







100万用户,抢10万优惠券,如何设计?
一、10Wqps抢券系统的功能分析
首先看看,电商系统(Electronic Commerce Systems)的促销手段:
-
优惠券
-
拼团
-
砍价
-
老带新
说到电商平台上,无人不知优惠券体系,它是一种常见的促销方式,所以说, 优惠券是电商常见的营销手段,具有灵活的特点。
优惠券 的功能:在规定的周期内,购买对应商品类型和额度商品时,下单结算时会减免一定金额。
优惠券既可以作为促销活动的载体,也是重要的引流入口。
一般来说,优惠券系统是 商城营销模块中一个重要组成部分,哪怕早在 商城单体应用时代,优惠券就是其中核心模块之一。
在电商系统中 优惠券的种类,主要有:
-
代金券
可以直接抵扣商品金额,不找零;任意金额可用(可能会导致零元单,看业务是否能接受);可以同非商品券叠加
-
满减券
可以抵扣商品金额,有使用门槛;门槛金额需大于优惠金额;可以同非商品券叠加
-
折扣券
可以抵扣商品金额,有使用门槛,需要设置封顶金额;可以同非商品券叠加
-
运费券
不可以抵扣商品金额;只能够抵扣运费;可以同非商品券叠加
在电商系统中 优惠券 涉及到两个核心功能:
(1)发放券
-
谁能领?
所有用户 or 指定的用户
-
领取上限
一个优惠券最多能领取多少张?
-
领取方式
用户主动领取 or 自动发放被动领取
(2)核销券
-
作用范围
商品、商户、类目
-
计算方式
是否互斥、是否达到门槛等
V1.0版本的抢券系统需求拆解
最为简单的一个抢券系统的功能,保护两个部分:
-
tob部分:配置券,会涉及到券批次(券模板)创建,券模板的有效期以及券的库存信息
-
toc部分:发券,会涉及到券记录的创建和管理(过期时间,状态)
因此,我们可以将需求先简单拆解为两部分:
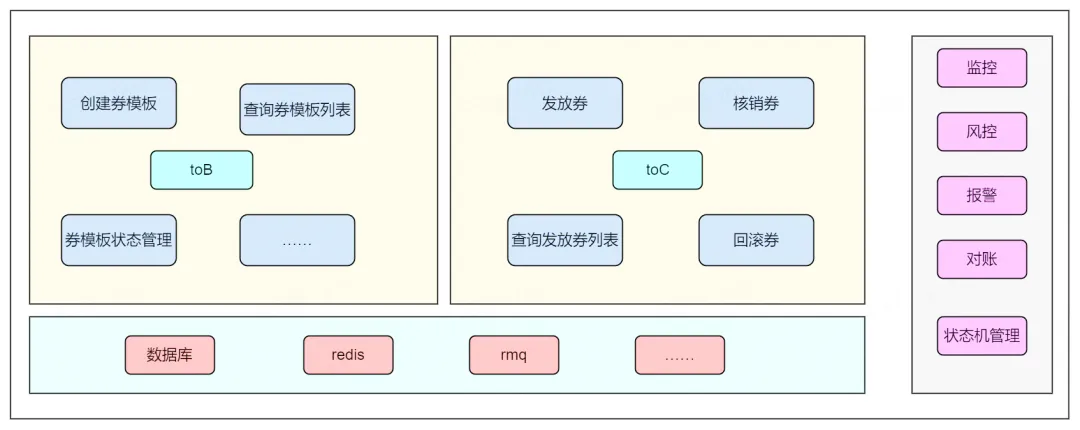
