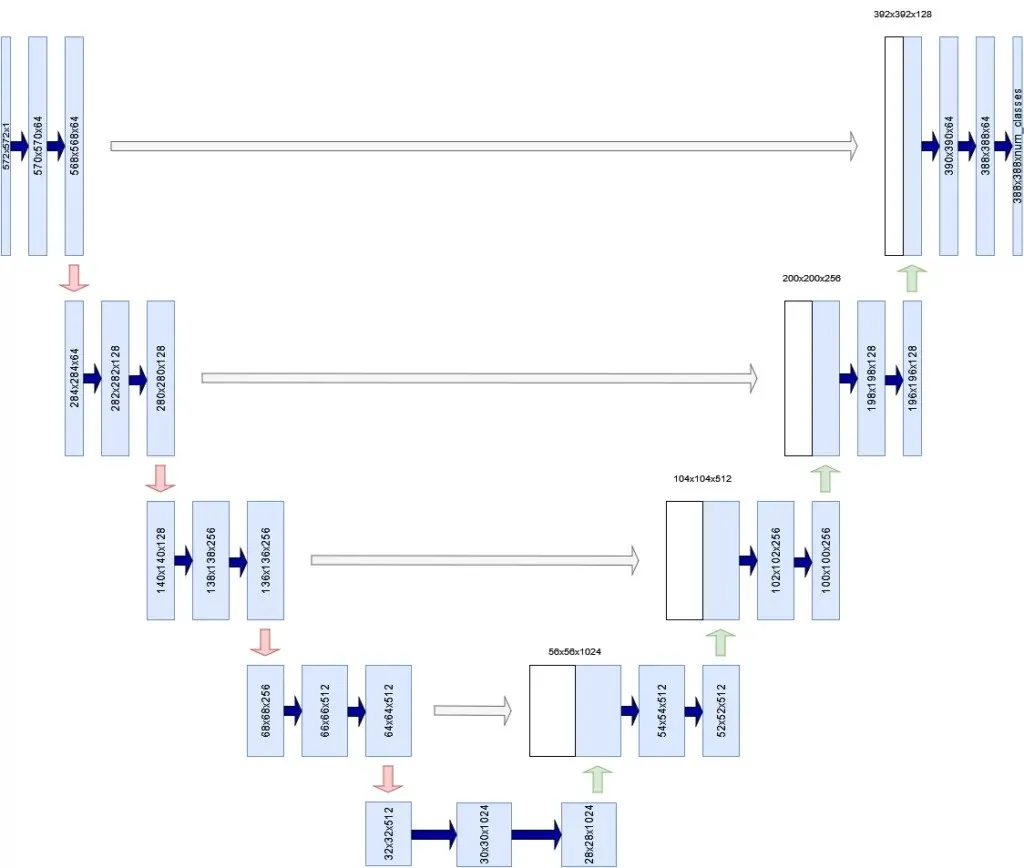
使用 Tensorflow 和 Keras 构建 U-Net
现在,你已经了解了 U-Net 的高级工作原理,是时候构建一个了。打开集成开发环境,创建一个 Python 文件(如 unet.py)或打开一个 Jupyter Notebook。同时确保已经安装了接下来的先决条件。然后我们就可以开始编写代码了!
先决条件
要运行代码,你必须在环境中安装一些依赖项。
首先,你需要最新版本的 Python 3.x。
此外,你还需要 tensorflow 和 matplotlib。这些都可以通过 pip 包管理器安装。安装完成后,你就可以开始使用了!
导入
import os
import tensorflow
from tensorflow.keras.layers import Conv2D,\
MaxPool2D, Conv2DTranspose, Input, Activation,\
Concatenate, CenterCrop
from tensorflow.keras import Model
from tensorflow.keras.initializers import HeNormal
from tensorflow.keras.optimizers import schedules, Adam
from tensorflow.keras.losses import SparseCategoricalCrossentropy
from tensorflow.keras.callbacks import TensorBoard
from tensorflow.keras.utils import plot_model
import tensorflow_datasets as tfds
import matplotlib.pyplot as pltU-Net 配置定义
在我看来,将各种配置选项分散在整个模型中是一种糟糕的做法。相反,我更喜欢将它们定义在一个定义中,这样我就可以在整个模型中重复使用它们(如果我需要将模型部署到生产环境中,我可以通过一个 JSON 环境变量提供我的配置,该变量可以很容易地作为 dict 读入 Python)。下面就是配置定义的样子。下面,我们将讨论组件:
'''
U-NET CONFIGURATION
'''
def configuration():
''' Get configuration. '''
return dict(
data_train_prc = 80,
data_val_prc = 90,
data_test_prc = 100,
num_filters_start = 64,
num_unet_blocks = 3,
num_filters_end = 3,
input_width = 100,
input_height = 100,
mask_width = 60,
mask_height = 60,
input_dim = 3,
optimizer = Adam,
loss = SparseCategoricalCrossentropy,
initializer = HeNormal(),
batch_size = 50,
buffer_size = 50,
num_epochs = 50,
metrics = ['accuracy'],
dataset_path = os.path.join(os.getcwd(), 'data'),
class_weights = tensorflow.constant([1.0, 1.0, 2.0]),
validation_sub_splits = 5,
lr_schedule_percentages = [0.2, 0.5, 0.8],
lr_schedule_values = [3e-4, 1e-4, 1e-5, 1e-6],
lr_schedule_class = schedules.PiecewiseConstantDecay
)- 回想一下,数据集必须分成训练集、验证集和测试集。训练集是最大的也是最主要的数据集,可以让你在训练过程中进行前后传递和优化。但是,由于你已经看过这个数据集,因此在训练过程中会使用验证集来评估每个历时后的性能。最后,由于模型最终也可能在验证集上过拟合,因此还有一个测试集,但在训练过程中根本不会使用。相反,测试集用于模型评估,以确定模型是否能在未见过的数据上表现良好。如果能做到这一点,那么它也更有可能在现实世界中发挥作用。
- 在模型配置中,data_train_prc、data_val_prc 和 data_test_prc 用于表示特定分割结束的百分比。在上面的配置中,80、90 和 100 表示 0-80% 的数据集将用于训练,80-90%(即总共 10%)用于验证,90-100%(也是 10%)用于测试。稍后你会发现,以这种方式指定数据集是很有好处的,因为 tfds.load 允许我们重新组合两个数据集(训练/测试),并将它们分成三个!
- 第一个 U-net 卷积块生成的特征图数量为 64。你的网络将总共由 3 个 U-Net 块组成(上面的草图有 5
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 842
842

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









