







MySQL 调优
性能优化其实可以从多个角度出发考虑,如 架构优化、前端调优、中间件调优、网关调优、容器调优、JVM调优、接口调优、服务器调优、数据库调优.... 等,从优化类型上而言,主体可以分为三类:
-
• ①结构/架构优化:优化应用系统整体架构做到性能提升的目的。如:读写分离、集群热备、分布式架构、引入缓存/消息/搜索中间件、分库分表、中台架构(大数据中台、基础设施中台)等。
-
• ②配置/参数优化:调整应用系统中各层面的配置文件、启动参数达到优化性能的目标。如:JVM、服务器、数据库、操作系统、中间件、容器、网关参数调整等。
-
• ③代码/操作优化:开发者编写程序时,从代码、操作方面进行调节,达到效率更高的初衷。如:代码中使用更优秀的算法思想/设计模式、SQL优化、对中间件的操作优化等。
当
MySQL出现了性能瓶颈时,就算Java程序没出现瓶颈,也会因此受到限制,这也是著名的木桶效应:一个木桶能装多少水,完全取决于木桶中最短的那块木板。
一、系统中性能优化的核心思维
性能调优与线上排查问题一样,是建立在经验的基础之上才能做好的,对于调优要实事求是,任何的调优手段或技巧不要纸上谈兵,只有经过实践的才能用于生产环境,千万不要将一些没有实际依据的调优策略用于线上环境,否则可能会导致原本好好运行的应用程序,反而由于调优被调到崩溃。
1.1、单个节点层面调优的核心思想
在一个程序中,所有的业务执行实体都为线程,应用程序的性能跟线程是直接挂钩的。而程序中的一条线程必须要经过CPU的调度才可执行,线程执行时必然也会需要数据、产生数据,最终也会和内存、磁盘打交道。因而单个节点的性能表现,不可避免的会跟CPU、内存、磁盘沾上关系。
线程越多,需要的CPU调度能力也就越强,需要的内存也越大,磁盘IO速率也会要求越快。因此CPU、内存、磁盘,这三者之间的任意之一达到了瓶颈,程序中的线程数量也会达到极限。达到极限后,系统的性能会成抛物线式下滑,从而可能导致系统整体性能下降乃至瘫痪。
由于如上原因,在考虑性能优化时,必然不能让
CPU、内存、磁盘等资源的使用率达到95%+,一般而言,最大利用率控制在80-85%左右的最佳状态。
同时,由于程序的性能跟线程挂钩,所以线程工作模型也是影响性能的重要因素。目前程序设计中主要存在三种线程处理模型:BIO、NIO、AIO(NIO2),BIO是最传统的一对一处理模型,也就是一个客户端请求分配一条线程处理。NIO的最佳实践为reactor模型,而proactor模型又作为了NIO2/AIO的落地者。绝大部分情况下,AIO的性能优于NIO,而NIO的性能又远超于BIO。
所以在做性能优化时,你应该要清楚系统的性能瓶颈在哪儿,到底是要调哪个位置?是线程模型?或是
CPU调度?还是内存回收?亦是磁盘IO速率?针对不同层面有不同的优化方案,并非为了追求“热词/潮流”而盲目的调优。
1.2、优秀且适用的系统架构胜过千万次调优
一个单体架构(Tomcat+MySQL)部署的系统遇到性能问题时,能力再强,本事再大,任凭使出浑身解数也无法将其调到处理万级并发的程序,正常服务器部署的一台MySQL服务做到极致调优也难以在一秒内承载5000+的QPS。一味的追求极致的优化,其实也难以解决真正大流量下的并发冲击,因此一套优秀的系统架构胜过自己千万次的调优。
当然,也并非说项目实现时,越多的技术加进来越好,一套完善的分布式架构就必然比单体架构要好吗?其实也不见得,因为当引入的技术越多,所需要考虑的问题也会更多,耗费的成本也会越高,一个项目收益60W,结果用上最好的配置(高端的开发者+顶级的服务器+完善的分布式架构)成本耗费200W,这值得吗?答案显而易见。因此,并没有最好的技术架构,只有最适用的架构,能从现有环境及实际业务出发,选用最为合适的技术体系,这才是我们应该做的事情。如:
-
• 项目业务中读写参半,单节点难以承载压力,项目集群、双主热备值得参考。
-
• 项目业务中写大于读,引入消息中间件、
DB分库、项目集群也可以考虑。 -
• 项目业务中读大于写,引入缓存/搜索中间件、动静分离、读写分离是些不错的选择。
当你的系统原有架构遇到性能瓶颈时,你甚至可以考虑进一步做架构优化,如:设计多级分布式缓存、缓存中间件做集群、消息中间件做集群、
Java程序做集群、数据库做分库分表、搜索中间件做集群.....,慢慢的,你的系统会越来越庞大复杂,需要处理的问题也更为棘手,但带来的效果也显而易见,随着系统的结构不断变化,承载百万级、千万级、亿级、乃至更大级别的流量也并非难事。
但只有当你的业务流量/访问压力在选用其他架构无法承载时,你才应该考虑更为庞大的架构。当然,如果项目在起步初期就有预估会承载巨大的流量压力,那么提前考虑也很在理,采用分布式/微服务架构也并非失策,因为对比其他架构体系而言,微服务架构的拓展性更为灵活。但也需要记住:分布式/微服务体系是很好,但它不一定适用于你的项目。
1.3、预防大于一切,调优并非“临时抱佛脚”
当问题出现时再想办法解决,这种策略永远都属于下下策,防范于未然才是最佳方案,提前防范问题出现主要可分为两个阶段:
-
• ①项目初期预测未来的流量压力,提前根据业务设计出合适的架构,确保上线后可以承载业务的正常增长。
-
• ②项目上线后,配备完善的监控系统,在性能瓶颈来临前设好警报线,确保能够在真正的性能瓶颈到来之前解决问题。
对于项目初期的架构思考,值得牢记的一点是:不要“卡点”设计,也不能过度设计造成性能过剩,举例:
项目上线后的正常情况下,流量大概在“一木桶”左右,结果你设计时直接整出一个承载“池塘”级别的流量结构,这显然是不合理的,毕竟架构体系越庞大,项目的成本也自然就越高。当然,也不能说正常情况下压力在“一木桶”左右,就只设计出一套仅能够承载“一木桶”流量的结构,这种“卡点”设计的策略也不可取,因为你需要适当考虑业务增长带来的风险,如果“卡点”设计,那么很容易让项目上线后,短期内就遭遇性能瓶颈。因此,如果项目正常的访问压力大概在“桶”级别,那将结构设计到“缸”级别最合理,这样即不必担心过度设计带来的性能过剩,导致成本增高,也无需考虑卡点设计造成的:项目短期遭遇性能瓶颈。但设计时的这个度,必须由你自己根据项目的业务场景和环境去思量,不存在千篇一律的方法可教。
有人曾说过:“如果你可以根据业务情景设计出一套能确保业务增长,且在线上能稳定运行三年时间以上的结构,那你就是位业内的顶尖架构”,但老话说的好:“计划永远赶不上变化”,就算思考到业务的每个细节,也不可能设计出一套一劳永逸的结构出现,我们永远无法判断意外和明天哪个先来。因而,项目上线后,配备完善的监控警报系统也是必不可少的。不过值得注意的是:
监控系统的作用并不是用来提醒你项目“game over”了的,而是用来提醒你:线上部署的应用系统可能会“game over”或快“game over”了,毕竟当项目灾难已经发生时再给警报,那到时候的情况就是:“亡羊补牢,为时已晚”。
通常情况下,在监控系统上面设置的性能阈值都会比最大极限值要低5~15%,如:最大极限值是85%,那设置告警值一般是75%左右就会告警,不会真达到85%才告警,只有这样做才能留有足够的时间让运维和开发人员介入排查。当系统发出可能“game over”的警告时,开发和运维人员就应当立即排查相关的故障隐患,然后再通过不断的修改和优化,提前将可能会出现的性能瓶颈解决,这才是性能调优的正确方案。
因此,最终结论为:绝不能等到系统奔溃才去优化,预防胜于一切。
1.4、无需追求完美,理性权衡利弊
“追求极致,做到完美”这点是大部分开发者的通病,很多人会因为这个思想导致自己在面临一些问题时束手无策,比如举个例子:
业务:
MacBookPro一元购活动,预计访问压力:10000QPS。
环境:单台机器只能承载2000QPS,目前机房中还剩余两台空闲服务器。
状况:此时就算将空闲的两台机器加上去,也无法顶住目前的访问压力。
此时你会怎么做?很多人都会茫然、会束手无策,这看起来好像是没办法的事情呀.....
但事实真的如此吗?并非如此,其实这种情况也有多种解决方案,如:
-
• ①停掉系统中部分非核心的业务,将服务器资源暂时让给该业务。
-
• ②抛弃掉部分用户的请求,只接受处理部分用户的请求,对于抛弃的用户请求直接返回信息提示。
这些方案是不是可以解决上面的哪个问题呢?答案是肯定的,所以适当舍弃一部分是这种场景下最佳方案,千万不能抱有追求完美的想法,例如:
-
• 系统中的服务不能停啊,得保持正常服务啊,否则影响程序功能的完善性。
-
• 用户的请求怎么能抛,用户的访问必须得响应啊,否则影响用户体验感。
但事实告诉你的是:类似于京东、淘宝、12306等这些国内的顶级门户网站,在处理高并发场景时照样如此。好比阿里,在双十一的时候都会抽调很多冷门业务的服务器资源给淘宝使用,也包括你在参与这些电商平台的抢购或秒杀类活动时,你是否遇到过如下情况:
-
• 服务器繁忙,请稍后重试......