同时,无论是券模板还是券记录,都需要开放查询接口,支持券模板/券记录的查询。
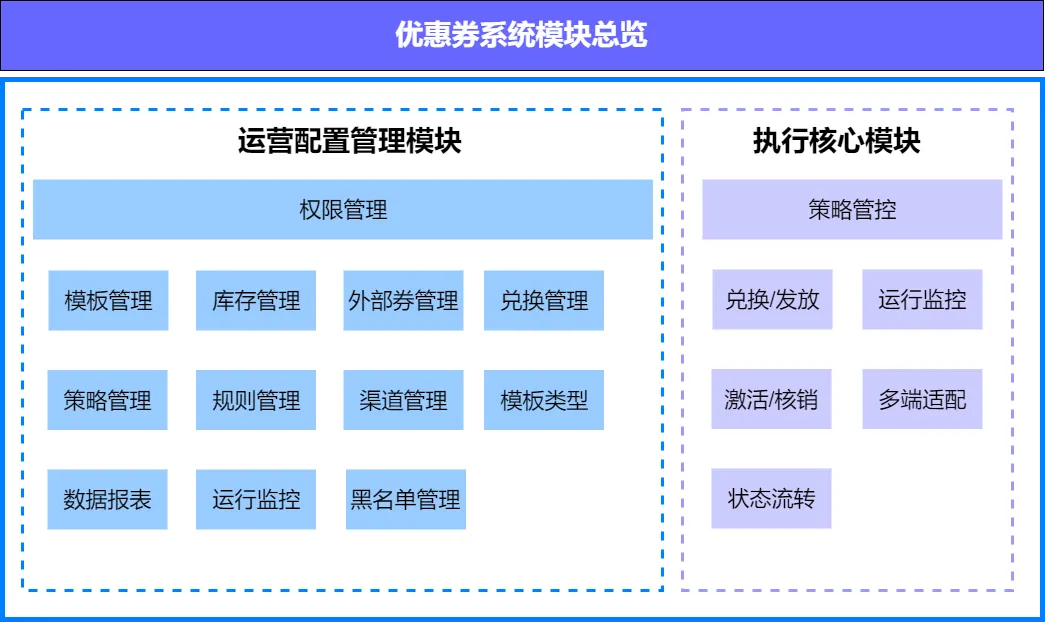
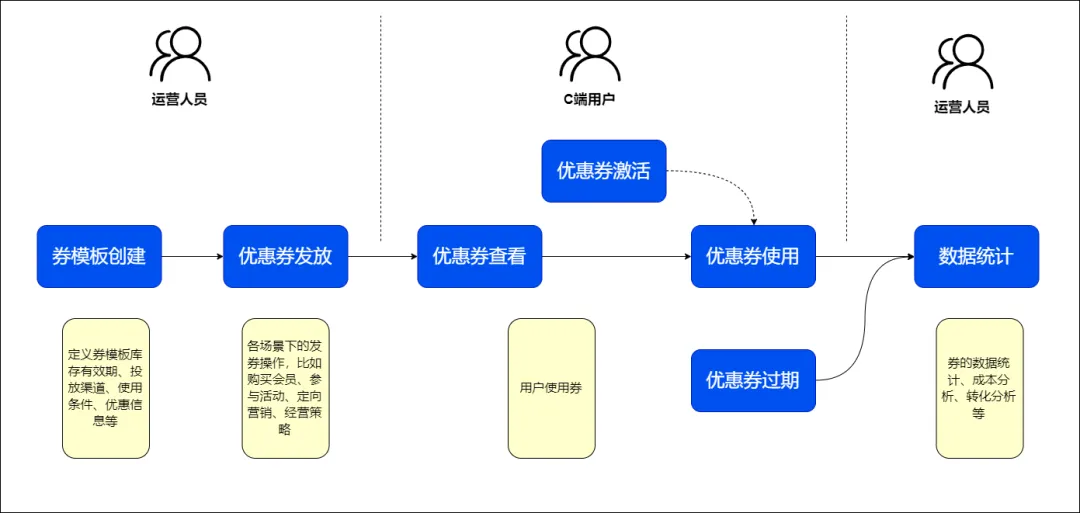
V1.0版本的模块介绍
优惠券系统主要分为tob部分 运营端的运营配置管理模块和toc部分执行端的执行核心模块。
tob部分 优惠券运营配置管理模块提供给运营人员操作、管理券权益,回收数据分析。包括
-
模板库存管理、
-
外部券管理、
-
策略规则管理、
-
数据报表等功能。
toc部分 优惠券执行核心模块包括:
-
优惠券的兑换发放、
-
使用核销、
-
状态流转等功能,
-
提供统一的API接口,供上游各业务系统调用,参与到各产品功能环节。
同时在运行中有完善的运行监控和有效的策略管控能力,提供保障。
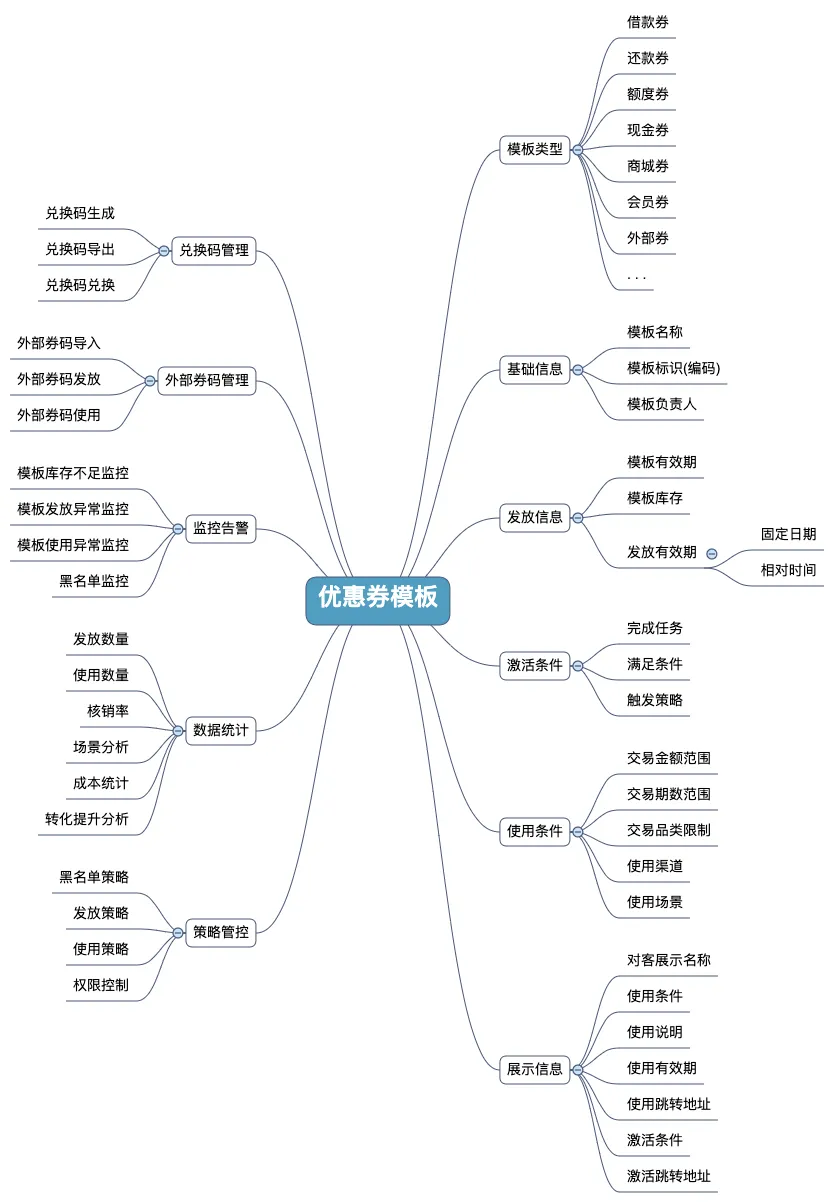
优惠券模板管理的设计
优惠券信息的定义是基于对应模板的,一张优惠券一般有这些要素:
-
券的名称描述等信息
-
券的类型
-
应该在什么条件下能使用
-
使用时优惠减免多少。
这些要素被抽象为券模板,在不同模板中定义了券的不同元素。
模板主要包含了两部分信息:模板配置和运营管理。
模板配置主要定义了模板使用的业务配置,比如模板类型、基础信息、发放信息、激活条件、使用条件、展示信息、兑换码管理、外部券管理等。
运营管理是对模板的使用、运行进行的监控统计分析,包含监控告警、数据统计、策略管控。
抢券系统的业务流程设计
优惠券系统提供统一的 API 接口和 MQ 消息,提供配券、发券、查券、用券的能力,接入到上游各业务系统中。
优惠券的使用规则设计
1.叠加规则
-
一般情况下,商品券我们分为商家自有券和平台发放券,都为商品券,平台的自有券是可以和商家的自行发放的券进行叠加的,但是商家券与 商家券不能叠加,平台券和平台券不能叠加,所以有
