









数据一致性通常讲的主要是数据存储系统,主从MySQL、分布式存储系统等,如何保证数据一致性,比如说主从一致性,副本一致性,保证不同的时间或者相同的请求访问这种主从数据库时访问的数据是一致性的,不会这次访问是结果 A 下次是结果 B。
- 什么是MySQL主从同步?
MySQL主从同步是一种数据复制方式,它可以将一个MySQL数据库的数据复制到另一个MySQL数据库中,从而保证数据的备份和高可用性。在一个MySQL主从同步的架构中,主数据库负责写入数据,而从数据库则负责读取数据。主数据库将写入的数据复制到从数据库,从数据库可以通过备份数据来提高数据的可用性和可靠性。
- MySQL主从同步的问题
MySQL主从同步可以提高数据的可用性和可靠性,但是在实际应用中,也会遇到一些问题。下面是一些常见的问题:
1. 数据不一致:由于主从同步是异步的,从数据库可能会出现数据不一致的情况。例如,在主数据库中写入了一条数据,但是在从数据库中还没有同步完成,这时如果从数据库查询该数据,就会出现数据不一致的问题。
2. 延迟问题:由于主从同步是异步的,从数据库可能会出现延迟的情况。例如,在主数据库中写入了一条数据,但是在从数据库中还没有同步完成,这时如果从数据库查询该数据,就会出现延迟的问题。
3. 主从切换问题:在主从同步的架构中,如果主数据库出现故障,需要将从数据库切换为主数据库。但是,在切换的过程中,可能会出现数据不一致的情况。
- 如何解决数据不一致问题?
1.半同步复制
办法就是等主从同步完成之后,等主库上的写请求再返回,这就是常说的“半同步复制”。
实现方案
MySQL的半同步复制方案,下面以MySQL为例介绍。
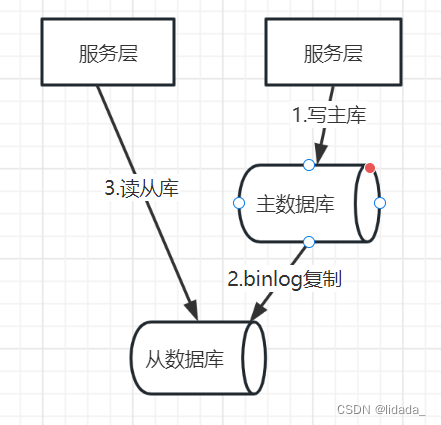
MySQL半同步复制
MySQL的Replication默认是一个异步复制的过程,从MySQL5.5开始,MySQL以插件的形式支持半同步复制,先谈下异步复制,这样可以更好的理解半同步复制。
1)异步复制
MySQL默认的复制是异步的,主库在执行完客户端提交的事务后会立即将结果返给给客户端,并不关心从库是否已经接收并处理,这样就会有一个问题,主如果crash掉了,此时主上已经提交的事务可能并没有传到从库上。
2)半同步复制
介于异步复制和全同步复制之间,主库在执行完客户端提交的事务后不是立刻返回给客户端,而是等待至少一个从库接收到并写到relaylog中才返回给客户端。相对于异步复制,半同步复制提高了数据的安全性,同时它也造成了一定程度的延迟,这个延迟最少是一个TCP/IP往返的时间。所以,半同步复制最好在低延时的网络中使用。
半同步复制原理:
·事务在主库写完binlog后需要从库返回一个已接受,才放回给客户端
·mysql5.5版本以后,以插件的形式存在,需要单独安装
·确保事务提交后binlog至少传输到一个从库
·不保证从库应用完成这个事务的binlog
·性能有一定的降低
·网络异常或从库宕机,卡主库,直到超时或从库恢复
该方案优点:
利用数据库原生功能,比较简单
该方案缺点:
主库的写请求时延会增长,吞吐量会降低
2.数据库中间件