-
• 服务器已满,排队中.....
-
• 前方拥堵,排队中,当前第
x位.....
如果当你遇到了这些情况,答案显而易见,你的请求压根就没有到后端,在前端就给你
pass了,然后给你返回了一个字符串,让你傻傻的等待,实则你的请求早就被抛弃了.....
这个例子要告诉大家的是:在处理棘手问题或优化性能时,无需刻意追求完美,理性权衡利弊后,适当的做出一些决断,抛弃掉一部分不重要的,起码比整个系统挂掉要好,何况之后也同样可以恢复。
1.5、性能调优的通核心步骤
性能优化永远是建立在性能瓶颈之上的,如果你的系统没有出现瓶颈,那则无需调优,调优之前需要牢记的一点是:不要为了调优而调优,而是需要调优时才调。
而发现性能瓶颈的方式有两种,一种是你的应用中具备完善的监控系统,能够提前感知性能瓶颈的出现。另一种则是:应用中没有搭载监控系统,性能瓶颈已经发生,从而导致应用频繁宕机。大型的系统一般都会搭载完善的监控系统,但大多数中小型项目却不具备该条件,因此,大部分中小型项目发现性能瓶颈时,大多数情况下已经“game over”了。
通常而言,性能优化的步骤可分为如下几步:
-
• ①发现性能瓶颈:如有监控系统,那它会主动发出警报;如若没有,那出现瓶颈时应用肯定会出问题,如:无响应、响应缓慢、频繁宕机等。
-
• ②排查瓶颈原因:排查瓶颈是由于故障问题导致的,还是真的存在性能瓶颈。
-
• ③定位瓶颈位置:往往一个系统都会由多个层面协同工作,然后对外提供服务,当发现性能瓶颈时,应当确定瓶颈的范围,如:网络带宽瓶颈、Java应用瓶颈、数据库瓶颈等。
-
• ④解决性能瓶颈:定位到具体的瓶颈后对症下药,从结构、配置、操作等方面出发,着手解决瓶颈问题。
单层面的性能调优其实只能当成锦上添花的作用,但绝对不能成为系统性能高/低、响应快/慢、吞吐量大/小的决定性要素。应用系统的性能本身就还算可以,那么调优的作用是让其性能更佳。但如若项目结构本身就存在问题,那么能够带来的性能提升也是有限的。
二、MySQL的性能优化实践
2.1、MySQL调优的五个维度
聊到MySQL的性能优化,其实也可以从多个维度出发,共计优化项如下:
-
• ①客户端与连接层的优化:调整客户端
DB连接池的参数和DB连接层的参数。 -
• ②
MySQL结构的优化:合理的设计库表结构,表中字段根据业务选择合适的数据类型、索引。 -
• ③
MySQL参数优化:调整参数的默认值,根据业务将各类参数调整到合适的大小。 -
• ④整体架构优化:引入中间件减轻数据库压力,优化
MySQL架构提高可用性。 -
• ⑤编码层优化:根据库表结构、索引结构优化业务
SQL语句,提高索引命中率。
纵观现在MySQL中的各类优化手段,基本上都是围绕着上述的五个维度展开,这五个性能优化项中,通常情况下,带来的性能收益排序为④ > ② > ⑤ > ③ > ①,不过带来的性能收益越大,也就意味着成本会更高,因此大家在调优时,一定要记得按需进行,不要过度调优,否则也会带来额外的成本开销!
2.2、MySQL连接层优化策略
一个用户请求最终会在Java程序中分配一条线程处理,最终会变成一条SQL发往MySQL执行,而Java程序、MySQL-Server之间是通过建立网络连接的方式进行通信,这些连接在MySQL中被称为数据库连接,本质上在MySQL内部也是一条条工作线程负责执行SQL语句,那么思考一个问题:数据库连接数是越大越好吗?
对于这个问题,答案是
NO,这是为什么呢?既然说一个客户端连接是一条线程,那数据库的最大连接数调整到1W,岂不是代表着同时可以支持1W个客户端同时操作啦?在不考虑硬件的情况下确实如此,但结合硬件来看待,答案就不相同的,一起来聊聊原因。
数据库连接数越大,也就意味着内部创建出的工作线程会越多,线程越多代表需要的CPU配置得更高,比如现在有300个客户端连接,内部创建了300条工作线程处理,但服务器的CPU仅有32个核心,那当前服务器最多只能支持32条线程同时工作,那其他268条线程怎么办呢?为了其他线程能够正常执行,CPU就会以时间片调度的模式工作,不同核心在不同线程间反复切换执行,但由于线程数远超核心数,因此会导致线程上下文切换的开销,远大于线程执行的开销。
正是由于上述原因,所以数据库的连接数该设置成多少合适呢?这就是一个值得探讨的问题,而连接池又会分为客户端连接池、服务端连接池,客户端连接池是指
Java自身维护的数据库连接对象,如C3P0、DBCP、Druid、HikariCP...等连接池。服务端连接池是指MySQL-Server的连接层中,自身维护的一个连接池,用来实现线程复用的目的。
对于MySQL连接池的最大连接数,这点无需咱们关心,重点调整的是客户端连接池的连接数,为啥呢?因为MySQL实例一般情况下只为单个项目提供服务,你把应用程序那边的连接数做了限制,自然也就限制了服务端的连接数。但为啥不将MySQL的最大连接数和客户端连接池的最大连接数保持一致呢?这是由于有可能你的数据库实例不仅仅只为单个项目提供服务,比如你有时候会通过终端工具远程连接MySQL,如果你将两个连接池的连接数保持一致,就很有可能导致MySQL连接数爆满,最终造成终端无法连上MySQL。
客户端的连接池大小该如何设置呢?先来借鉴一下
PostgreSQL提供的计算公式:
最大连接数 = (CPU核心数 * 2) + 有效磁盘数
这个公式其实不仅仅只适用于PostgreSQL,在MySQL、Oracle...中同样适用,但公式中有一点比较令人产生疑惑,即“有效磁盘数”,这是个啥?其实是指SSD固态硬盘,如果部署数据库的服务器,其硬盘是SSD类型,那么在发生磁盘IO基本上不会产生阻塞。因为SSD相较于传统的机械硬盘,它并没有的磁片,无需经过旋转磁面的方式寻址,所以SSD硬盘的情况下,可以再+1。
比如目前服务器的硬件配置为CPU:16core、硬盘类型:SSD,此时最佳的最大连接数则为16*2+1=33,而常驻连接数可以调整到30左右,这组配置绝对是当前场景下的最佳配置,如若再调大连接数,这反而会让性能更慢,因为会造成线程上下文切换的额外开销。
但是要注意:
C3P0、DBCP、Druid、HikariCP...等连接池的底层本质上是一个线程池,对于线程池而言,想要处理足够高的并发,那应该再配备一个较大的等待队列,也就是当目前池中无可用连接时,其他的用户请求/待执行的SQL语句则会加入队列中阻塞等待。
当然,上述这个公式虽说能够应对绝大部分情况,但实际业务中,还需要考虑SQL的执行时长,比如一类业务的SQL执行只需10ms,而另一类SQL由于业务过为繁琐,每次调用时会产生一个大事务,一次执行下来可能需要5s+,那这两种情况都采用相同的连接池可以吗?可以是可以,但大事务会影响其他正常的SQL,因此想要完美的解决这类问题,最好再单独开一个连接池,为大事务或执行耗时较长的SQL提供服务。
2.2.1、偶发高峰类业务的连接数配置
啥叫偶发高峰类业务呢?就类似于滴滴打车这类业务,在早晚上下班时间段、周末假期时间段,其流量显然会比平常高很多,对于这类业务,常驻线程数不适合太多,因为并发来临时会导致创建大量连接,而并发过后一直保持数据库连接会导致资源被占用,所以对于类似的业务,可以将最大连接数按之前的公式配置,而常驻连接数则可以配成CPU核数+1,同时缩短连接的存活时间,及时释放空闲的数据库连接,以此确保资源的合理分配。
2.2.2、分库分表情况下的连接数配置
对于读写分离、双主双写、分库分表的情况下,就不适合这样配置,毕竟部署了多个MySQL节点,也就意味着拥有多台服务器的硬件资源,因此在数据库部署了多节点的情况下,请记得根据每个节点的硬件配置,来规划出合理的连接数。
2.2.3、连接层调优小结
对于连接层的调优,实际上是指调整它的参数,即常驻连接数、最大连接数、空闲连接存活时间以及等待队列的容量,在这里聊到过一点:合理的连接数才是最好的,而并非越大越好
线程上下文切换的开销,一颗CPU核心在2~3条线程之间切换不会存在太大的开销,但在十多条线程之间切换,则会导致切换开销远超出线程执行本身的开销。
如若部署
MySQL的服务器硬件配置更高,那也可以手动将MySQL默认的最大连接数调大,set max_connections = n;即可。
最后提一嘴:对于最佳连接数的计算,首先要把CPU核数放首位考虑,紧接着是磁盘,最后是网络带宽,因为带宽会影响SQL执行时间,综合考虑后才能计算出最合适的连接数大小。