商家券+平台券
-
商品券和运费券是可以叠加的,那么我们可以知道,叠加规则可以
商家券+平台券+运费券
-
有时候,双十一等大促期间,电商平台还会出一些神券,这些券也是可以和上边的券叠加的,给到用户更多的优惠
商家券+平台券+运费券+神券
2.命中规则
对于用户的优惠券来说,可能有很多,但是最优的搭配只能有一个,所以在选中最优的优惠券时,我们需要有一些排序条件
命中规则考虑的因素比较多
-
金额
金额是用户最关心的一个点,到底能有多大优惠,一定是体现在金额上,所以我们在搭配优惠券时,一定要把金额最大的,排在第一位
-
时间
优惠券都有有效时间,有可能有两张券,他们的面额、使用条件等,都一样,那么过期时间就作为一个排序条件,最先过期的优先
-
类型
可能我们的多张优惠券计算出来的金额都一样,时间也都一样,那么券的类型就很重要了。
一般来说满减券要优先,折扣券次之,代金券最后。
因为满减券有门槛,有最大值,但是折扣券可能封顶的优惠更大,而代金券又没有门槛。
也就是说,满减券是限制最多的,优先使用掉。
-
商品
有些券有商品的适用范围,有些券是全品类的,那么我们优先使用限制商品的券。
-
渠道
有些券限制了APP还是小程序使用,有些是全渠道通用的券,那么优先使用限制渠道的券
优惠卷的生命周期设计
优惠券各状态说明
| 券状态 | 说明 |
| 待激活 |
发放给用户时券的初始状态,需用户完成任务或达到一定条件后自动触发激活券,激活后才能使用。 |
| 待使用 |
发放给用户时券的初始状态;由用户自己激活的券;可直接在各场景下使用。 |
| 已使用 |
用户已使用的券。 |
| 已过期 |
发放给用户,直到过期都未使用的券。 |
| 锁定 |
被锁定的券,在订单流转过程中会出现。比如已下单未付款时,使用的券被锁定。 |