流程:
1)所有的读写都走数据库中间件,通常情况下,写请求路由到主库,读请求路由到从库
2)记录所有路由到写库的key,在主从同步时间窗口内(假设是500ms),如果有读请求访问中间件,此时有可能从库还是旧数据,就把这个key上的读请求路由到主库。
3) 在主从同步时间过完后,对应key的读请求继续路由到从库。
相关的中间件有:
1) canal:是阿里巴巴旗下的一款开源项目,纯Java开发,基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了MySQL。
2) otter:也是阿里开源的一个分布式数据库同步系统,尤其是在跨机房数据库同步方面,有很强大的功能。它是基于数据库增量日志解析,实时将数据同步到本机房或跨机房的mysql/oracle数据库。
两者的区别在于:
otter目前嵌入式依赖canal,部署为同一个jvm,目前设计为不产生Relay Log。
otter目前允许自定义同步逻辑,解决各类需求。
该方案优点:
能保证绝对—致
该方案缺点:
数据库中间件的成本较高
3.缓存记录写key法
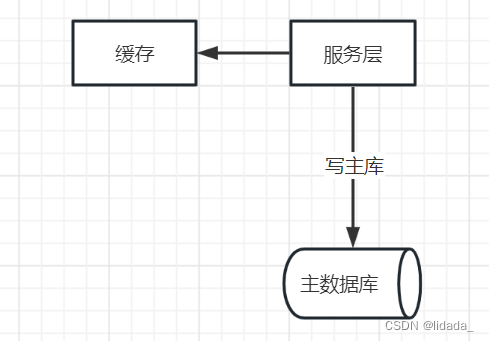
写流程:
1)如果key要发生写操作,记录在cache里,并设置“经验主从同步时间”的cache超时时间,例如500ms
2)然后修改主数据库
读流程:
1)先到缓存里查看,对应key有没有相关数据
2)有相关数据,说明缓存命中,这个key刚发生过写操作,此时需要将请求路由到主库读最新的数据。
3)如果缓存没有命中,说明这个key上近期没有发生过写操作,此时将请求路由到从库,继续读写分离。
该方案优点:
相对数据库中间件,成本较低
该方案缺点:
为了保证“一致性”,引入了一个cache组件,并且读写数据库时都多了缓存操作。
- CAP定理
CAP定理:指的是在一个分布式系统中,Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可同时获得
其中:
一致性(C):指所有节点在同一时刻的数据完全一致。
可用性(A):指服务一直可用,而且响应时间正常。例如,不管什么时候访问X节点和Y节点都可以正常获取数据值,而不会出现问题。
分区容错性(P):指在遇到某节点或网络分区故障时,仍然能够对外提供满足一致性和可用性的服务。例如X节点和Y节点出现故障,但是依然可以很好地对外提供服务。
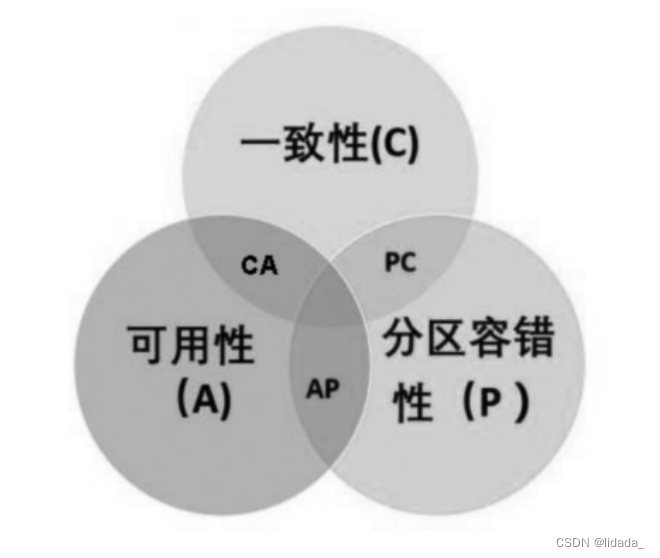
CAP理论就是说在分布式存储系统中,最多只能实现上面的两点。而由于当前的网络硬件肯定会出现延迟丢包等问题,所以分区容忍性是我们必须需要实现的。所以我们只能在一致性和可用性之间进行权衡
CP: 如果不要求A(可用),每个请求都需要在服务器之间保持强一致,而P(分区)会导致同步时间无限延长(也就是等待数据同步完才能正常访问服务),一旦发生网络故障或者消息丢失等情况,就要牺牲用户的体验,等待所有数据全部一致了之后再让用户访问系统
AP:要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。
所以对于注册中心来说只能从CP(优先保证数据一致性)、AP(优先保证数据可用性)中根据实际业务场景选择一种。
CP : 适合支付、交易类,要求数据强一致性,宁可业务不可用,也不能出现脏数据
AP: 互联网业务,比如信息流架构,不要求数据强一致,更想要服务可用
总结来说,CAP 定理认为,一个提供数据服务的存储系统无法同时满足数据一致性、数据可用性、分区容忍性。















 2067
2067











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









