







我们知道“Linux下一切皆文件”(当然由于历史原因,网络设备除外,它是通过socket进行操作的),我们操作设备都要通过文件进行操作也就是所所谓的操作设备文件节点,但是在Linux内核中是使用设备号来唯一的识别和管理设备,就相当于公民的省份证号码一样(其实吧,计算机还是喜欢数字的像标识进程使用进程的PID,管理用户使用UID,管理磁盘上的文件使用的inode号,管理网络中的计算机使用IP地址等等)。
那么设备号到底是什么东西?在Linux系统中如何才能保证每个设备的设备号是唯一的?下面我们来看一下:
1.设备号的构成
Linux系统中一个设备号由主设备号和次设备号构成,Linux内核用主设备号来定位对应的设备驱动程序(即是主设备找驱动),而次设备号用来标识它同个驱动所管理的若干的设备(次设备号找设备)。因此,从这个角度来看,设备号作为系统资源,必须要进行仔细的管理,以防止设备号与驱动程序的错误对应所带来的管理设备的混乱。
下图为一个嵌入式设备上的串口的设备文件节点信息:
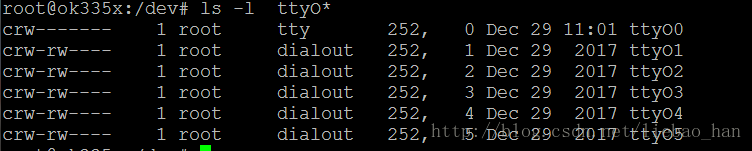
可以看到他们的主设备号都是252,次设备号0-5,即是这种串口驱动管理了6个不同的设备。
Linux系统中,使用dev_t类型来标识一个设备号,他是一个32位的无符号整数:
<include linux/types.h>
typedef __u32 __kernel_dev_t;
typedef __kernel_dev_t dev_t;其中,12为主设备号,20为次设备如下图。

随着内核版本的演变,上述的主次设备号的构成也许会发生变化,所以设备驱动开发者应该避免直接使用主次设备号锁占的位宽来获得对应的主设备号或者次设备号。内核为了保证在主次设备号位宽发生变化时,现在的程序依然可以工作,内核提供了如下的几个宏:
<include /linux/kdev_t.h>
#define MINORBITS 20
#define MINORMASK ((1U << MINORBITS) - 1)
#define MAJOR(dev) ((unsigned int) ((dev) >> MINORBITS))
#define MINOR(dev) ((unsigned int) ((dev) & MINORMASK))
#define MKDEV(ma,mi) (((ma) << MINORBITS) | (mi))MAJOR宏是用来从一个dev_t 类型的设备号中提取出主设备号,MINOR用来提取次设备号。MKDEV则是将主设备号ma和次设备号mi合成一个dev_t类型的设备号。实现原理都是通过未操作,不在赘述。在上述的宏定义中,MINORBITS在3.14.0内核中定义为20,
如果之后的内核对主次设备号所占的位宽进行调整,例如将MINORBITS改为8,只要驱动程序坚持使用MAJOR,MINOR,MKDEV来操作设备号,那么这部分的代码无需修改就可以用在新的内核中运行。
在实际的驱动开发中,我们经常已知inode,那么我们可以通过inode来获得主次设备号:
<include /linux/fs.h>
static inline unsigned iminor(const struct inode *inode)
{
return MINOR(inode->i_rdev);
}
static inline unsigned imajor(const struct inode *inode)
{
return MAJOR(inode->i_rdev);
}
iminor用于根据inode获得次设备号,imajor用于根据inode获得主设备号。
2.设备号的分配和管理
在内核源码中,进行设备号的分配与管理的函数有一下两个:register_chrdev_region,alloc_chrdev_region
1)register_chrdev_region函数
此函数用于静态注册设备号,优点是可以在注册的时候就知道其设备号,缺点是可能会与系统中已经注册的设备号冲突导致注册失败。
int register_chrdev_region(dev_t from, unsigned count, const char *name)
{
struct char_device_struct *cd;
dev_t to = from + count;
dev_t n, next;
for (n = from; n < to; n = next) {
next = MKDEV(MAJOR(n)+1, 0);
if (next > to)
next = to;
cd = __register_chrdev_region(MAJOR(n), MINOR(n),
next - n, name);
if (IS_ERR(cd))
goto fail;
}
return 0;
fail:
to = n;
for (n = from; n < to; n = next) {
next = MKDEV(MAJOR(n)+1, 0);
kfree(__unregister_chrdev_region(MAJOR(n), MINOR(n), next - n));
}