2.3、MySQL结构的优化方案
MySQL结构优化,主要是指三方面,即表结构、字段结构以及索引结构。
2.3.1、表结构的优化
①表结构设计时的第一条也是最重要的一条,字段数量一定不要太多,之前我手里有个老项目要做二开,里面30~40个字段的表比比皆是,更有甚者达到了60~70个字段一张表,这种方式显然并不合理。InnoDB引擎基本上都会将数据操作放到内存中完成,而当一张表的字段数量越多,那么能载入内存的数据页会越少,当操作时数据不在内存,又不得不去磁盘中读取数据,这显然会很大程度上影响MySQL性能。
咱们思考一个问题:一张
40~50个字段的表结构,在实际业务中会使用到它每个字段吗?答案是No,一张40~50个字段的表中,常用的字段最多只有10~20个,这类字段可以理解成热点字段,而其他的字段都属于冷字段,但由于你将所有字段都设计到了一张表中,因此就会导致载入内存时,会将一整条数据全部载入,对应的冷字段会造成额外的额外的内存浪费。
因此对于表结构的设计,正常情况下应当遵循《数据库三范式》的原则设计,尽可能的根据业务将表结构拆分的更为精细化,一方面能够确保内存中缓存的数据更多,同时也更便于维护,而且执行SQL时,效率也会越高。
一张表最多最多只能允许设计
30个字段左右,否则会导致查询时的性能明显下降。
②当然,也并不是说一定要遵守三范式的设计原则,有时候经常做连表查询的字段,可以适当的在一张表中冗余几个字段,这种做法的最大好处是能够减少连表查询次数,用空间换时间的思想。但也并非是无脑做冗余,否则又会回到前面的情况,一张表中存在大量的无用字段,这里的冗余是指经常连表查询的字段。
③主键的选择一定要合适。首先一张表中必须要有主键,其次主键最好是顺序递增的数值类型,最好为int类型。一张表如果业务中自带自增属性的字段,最好选择这些字段作为主键,例如学生表中的学号、职工表中的工号....,如果一张表的业务中不带有这类字段,那也可以设计一个与业务无关、无意义的数值序列字段作为主键,因为这样做最适合维护表数据(跟聚簇索引有关)。
只有当迫不得已的情况下,再考虑使用其他类型的字段作为主键,但也至少需要保持递增性,比如分布式系统中的分布式
ID,这种情况下就无法依靠数据库int自增去确保唯一性,就必须得通过雪花算法这类的ID生成策略,以此来确保ID在全局的唯一性。
④对于实时性要求不高的数据建立中间表。很多时候咱们为了统计一些数据时,通常情况下都会基于多表做联查,以此来确保得到统计所需的数据,但如若对于实时性的要求没那么高,就可以在库中建立相应的中间表,然后每日定期更新中间表的数据,从而达到减小连表查询的开销,同时也能进一步提升查询速度。
适当的场景下建立中间表,是一种能够带来不小性能收益的手段。
⑤根据业务特性为每张不同的表选择合适的存储引擎。其实存储引擎这块主要是在InnoDB、MyISAM两者之间做抉择,对于一些经常查询,很少发生变更的表,就可以选择MyISAM引擎,比如字典表、标签表、权限表....,因为读远大于写的表中,MyISAM性能表现会更佳,其他的表则可以使用默认的InnoDB引擎。
2.3.2、字段结构的优化
字段结构的优化其实主要指选择合适的数据类型,大多数开发在设计表字段结构时,如果要使用数值类型一般会选择int,使用字符串类型一般会选择varchar,但这些字段类型可以适当的做些调整,同一种数据类型也有不同范围的具体类型可选,哪在有些情况下就可以选择更合适的类型,例如:
-
• 对于姓名字段,一般都会限制用户名长度,这时不要无脑用
varchar,使用char类型更好。 -
• 对于一些显然不会拥有太多数据的表,主键
ID的类型可以从int换成tinyint、smallint、mediumit。 -
• 对于日期字段,不要使用字符串类型,而更应该选择
datetime、timestamp,一般情况下最好为后者。 -
• 对于一些固定值的字段,如性别、状态、省份、国籍等字段,可以选择使用数值型代替字符串,如果必须使用字符串类型,最好使用
enum枚举类型代替varchar类型。
总之在选择字段的数据类型时有三个原则:
-
• ①在保证足够使用的范围内,选择最小数据类型,因为它们会占用更少的磁盘、内存和
CPU缓存,同时在处理速度也会更快。 -
• ②尽量避免索引字段值为
NULL,定义字段时应尽可能使用NOT NULL关键字,因为字段空值过多会影响索引性能。 -
• ③在条件允许的情况下,尽量使用最简单的类型代替复杂的类型,如
IP的存储可以使用int而并非varchar,因为简单的数据类型,操作时通常需要的CPU资源更少。
2.3.3、索引结构的优化
索引结构优化主要是指根据业务创建更合适的索引,这里主要可以从四个方面考虑,下面一起来聊一聊。
①索引字段的组成尽量选择多个,如果一个表中需要建立多个索引,应适当根据业务去将多个单列索引组合成一个联合索引,这样做一方面可以节省磁盘空间,第二方面还可以充分使用索引覆盖的方式查询数据,能够在一定程度上提升数据库的整体性能。
②对一个值较长的字段建立索引时,可以选用字段值的前
N个字符创建索引,也就是对于值较长的字段尽量建立前缀索引,而不是通过完整的字段值建立索引,索引字段值越小,单个B+Tree的节点中能存储的索引键会越多,一个节点存下的索引键越多,索引树会越矮,查询性能自然会越高。
③索引类型的选择一定要合理,对于经常做模糊查询的字段,可以建立全文索引来代替普通索引,因为基于普通索引做
like查询会导致索引失效,而采用全文索引的方式做模糊查询效率会更高更快,并且全文索引的功能更为强大。
④索引结构的选择可以根据业务进行调整,在某些不会做范围查询的字段上建立索引时,可以选用
hash结构代替B+Tree结构,因为Hash结构的索引是所有数据结构中最快的,散列度足够的情况下,复杂度仅为O(1)。
2.4、MySQL参数优化的选项
和
JVM参数调优一样,本质上每个参数的默认值,为了兼容所有业务,因此都是经过MySQL官方精心设计过的,也正因如此,所以有些参数的默认值能发挥出的性能只能算中规中矩,在服务器硬件配置不错的情况下,适当调整一些参数,来试图进行一些激进的优化,从而达到性能更佳的效果。
2.4.1、调整InnoDB缓冲区
在MySQL参数中,首先最值得调整的就是InnoDB缓冲区的大小,因为InnoDB将是MySQL启动后使用最多的引擎,所以为其分配一个足够大的缓冲区,能够在最大程度上提升MySQL的性能,但是缓冲区该分配多少内存呢?有人说是机器内存的80%,但这会让其他区域没有足够的内存使用,所以最佳比例应该控制在70~75%左右,比如一台服务器的内存为32GB,将innodb_buffer_pool_size = 22938M(23GB)左右最合理。
为
InnoDB的缓冲区分配了足够的大小后,运行期间InnoDB会根据实际情况,去自动调整内部各区域中的数据,如热点数据页、自适应哈希索引.....,调整该区域的大小后,能直接让MySQL性能上升一个等级。
同时当InnoDB缓冲区空间大于1GB时,InnoDB会自动将缓冲区划分为多个实例空间,这样做的好处在于:多线程并发执行时,可以减少并发冲突。MySQL官方的建议是每个缓冲区实例必须大于1GB,因此如果机器内存较小时,例如8/16GB,可以指定为1GB,但是机器内存够大时,比如达到了32GB/64GB甚至更高,哪可以适当将每个缓冲区实例调整到2GB左右。
比如现在假设缓冲区共计拥有
40GB内存,哪设置将缓冲区实例设置为innodb_buffer_pool_instances = 20个比较合适。
2.4.2、调整工作线程的缓冲区
除开可以调整InnoDB的缓冲区外,同时还可以调大sort_buffer、read_buffer、join_buffer几个区域,这几个区域属于线程私有区域,也就意味着每条线程都拥有这些区域:
-
•
sort_buffer_size:排序缓冲区大小,影响group by、order by...等排序操作。 -
•
read_buffer_size:读取缓冲区大小,影响select...查询操作的性能。 -
•
join_buffer_size:联查缓冲区大小,影响join多表联查的性能。
