







本文为个人学习过程中的学习笔记,仅供参考。
6 .信号量(semaphore)
一、什么是信号量
信号量是一个计数器,用于多进程对共享数据的访问,信号量的意图在于进程间同步。 信号量以保护临界资源为目的,但他本身也是个临界资源;他控制多个进程对共享资源的访问,通常描述临界资源当中,临界资源的数量,常常被当做锁来使用,防止一个进程访问另外一个进程正在使用的资源 。不用来储存进程间的缓存数据。
信号量是一个特殊的变量,程序对其访问都是原子操作,且只允许对它进行等待(即P(信号变量))和发送(即V(信号变量))信息操作。
二、名词解释
进程互斥:由于各进程要求共享资源,而且有些资源需要互斥使用,因此各进程竞争使用这些资源,进程的这种关系为进程的互斥。也就是说一个资源每次只能被一个进程访问。
进程同步:在访问资源的时候,以某种特定顺序的方式区访问资源,也就是多个进程需要相互配合共同完成一项资源。
临界资源(互斥资源):系统中某些资源一次只允许一个进程使用。
临界区:在进程中涉及到互斥资源的程序段。
原子性:不可被中断的操作,通俗点就是一件事情只会有两种情况,要么是做了,要么就没做。
三、特点:
1. 信号量用于进程间同步,若要在进程间传递数据需要结合共享内存
2. 信号量基于操作系统的PV操作,都是原子操作。
3. 每次对信号量的PV操作不仅限于对信号量值加1或减1,而且可以是加减任意正整数。
4. 支持信号量组
四、信号量的操作
为了获得共享资源,进程需要执行下列操作:
(1)创建一个信号量:这要求调用者指定初始值,对于二值信号量来说,它通常是1,也可是0。
(2)等待一个信号量:该操作会测试这个信号量的值,如果小于等于0,就阻塞。也称为P操作。
(3)挂出一个信号量:该操作将信号量的值加1,也称为V操作。
为了正确地实现信号量,信号量值的测试及减1操作应当是原子操作。为此,信号量通常是在内核中实现的。Linux环境中,有三种类型:Posix(可移植性操作系统接口)有名信号量(使用Posix IPC名字标识)、Posix基于内存的信号量(存放在共享内存区中)、System V信号量(在内核中维护)。这三种信号量都可用于进程间或线程间的同步。
信号量与普通整型变量的区别:
(1)信号量是非负整型变量,除了初始化之外,它只能通过两个标准原子操作:wait(semap) , signal(semap) ; 来进行访问;
(2)操作也被成为PV原语(P来源于荷兰语proberen"测试",V来源于荷兰语verhogen"增加",P表示通过的意思,V表示释放的意思),而普通整型变量则可以在任何语句块中被访问;
信号量与互斥量之间的区别:
(1)互斥量用于线程的互斥,信号量用于线程的同步。这是互斥量和信号量的根本区别,也就是互斥和同步之间的区别。
互斥:是指某一资源同时只允许一个访问者对其进行访问,具有唯一性和排它性。但互斥无法限制访问者对资源的访问顺序,即访问是无序的。
同步:是指在互斥的基础上(大多数情况),通过其它机制实现访问者对资源的有序访问。
在大多数情况下,同步已经实现了互斥,特别是所有写入资源的情况必定是互斥的。少数情况是指可以允许多个访问者同时访问资源
(2)互斥量值只能为0/1,信号量值可以为非负整数。
也就是说,一个互斥量只能用于一个资源的互斥访问,它不能实现多个资源的多线程互斥问题。信号量可以实现多个同类资源的多线程互斥和同步。当信号量为单值信号量是,也可以完成一个资源的互斥访问。
(3)互斥量的加锁和解锁必须由同一线程分别对应使用,信号量可以由一个线程释放,另一个线程得到。
五、原型API
最简单的信号量是只能取0和1的变量,这也是信号量最常见的一种形式,叫做二进制信号量。而可以取多个正整数的信号量被称为通用信号量。
Linux下的信号量函数都是在通用的信号量组上进行操作,而不是在一个单一的信号量上。
#include <sys/sem.h>
// 创建或获取一个信号量组:若成功返回信号量集ID,失败返回-1
int semget(key_t key, int num_sems, int sem_flags);
// 对信号量组进行操作,改变信号量的值:成功返回0,失败返回-1
int semop(int semid, struct sembuf semoparray[], size_t numops);
// 控制信号量的相关信息
int semctl(int semid, int sem_num, int cmd, ...);
1、semget函数
它的作用是创建一个新信号量或取得一个已有信号量。
int semget(key_t key, int num_sems, int sem_flags);
//成功返回一个相应信号量集ID,失败返回-1.
