







高并发下接口幂等性
日常的开发中有些接口对幂等性有严格的要求,如增加/扣减积分、用户支付/退款等场景,如果没有做接口的幂等性就会造成一定的资损或者用户投诉等问题。如下是增加积分过程,若接口未做幂等处理,现在由于积分服务响应超时导致Nginx重试:
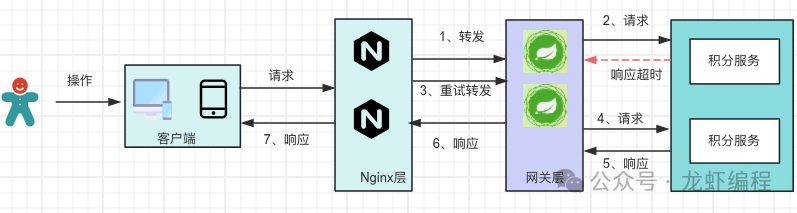
会出现由于积分服务没有做接口幂等处理,Nginx重试操作使得积分接口多次被调用,最终会给用户多加了积分。那么导致接口重复执行的来源有哪些?如何保证接口的幂等性呢?下面我们就这些问题做分析。
1、接口重复执行的场景
(1)用户重复提交请求(如用户点击按钮手速快,连续点击了多次提交按钮)或者用户的恶意攻击,导致请求被多次的转发到后端服务上。如下是用户连续点击发送的两次请求到后端:

实际上请求1和请求2我们只需要处理一个请求就好了,但是现在两个请求都过来了,就需要做幂等处理保证业务的一致性。
(2)分布式环境中服务的超时重试机制,MQ的自带的重试功能或生产者重复生产消息导致接口被重复调用。如下是MQ导致接口多次调用的情况:
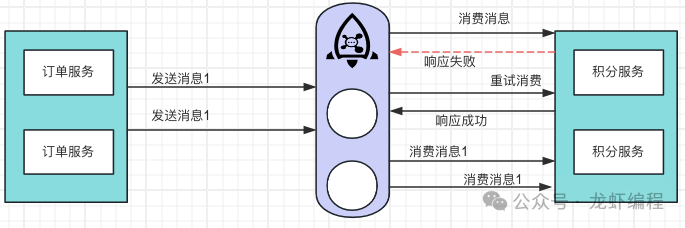
以上是常见的几种导致接口被重复的调用的场景,清楚了接口为什么出现被重复调用,下面就来分析几种解决这个问题的方案。
2、整理保证接口幂等性的方案
(1)前端控制方案
前端工程师在用户提交了请求后让提交按钮变成禁用状态或者跳转到其他的页面的方式,可以在一定程度上可以保证不会出现重复提交的问题。
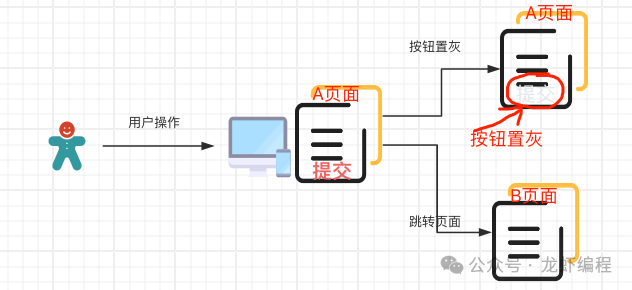
此方案可以一定程度上防君子但是不防小人,因为有的用户直接拿到接口后刷接口,那么此时就尴尬了。
(2)借助Redis的setnx命令
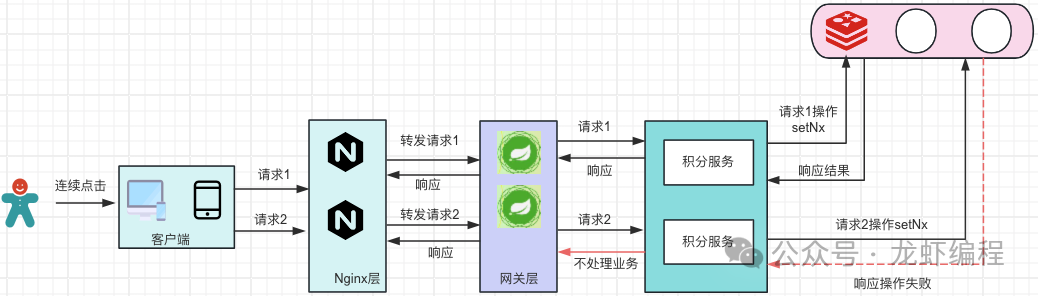
用户的请求1和请求2过来之后,我们在积分服务中拿到业务的唯一标识(如订单的id)到Redis中通过setnx命令并设定过期时间(过期时间可以根据业务来设定)来操作,判断setnx命令是否可以操作成功,如果操作成功那么允许执行业务,如果操作失败就不处理业务。
(3)后端发放令牌的方式

用户请求服务前,首先需要发送一个请求1到后端获取令牌(如JWT),获取到令牌后请求2和请求3(假设请求3是重复请求)都携带令牌请求到后端,后端接受到请求后先验证令牌的有效性,如果令牌是无效的就直接返回;如果令牌是有效的就将令牌保存到数据库中(数据库中设置令牌是唯一键)
(a)保存令牌数据成功就开始处理对应的任务
(b)保存令牌信息失败并且提示是唯一键冲突的异常,那么手动捕获异常并返回“重复请求”的提示给用户。
上面采用的是将令牌存储到数据库的方式实现,也可以使用Redis来实现,如下图所示:
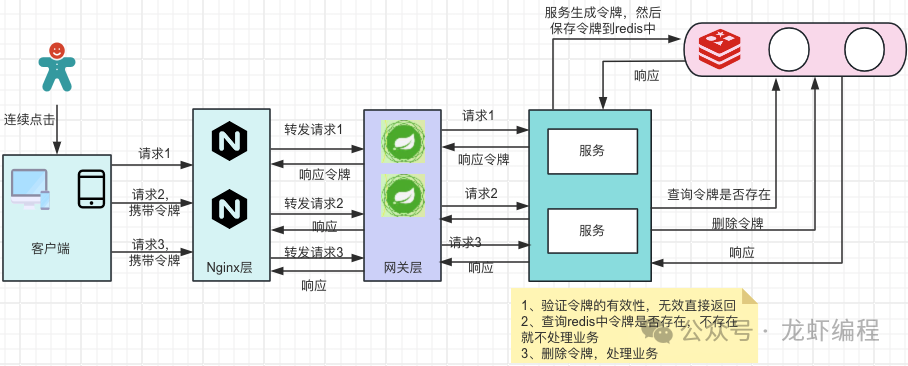
生成令牌后缓存到redis中,然后请求携带令牌到后端,后端首先检查令牌是否有效,如果无效就直接返回;如果令牌有效再去检查令牌是否在Redis中,如果令牌不在Redis中就直接返回,如果在Redis中就删除令牌然后处理业务。
(4)数据库的唯一索引机制(去重表机制)
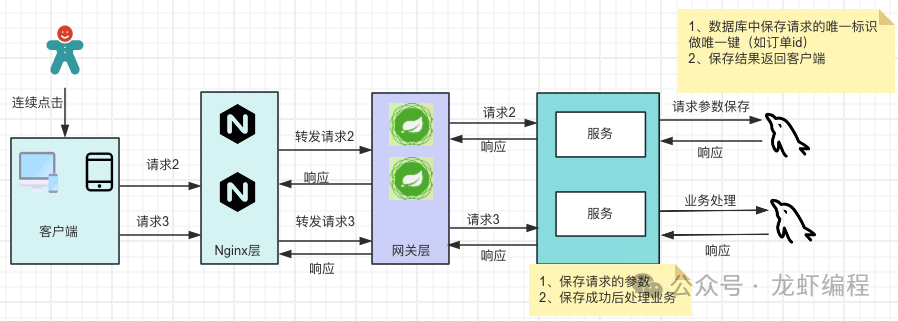
数据库给请求中的唯一标识的参数做唯一索引(如订单号),这样请求过来之后首先去保存请求参数信息,如果保存成功就可以执行业务;如果保存失败并提示唯一键冲突,直接返回提示用户“请勿重复”提交,在高并发下,此方式的效率比较低。
(5)Redis计数方式

每次请求到后端之后,首先通过Redis记录一下请求中的唯一标识,然后使用redis计数并且返回计数的结果,如果计数的结果大于1,则表示当前已请求是重复请求;如果计数等于1就可以处理业务。
(6)状态机方式