对于这些区域,最好根据机器内存来设置为一到两倍MB,啥意思呢?比如4GB的内存,建议将其调整为4/8MB、8GB的内存,建议将其调整为8/16MB.....,但这些区域的大小最好控制在64MB以下,因为线程每次执行完一条SQL后,就会将这些区域释放,所以再调大也没有必要了。
对于排序查询的操作,还可以调整一个参数:
max_length_for_sort_data,这个参数关乎着MySQL排序的方式,如果排序字段值的最大长度小于该值,则会将所有要排序的字段值载入内存排序,但如果大于该值时,则会一批一批的加载排序字段值进内存,然后一边加载一边做排序。
上述这两种排序算法,显然第一种效率更高,毕竟这种方式是基于所有的数据做排序,第二种算法则是一批一批数据做排序,每批数据都可能会打乱之前排好序的数据,因此可以适当调大该参数的值(但这个值究竟多少合适,要根据具体的业务来做抉择,否则交给还是使用MySQL自己来控制)。
2.4.3、调整临时表空间
同时还可以调整tmp_table_size、max_heap_table_size两个参数,这两个参数主要是限制临时表可用的内存空间,当创建的临时表空间占用超过tmp_table_size时,就会将其他新创建的临时表转到磁盘中创建,这显然是十分违背临时表的设计初衷,毕竟创建临时表的目的就是用来加快查询速度,结果又最后又把临时表放到磁盘中去了,这反而还多了一步开销。
那么这两个参数该设置多大呢?这要根据
show global status like 'created_tmp%';的统计信息来决定,用统计出来的信息:Created_tmp_disk_tables / Created_tmp_tables * 100% = 120%,达到这个标准就比较合适,但调整这个区域的值需要反复重启MySQL以及压测,因此比较费时间,如果你在项目中很少使用临时表,哪也可以不关心这块参数的调整。
2.4.4、调整空闲线程的存活时间
其实对于MySQL最大连接数无需做过多控制,客户端连接池那边做了调整即可,对于这点是没错的,可以通过下述命令查看数据库连接的峰值:
-
•
show global status like 'Max_used_connections';
一般在客户端做了连接数控制后,这个峰值一般都会在客户端最大连接数的范围之内,对于数据库连接这块唯一需要稍微调整的即是空闲连接的超时时间,即wait_timeout、interactive_timeout两个参数,这两个参数必须一同设置,否则不会生效,MySQL内部默认为8小时,也就是一个连接断开后,默认也会将对应的工作线程缓存八小时后再销毁,这里我们可以手动调整成30min~1h左右,可以让无用的连接能及时释放,减少资源的占用。
2.4.5、MySQL参数调优小结
对于上述的一些调优参数,可以在启动之后通过set global @@xxx = xxx的方式调整,但最好还是直接修改my.ini/my.conf配置文件,因为这样可以让这些参数在每次启动时都生效,避免了每次重启时还需要手动调整。
最后,对于某些安全性要求不高的业务中,也可以适当调整
MySQL数据和日志的刷盘策略,将其调整到更长的间隔时间刷盘,虽然这样会导致安全性下降,出现一定的数据丢失,但可以换来不错的性能(也包括事务的隔离级别,也可以从RR调整到RC级别,这样也能够减少一定程度上的并发冲突,从而使得数据库的整体并发量提高)。
2.5、架构优化与SQL优化
变更项目的整体架构,这是性能优化收益最大的手段。
对于架构优化主要牵扯两块,一方面是从整个项目的角度出发,引入一些中间件来优化整体性能。另一方面则是调整
MySQL的部署架构,以此来确保可承载更大的流量访问,提高数据层的整体吞吐。
2.5.1、引入缓存中间件解决读压力
正常的项目业务中,往往读请求的数量远超写请求,如果将所有的读请求都落入数据库处理,这自然会对MySQL造成巨大的访问压力,严重的情况下甚至会由于流量过大,直接将数据库打到宕机,因此为了解决这系列问题,通常都会在应用程序和数据库之间架设一个缓存,例如最常用的Redis。
在项目中引入Redis作为缓存后,在缓存Key设计合理的情况下,至少能够为MySQL分担70%以上的读压力,查询MySQL之前先查询一次Redis,Redis中有缓存数据则直接返回,没有数据时再将请求交给MySQL处理,从MySQL查询到数据后,再次将数据写入Redis,后续有相同请求再来读取数据时,直接从Redis返回数据即可。
2.5.2、引入消息中间件解决写压力
Redis,能够在很大程度上减轻MySQL的读请求压力,但当业务系统中的写操作也较为频繁时又该怎么办呢?可以引入MQ消息中间件做削峰填谷。
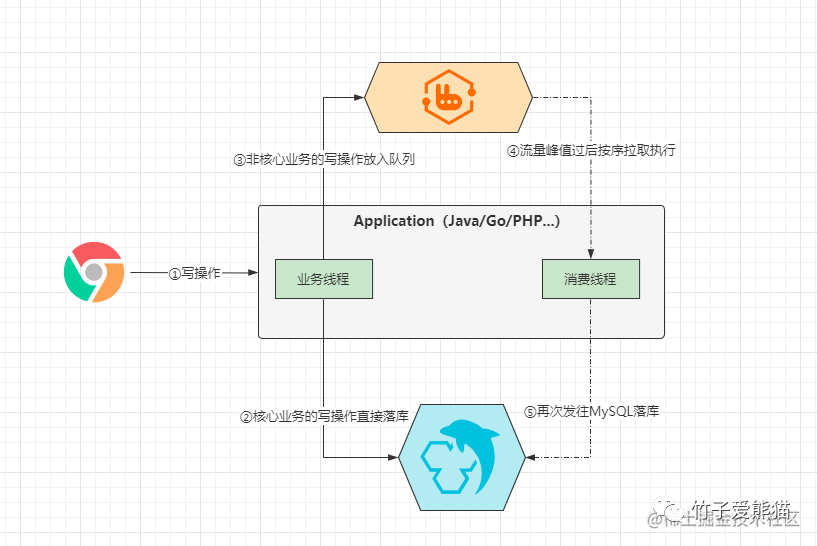
App-MQ-MySQL
例如:下单业务通常由「提交订单、支付费用、扣减库存、修改订单状态、添加发票记录、添加附赠服务....」这一系列操作组成,其中「提交订单、支付费用」属于核心业务,因此当用户下单时,这两类请求可以发往MySQL执行落库操作,而对于「扣减库存、修改订单状态、添加发票记录、添加附赠服务....」这类操作则可以发往MQ,当写入MQ成功,则直接返回客户端下单成功,后续再由消费线程去按需拉取后执行。
当然,对于「扣减库存」而言,其实在
Redis中也会缓存商品信息,在扣减库存时仅仅只会减掉Redis中的商品库存,确保其他用户看到的库存信息都是实时的,最终的减库存操作,是去异步消费MQ中的消息后,最终才落库的。
经过MQ做了流量的削峰填谷后,这能够在极大的程度上减轻MySQL的写压力,能够将写压力控制到一个相较平缓的程度,防止由于大量写请求直接到达MySQL,避免负载过高造成的宕机现象出现。
2.5.3、MySQL主从读写分离
前面聊到的Redis也好,MQ也罢,这都属于在MySQL之前架设中间件,以此来减少真正抵达数据库的请求数量,万一经过Redis、MQ后,那些必须要走MySQL执行的请求依旧超出单机MySQL的承载范围时,如若MySQL依旧以单机形式在线上运行,这绝对会导致线上频繁宕机的情况出现。
MySQL的架构优化方案:主从架构、双主架构、分库分表架构。
主从复制,这是大多数中间件都会存在的一种高可用机制,而MySQL中也存在这种架构,也就是使用两台服务器来部署两个MySQL节点,一台为主机,另一台为从机,从节点会一直不断的从主节点上同步增量数据,当主节点发生故障时,从节点可以替换原本的主节点,以此来为客户端提供正常服务,架构模型如下:
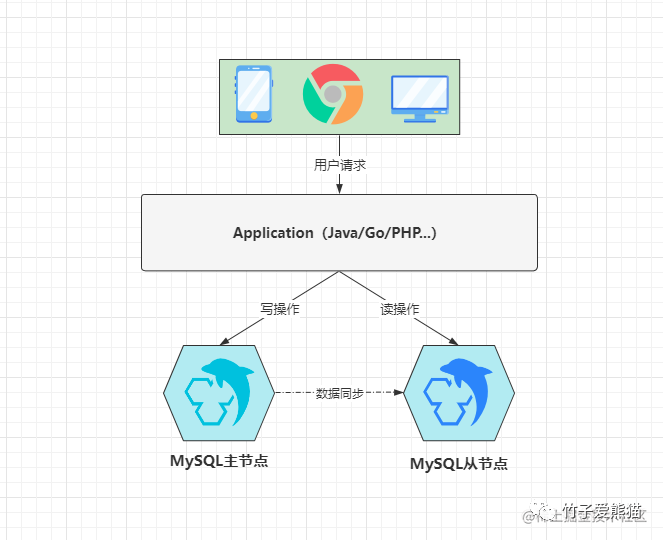
主从读写分离
在上图中就是一个典型的主从架构,但如果从节点仅仅只是作为一个备胎,这难免有些浪费资源,因此可以在主从架构的模式下,再略微做些调整,即实现读写分离,由于读操作并不会变更数据,所以对于读请求可以分发到从节点上处理,对于会引发数据变更的写请求,则分发到主节点处理,这样从而能够进一步提升MySQL的整体性能。
主节点的数据变更后,从节点也会基于
bin-log日志去同步数据,但这种模式下会存在些许的数据不一致性,因为同步是需要时间的,向主节点修改一条数据后,立马去从节点中查询,这时不一定能够看到最新的数据,因为这时数据也许还未被同步过来。
如果项目业务对数据实时性要求特别高,哪就不要考虑主从架构。
2.5.4、MySQL双主双写热备
前面主从读写分离的方案,更适用于一些读大于写的业务,但对于一些类似于仓储这种写大于读的项目业务,这种方案带来的性能收益不见得有多好,因此从机分担的读压力,可能仅是系统的10~20%流量,因此对于这种场景下,双主双写(双主热备)方案才是最佳选择,其架构图如下:

双主双写架构
这里的两个MySQL节点都为主,同时它们也都为从。其实就是指这两个节点互为主从,两者之间相互同步数据,同时都具备处理读/写请求的能力,当出现数据库的读/写操作时,可以将请求抛给其中任意一个节点处理。
但是为了兼容两者之间的数据,对于每张表的主键要处理好,如果表的主键是
int自增类型的,请一定要手动设置一下自增步长和起始值,比如这里有两个MySQL节点,那么可以将步长设置为2,起始值分别为1、2,这样做的好处是啥?能够确保主键的唯一性,设置后两个节点自增ID的序列如下:
节点1:[1、3、5、7、9、11、13、15、17、19.....]
