







什么?你看了那么多遍kmp还没理解?这篇文章就让你彻底理解:P
--------------------------------------------------《第一部分:特殊情况》--------------------------------------------------------------
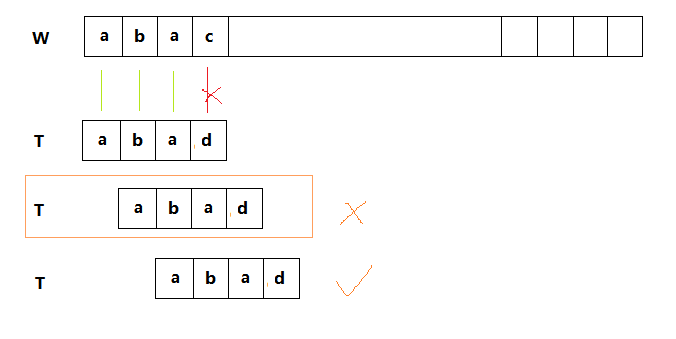
如图现在有两个字符串W和T,要在W中找到T。很明显W[3]和T[3]不匹配,那么下一步该怎么比较呢?
->如果在生活中我遇到这样的问题,我肯定不会拿W[1]和T[0]相比,而是直接让W[2]和T[0]对齐,然后让W[3]和T[1]进行对比,想想还有点小机智呢...
为什么聪明的人类会略去中间的一步W[1]和T[0],而直接进行W[3]和T[1]的比较呢?
->因为我们可以很明显的看出T[0] != T[1] && T[1] ==W[1] ,所以T[0] != W[1]。于是我们跳过T[0]和W[1]的比较,直接让W[2]和T[0]对齐,然后让W[3]和T[1]进行对比,这就是KMP最核心的内容了。
下面就通过几个小问题深入理解KMP的核心思想
1、为什么W[2]能和T[0]对齐?
之所以能让W[2]和T[0]对齐当然是因为W[2]和T[0]相等了...
2、W[3]和T[3]的位置发生失配能说明什么?
说明在这之前都匹配,即W[0]和T[0],W[1]和T[1],W[2]和T[2]都是相等的...
3、由问题1和问题2还能得到什么?
W[2]和T[0]相同,W[2]和T[2]相同,bingo,得到T[0]和T[2]相同:)
4、如果T[0]和T[2]不相同,那么还能将W[2]和T[0]对齐吗?
当然不行了,T[0]和T[2]不同,W[2]和T[2]相同,那么T[0]和W[2]也就不同了,所以答案是否定的!
5、T[0]和T[2]的位置有什么特点?
T[0]是T的最开始位置,T[2]是最靠后的位置(除了T[3]产生失配的位置以外,下同)。
6、总结一下我们的发现。
在W[3]和T[3]发生失配时,如果T的最前的1个字符T[0]和T的最后一个字符T[2]相同(除了T[3]产生失配的位置以外,下同,不再强调),那么我们可以将T[0]和W[3-1]对齐,然后直接比较W[3]和T[1],从而大大比较的效率,当然这里还看不出来效率问题。
--------------------------------------------------《第二部分:一般情况》--------------------------------------------------------------
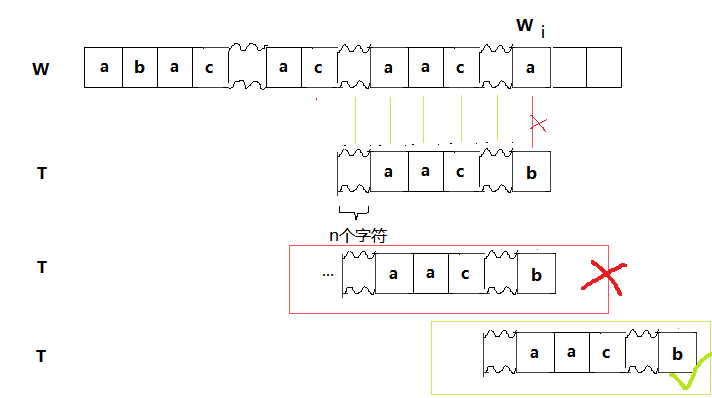
一般都把这里的W串称为目标串,T串称为模式串。
现在我们把上面的特殊情况一般化,即把W[3]的a看成一个包含n个字符的字符序列,失配的位置为W[i]。
->当在目标串的W[i]处发生失配时,如果模式串T的前n个字符和结尾的n个字符相同(当然要除去产生失配的那个字符),根据上面特殊情况的分析,我们可以直接用T的前n个字符和以W[i]为起始位置的n个字符对齐,直接比较W[j]和T[n]是否相同即可。想象一下如果n是2^10或者更大,一步一步的移动会做多少无用功啊...这下可以体会到什么叫大大提高效率了吧...
->这也说明了努力虽然很重要,但是如果方法不对,结果可想而知 :(
--------------------------------------------------《第三部分:Next数组》--------------------------------------------------------------
Next值:
用现代的话说就是备胎,即当模式串中的一个元素失配以后,用哪个第几个元素代替它继续进行比较。
它的值等于去掉失配元素之后,前后相等子串的最大长度。
举例说明
->在第一部分中,T[3]失配之后,去掉最T[3]以后的字符序列,只有第一个字符和最后一个字符相等(都是a),所以3的Next值为1;。
那么下次比较时,应该用第一个元素T[1]代替它继续比较;
->在第二部分中,T[2n+3]失配之后,去掉最T[2n+3]以后的字符序列,最开始的n个字符序列和最后n个字符相等,所以2n+3的Next值为n;。
那么下次比较时,应该用第一个元素T[n]代替它继续比较,
Next数组:
所有的备胎组成的数组自然就是Next数组了。
那么如何求得Next数组是KMP算法中一个最重要的环节了,假设我们计算出了next[i] = n, 那么next[i+1] = ?
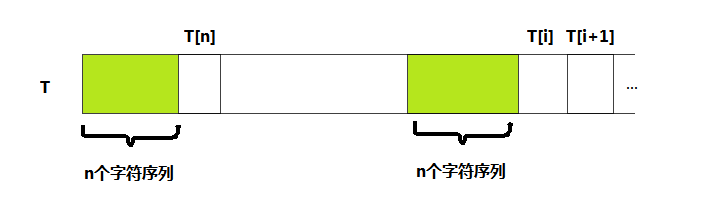
如图,当T[i]失配时,备胎T[n]就会移动到T[i]的位置,代替T[i]继续进行比较。由前面的知识可知两个填充绿色的字符序列是相等的。
现在要求Next[i+1]:
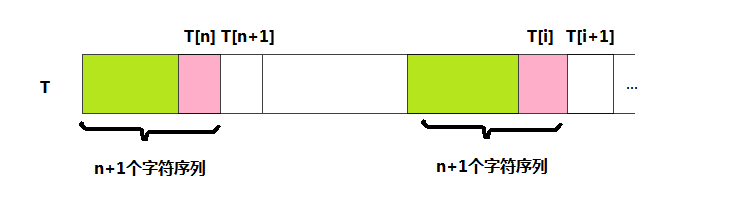
-> 如上图,假如T[i] == T[n],那么T的前n+1个元素和最后n+1个元素相同,所以当T[i+1]失配的时候,
可以直接使用T[n+1]替代T[i+1]进行比较。这样也就得到Next[i+1] = n + 1 = Next[i]+1;
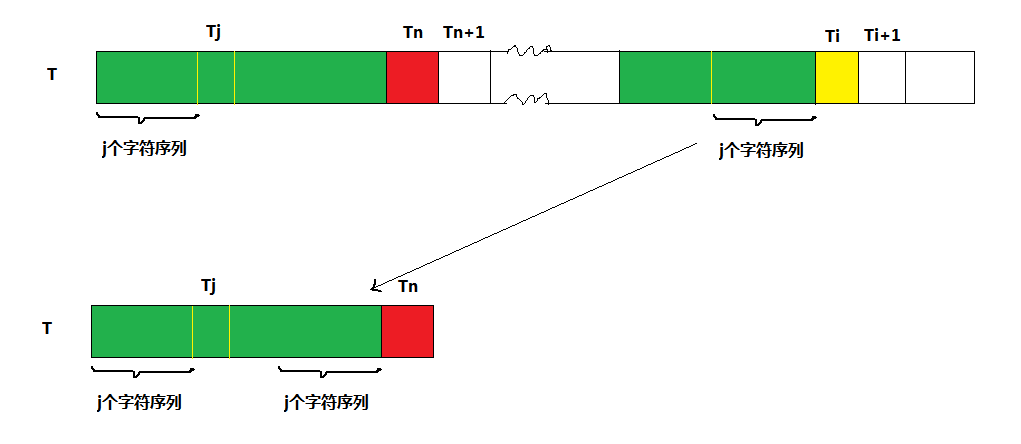
-> 如上图,假如T[i] != T[n] 呢? 这时候我们就不能在Next[i]之上作文章了,而是需要重新找最大子串。具体做法如下:
1、先在前i个元素中找到长度为j的最大子串; 由于绿色标记的串都相等,所以可以把思路转换下,即在前n个字符序列中查找最大字串序列;此时可以发现最大长度就是Next[n]的值,j = Next[n];
2、现在要求Next[i+1]
-> 假如T[i] == T[j],Next[i+1] = j + 1 = Next[Next[i]] + 1;