有些业务可以是用状态机的方案来实现,如请求1的目的是把订单状态从待支付---->待发货,请求2的目的是将把订单状态从待支付---->交易关闭;如果请求1修改成功之后,请求2的操作是无效的。底层的sql如下:
update order set status = x where statue = '待支付';通过返回的影响行数来判断是否操作成功(影响行数为1表示操作成功),如果操作失败可以做对象的提示
总结:
(1)接口出现重复调用的情况有可能来源于前端(用户多次点击或者恶意攻击等),也有可能后端(服务重试机制)
(2)保证接口幂等性的方案有多种,如去重表、Redis计数或者setnx方式、携带令牌方式、状态机方式等都可以实现。
(3)数据库的乐观锁和悲观锁是可以解决并发问题,但是不一定可以保证幂等性问题(如请求1和请求2按照获取锁的先后顺序执行,等于还是执行了两次,可能还是会对业务造成影响)。
项目中有10000个 if else 优化方案
在实际工作中,遇到类似于 10000 行 if else 代码的情况确实是极为罕见的。如果真的需要写这么多判断语句,不仅会增加代码的复杂度,还会影响系统的性能和可维护性。
虽然提到了策略模式等设计模式可以用来优化这种情况,但并不意味着它们是唯一的解决方案。每个问题都有不同的解决方法,需要根据具体情况进行分析和选择。
所以这题可以这样回答:
-
如果这 1 万个 if else 是在同一个代码块流程里面,这就要考虑这 1 万 if else 存在的意义了,因为这么量极的 if else 会很难维护,也会极其影响性能,需要具体分析然后再去分析如何去分解和优化。
-
如果这 1 万个 if else 分散在同一个项目里面,那么优化 if else 的方式有很多种,包括.……
方案1:策略模式
尽管策略模式可以使代码更加优雅,但也存在一些问题:
-
当遇到大量 if/else 分支,如 10000 个,就会涉及 10000 个策略类,导致类的膨胀,随着时间推移变得更加庞大和复杂。
-
如果是多层嵌套的 if/else,则策略模式可能无法发挥作用。
策略模式的优势在于方便解耦,适用于包含多种不同逻辑和算法的 if 场景,但对于大量 if/else 场景并不适用。
方案2:策略模式变体
这是策略模式的一种变体:
Map<Integer, Runnable> actionMap = new HashMap<>();
actionMap.put("condition1", () -> { /* 分支1的执行逻辑 */ });
actionMap.put("condition2", () -> { /* 分支2的执行逻辑 */ });
actionMap.put("conditionN", () -> { /* 分支N的执行逻辑 */ });
// 根据条件获取执行逻辑
Runnable action = actionMap.get("condition1");
if (action != null) {
action.run();
}通过将业务逻辑代码分离出去,可以简化单个类的代码,避免策略实现类的膨胀。然而,如果存在大量的条件映射,仍然会导致单个类的膨胀和难以维护。
在该情况下,使用线程异步执行的示例,还可以将要执行的逻辑代码存储在其他类或数据库中,然后通过反射或动态编译的方式加载并执行。这种方法可以进一步降低单个类的复杂度,实现更好的代码维护和可扩展性。
方案3:多级嵌套优化
上面说的两种方案嵌套可能无法解决,如果是这种带层级的判断是可以优化的:
if(xxxOrder != null){
if(xxxOrder.getXxxShippingInfo() != null){
if(xxxOrder.getXxxShippingInfo().getXxxShipmentDetails() != null){
if(xxxOrder.getXxxShippingInfo().getXxxShipmentDetails().getXxxTrackingInfo() != null){
...