节点2:[2、4、6、8、10、12、14、16、18、20.....]
当插入数据的SQL语句发往节点1时,会按照奇数序列自增ID,发往节点2时会以偶数序列自增ID,然后双方相互同步数据,最终两个MySQL节点都会具备完整的数据,因此后续的读请求,无论发往哪个节点都可以读到数据。
2.5.5、MySQL分库分表思想
多主模式有个天大的弊端,是存储容量的上限+木桶效应。因为多主模式中的每个节点都会存储完整的数据,因此当数据增长达到硬件的最大容量时,就无法继续写入数据了,此时只能通过加大磁盘的形式进一步提高存储容量,但硬件也不可能无限制的加下去,而且由于多主是基于主从架构实现的,因为具备木桶效应,要加得所有节点一起加,否则另一个节点无法同步写入数据时,就会造成所有节点无法写入数据。
需要用到这么多
MySQL节点的业务,其数据的增长速度自然不慢,因此在存储容量方面很容易抵达瓶颈,这种情况下选择分库分表才是最佳方案。
MySQL-垂直分库
垂直分库,根据业务属性的不同,会创建不同的数据库,然后由不同的业务连接不同的数据库,各自之间数据分开存储,节点之间数据不会同步,以这种方式来部署MySQL,即提高了数据库的整体吞吐量和并发能力,同时也不存在之前的存储容量的木桶问题。
分库分表不是一种很完美的解决方案,实际上当对项目做了分库分表之后,带来的问题、要解决的问题只会更多,只不过相较于分库分表带来的收益而言,解决问题的成本是值得的,所以才会使用分库分表技术。
三、MySQL优化篇总结
对于MySQL数据库的一些调优策略,其中能够带来最大收益的方案则是优化项目架构和数据库架构,但这种方案成本也是最高的,一方面需要解决新的问题,同时还需要额外的部署成本,所以在无需使用更高规格的架构处理并发时,就不必提前做这些架构设计,因为能够根据业务特性控制成本,也是作为一个优秀的高级开发/架构师必备的思想。
任何的优化手段都具有主观的性质存在,而且每一种优化的手段都需要付出一定的代价。同时,性能优化并没有非常标准的优化方案参考,优化是一个永无止境的方向,随着工作经验的不断积累,你的优化手段和见解就有可能不同,最终落地的优化方案也会不同。
PS:单机MySQL最好的优化手段,请手动将MySQL版本升级到5.7及以上,因为MySQL5.6之后官方对后续的版本做了很大程度上的改进,引入了很多高性能技术,所以如果你项目的MySQL版本还在其之下,条件允许的情况下一定记得先做版本升级。
SQL 优化
(Structured Query Language)标准结构化查询语言简称SQL,无论什么关系型数据库,本质上SQL的语法都是相同的,因为它们都实现了相同的SQL标准,不同数据库之间仅支持的特性不同而已。
而所谓的
SQL优化,就是指将一条SQL写的更加简洁,让SQL的执行速度更快,易读性与维护性更好。
SQL优化是建立在不影响业务的前提之上的,如果为了提高执行效率,把SQL改成了不符合业务需求的样子,这是不行的。如果一件事违背了初衷,就算再好也无济于事,比如心算特别快,但如果算的不准,再快也没意义,这个道理放在SQL优化中亦是同理,优化一定要建立在不违背业务需求的情况下进行!
一、编写SQL的基本功
**拆解业务需求,先以定值推导SQL**。
所谓的
SQL编写技巧亦是如此,面对一个较为复杂或较难实现的业务需求时,就可以按照需求进行逐步拆分,化繁为简后逐步实现。
**先以定值推导SQL**,这是啥意思呢?因为有些情况下,一个查询条件会依赖于另一条SQL的执行结果来决定,很多人在这种情况下会直接组合起来一起写,但这会导致编写SQL的复杂度再次提升,因此在这种情况下,可以先用指定值作为条件去查询,例如xx = "xxx",后面等整体SQL完成后,再套入SQL。
在编程中有句话叫做:扎实的基础理论知识,会决定一个人水平飞得有多高,但能够将相应的理论用于实践,这才能真正体现出一个人的水平有多牛,只懂理论不懂实践,这无异于纸上谈兵。
select *from zz_users;
+---------+-----------+----------+----------+---------------------+
| user_id | user_name | user_sex | password | register_time |
+---------+-----------+----------+----------+---------------------+
|1|熊猫|女|6666|2022-08-1415:22:01|
|2|竹子|男|1234|2022-09-1416:17:44|
|3|子竹|男|4321|2022-09-1607:42:21|
|4|黑熊|男|8888|2022-09-1723:48:29|
|8|猫熊|女|8888|2022-09-2717:22:29|
|9|棕熊|男|0369|2022-10-1723:48:29|
+---------+-----------+----------+----------+---------------------+-
基于性别字段分组,然后
ID排序,最后显示各组中的所有姓名,每个姓名之间用,隔开。
group_concat(),它可以给我们返回指定字段分组组合返回的结果。
③将排序语句应用于分组查询的结果中,然后再根据`user_id`排序输出姓名。
select
user_sex as"性别",
convert(group_concat(user_name orderby user_id desc separator ",") using utf8) as"姓名"
from `zz_users`
group by user_sex;
-- 执行结果如下:
+------+------------------------+
|性别|姓名|
+------+------------------------+
|女|猫熊,熊猫|
|男|棕熊,黑熊,子竹,竹子|
+------+------------------------+二、SQL优化的小技巧
如何让自己的
SQL又快又好呢?答案其实非常简单,减小查询的数据量、提升SQL的索引命中率即可。
2.1、编写SQL时的注意点
在写SQL的时候,往往很多时候的细节不注意,就有可能导致索引失效,也因此会造成额外的资源开销,而我们要做的就是避开一些误区,确保自己的SQL在执行过程中能够最大程度上节省资源、缩短执行时间,下面罗列一些经典的SQL注意点。
2.1.1、查询时尽量不要使用*
一般在写SQL为了方便,所以通常会采用*来代替所有字段,写*的确能让程序员更省力,但对机器就不太友好了,因此在写查询语句时一律不要使用*代替所有字段,这条准则相信大家都知道,但到底是为什么呢?
其实主要有如下几方面的原因:
-
• ①分析成本变高。
一条SQL在执行前都会经过分析器解析,当使用*时,解析器需要先去解析出当前要查询的表上*表示哪些字段,因此会额外增加解析成本。但如果明确写出了查询字段,分析器则不会有这一步解析*的开销。
-
• ②网络开销变大。
当使用*时,查询时每条数据会返回所有字段值,然后这些查询出的数据会先被放到结果集中,最终查询完成后会统一返回给客户端,但线上Java程序和MySQL都是分机器部署的,所以返回数据时需要经过网络传输,而由于返回的是所有字段数据,因此网络数据包的体积就会变大,从而导致占用的网络带宽变高,影响数据传输的性能和资源开销。但实际上可能仅需要用到其中的某几个字段值,所以写清楚字段后查询,能让网络数据包体积变小,从而减小资源消耗、提升响应速度。
-
• ③内存占用变高。
当查询一条数据时都会将其结果集放入到BufferPool的数据缓冲页中,如果每次用*来查询数据,查到的结果集自然会更大,占用的内存也会越大,单个结果集的数据越大,整个内存缓冲池中能存下的数据也就越少,当其他SQL操作时,在内存中找不到数据,又会去触发磁盘IO,最终导致MySQL整体性能下降。
-
• ④维护性变差。
用过MyBatis框架的小伙伴应该都知道一点,一般为了对应查询结果与实体对象的关系,通常都需要配置resultMap来声明表字段和对象属性的映射关系,但如果每次使用*来查询数据,当表结构发生变更时,就算变更的字段结构在当前业务中用不到,也需要去维护已经配置好的resultMap,所以会导致维护性变差。但声明了需要的字段时,配置的resultMap和查询字段相同,因此当变更的表结构不会影响当前业务时,也无需变更当前的resultMap。
综上所述,使用*的情况下反而会带来一系列弊端,所以能显示写明所需字段的情况下,尽量写明所需字段,除开上述原因外,还有一点最关键的原因:基于非主键字段查询可能会产生回表现象,如果是基于联合索引查询数据,需要的结果字段在联合索引中有时,可能通过索引覆盖原理去读数据,从而减少一次回表查询。但使用*查询所有字段数据时,由于联合索引中没有完整数据,因此只能做一次回表从聚簇索引中拿数据。
2.1.2、连表查询时尽量不要关联太多表
对于这点的原因其实很简单,一旦关联太多的表,就会导致执行效率变慢,执行时间变长,原因如下:
-
• 数据量会随表数量呈直线性增长,数据量越大检索效率越低。
-
• 当关联的表数量过多时,无法控制好索引的匹配,涉及的表越多,索引不可控风险越大。
一般来说,交互型的业务中,关联的表数量应当控制在5张表之内,而后台型的业务由于不考虑用户体验感,有时候业务比较复杂,又需要关联十多张表做查询,此时可以这么干,但按照《高性能MySQL》上的推荐,最好也要控制在16~18张表之内(阿里开发规范中要求控制在3张表以内)。
2.1.3、多表查询时一定要以小驱大
所谓的以小驱大即是指用小的数据集去驱动大的数据集,说简单一点就是先查小表,再用小表的结果去大表中检索数据,其实在MySQL的优化器也会有驱动表的优化,当执行多表联查时,MySQL的关联算法为Nest Loop Join,该算法会依照驱动表的结果集作为循环基础数据,然后通过该结果集中一条条数据,作为过滤条件去下一个表中查询数据,最后合并结果得到最终数据集,MySQL优化器选择驱动表的逻辑如下:
-
• ①如果指定了连接条件,满足查询条件的小数据表作为驱动表。
-
• ②如果未指定连接条件,数据总行数少的表作为驱动表。
如果在做连表查询时,你不清楚具体用谁作为驱动表,哪张表去join哪张表,这时可以交给MySQL优化器自己选择,但有时候优化器不一定能够选择正确,因此写SQL时最好自己去选择驱动表,小表放前,大表放后。
举个子查询的小表驱动大表的例子:
select * from xxx where yyy in (select yyy from zzz where ....);MySQL在执行上述这条SQL时,会先去执行in后面的子查询语句,这时尽量要保证子查询的结果集小于in前面主查询的结果集,这样能够在一定程度上减少检索的数据量。通常使用in做子查询时,都要确保in的条件位于所有条件的最后面,这样能够在最大程度上减小多表查询的数据匹配量。
以小驱大这个规则也可以进一步演化,也就是当查询多张表数据时,如果有多个字段可以连接查询,记得使用
and来拼接多个联查条件,因为条件越精准,匹配的数据量就越少,查询速度自然会越快。
对于单表查询时也是如此,比如要对数据做分组过滤,可以先用where过滤掉一部分不需要的数据后,再对处理后的数据做分组排序,因为分组前的数据量越小,分组时的性能会更好!