key_t key:整数值,可以理解为文件目录索引值、不同于id为该文件id名。
int num_sems: 指定需要的信号量数目,它的值几乎总是1。
int sem_flags:一组标志,当想要当信号量不存在时创建一个新的信号量 IPC_CREAT|06662、semop函数
它的作用是改变信号量的值,进行PV操作的函数。原型为:
int semop(int sem_id, struct sembuf *sem_opa, size_t num_sem_ops);
sem_id: 是由semget返回的信号量标识符,
struct sembuf *sem_opa:信号量结构体struct sembuf指针,该指针改变后的信号量
size_t num_sem_ops: struct sembuf变量成员数量sembuf结构的定义如下:
struct sembuf{
short sem_num;//除非使用一组信号量,否则它为0
short sem_op;//信号量在一次操作中需要改变的数据,通常是两个数,一个是-1,即P(等待)操作,
//一个是+1,即V(发送信号)操作。
short sem_flg;//通常为SEM_UNDO,使操作系统跟踪信号,
//并在进程没有释放该信号量而终止时,操作系统释放信号量
};由于信号量只能进行两种操作等待和发送信号,即P(sv)和V(sv)
P操作:sem_op= -1 <0,使得共享临界资源上锁,其它进程不得访问
V操作:sem_op= 1 >0,使得共享临界资源解锁,其它进程可以访问
semctl在初始化信号量的时候,union semum结构体中val就是信号量的初始化值,一般==1;
进行PV操作时,semop函数把 struct sembuf结构体中设置好的参数储存,此时val+1或-1,从而达到加锁解锁的目的,控制进程访问。
举个例子,就是两个进程共享信号量sv=val=1,一旦其中一个进程执行了P(sv)操作,它将得到信号量,并可以进入临界区,sem_op使sv减1。而第二个进程将被阻止进入临界区,因为当它试图执行P(sv)时,sv为0,它会被挂起以等待第一个进程离开临界区域并执行V(sv)释放信号量,这时第二个进程就可以恢复执行。
3、semctl函数
该函数用来直接控制信号量信息,初始化和删除信号量
int semctl(int sem_id, int sem_num, int cmd, ...);int sem_id:信号量标示符
int sem_num:信号量集中有多个信号量,表示第几个信号量 0-*
int cmd:
| cmd | SETVAL | 用来把信号量初始化为一个已知的值。p 这个值通过union semun中的val成员设置,其作用是在信号量第一次使用前对它进行设置。 |
| IPC_RMID | 用于删除一个已经无需继续使用的信号量标识符。 |

如果有第四个参数,它通常是一个union semum结构,定义如下:
union semun{
int val;
struct semid_ds *buf;
unsigned short *arry;
};//该结构体需要手动设置当cmd设置信号量初值时,第4个参数 的val =初值。 直接填写变量名:tmpsem
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
#include <unistd.h>
union semun {
int val; /* Value for SETVAL */
struct semid_ds *buf; /* Buffer for IPC_STAT, IPC_SET */
unsigned short *array; /* Array for GETALL, SETALL */
struct seminfo *__buf; /* Buffer for IPC_INFO
(Linux-specific) */
};
void plock(int semid){ //P操作,初始值-1,之后<0,阻塞。钥匙减一
struct sembuf sops;
sops.sem_num=0;
sops.sem_op=-1;
sops.sem_flg=SEM_UNDO;
semop(semid,&sops,1);
}
void vfree(int semid){// V 操作加一,初始值>0,解放资源。钥匙加一
struct sembuf sops;
sops.sem_num=0;
sops.sem_op=1;
sops.sem_flg=SEM_UNDO;
semop(semid,&sops,1);
}
int main()
{
int semid;
key_t key=ftok(".",3);
semid=semget(key,1,IPC_CREAT|0666);
union semun initsem;
initsem.val=0;
semctl(semid,0,SETVAL,&initsem); //赋初始值==0.也可为1 ,看需求。相当于钥匙
plock(semid);
printf("This is father\n");
vfree(semid);
semctl(semid,0,IPC_REID);//删除信号量,
return 0;
}
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
#include <unistd.h>
union semun {
int val; /* Value for SETVAL */
struct semid_ds *buf; /* Buffer for IPC_STAT, IPC_SET */
unsigned short *array; /* Array for GETALL, SETALL */