}
}
}
}方案4:使用三目运算符
如果判断条件不多,只有 2、3 个的情况下可以使用三目运算符简化 if else 分支。
if (condition1) {
desc = "XX1";
} else if (condition2) {
desc = "XX2";
} else {
desc = "XX3";
}使用三目运算符一行搞定:
String desc = condition1 ? "XX1" : (condition2 ? "XX2" : "XX3");超过 3 个条件就不建议使用了,不然代码可读性会大大降低。
方案5:使用枚举
枚举类型可以用来表示一组固定的值,例如星期几、月份、颜色等,它提供了一种更简洁、可读性更高的方式来表示一组相关的常量。
如以下示例代码:
public class Test {
public static void main(String[] args) {
Day today = Day.MONDAY;
System.out.println("Today is " + today);
System.out.println("Today is " + today.getChineseName());
}
enum Day {
MONDAY("星期一"),
TUESDAY("星期二"),
WEDNESDAY("星期三"),
THURSDAY("星期四"),
FRIDAY("星期五"),
SATURDAY("星期六"),
SUNDAY("星期日");
private String chineseName;
Day(String chineseName) {
this.chineseName = chineseName;
}
public String getChineseName() {
return chineseName;
}
}
}这里我只写了一个字段,我们可以在枚举属性里面定义多个字段,这样就无需大量的 if else 判断,直接通过枚举来获取某个某一组固定的值了。
方案6:使用 Optional
Java 8 引入了一个新特性 Optional,它是一个容器对象,可以包含 null 值,可以替代繁琐的 xx != null 判断逻辑。
方案7:尽快返回
分析业务,根据 if else 的执行次数按降序排,把执行次数较多的 if 放在最前面,如果符合条件,就使用 return 返回,如下面代码:
if (条件1) {
return
}
if (条件2) {
return
}
...这种改进方式可能是一种简单的方法,可以显著提升系统的性能,但仍然存在以下问题:
-
有些条件不适合按照执行次数排序,可能存在先后或互斥关系。
-
当新增一个条件时,可能无法立即确定其执行次数,将其放置在后面可能会影响性能。
-
这种方法并没有帮助减少类的膨胀或改善代码维护性。
方案8:去除没必要的 if else
比如这种:
if (condition) {
...
} else {
return;
}优化后:
if(!condition){
return;
}或者是这样:
return !condition方案9:合并条件
考虑这 1 万 if else 是不是真的每个都有必要,是不是可以合并归类,比如是不是可以把几百、几千个相似逻辑的归为一类,这样也能大大简化 if else 数量。
比如以下代码:
double calculateShipping() {
if (orderAmount > 1000) {
return 0.5;
}
if (customerLoyaltyLevel > 5) {
return 0.5;
}
if (promotionIsActive) {
return 0.5;
}
}优化后:
double calculateShipping() {
if (orderAmount > 1000 || customerLoyaltyLevel > 5 || promotionIsActive) {
return 0.5;
}
}这样就把返回相同值的 if 归为一类了,如果 if 较大就能大大简化代码量。
方案10:规则引擎
针对复杂的业务逻辑,由于业务规则经常变化且不依赖于技术团队来制定,实现可配置的逻辑处理时,可以考虑使用规则引擎,例如 Drools。
规则引擎系统可执行一组规则,许多业务应用程序中,业务决策可以通过一系列逻辑规则定义,规则引擎允许这些规则在运行时执行,而无需硬编码在应用程序中。
规则引擎的优势包括:
-
实现业务逻辑与程序代码的解耦;
-
提高业务逻辑的可管理性;
-
提升系统的灵活性和可扩展性;
-
允许业务人员参与决策过程。
总结
在本文中,总结了 10 种优化 if else 的方法,实际上还有更多方法可供选择。除了多种优化技巧外,根据不同的场景,还可以考虑使用多态、责任链模式、模板方法模式等方法来减少 if else 的影响。
线程交替打印ABC如何实现?
三个线程交替打印 ABC
问题描述:写三个线程打印 "ABC",一个线程打印 A,一个线程打印 B,一个线程打印 C,一共打印 10 轮。
这里提供一个 Semaphore版本和 ReentrantLock + Condition 版本。
Semaphore 实现
我们先定义一个类 ABCPrinter 用于实现三个线程交替打印 ABC。
public class ABCPrinter {
private final int max;
// 从线程 A 开始执行
private final Semaphore semaphoreA = new Semaphore(1);
private final Semaphore semaphoreB = new Semaphore(0);
private final Semaphore semaphoreC = new Semaphore(0);
public ABCPrinter(int max) {
this.max = max;
}
public void printA() {
print("A", semaphoreA, semaphoreB);
}
public void printB() {
print("B", semaphoreB, semaphoreC);
}
public void printC() {
print("C", semaphoreC, semaphoreA);
}
private void print(String alphabet, Semaphore currentSemaphore, Semaphore nextSemaphore) {
for (int i = 1; i <= max; i++) {
try {
currentSemaphore.acquire();
System.out.println(Thread.currentThread().getName() + " : " + alphabet);
// 传递信号给下一个线程
nextSemaphore.release();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
return;
}
}
}
}
可以看到,我们这里用到了三个信号量,分别用于控制这三个线程的交替执行。semaphoreA 信号量先获取,也就是先输出“A”。一个线程执行完之后,就释放下一个信号量。也就是,A 线程执行完之后释放semaphoreB信号量,B 线程执行完之后释放semaphoreC信号量,以此类推。
接着,我们创建三个线程,分别用于打印 ABC。
ABCPrinter printer = new ABCPrinter(10);
Thread t1 = new Thread(printer::printA, "Thread A");
Thread t2 = new Thread(printer::printB, "Thread B");
Thread t3 = new Thread(printer::printC, "Thread C");
t1.start();
t2.start();
t3.start();
输出如下:
Thread A : A
Thread B : B
Thread C : C
......
Thread A : A
Thread B : B
Thread C : C
ReentrantLock + Condition 实现
思路和 synchronized+wait/notify 很像。
public class ABCPrinter {
private final int max;
// 用来指示当前应该打印的线程序号,0-A, 1-B, 2-C
private int turn = 0;
private final ReentrantLock lock = new ReentrantLock();
private final Condition conditionA = lock.newCondition();
private final Condition conditionB = lock.newCondition();
private final Condition conditionC = lock.newCondition();
public ABCPrinter(int max) {
this.max = max;
}
public void printA() {
print("A", conditionA, conditionB);
}
public void printB() {
print("B", conditionB, conditionC);
}
public void printC() {
print("C", conditionC, conditionA);
}
private void print(String name, Condition currentCondition, Condition nextCondition) {
for (int i = 0; i < max; i++) {
lock.lock();
try {
// 等待直到轮到当前线程打印
// turn 变量的值需要与线程要打印的字符相对应,例如,如果turn是0,且当前线程应该打印"A",则条件满足。如果不满足,当前线程调用currentCondition.await()进入等待状态。
while (!((turn == 0 && name.charAt(0) == 'A') || (turn == 1 && name.charAt(0) == 'B') || (turn == 2 && name.charAt(0) == 'C'))) {
currentCondition.await();
}
System.out.println(Thread.currentThread().getName() + " : " + name);
// 更新打印轮次,并唤醒下一个线程
turn = (turn + 1) % 3;
nextCondition.signal();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
lock.unlock();
}
}
}
}
在上面的代码中,三个线程的协调主要依赖:
-
ReentrantLock lock: 用于线程同步的可重入锁,确保同一时刻只有一个线程能修改共享资源。 -
Condition conditionA/B/C: 分别与"A"、"B"、"C"线程关联的条件变量,用于线程间的协调通信。一个线程执行完之后,通过调用nextCondition.signal()唤醒下一个应该打印的线程。
控制三个线程的执行顺序
问题描述:假设有 T1、T2、T3 三个线程,你怎样保证 T2 在 T1 执行完后执行,T3 在 T2 执行完后执行?