可以把
SQL当成一个链式处理器,每一次新的子查询、关联查询、条件处理....等情况时,都可以看成一道道的工序,我们在写SQL时要注意的是:在下一道工序开始前尽量缩小数据量,为下一道工序尽可能提供更加精准的数据。
2.1.4、不要使用like左模糊和全模糊查询
如若like关键字以%号开头会导致索引失效,从而导致SQL触发全表查询,因此需要使用模糊查询时,千万要避免%xxx、%xxx%这两种情况出现,实在需要使用这两类模糊查询时,可以适当建立全文索引来代替,数据量较大时可以使用ES、Solr....这类搜索引擎来代替。
2.1.5、查询时尽量不要对字段做空值判断
select * from xxx where yyy is null;
select * from xxx where yyy not is null;当出现基于字段做空值判断的情况时,会导致索引失效,因为判断null的情况不会走索引,因此切记要避免这样的情况,一般在设计字段结构的时候,请使用not null来定义字段,同时如果想为空的字段,可以设计一个0、""这类空字符代替,一方面要查询空值时可通过查询空字符的方式走索引检索,同时也能避免MyBatis注入对象属性时触发空指针异常。
2.1.6、不要在条件查询=前对字段做任何运算
select * from zz_users where user_id * 2 = 8;
select * from zz_users where trim(user_name) = "熊猫";zz_users用户表中user_id、user_name字段上都创建了索引,但上述这类情况都不会走索引,因为MySQL优化器在生成执行计划时,发现这些=前面涉及到了逻辑运算,因此就不会继续往下走了,会将具体的运算工作留到执行时完成,也正是由于优化器没有继续往下走,因此不会为运算完成后的字段选择索引,最终导致索引失效走全表查询。
从这里可以得出一点,千万不要在条件查询的
=前,对字段做任何运算,包括了函数的使用也不允许,因为经过运算处理后的字段会变成一个具体的值,而并非字段了,所以压根无法使用到索引。
2.1.7、 !=、!<>、not in、not like、or...要慎用
简单来说就是这类写法也可能导致索引失效,因此在实际过程中可以使用其他的一些语法代替,比如or可以使用union all来代替:
select user_name from zz_users where user_id=1 or user_id=2;
-- 可以替换成:
select user_name from zz_users where user_id=1
union all
select user_name from zz_users where user_id=2;虽然这样看起来SQL变长了,但实际情况中查询效率反而更高一些,因为后面的SQL可以走索引(对于其他的一些关键字也一样,可以使用走索引的SQL来代替这些关键字实现)。
2.1.8、必要情况下可以强制指定索引
在表中存在多个索引时,有些复杂SQL的情况下,或者在存储过程中,必要时可强制指定某条查询语句走某个索引,因为MySQL优化器面对存储过程、复杂SQL时并没有那么智能,有时可能选择的索引并不是最好的,这时我们可以通过force index,如下:
select * from zz_users force index(unite_index) where user_name = "熊猫";这样就能够100%强制这条SQL走某个索引查询数据,但这种强制指定索引的方式,一定要建立在对索引结构足够熟悉的情况下,否则效果会适得其反。
2.1.10、避免频繁创建、销毁临时表
临时表是一种数据缓存,对于一些常用的查询结果可以为其建立临时表,这样后续要查询时可以直接基于临时表来获取数据,MySQL默认会在内存中开辟一块临时表数据的存放空间,所以走临时表查询数据是直接基于内存的,速度会比走磁盘检索快上很多倍。但一定要切记一点,只有对于经常查询的数据才对其建立临时表,不要盲目的去无限制创建,否则频繁的创建、销毁会对MySQL造成不小的负担。
2.1.11、尽量将大事务拆分为小事务执行
一个事务在执行事,如果其中包含了写操作,会先获取锁再执行,直到事务结束后MySQL才会释放锁。
而一个事务占有锁之后,会导致其他要操作相同数据的事务被阻塞,如果当一个事务比较大时,会导致一部分数据的锁定周期较长,在高并发情况下会引起大量事务出现阻塞,从而最终拖垮整个
MySQL系统。
-
•
show status like 'innodb_log_waits';查看是否有大事务由于redo_log_buffer不足,而在等待写入日志。
大事务也会导致日志写入时出现阻塞,这种情况下会强制触发刷盘机制,大事务的日志需要阻塞到有足够的空间时,才能继续写入日志到缓冲区,这也可能会引起线上出现阻塞。
因此基于上述原因,在面对一个较大的事务时,能走异步处理的可以拆分成异步执行,能拆分成小事务的则拆成小事务,这样可以在很大程度上减小大事务引起的阻塞。
2.1.12、从业务设计层面减少大量数据返回的情况
之前在做项目开发时碰到过一些奇葩需求,就是要求一次性将所有数据全部返回,而后在前端去做筛选展现,这样做虽然也可以,但如果一次性返回的数据量过于巨大时,就会引起网络阻塞、内存占用过高、资源开销过大的各类问题出现,因此如果项目中存在这类业务,一定要记住拆分掉它,比如分批返回给客户端。
分批查询的方式也被称之为增量查询,每次基于上次返回数据的界限,再一次读取一批数据返回给客户端,这也就是经典的分页场景,通过分页的思想能够提升单次查询的速度,以及避免大数据量带来的一系列后患问题。
2.1.13、尽量避免深分页的情况出现
前面刚刚聊过分页,分页虽然比较好,但也依旧存在问题,也就是深分页问题,如下:
select xx,xx,xx from yyy limit 100000,10; 上述这条SQL相当于查询第1W页数据,在MySQL的实际执行过程中,首先会查询出100010条数据,然后丢弃掉前面的10W条数据,将最后的10条数据返回,这个过程无异极其浪费资源。
哪面对于这种深分页的情况该如何处理呢?有两种情况。
如果查询出的结果集,存在递增且连续的字段,可以基于有序字段来进一步做筛选后再获取分页数据,如下:
select xx,xx,xx from yyy where 有序字段 >= nnn limit 10; 也就是说这种分页方案是基于递增且连续字段来控制页数的,如下:
-- 第一页
select xx,xx,xx from yyy where有序字段>=1 limit 10;
-- 第二页
select xx,xx,xx from yyy where有序字段>=11 limit 10;
-- 第N页.....