| 已回收 |
被回收的券,用户不可使用。比如活动资格被取消后,回收已发放的券。 |
V2.0版本的抢券系统需求演进
V1.0版本 优惠券最早和商城耦合在一个系统中
随着商城的不断发展,营销活动力度加大,优惠券使用场景增多,优惠券系统逐渐开始“力不从心”,暴露了很多问题:
-
海量优惠券的发放,达到优惠券单库、单表存储瓶颈。
-
与商城系统的高耦合,直接影响了商城整站接口性能。
-
优惠券的迭代更新受限于商城的版本安排。
-
针对多品类优惠券,技术层面没有沉淀通用优惠券能力。
为了解决以上问题,V2.0优惠券系统进行了系统独立,提供通用的优惠券服务,独立后的系统架构如下:
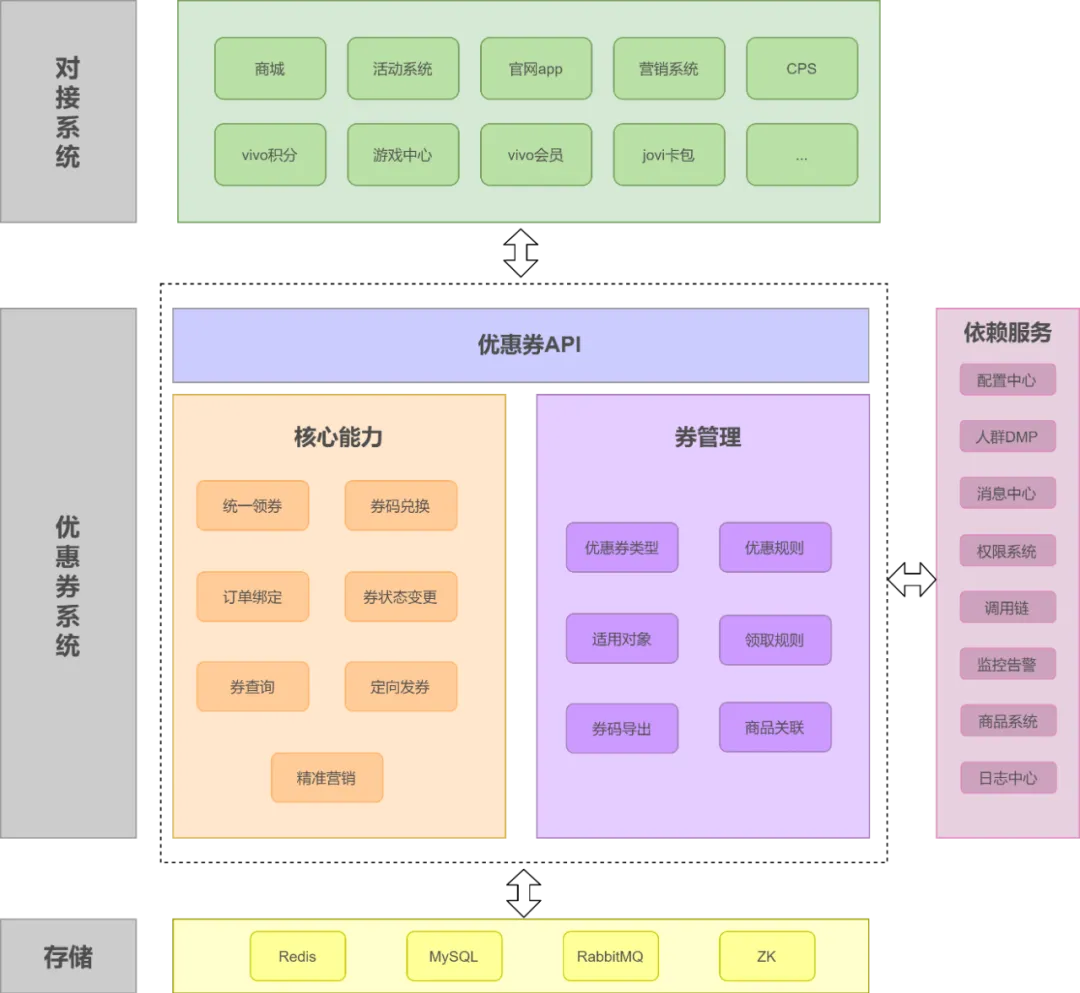
V2.0优惠券系统覆盖了优惠券的4个核心要点:创、发、用、计。
-
“创”指优惠券的创建,包含各种券规则和使用门槛的配置。
-
“发”指优惠券的发放,优惠券系统提供了多种发放优惠券的方式,满足针对不同人群的主动发放和被动发放。
-
“用”指优惠券的使用,包括正向购买商品及反向退款后的优惠券回退。
-
“计”指优惠券的统计,包括优惠券的发放数量、使用数量、使用商品等数据汇总。
除了提供常见的优惠券促销玩法外,优惠券系统还以优惠券的形式作为其他一些活动或资产的载体,比如手机类商品的保值换新、内购福利、与外部广告商合作发放优惠券等。
以下为V2.0版本的抢券系统的展示:
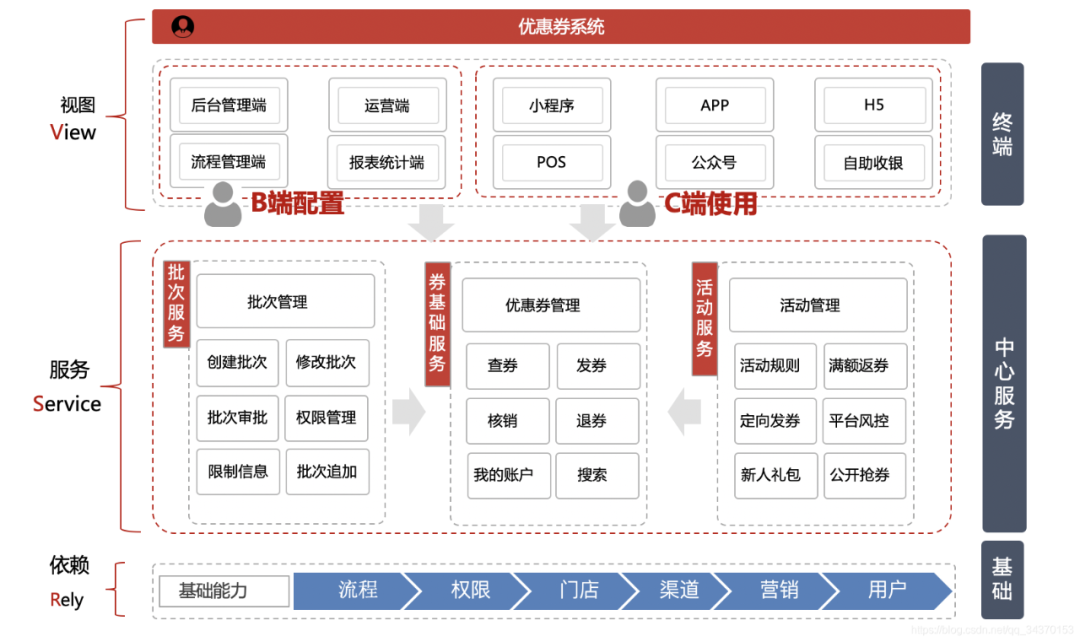
优惠券的依赖方和调用方
依赖方
-
商品
好多优惠券都是限制哪些商品可用,商品服务作为一个基础服务,是优惠券系统需要依赖的
-
商户
有些券是商家券,限制了哪个商家可用,比如lining可用,nike不可用,我们要识别到是哪个商户,所以需要依赖商户系统
-
职能