return PTR_ERR(cd);
}该函数第一个参数from表示是一个设备号,第二个是连续设备编号的个数,代表当前驱动所管理的同类设备的个数,第三个参数name表示设备或者驱动的名称。可以看到register_chrdev_region的核心功能体现在__register_chrdev_region函数中,在讨论这个函数之前,先要看看一个全局的指针数组chrdevs,他是内核用于设备号分配和管理的核心元素,定义如下:
<fs/char_dev.c>
static struct char_device_struct {
struct char_device_struct *next;
unsigned int major;//主设备号
unsigned int baseminor;//第一个次设备号
int minorct;//次设备的个数
char name[64];//驱动名
struct cdev *cdev; /* will die */
} *chrdevs[CHRDEV_MAJOR_HASH_SIZE];
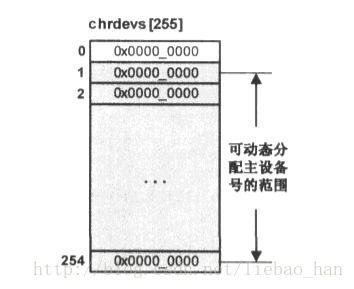
//#define CHRDEV_MAJOR_HASH_SIZE 255这个数组的每一项都是一个指向struct char_device_struct类型的指针。系统刚开始运行时,数组的初始化状态如下图:
现在再看看register_chrdev_region函数,函数完成的主要功能是将当前设备驱动程序要使用的设备记录到chrdevs数组中,而有了这种对设备号使用情况的跟踪,系统就可以避免不同的设备驱动程序使用同一个设备号的情况出现。这就意味着当驱动程序调用这个函数时,事先已经明确知道他要使用的设备号,之所以调用这个函数,是要将所管理的设备号纳入到内核的设备号管理体系中,防止被的驱动程序错误使用到。当然如果它试图使用的设备号已经被之前某个驱动程序使用了,调用将会失败,register_chrdev_region将返回错误码给调用者,如果调用成功,函数将返回0。
下面看看它的核心函数:__register_chrdev_region:
static struct char_device_struct *
__register_chrdev_region(unsigned int major, unsigned int baseminor,
int minorct, const char *name)
{
struct char_device_struct *cd, **cp;
int ret = 0;
int i;
cd = kzalloc(sizeof(struct char_device_struct), GFP_KERNEL);//分配struct char_device_struct结构
if (cd == NULL)
return ERR_PTR(-ENOMEM);
mutex_lock(&chrdevs_lock);
/* temporary */
if (major == 0) {
for (i = ARRAY_SIZE(chrdevs)-1; i > 0; i--) {
if (chrdevs[i] == NULL)
break;
}
if (i == 0) {
ret = -EBUSY;
goto out;
}
major = i;//主设备号返回给调用者
ret = major;
}
cd->major = major;//主设备号赋值
cd->baseminor = baseminor;//次设备号赋值
cd->minorct = minorct;//次设备个数赋值
strlcpy(cd->name, name, sizeof(cd->name));//驱动名赋值
i = major_to_index(major);//主设备号得到散列哈希索引值
for (cp = &chrdevs[i]; *cp; cp = &(*cp)->next)
if ((*cp)->major > major ||
((*cp)->major == major &&
(((*cp)->baseminor >= baseminor) ||
((*cp)->baseminor + (*cp)->minorct > baseminor))))
break;
/* Check for overlapping minor ranges. */
if (*cp && (*cp)->major == major) {
int old_min = (*cp)->baseminor;
int old_max = (*cp)->baseminor + (*cp)->minorct - 1;
int new_min = baseminor;
int new_max = baseminor + minorct - 1;
/* New driver overlaps from the left. */
if (new_max >= old_min && new_max <= old_max) {
ret = -EBUSY;
goto out;
}
/* New driver overlaps from the right. */