-- 第10000页
select xx,xx,xx from yyy where有序字段>=100001 limit 10; 这种情况下,MySQL就会先按where条件筛选到数据之后,再获取前十条数据返回,甚至还可以通过between做优化:
select xx,xx,xx from yyy where 有序字段 between 1000000 and 1000010; 这种方式就完全舍弃了limit关键字来实现分页,但这种方式仅适合于基于递增且连续字段分页。
那么例如搜索分页呢?这种分页情况是无序的,因为搜索到的数据可以位于表中的任意行,所以搜索出的数据中,就算存在有序字段,也不会是连续的,这该如何是好?这种情况下就只能在业务上限制深分页的情况出现了,以百度为例:

百度搜索分页
虽然搜索mysql关键字之后,显示大约搜索到了一亿条数据,但当咱们把分页往后拉就会发现,最大只能显示76页,当你再尝试往后翻页时就会看到一个提示:“限于网页篇幅,部分结果未予显示”。
上述百度的这个例子中,就从根源上隔绝了深分页的出现,毕竟你都没给用户提供接下来的分页按钮了,这时自然也就无法根据用户操作生成深分页的
SQL。
但上述这种思想仅局限于业务允许的情况下,以搜索为例,一般用户最多看前面30页,如果还未找到他需要的内容,基本上就会换个更精准的关键词重新搜索。
哪如果业务必须要求展现所有分页数据,此时又不存在递增的连续字段咋办?哪这种情况下要么选择之前哪种很慢的分页方式,要么就直接抛弃所有!每次随机十条数据出来给用户,如果不想重复的话,每次新的分页时,再对随机过的数据加个标识即可。
2.1.14、SQL务必要写完整,不要使用缩写法
-- 为字段取别名的简单写法
select user_name "姓名"from zz_users;
-- 为字段取别名的完整写法
select user_name as"姓名"from zz_users;
-- 内连表查询的简单写法
select*from表1,表2...where表1.字段=表2.字段...;
-- 内连表查询的完整写法
select*from表1别名1innerjoin表2别名2on别名1.字段=别名2.字段;
......这种做法略微有些问题,因为隐式的这种写法,在MySQL底层都需要做一次转换,将其转换为完整的写法,因此简写的SQL会比完整的SQL多一步转化过程,如果你考虑极致程度的优化,也切记将SQL写成完整的语法。
2.1.15、基于联合索引查询时请务必确保字段的顺序性
想要基于建立的联合索引查询数据,就必须要按照索引字段的顺序去查询数据,否则可能导致所以完全利用联合索引,虽然MySQL8.0版本中推出了《索引跳跃扫描机制》,但这种方案也会存在较大的开销,同时还有很强的局限性,所以最好在写SQL时,依旧遵循索引的最左前缀原则撰写。
2.1.16、客户端的一些操作可以批量化完成
批量新增某些数据、批量修改某些数据的状态.....,这类需求在一个项目中也比较常见,一般的做法如下:
for (xxObject obj : xxObjs) {
xxDao.insert(obj);
}
/**
* xxDao.insert(obj)对应的SQL如下:
* insert into tb_xxx values(......);
**/这种情况确实可以实现批量插入的效果,但是每次都需要往MySQL发送SQL语句,这其中自然会带来额外的网络开销以及耗时,因此上述实现可以更改为如下:
xxDao.insertBatch(xxObjs);
/**
* xxDao.insertBatch(xxObjs)对应的SQL如下:
* insert into tb_xxx values(......),(......),(......),(......),.....;
**/这样会组合成一条SQL发送给MySQL执行,能够在很大程度上节省网络资源的开销,提升批量操作的执行效率。
这样的方式同样适用于修改场景,如果一个业务会出现批量修改的情况时,也切记不要用
for循环来调用update语句对应的接口,而是应该再写一个update/replace语句的批量修改接口。
2.1.17、明确仅返回一条数据的语句可以使用limit 1
select * from zz_users where user_name = "竹子";
select * from zz_users where user_name = "竹子" limit 1;上述这两条SQL语句都是根据姓名查询一条数据,但后者大多数情况下会比前者好,因为加上limit 1关键字后,当程序匹配到一条数据时就会停止扫描,如果不加的情况下会将所有数据都扫描一次。所以一般情况下,如果确定了只需要查询一条数据,就可以加上limit 1提升性能。
但在一些极端情况下,性能可能相差不大,比如要查询的数据位于表/索引文件的最后面,那么依旧会全部扫描一次。还有一种情况是基于主键/唯一索引字段查询数据时,由于这些字段值本身具备唯一性,因此
MySQL在执行时,当匹配到第一个值时就会自动停止扫描,因此上述这个方案只适用于普通索引字段、或表中的普通字段。
2.2、SQL优化的业内标准
评判任何一件事情到底有没有做好都会有标准,而SQL语句的执行时间也一样,业内也早有了相应的标准,相信大家一定都听说过下述这个用户体验原则:
客户端访问时,能够在
1s内得到响应,用户会觉得系统响应很快,体验非常好。
客户端访问时,1~3秒内得到响应,处于可以接受的阶段,其体验感还算不错。
客户端访问时,需要等待3~5秒时才可响应,这是用户就感觉比较慢了,体验有点糟糕。
客户端访问时,一旦响应超过5秒,用户体验感特别糟糕,通常会选择离开或刷新重试。
上述这四条是用户体验感的四个等级,一般针对于C端业务而言,基本上都需要将接口响应速度控制到第二等级,即最差也要三秒内给用户返回响应,否则会导致体验感极差,从而让用户对产品留下不好的印象。
所谓的三秒原则通常是基于
C端业务而言的,对于B端业务来说,通常用户的容忍度会高一些,也包括B端业务的业务逻辑会比C端更为复杂一些,所以可将响应速度控制到第三等级,也就是5s内能够得到响应。针对于一些特殊类型的业务,如后台计算型的业务,好比跑批对账、定时调度....等,这类因为本身业务就特殊,因此可不关注其响应速度。
回归前面的用户三秒体验原则,似乎三秒也不难做到对嘛?基本上SQL语句在1~3秒内都能执行完成呀,但请牢记:这个三秒并不能全部分配给SQL执行,为什么呢?因为用户感受到的响应速度会由多方面的耗时组成,如下:
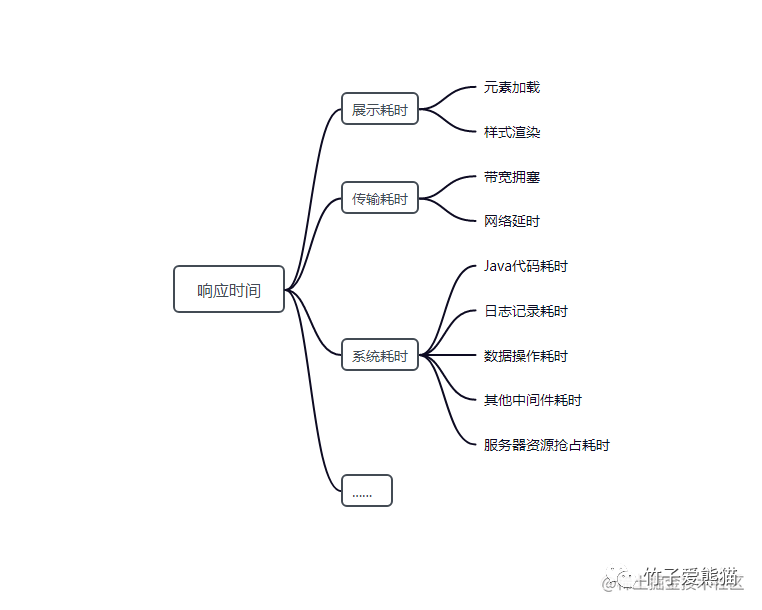
接口响应时间
从上图观察中可得知,所谓给用户的响应时间其实会包含各方面的耗时,也就是这所有的过程加一块儿,必须要在1~3s内给出响应,而SQL耗时属于「系统耗时→数据操作耗时」这部分,因此留给SQL语句执行的时间最多只能有500ms,一般在用户量较大的门户网站中,甚至要求控制在10ms、30ms、50ms以内。
三、MySQL索引优化
10~50ms听起来是个很难抵达的标准,但实际大部分走索引查询的语句基本上都能控制在该标准内,那又该如何判断一条SQL会不会走索引呢?这里需要使用一个工具:explain,下面一起来聊一聊。
3.1、explain分析工具
它本身是MySQL自带的一个执行分析工具,可使用于select、insert、update、delete、repleace等语句上,需要使用时只需在SQL语句前加上一个explain关键字即可,然后MySQL会对应语句的执行计划列出,比如:

explain工具
上述这些字段在之前也简单提到过,但并未展开细聊,所以在这里就先对其中的每个字段做个全面详解(MySQL8.0版本中才有12个字段,MySQL5.x版本只有10个字段)。
3.1.1、id字段
这是执行计划的ID值,一条SQL语句可能会出现多步执行计划,所以会出现多个ID值,这个值越大,表示执行的优先级越高,同时还会出现四种情况:
-
•
ID相同:当出现多个ID相同的执行计划时,从上往下挨个执行。 -
•
ID不同时:按照ID值从大到小依次执行。 -
•
ID有相同又有不同:先从大到小依次执行,碰到相同ID时从上往下执行。 -
•
ID为空:ID=null时,会放在最后执行。
3.1.2、select_type字段
当前执行的select语句其具体的查询类型,有如下取值:
-
•
SIMPLE:简单的select查询语句,不包含union、子查询语句。 -
•
PRIMARY:union或子查询语句中,最外层的主select语句。 -
•
SUBQUEPY:包含在主select语句中的第一个子查询,如select ... xx = (select ...)。 -
•
DERIVED:派生表,指包含在from中的子查询语句,如select ... from (select ...)。 -
•
DEPENDENT SUBQUEPY:复杂SQL中的第一个select子查询(依赖于外部查询的结果集)。 -
•
UNCACHEABLE SUBQUERY:不缓存结果集的子查询语句。 -
•
UNION:多条语句通过union组成的查询中,第二个以及更后面的select语句。 -
•
UNION RESULT:union的结果集。 -
•
DEPENDENT UNION:含义同上,但是基于外部查询的结果集来查询的。 -
•
UNCACHEABLE UNION:含义同上,但查询出的结果集不会加入缓存。 -
•
MATERIALIZED:采用物化的方式执行的包含派生表的查询语句。
这个字段主要是说明当前查询语句所属的类型,以及在整条大的查询语句中,当前这个查询语句所属的位置。
3.1.3、table字段
表示当前这个执行计划是基于哪张表执行的,这里会写出表名,但有时候也不一定是物理磁盘中存在的表名,还有可能出现如下格式:
-
•
<derivenN>:基于id=N的查询结果集,进一步检索数据。 -
•
<unionM,N>:会出现在查询类型为UNION RESULT的计划中,表示结果由id=M,N...的查询组成。 -
•
<subqueryN>:基于id=N的子查询结果,进一步进行数据检索。 -
•
<tableName>:基于磁盘中已创建的某张表查询。
一句话总结就是:这个字段会写明,当前的这个执行计划会基于哪个数据集查询,有可能是物理表、有可能是子查询的结果、也有可能是其他查询生成的派生表。
3.1.4、partitions字段
这个字段在早版本的explain工具中不存在,这主要是用来显示分区的,因为后续版本的MySQL中支持表分区,该列的值表示检索数据的分区。