在权限控制和用户的有效性判断上,需要依赖职能系统,做校验相关的处理
-
审批流
在创建优惠券的时候,我们需要有流程化的管控,需要对接审批流
调用方
-
APP、小程序
C端作为流量的入口,需要展示优惠券的信息数据,承接了优惠券展示的所有能力
从领券开始,到提交订单时的查询可以使用的优惠券,到提交订单后的核销优惠券,最后在我的账户里边查询个人优惠券信息,完成了一整个C端的生命周期处理,属于最关键的调用方。
-
订单
订单系统,在提交订单时,需要向优惠券系统来校验,券的状态等数据,如果订单金额符合满额返券的金额。那么还需要调用优惠券系统来向用户发券
-
营销工具
一些营销工具多种多样,比如新人礼包等,需要调用优惠券系统来获取券的信息
二、抢券系统的非功能需求
如何从零搭建10万级 QPS 大流量、高并发优惠券系统?
大促期间,多个业务方都有发放优惠券的需求,且对发券的 QPS 量级有明确的需求。
所有的优惠券发放、核销、查询都需要一个高并发架构 来承载。
因此,需要设计、开发一个能够支持十万级 QPS 的券系统,并且对优惠券完整的生命周期进行维护。
NFR难题1:如何实现10Wqps的领券能力?
以多点APP为例,来看看如何实现10Wqps的领券能力?
优惠券并不是每个人都可以领取的,有很多限制条件,比如”有些优惠券只有新人可以领“,”有些优惠券一天只能领一张“,”有些券需要完成任务或达到一定门槛才可以领“,等等。
我们简单看下优惠券领取的流程图:

优惠券的领取,逻辑相对简单些,需要关注券模板、领取记录,用户标签等几个维度校验。
如果满足条件就可以给用户发放优惠券。
券模板校验:
-
优惠券模板本身设置领取时间,只有在区间时间内才有机会领取优惠券,当然是否能最终领取还取决于其他条件。
-
券库存。正如商品一样,没有库存的商品是无法下单售卖
-
当日发放限制。为了防止用户对券哄抢,同时为了延长活动的黏性效果,会限量每天发放优惠券数量。