// T1
CompletableFuture<Void> futureT1 = CompletableFuture.runAsync(() -> {
System.out.println("T1 is executing.Current time:" + DateUtil.now());
// 模拟耗时操作
ThreadUtil.sleep(1000);
});
// T2 在 T1 完成后执行
CompletableFuture<Void> futureT2 = futureT1.thenRunAsync(() -> {
System.out.println("T2 is executing after T1.Current time:" + DateUtil.now());
ThreadUtil.sleep(1000);
});
// T3 在 T2 完成后执行
CompletableFuture<Void> futureT3 = futureT2.thenRunAsync(() -> {
System.out.println("T3 is executing after T2.Current time:" + DateUtil.now());
ThreadUtil.sleep(1000);
});
// 等待所有任务完成,验证效果
ThreadUtil.sleep(3000);
可以看到,我们这里通过 thenRunAsync()方法就实现了 T1、T2、T3 的顺序执行。thenRunAsync()方法的作用就是做完第一个任务后,再做第二个任务。也就是说某个任务执行完成后,执行回调方法
输出:
T1 is executing.Current time:2024-06-23 21:59:38
T2 is executing after T1.Current time:2024-06-23 21:59:39
T3 is executing after T2.Current time:2024-06-23 21:59:40
如果我们想要实现 T3 在 T2 和 T1 执行完后执行,T2 和 T1 可以同时执行,应该怎么办呢?
// T1
CompletableFuture<Void> futureT1 = CompletableFuture.runAsync(() -> {
System.out.println("T1 is executing. Current time:" + DateUtil.now());
// 模拟耗时操作
ThreadUtil.sleep(1000);
});
// T2
CompletableFuture<Void> futureT2 = CompletableFuture.runAsync(() -> {
System.out.println("T2 is executing. Current time:" + DateUtil.now());
ThreadUtil.sleep(1000);
});
// 使用allOf()方法合并T1和T2的CompletableFuture,等待它们都完成
CompletableFuture<Void> bothCompleted = CompletableFuture.allOf(futureT1, futureT2);
// 当T1和T2都完成后,执行T3
bothCompleted.thenRunAsync(() -> System.out.println("T3 is executing after T1 and T2 have completed.Current time:" + DateUtil.now()));
// 等待所有任务完成,验证效果
ThreadUtil.sleep(3000);
同样非常简单,可以通过 CompletableFuture 的 allOf()这个静态方法来并行运行多个 CompletableFuture 。然后,再利用 thenRunAsync()方法即可。
从 5s 到 0.5s!看看人家的 CompletableFuture 异步任务优化技巧,确实优雅!。
b+ 树的优缺点
B+ 树是一种自平衡的树数据结构,它通常用于数据库和操作系统的文件系统中。B+ 树是 B 树的一种变体,具有以下优缺点:优点 :
-
平衡性:B+ 树的所有叶子节点都具有相同的深度,这保证了搜索操作的效率。
-
降低磁盘I/O:由于 B+ 树的特性,它可以在磁盘上存储大量的键,并且在查找时只需要少量的磁盘I/O 操作,这减少了查找时间。
-
范围查询:B+ 树的叶子节点包含了所有的键值,并且是顺序链接的,这使得范围查询非常高效。
-
缓存友好:由于内部节点不包含数据,B+ 树可以在内存中缓存更多的键,这提高了缓存的利用率。
-
插入和删除操作高效:B+ 树的插入和删除操作通常只需要对少量节点进行修改,这使得它们在大多数情况下都非常高效。
-
扇出率高:B+ 树的每个内部节点可以有大量的子节点,这意味着树的高度相对较低,从而提高了效率。
缺点 :
-
复杂度:B+ 树的实现比其他数据结构(如二叉搜索树)更为复杂,这增加了开发和维护的难度。
-
内存使用:虽然 B+ 树在缓存友好性方面表现良好,但它的内部节点仍然需要占用一定的内存空间。
-
节点分裂和合并:在插入和删除操作时,B+ 树可能需要进行节点的分裂和合并,这增加了操作的复杂性。
-
不适用于小数据集:对于小数据集,B+ 树的优势可能不明显,因为它的自平衡特性在数据量较小时可能不会带来显著的性能提升。
索引的实践优化
索引是数据库中用于快速检索数据的数据结构。正确的索引策略可以显著提高查询性能,而不恰当的索引则可能导致性能下降。以下是一些实践中的索引优化建议:
-
选择合适的索引列:
-
选择查询中经常使用的列作为索引。
-
对于经常在 WHERE 子句、JOIN 操作、ORDER BY 和GROUP BY 中出现的列建立索引。
-
-
考虑索引的选择性:
-
高选择性的列(即具有大量唯一值的列)是建立索引的好候选。
-
低选择性的列(如性别或状态列,只有几个重复的值)不适合单独建立索引。
-
-
使用复合索引:
-
当查询条件中包含多个列时,可以考虑建立复合索引。
-
确保复合索引中的列顺序与查询条件中的列顺序相匹配。
-
-
限制索引的数量:
-
不要过度索引,每个额外的索引都会增加写操作的成本。
-
定期审查和移除不再使用或很少使用的索引。
-
-
使用前缀索引:
-
对于 CHAR、VARCHAR 类型的列,如果列的长度很长,可以使用前缀索引来节约空间并提高效率。
-
-
考虑索引的维护成本:
-
定期对索引进行维护(如重建或重新组织)可以提升性能,但也要考虑到维护操作的成本。
-
-
避免在索引列上进行计算:
-
尽量避免在 WHERE 子句中对索引列使用函数或计算,这会导致索引失效。
-
-
使用覆盖索引:
-
覆盖索引包含了查询中所有需要的列,这样就可以避免回表查询,提高查询效率。
-
-
监控索引的使用情况:
-
使用数据库的性能监控工具来查看索引的使用情况,并根据实际情况调整索引策略。
-
-
考虑InnoDB特有的索引特性:
-
对于使用 InnoDB 存储引擎的 MySQL 数据库,主键索引通常是最好的选择,因为它们可以避免额外的行 ID 查找。
-
InnoDB 会自动创建聚簇索引,所以主键的选择对性能有重要影响。