3.1.5、type字段
该字段表示当前语句执行的类型,可能出现的值如下:
-
•
all:全表扫描,基于表中所有的数据,逐行扫描并过滤符合条件的数据。 -
•
index:全索引扫描,和全表扫描类似,但这个是把索引树遍历一次,会比全表扫描要快。 -
•
range:基于索引字段进行范围查询,如between、<、>、in....等操作时出现的情况。 -
•
index_subquery:和上面含义相同,区别:这个是基于非主键、唯一索引字段进行in操作。 -
•
unique_subquery:执行基于主键索引字段,进行in操作的子查询语句会出现的情况。 -
•
index_merge:多条件查询时,组合使用多个索引来检索数据的情况。 -
•
ref_or_null:基于次级(非主键)索引做条件查询时,该索引字段允许为null出现的情况。 -
•
fulltext:基于全文索引字段,进行查询时出现的情况。 -
•
ref:基于非主键或唯一索引字段查找数据时,会出现的情况。 -
•
eq_ref:连表查询时,基于主键、唯一索引字段匹配数据的情况,会出现多次索引查找。 -
•
const:通过索引一趟查找后就能获取到数据,基于唯一、主键索引字段查询数据时的情况。 -
•
system:表中只有一行数据,这是const的一种特例。 -
•
null:表中没有数据,无需经过任何数据检索,直接返回结果。
这个字段的值很重要,它决定了MySQL在执行一条SQL时,访问数据的方式,性能从好到坏依次为:
-
• 完整的性能排序:
null → system → const → eq_ref → ref → fulltext → ref_or_null → index_merge → unique_subquery → index_subquery → range → index → all -
• 常见的性能排序:
system → const → eq_ref → ref → fulltext → range → index → all
一般在做索引优化时,一般都会要求最好优化到ref级别,至少也要到range级别,也就是最少也要基于次级索引来检索数据,不允许出现index、all这类全扫描的形式。
3.1.6、possible_keys字段
这个字段会显示当前执行计划,在执行过程中可能会用到哪些索引来检索数据,但要注意的一点是:可能会用到并不代表一定会用,在某些情况下,就算有索引可以使用,MySQL也有可能放弃走索引查询。
3.1.7、key字段
前面的possible_keys字段表示可能会用到的索引,而key这个字段则会显示具体使用的索引,一般情况下都会从possible_keys的值中,综合评判出一个性能最好的索引来进行查询,但也有两种情况会出现key=null的这个场景:
-
•
possible_keys有值,key为空:出现这种情况多半是由于表中数据不多,因此MySQL会放弃索引,选择走全表查询,也有可能是因为SQL导致索引失效。 -
•
possible_keys、key都为空:表示当前表中未建立索引、或查询语句中未使用索引字段检索数据。
默认情况下,possible_keys有值时都会从中选取一个索引,但这个选择的工作是由MySQL优化器自己决定的,如果你想让查询语句执行时走固定的索引,则可以通过force index、ignore index的方式强制指定。
3.1.8、key_len字段
这个表示对应的执行计划在执行时,使用到的索引字段长度,一般情况下都为索引字段的长度,但有三种情况例外:
-
• 如果索引是前缀索引,这里则只会使用创建前缀索引时,声明的前
N个字节来检索数据。 -
• 如果是联合索引,这里只会显示当前
SQL会用到的索引字段长度,可能不是全匹配的情况。 -
• 如果一个索引字段的值允许为空,
key_len的长度会为:索引字段长度+1。
3.1.9、ref字段
显示索引查找过程中,查询时会用到的常量或字段:
-
•
const:如果显示这个,则代表目前是在基于主键字段值或数据库已有的常量(如null)查询数据。-
•
select ... where 主键字段 = 主键值; -
•
select ... where 索引字段 is null;
-
-
• 显示具体的字段名:表示目前会基于该字段查询数据。
-
•
func:如果显示这个,则代表当与索引字段匹配的值是一个函数,如:-
•
select ... where 索引字段 = 函数(值);
-
3.1.10、rows字段
这一列代表执行时,预计会扫描的行数,这个数字对于InnoDB表来说,其实有时并不够准确,但也具备很大的参考价值,如果这个值很大,在执行查询语句时,其效率必然很低,所以该值越小越好。
3.1.11、filtered字段
这个字段在早版本中也不存在,它是一个百分比值,意味着表中不会扫描的数据百分比,该值越小则表示执行时会扫描的数据量越大,取值范围是0.00~100.00。
3.1.12、extra字段
该字段会包含MySQL执行查询语句时的一些其他信息,这个信息对索引调优而言比较重要,可以带来不小的参考价值,但这个字段会出现的值有很多种,如下:
-
•
Using index:表示目前的查询语句,使用了索引覆盖机制拿到了数据。 -
•
Using where:表示目前的查询语句无法从索引中获取数据,需要进一步做回表去拿表数据。 -
•
Using temporary:表示MySQL在执行查询时,会创建一张临时表来处理数据。 -
•
Using filesort:表示会以磁盘+内存完成排序工作,而完全加载数据到内存来完成排序。 -
•
Select tables optimized away:表示查询过程中,对于索引字段使用了聚合函数。 -
•
Using where;Using index:表示要返回的数据在索引中包含,但并不是索引的前导列,需要做回表获取数据。 -
•
NULL:表示查询的数据未被索引覆盖,但where条件中用到了主键,可以直接读取表数据。 -
•
Using index condition:和Using where类似,要返回的列未完全被索引覆盖,需要回表。 -
•
Using join buffer (Block Nested Loop):连接查询时驱动表不能有效的通过索引加快访问速度时,会使用join-buffer来加快访问速度,在内存中完成Loop匹配。 -
•
Impossible WHERE:where后的条件永远不可能成立时提示的信息,如where 1!=1。 -
•
Impossible WHERE noticed after reading const tables:基于唯一索引查询不存在的值时出现的提示。 -
•
const row not found:表中不存在数据时会返回的提示。 -
•
distinct:去重查询时,找到某个值的第一个值时,会将查找该值的工作从去重操作中移除。 -
•
Start temporary, End temporary:表示临时表用于DuplicateWeedout半连接策略,也就是用来进行semi-join去重。 -
•
Using MRR:表示执行查询时,使用了MRR机制读取数据。 -
•
Using index for skip scan:表示执行查询语句时,使用了索引跳跃扫描机制读取数据。 -
•
Using index for group-by:表示执行分组或去重工作时,可以基于某个索引处理。 -
•
FirstMatch:表示对子查询语句进行Semi-join优化策略。 -
•
No tables used:查询语句中不存在from子句时提示的信息,如desc table_name;。
除开上述内容外,具体的可参考《explain-Extra字段详解》,其中介绍了Extra字段可能会出现的所有值,最后基于Extra字段做个性能排序:
-
•
Using index → NULL → Using index condition → Using where → Using where;Using index → Using join buffer → Using filesort → Using MRR → Using index for skip scan → Using temporary → Strart temporary,End temporary → FirstMatch
上面这个排序中,仅列出了一些实际查询执行时的性能排序,对于一些不重要的就没有列出了。
3.2、索引优化参考项
在上面咱们简单介绍了explain工具中的每个字段值,字段数量也比较多,但在做索引优化时,值得咱们参考的几个字段为:
-
•
key:如果该值为空,则表示未使用索引查询,此时需要调整SQL或建立索引。 -
•
type:这个字段决定了查询的类型,如果为index、all就需要进行优化。 -
•
rows:这个字段代表着查询时可能会扫描的数据行数,较大时也需要进行优化。 -
•
filtered:这个字段代表着查询时,表中不会扫描的数据行占比,较小时需要进行优化。 -
•
Extra:这个字段代表着查询时的具体情况,在某些情况下需要根据对应信息进行优化。
PS:在
explain语句后面紧跟着show warings语句,可以得到优化后的查询语句,从而看出优化器优化了什么。
3.3、索引优化实践
上面了解了索引优化时的一些参考项,接着来聊聊索引优化的实践,不过在优化之前要先搞清楚什么是索引优化,其实无非就两点:
-
• 把
SQL的写法进行优化,对于无法应用索引,或导致出现大数据量检索的语句,改为精准匹配的语句。 -
• 对于合适的字段上建立索引,确保经常作为查询条件的字段,可以命中索引去检索数据。
总归说来说去,也就是要让SQL走索引执行,但要记住:并非走了索引就代表你的执行速度就快,因为如果扫描的索引数据过多,依旧可能会导致SQL执行比较耗时,所以也要参考type、rows、filtered三个字段的值,来看看一条语句执行时会扫描的数据量,判断SQL执行时是否扫描了额外的行记录,综合分析后需要进一步优化到更细粒度的检索。
索引优化其实本质上,也就是遵循前面第二阶段提出的
SQL小技巧撰写语句,以及合理的使用与建立索引。
对于一些无可避免的慢SQL执行,比如复杂SQL的执行、深分页等情况,要么就从业务层面着手解决,要么就接受一定的耗时,毕竟凡事不可能做到十全十美。















 1059
1059











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