struct seminfo *__buf; /* Buffer for IPC_INFO
(Linux-specific) */
};
void plock(int semid){
struct sembuf sops;
sops.sem_num=0;
sops.sem_op=-1;
sops.sem_flg=SEM_UNDO;
semop(semid,&sops,1);
}
void vfree(int semid){
struct sembuf sops;
sops.sem_num=0;
sops.sem_op=1;
sops.sem_flg=SEM_UNDO;
semop(semid,&sops,1);
}
int main()
{
int semid;
key_t key=ftok(".",3);
semid=semget(key,1,IPC_CREAT|0666);
/* union semun initsem;
initsem.val=0;
semctl(semid,0,SETVAL,&initsem);//不需要
*/
printf("This is child\n");
vfree(semid);
return 0;
}
7 .套接字(socket)
套接字是一种通信机制,凭借这种机制,客户/服务器(即要进行通信的进程)系统的开发工作既可以在本地单机上进行,也可以跨网络进行。也就是说它可以让不在同一台计算机但通过网络连接计算机上的进程进行通信。
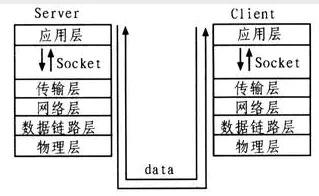
Socket是应用层和传输层之间的桥梁
套接字是支持TCP/IP的网络通信的基本操作单元,可以看做是不同主机之间的进程进行双向通信的端点,简单的说就是通信的两方的一种约定,用套接字中的相关函数来完成通信过程。
套接字特性
套接字的特性由3个属性确定,它们分别是:域、端口号、协议类型。
(1)套接字的域
它指定套接字通信中使用的网络介质,最常见的套接字域有两种:
一是AF_INET,它指的是Internet网络。当客户使用套接字进行跨网络的连接时,它就需要用到服务器计算机的IP地址和端口来指定一台联网机器上的某个特定服务,所以在使用socket作为通信的终点,服务器应用程序必须在开始通信之前绑定一个端口,服务器在指定的端口等待客户的连接。
另一个域AF_UNIX,表示UNIX文件系统,它就是文件输入/输出,而它的地址就是文件名。
(2)套接字的端口号
每一个基于TCP/IP网络通讯的程序(进程)都被赋予了唯一的端口和端口号,端口是一个信息缓冲区,用于保留Socket中的输入/输出信息,端口号是一个16位无符号整数,范围是0-65535,以区别主机上的每一个程序(端口号就像房屋中的房间号),低于256的端口号保留给标准应用程序,比如pop3的端口号就是110,每一个套接字都组合进了IP地址、端口,这样形成的整体就可以区别每一个套接字。
(3)套接字协议类型
因特网提供三种通信机制,
一是流套接字,流套接字在域中通过TCP/IP连接实现,同时也是AF_UNIX中常用的套接字类型。流套接字提供的是一个有序、可靠、双向字节流的连接,因此发送的数据可以确保不会丢失、重复或乱序到达,而且它还有一定的出错后重新发送的机制。
二个是数据报套接字,它不需要建立连接和维持一个连接,它们在域中通常是通过UDP/IP协议实现的。它对可以发送的数据的长度有限制,数据报作为一个单独的网络消息被传输,它可能会丢失、复制或错乱到达,UDP不是一个可靠的协议,但是它的速度比较高,因为它并一需要总是要建立和维持一个连接。
三是原始套接字,原始套接字允许对较低层次的协议直接访问,比如IP、 ICMP协议,它常用于检验新的协议实现,或者访问现有服务中配置的新设备,因为RAW SOCKET可以自如地控制Windows下的多种协议,能够对网络底层的传输机制进行控制,所以可以应用原始套接字来操纵网络层和传输层应用。比如,我们可以通过RAW SOCKET来接收发向本机的ICMP、IGMP协议包,或者接收TCP/IP栈不能够处理的IP包,也可以用来发送一些自定包头或自定协议的IP包。网络监听技术很大程度上依赖于SOCKET_RAW。
原始套接字与标准套接字的区别在于:
原始套接字可以读写内核没有处理的IP数据包,而流套接字只能读取TCP协议的数据,数据报套接字只能读取UDP协议的数据。因此,如果要访问其他协议发送数据必须使用原始套接字。
套接字通信的建立
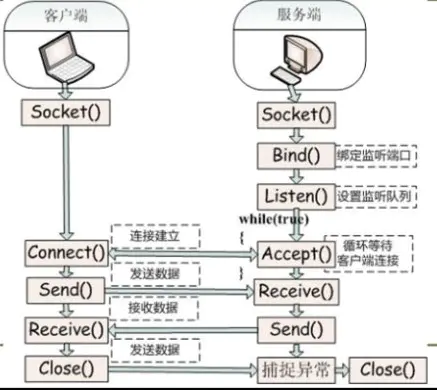
Socket通信基本流程
** 服务器端**
(1)首先服务器应用程序用系统调用socket来创建一个套接字,它是系统分配给该服务器进程的类似文件描述符的资源,它不能与其他的进程共享。
(2)然后,服务器进程会给套接字起个名字,我们使用系统调用bind来给套接字命名。然后服务器进程就开始等待客户连接到这个套接字。
(3)接下来,系统调用listen来创建一个队列并将其用于存放来自客户的进入连接。
(4)最后,服务器通过系统调用accept来接受客户的连接。它会创建一个与原有的命名套接不同的新套接字,这个套接字只用于与这个特定客户端进行通信,而命名套接字(即原先的套接字)则被保留下来继续处理来自其他客户的连接(建立客户端和服务端的用于通信的流,进行通信)。
客户端
(1)客户应用程序首先调用socket来创建一个未命名的套接字,然后将服务器的命名套接字作为一个地址来调用connect与服务器建立连接。
(2)一旦连接建立,我们就可以像使用底层的文件描述符那样用套接字来实现双向数据的通信(通过流进行数据传输)。
















 600
600











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