->如上图,假如T[i] != T[j],...可以发现又要递归查找合适的最大子串k;
。。。。递归ing。。。。
假设我们现在递归到最大子串长度为1,即T[0] ==T[i-1]
->如果T[1] == T[i],则Next[i+1] = 1 + 1 = 2;
->如果T[1] != T[i],再进行最后一次递归,这时最大子串长度为0。判断T[0]和T[i]是否相等,如果相等T[i+1] = 1,否则T[i+1] = 0;

经过上面的分析可知,只要满足下面的条件就要进行递归查找最大子串长度:最大子串大于0(Next[i] > 0)并且T[i] != T[x]。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
inline void BuildNext(const char *T, int Next[])
{
int i,j;
//T[0]是最开始的元素,没有备胎可选,用-1表示;
//T[1]也很无奈,只能选择T[0]做备胎,所以Next[1] = 0;
Next[0] = -1;
j = Next[1] = 0;
printf("Next[%d] is %d\n",0, Next[0]);
printf("Next[%d] is %d\n",1, Next[1]);
for (i = 2; i < strlen(T); i++){
while (j > 0 && T[i-1] != T[j]) j = Next[j];
if (T[i-1] == T[j]) j++;
Next[i] = j;
printf("Next[%d] is %d\n",i, Next[i]);
}
}
int main(void)
{
const char *T = "abcabcacab";
int Next[128] = {0};
BuildNext(T, Next);
return 0;
}














 277
277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