优惠券不是随便乱发的,毕竟要计入公司的支出成本,一旦涉及到钱的问题便是个严肃的问题。
定位好用户群体,什么样的优惠券发给什么类型的用户才能获得最大收益。所以我们在创建优惠券时,除了设置适用的商品范围,还要限制优惠券的用户类型。人尽其用,物尽其才。
适用商品范围一般在页面展示或下单时才用到。而用户类型则相反,需要前置控制,也就是说在用户领取时校验,一旦用户领取成功就属于用户个人财产,只要没有过期都可以使用。
用户领取记录校验:
-
根据券模板的领取条件限制,以及用户的领取记录,判断是否还可以领取
用户标签校验:
-
有些券限制只有新人才可以领取。如:新人专享活动
-
券也可以跟用户等级挂钩,只有达到设置的等级才可以领取
-
黑名单用户。用风控挂钩,识别风险刷券用户
-
自定义用户。可以给用户打一些特定标签。并针对该类型的用户发放。
技术挑战:如何实现10Wqps的领券能力?
-
风控如何接入,领券接口的10Wqps,对风控接口性能有较高要求
-
券缓存如何设计。一般会按变化的频率做拆分。券模板本身内容可以封装一个缓存模型。其中的券库存由于经常变化,需要单独剥离处理,采用缓存+数据库。但如何保证两者的数据一致性需要我们特别关注
-
领取记录同样采用缓存+数据库
-
用户标签。由于不用的优惠券会限制发放给不用的用户人群,所以我们会根据券模板设置的用户标,采用策略模式,调用外部服务,实时查询用户是否满足领取条件。
如何实现10Wqps的领券能力?
NFR难题2:如何实现10Wqps的算券能力?
以 多点APP为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5985
5985

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