-
MySql InnoDB 是什么索引
InnoDB 是 MySQL 数据库的一个流行的存储引擎,它支持事务、行级锁定和外键约束。InnoDB 使用几种不同类型的索引来优化数据库性能:
-
主键索引(Primary Key Index):
-
InnoDB 会自动创建一个名为 PRIMARY 的索引,用于主键列。
-
主键索引是唯一的,并且每个表只能有一个主键索引。
-
主键索引是聚簇索引(Clustered Index)的一种,意味着数据行按照主键的顺序物理存储在磁盘上。
-
-
唯一索引(Unique Index):
-
唯一索引确保索引列中的每个值都是唯一的。
-
可以在表中的任何列或列组合上创建唯一索引。
-
-
辅助索引(Secondary Index):
-
辅助索引是非主键索引,可以创建在任何列或列组合上。
-
辅助索引的叶节点包含了索引列的值和对应行的主键值,这样可以通过辅助索引找到对应行的主键,然后通过主键索引找到完整的数据行。
-
-
全文索引(Full-text Index):
-
全文索引用于全文搜索,适用于 CHAR、VARCHAR 或 TEXT列。
-
全文索引可以快速查找文本中的关键字,常用于搜索引擎和文档管理系统。
-
-
覆盖索引(Covering Index):
-
当一个索引包含了查询所需的所有列时,称为覆盖索引。
-
使用覆盖索引可以避免回表查询,从而提高查询性能。
-
-
前缀索引(Prefix Index):
-
对于字符类型的列,如果列的长度很长,可以使用前缀索引来节约空间并提高效率。
-
前缀索引是基于列的前缀创建的,而不是整个列的值。
-
InnoDB 存储引擎特别优化了聚簇索引的性能,因为聚簇索引决定了数据在磁盘上的物理存储顺序。选择合适的主键对于 InnoDB 表来说非常重要,因为它会影响到整个表的性能。通常,使用自增的整数作为主键是一个好的选择,因为它可以保证索引的顺序插入和最小的页面分裂。InnoDB 还支持一些高级的索引特性,如索引条件推送(Index Condition Pushdown)、索引合并(Index Merge)等,这些特性可以在特定情况下提高查询性能。
-
限流算法
在实际应用中,每个系统或者服务都有其处理能力的极限(瓶颈),即便是微服务中有集群和分布式的夹持,也不能保证系统能应对任何大小的流量,因此,系统为了自保,需要对处理能力范围以外的流量进行“特殊照顾”(比如,丢弃请求或者延迟处理),从而避免系统卡死、崩溃或不可用等情况,保证系统整体服务可用。
令牌桶算法
令牌桶算法(Token Bucket Algorithm)是计算机网络和电信领域中常用的一种简单方法,用于流量整形和速率限制。它旨在控制系统在某个时间段内可以发送或接收的数据量,确保流量符合指定的速率。
令牌桶算法的核心思路:系统按照固定速度往桶里加入令牌,如果桶满则停止添加。当有请求到来时,会尝试从桶里拿走一个令牌,取到令牌才能继续进行请求处理,没有令牌就拒绝服务。示意图如下:
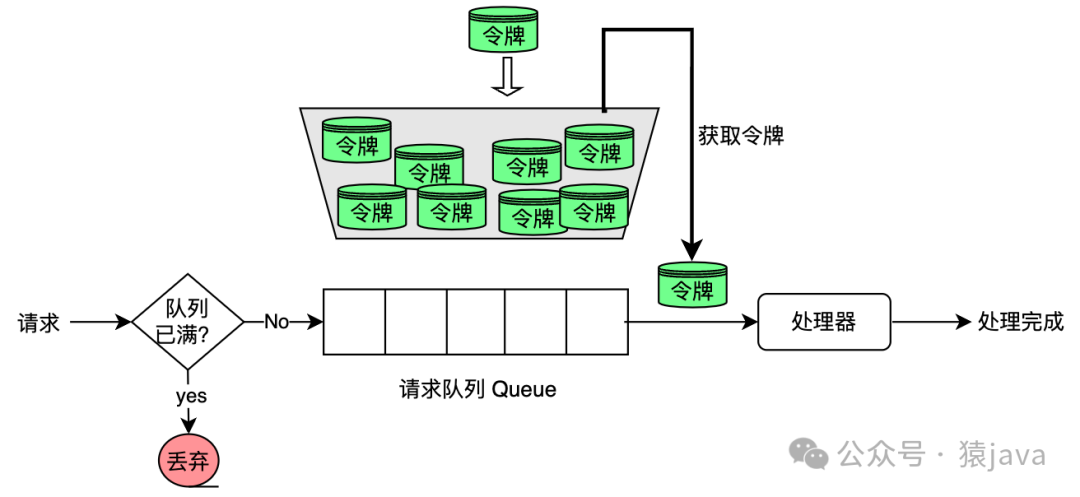
令牌桶法的几个特点:
-
令牌桶容量固定,即系统的处理能力阈值
-
令牌放入桶内的速度固定
-
令牌从桶内拿出的速度根据实际请求量而定,每个请求对应一个令牌
-
当桶内没有令牌时,请求进入等待或者被拒绝
令牌桶算法主要用于应对突发流量的场景,在 Java语言中使用最多的是 Google的 Guava RateLimiter,下面举几个例子来说明它是如何应对突发流量:
示例1
import java.util.concurrent.TimeUnit;
public class RateLimit {
public static void main(String[] args) {
RateLimiter limiter = RateLimiter.create(5); // 每秒创建5个令牌
System.out.println("acquire(5), wait " + limiter.acquire(5) + " s"); // 全部取走 5个令牌
System.out.println("acquire(1), wait " + limiter.acquire(1) + " s");// 获取1个令牌
boolean result = limiter.tryAcquire(1, 0, TimeUnit.SECONDS); // 尝试获取1个令牌,获取不到则直接返回
System.out.println("tryAcquire(1), result: " + result);
}
}示例代码运行结果如下:
acquire(5), wait 0.0 s
acquire(1), wait 0.971544 s
tryAcquire(1), result: false
桶中共有 5个令牌,acquire(5)返回0 代表令牌充足无需等待,当桶中令牌不足,acquire(1)等待一段时间才获取到,当令牌不足时,tryAcquire(1)不等待直接返回。
示例2
import com.google.common.util.concurrent.RateLimiter;
public class RateLimit {
public static void main(String[] args) {
RateLimiter limiter = RateLimiter.create(5);
System.out.println("acquire(10), wait " + limiter.acquire(10) + " s");
System.out.println("acquire(1), wait " + limiter.acquire(1) + " s");
}
}示例代码运行结果如下:
acquire(10), wait 0.0 s
acquire(1), wait 1.974268 s
桶中共有 5个令牌,acquire(10)返回0,和示例似乎有点冲突,其实,这里返回0 代表应对了突发流量,但是 acquire(1)
却等待了 1.974268秒,这代表 acquire(1)的等待是时间包含了应对突然流量多出来的 5个请求,即 1.974268 = 1 + 0.974268。
为了更好的验证示例2的猜想,我们看示例3:
示例3
import com.google.common.util.concurrent.RateLimiter;
import java.util.concurrent.TimeUnit;
public class RateLimit {
public static void main(String[] args) throws InterruptedException {
RateLimiter limiter = RateLimiter.create(5);
System.out.println("acquire(5), wait " + limiter.acquire(5) + " s");
TimeUnit.SECONDS.sleep(1);
System.out.println("acquire(5), wait " + limiter.acquire(5) + " s");
System.out.println("acquire(1), wait " + limiter.acquire(1) + " s");
}
}示例代码运行结果如下:
acquire(5), wait 0.0 s
acquire(5), wait 0.0 s
acquire(1), wait 0.966104 s
桶中共有 5个令牌,acquire(5)返回0 代表令牌充足无需等待,接着睡眠 1s,这样系统又可以增加5个令牌,
因此,再次 acquire(5)令牌充足返回0 无需等待,acquire(1)需要等待一段时间才能获取令牌。
漏桶算法
漏桶算法(Leaky Bucket Algorithm)的核心思路是:水(请求)进入固定容量的漏桶,漏桶的水以固定的速度流出,当水流入漏桶的速度过大导致漏桶满而直接溢出,然后拒绝请求。示意图如下:
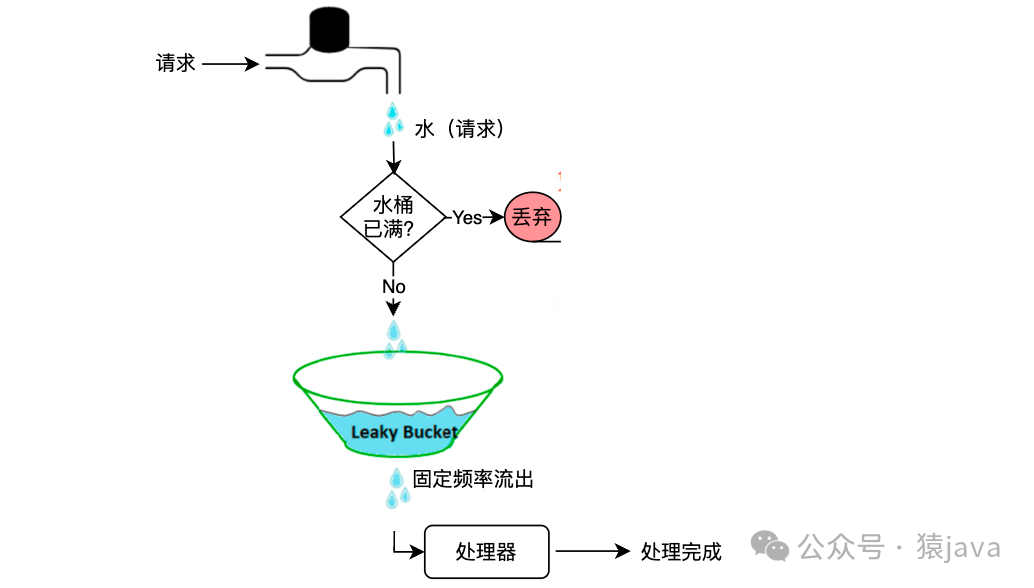
下面为一个 Java版本的漏桶算法示例:
import java.util.concurrent.*;
public class LeakyBucket {
private final int capacity; // 桶的容量
private final int rate; // 出水速率
private int water; // 漏斗中的水量
private long lastLeakTime; // 上一次漏水的时间
public LeakyBucket(int capacity, int rate) {
this.capacity = capacity;
this.rate = rate;
this.water = 0;
this.lastLeakTime = System.currentTimeMillis();
}
public synchronized boolean allowRequest(int tokens) {
leak(); // 漏水
if (water + tokens <= capacity) {
water += tokens; // 漏斗容量未满,可以加水
return true;
} else {
return false; // 漏斗容量已满,无法加水
}
}
private void leak() {
long currentTime = System.currentTimeMillis();
long timeElapsed = currentTime - lastLeakTime;
int waterToLeak = (int) (timeElapsed * rate / 1000); // 计算经过的时间内应该漏掉的水量
water = Math.max(0, water - waterToLeak); // 漏水
lastLeakTime = currentTime; // 更新上一次漏水时间
}
public static void main(String[] args) {
LeakyBucket bucket = new LeakyBucket(10, 2); // 容量为10,速率为2令牌/秒
int[] packets = {2, 3, 1, 5, 2, 10}; // 要发送的数据包大小
for (int packet : packets) {
if (bucket.allowRequest(packet)) {
System.out.println("发送 " + packet + " 字节的数据包");
} else {
System.out.println("漏桶已满,无法发送数据包");
}
try {
TimeUnit.SECONDS.sleep(1); // 模拟发送间隔
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
漏桶算法的几个特点:
-
漏桶容量固定
-
流入(请求)速度随意
-
流出(处理请求)速度固定
-
桶满则溢出,即拒绝新请求(限流)
计数器算法
计数器是最简单的限流方式,主要用来限制总并发数,主要通过一个支持原子操作的计数器来累计 1秒内的请求次数,当 秒内计数达到限流阈值时触发拒绝策略。每过 1秒,计数器重置为 0开始重新计数。比如数据库连接池大小、线程池大小、程序访问并发数等都是使用计数器算法。
如下代码就是一个Java版本的计数器算法示例,通过一个原子计算器 AtomicInteger来记录总数,如果请求数大于总数就拒绝请求,否则正常处理请求:
import java.util.concurrent.atomic.AtomicInteger;
public class CounterRateLimiter {
private final int limit; // 限流阈值
private final long windowSizeMs; // 时间窗口大小(毫秒)
private AtomicInteger counter; // 请求计数器
private long lastResetTime; // 上次重置计数器的时间
public CounterRateLimiter(int limit, long windowSizeMs) {
this.limit = limit;
this.windowSizeMs = windowSizeMs;
this.counter = new AtomicInteger(0);
this.lastResetTime = System.currentTimeMillis();
}
public boolean allowRequest() {
long currentTime = System.currentTimeMillis();
// 如果当前时间超出了时间窗口,重置计数器
if (currentTime - lastResetTime > windowSizeMs) {
counter.set(0);
lastResetTime = currentTime;
}
// 检查计数器是否超过了限流阈值
return counter.incrementAndGet() <= limit;
}
public static void main(String[] args) {
CounterRateLimiter rateLimiter = new CounterRateLimiter(3, 1000); // 每秒最多处理3个请求
for (int i = 0; i < 10; i++) {
if (rateLimiter.allowRequest()) {
System.out.println("允许请求 " + (i + 1));
} else {
System.out.println("限流,拒绝请求 " + (i + 1));
}
try {
Thread.sleep(200); // 模拟请求间隔
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
滑动窗口算法
滑动窗口算法是一种常用于限流和统计的算法。它基于一个固定大小的时间窗口,在这个时间窗口内统计请求的数量,
并根据设定的阈值来控制流量。比如,TCP协议就使用了该算法
以下是一个简单的 Java 示例实现滑动窗口算法:
import java.util.concurrent.atomic.AtomicInteger;
public class SlidingWindowRateLimiter {
private final int limit; // 限流阈值
private final long windowSizeMs; // 时间窗口大小(毫秒)
private final AtomicInteger[] window; // 滑动窗口
private long lastUpdateTime; // 上次更新窗口的时间
private int pointer; // 指向当前时间窗口的指针
public SlidingWindowRateLimiter(int limit, long windowSizeMs, int granularity) {
this.limit = limit;
this.windowSizeMs = windowSizeMs;
this.window = new AtomicInteger[granularity];
for (int i = 0; i < granularity; i++) {
window[i] = new AtomicInteger(0);
}
this.lastUpdateTime = System.currentTimeMillis();
this.pointer = 0;
}
public synchronized boolean allowRequest() {
long currentTime = System.currentTimeMillis();
// 计算时间窗口的起始位置
long windowStart = currentTime - windowSizeMs + 1;
// 更新窗口中过期的计数器
while (lastUpdateTime < windowStart) {
lastUpdateTime++;
window[pointer].set(0);
pointer = (pointer + 1) % window.length;
}
// 检查窗口内的总计数是否超过限流阈值
int totalRequests = 0;
for (AtomicInteger counter : window) {
totalRequests += counter.get();
}
if (totalRequests >= limit) {
return false; // 超过限流阈值,拒绝请求
} else {
window[pointer].incrementAndGet(); // 记录新的请求
return true; // 允许请求
}
}
public static void main(String[] args) {
SlidingWindowRateLimiter rateLimiter = new SlidingWindowRateLimiter(10, 1000, 10); // 每秒最多处理10个请求
for (int i = 0; i < 20; i++) {
if (rateLimiter.allowRequest()) {
System.out.println("允许请求 " + (i + 1));
} else {
System.out.println("限流,拒绝请求 " + (i + 1));
}
try {
Thread.sleep(100); // 模拟请求间隔
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
Redis + Lua分布式限流
Redis + Lua属于分布式环境下的限流方案,主要利用的是Lua在 Redis中运行能保证原子性。如下示例为一个简单的Lua限流脚本:
local key = KEYS[1]
local limit = tonumber(ARGV[1])
local current = tonumber(redis.call('get', key) or "0")
if current + 1 > limit then
return 0
else
redis.call("INCRBY", key, 1)
redis.call("EXPIRE", key, 1)
return 1
end
脚本解释:
-
KEYS[1]:限流的键名,注意,在Lua中,下角标是从 1开始
-
ARGV[1]:限流的最大值
-
redis.call(‘get’, key):获取当前限流计数。
-
redis.call(‘INCRBY’, key, 1):增加限流计数。
-
redis.call(‘EXPIRE’, key, 1):设置键的过期时间为 1 秒。
三方限流工具
当我们自己无法实现比较好的限流方案时,成熟的三方框架就是我们比较好的选择,下面列出两个 Java语言比较优秀的框架。
resilience4j
resilience4j 是一个轻量级的容错库,提供了限流、熔断、重试等功能。限流模块 RateLimiter 提供了灵活的限流配置,其优点如下:
-
集成了多种容错机制
-
支持注解方式配置
-
易于与 Spring Boot集成
Sentinel
Sentinel 是阿里巴巴开源的一个功能全面的流量防护框架,提供限流、熔断、系统负载保护等多种功能。其优点如下:
-
功能全面,适用于多种场景
-
强大的监控和控制台
-
与 Spring Cloud 深度集成
总结
本文讲述了以下几种限流方式:
-
计数器
-
滑动窗口
-
漏桶
-
令牌桶
-
Redis + Lua 分布式限流
-
三方限流工具
上面的限流方式,主要是针对服务器进行限流,除此之外,我们也可以对客户端进行限流, 比如验证码,答题,排队等方式。另外,我们也会在一些中间件上进行限流,比如Apache、Tomcat、Nginx等。
在实际的开发中,限流场景略有差异,限流的维度也不一样,比如,有的场景需要根据请求的 URL来限流,有的会对 IP地址进行限流、另外,设备ID、用户ID 也是限流常用的维度,因此,我们需要结合真实业务场景灵活的使用限流方案。
@Transactional(readOnly=true) 性能提升
4、MySQL中varchar(50)和varchar(500)区别是什么?
来源:https://cloud.tencent.com/developer/article/2356077
@Transactional(readOnly = true)是如何工作的,为什么使用它可以提高性能?
首先,让我们看一下事务接口。
boolean readOnly() default false;
可以看到 readOnly = true 选项允许优化。事务管理器将使用只读选项作为提示。用于事务管理器的JpaTransactionManager。
@Override
protected void doBegin(Object transaction, TransactionDefinition definition) {
JpaTransactionObject txObject = (JpaTransactionObject) transaction;
// Delegate to JpaDialect for actual transaction begin.
Object transactionData = getJpaDialect().beginTransaction(em,
new JpaTransactionDefinition(definition, timeoutToUse, txObject.isNewEntityManagerHolder()));
}
在JpaTransactionManager中,doBegin方法委托JpaDialect来开始实际的事务,并在JpaDialect中调用beginTransaction。让我们来看看HibernateJpaDialect类。
@Override
public Object beginTransaction(EntityManager entityManager, TransactionDefinition definition)
throws PersistenceException, SQLException, TransactionException {
// Adapt flush mode and store previous isolation level, if any.
FlushMode previousFlushMode = prepareFlushMode(session, definition.isReadOnly());
if (definition instanceof ResourceTransactionDefinition &&
((ResourceTransactionDefinition) definition).isLocalResource()) {
if (definition.isReadOnly()) {
session.setDefaultReadOnly(true);
}
}
}
protected FlushMode prepareFlushMode(Session session, boolean readOnly) throws PersistenceException {
FlushMode flushMode = session.getHibernateFlushMode();
if (readOnly) {
// We should suppress flushing for a read-only transaction.
if (!flushMode.equals(FlushMode.MANUAL)) {
session.setHibernateFlushMode(Flusode.MANUAL);
return flushMode;
}
}
else {
// We need AUTO or COMMIT for a non-read-only transaction.
if (flushMode.lessThan(FlushMode.COMMIT)) {
session.setHibernateFlushMode(FlushMode.AUTO);
return flushMode;
}
}
// No FlushMode change needed...
return null;
}
在JpaDialect中,我们可以看到JpaDialect使用只读选项准备刷新模式。当 readOnly = true 时, JpaDialect 禁止刷新。此外,您还可以看到,在准备刷新模式后,session.setDefaultReadOnly(true)将session的readOnly属性设置为true。
void setDefaultReadOnly(boolean readOnly);
在Session接口中,通过将readOnly属性设置为true,将不会对只读实体进行脏检查,也不会维护持久状态的快照。此外,只读实体的更改也不会持久化。
总而言之,这些是在 Hibernate 中使用@Transactional(readOnly = true)所得到的结果
-
性能改进:只读实体不进行脏检查
-
节省内存:不维护持久状态的快照
-
数据一致性:只读实体的更改不会持久化
-
当我们使用主从或读写副本集(或集群)时,
@Transactional(readOnly = true)使我们能够连接到只读数据库
2.当使用 JPA 时,是否应该总是将@Transactional(readOnly = true)添加到服务层的只读方法?
当使用@Transactional(readOnly = true)时,我们可以有很多优势。但是,将@Transactional(readOnly = true)添加到服务层的只读方法是否合适?
-
无限制地使用事务可能会导致数据库死锁、性能和吞吐量下降。
-
由于一个事务占用一个DB连接,所以
@Transactional(readOnly = true)添加到Service层的方法可能会导致DB连接饥饿。
第一个问题很难重现,来测试来检查第二个问题。
@Transactional(readOnly = true)
public List<UserDto> transactionalReadOnlyOnService(){
List<UserDto> userDtos = userRepository.findAll().stream()
.map(userMapper::toDto)
.toList();
timeSleepAndPrintConnection();
return userDtos;
}
public List<UserDto> transactionalReadOnlyOnRepository(){
List<UserDto> userDtos = userRepository.findAll().stream()
.map(userMapper::toDto)
.toList();
timeSleepAndPrintConnection();
return userDtos;
}
在服务层测试了两个方法,一个是@Transactional(readOnly = true),另一个是存储库层中的@Transactional (readOnly = true)(在 SimpleJpaRepository 中,它是 Jpa Respitory 的默认实现,在类的顶部有@Transformational(ready Only),因此 findAll()方法在默认情况下有@transactional(read only = True))。
从DB中获取userInfo并保持线程5秒钟,然后检查该方法何时释放连接。结果如下:
对于服务层方法中的@Transactional(readOnly = true),
activeConnections:0, IdleConnections:10, TotalConnections:10
start transactionalReadOnlyOnService!!
Hibernate:
select
u1_0.id,
u1_0.email,
u1_0.name,
u1_0.profile_file_name
from
users u1_0
activeConnections:1, IdleConnections:9, TotalConnections:10
activeConnections:1, IdleConnections:9, TotalConnections:10
activeConnections:1, IdleConnections:9, TotalConnections:10
activeConnections:1, IdleConnections:9, TotalConnections:10
activeConnections:1, IdleConnections:9, TotalConnections:10
end transactionalReadOnlyOnService!!
activeConnections:0, IdleConnections:10, TotalConnections:10
对于存储库层方法中的@Transactional(readOnly = true),
activeConnections:0, IdleConnections:10, TotalConnections:10
start transactionalReadOnlyOnRepository!!
Hibernate:
select
u1_0.id,
u1_0.email,
u1_0.name,
u1_0.profile_file_name
from
users u1_0
activeConnections:0, IdleConnections:10, TotalConnections:10
activeConnections:0, IdleConnections:10, TotalConnections:10
activeConnections:0, IdleConnections:10, TotalConnections:10
activeConnections:0, IdleConnections:10, TotalConnections:10
activeConnections:0, IdleConnections:10, TotalConnections:10
end transactionalReadOnlyOnRepository!!
activeConnections:0, IdleConnections:10, TotalConnections:10
正如看到的,@Transactional(readOnly = true)一旦查询结果到达,存储库层就会释放连接。然而,@Transactional(readOnly = true)在服务层的方法中直到服务层的方法结束才释放连接。因此,当服务层的方法有需要大量时间的逻辑时要小心,因为它可以长时间持有数据库连接,这可能会导致数据库连接匮乏。
总结
@Transactional(readOnly = true)有很多优点。
-
性能改进:只读实体不进行脏检查
-
节省内存:不维护持久状态的快照
-
数据一致性:只读实体的更改不会持久化
-
当我们使用主从或读写副本集(或集群)时,
@Transactional(readOnly = true)使我们能够连接到只读数据库
但是,您还应该记住,@Transactional(readOnly = true)在服务层的方法中可能会导致数据库死锁、性能低下和数据库连接匮乏。
当您需要将只读查询仅仅作为一个事务执行时,请毫不犹豫选择的在服务层的方法中使用@Transactional(readOnly = true),如果你的服务层的方法中有大量其他逻辑方法时,就要做取舍。















 423
423











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