if (new_min <= old_max && new_min >= old_min) {
ret = -EBUSY;
goto out;
}
}
cd->next = *cp;
*cp = cd;
mutex_unlock(&chrdevs_lock);
return cd;
out:
mutex_unlock(&chrdevs_lock);
kfree(cd);
return ERR_PTR(ret);
}函数首先分配一个struct char_device_struct类型的对象cd,然后对其进行一些初始化工作。这个过程完成之后,他就开始搜索chrdevs数组,是通过哈希表的形式进行 的(我们可以看到哈希表在内核的一些数据查找的重要地位),首先会通过主设备号生成一个散列关键值:
i = major_to_index(major);
在此追寻源码,发现major_to_index实现如下:其中CHRDEV_MAJOR_HASH_SIZE是之前看到的255
static inline int major_to_index(unsigned major)
{
return major % CHRDEV_MAJOR_HASH_SIZE;
}所以i = major %255。
此后,函数将对chrdevs[i]元素管理的链表进行扫描,如果chrdevs[i]上已经有了链表节点,表明之前有别的驱动程序使用的主设备号散列到chrdevs[i]上,为此函数就需要响应的逻辑确保当前正在操作的设备号不会与这些已经使用的设备号发生冲突,如果有冲突函数返回错误码,表明本次调用失败。如果本次调用使用的设备号与chrdevs[i]上已经有的设备号没有发生冲突,先前分配的struct char_device_struct对象cd将加入到chrdevs[i]领衔的链表中成为一个新的节点。接下来不进行往下分析,看一个具体的实例:
假设chrdevs数组初始化时,有个设备的主设备号为257,次设备为0,1,2,3(有四个次设备)。则调用如下
register_chrdev_region(MKDEV(257,0),4,”demodev”);
上述的函数调用完毕后,chrdevs数组状态如下图:
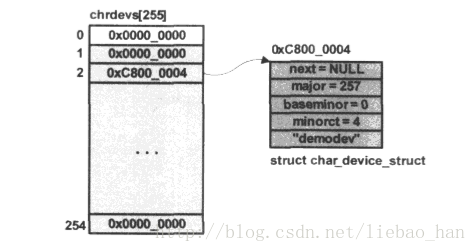
图中我们假设新分配的struct char_device_struc节点的内存地址为0xc8000004,i=257%255=2 则索引到chrdevs数组的第二项。
接下来,假设又有一个设备驱动使用主设备号为2,次设备号为0,则调用函数register_chrdev_region(MKDEV(2,0),1,”augdev”)来向系统注册设备号,i=2%255=2属于同一个哈希索引值,也索引到chrdevs数组的第二项。这时候俩设备号MKDEV(257,0)和MKDEV(2,0)并不冲突,所以注册总会成功的。可以看出,节点在插入哈希表中采用的是插入排序,这导致哈希表按照major的大小进行递增排序,此时chrdevs的数组状态如下图:
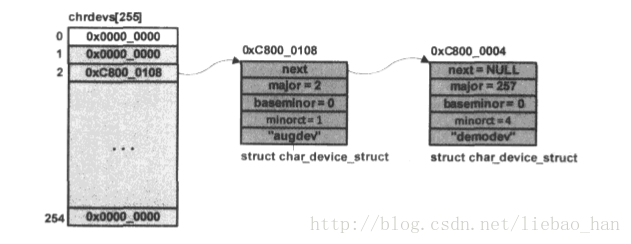
在上图的基础上,**如果有另一个驱动程序也调用register_chrdev_region注册设备号,主设备号也是257,那么只要其次设备号的范围在[baseminor,baseminor+minorct]不与设备“demodev”的次设备
范围发生重叠,系统依然会生成一个新的struct char_device_struc节点并加入到对应的哈希链表中。如果在主设备相同的情况下,如果次设备号的范围有重叠,则意味着有设备号的冲突,将导致register_chrdev_region调用失败。而对于主设备相同的若干struct char_device_struc对象,当系统加入链表时,将根据其baseminor成员的大小进行递增排序。**
2)alloc_chrdev_region函数
该函数时系统协助动态分配设备号,分配的主设备号的范围在1-254之间
int alloc_chrdev_region(dev_t *dev, unsigned baseminor, unsigned count,
const char *name)
{
struct char_device_struct *cd;
cd = __register_chrdev_region(0, baseminor, count, name);
if (IS_ERR(cd))
return PTR_ERR(cd);
*dev = MKDEV(cd->major, cd->baseminor);
return 0;
}
这个函数的核心调用也是__register_chrdev_region,相对于register_chrdev_region,alloc_chrdev_region在调用__register_chrdev_region时第一个参数为0,将导致__register_chrdev_region执行如下逻辑:
static struct char_device_struct *
__register_chrdev_region(unsigned int major, unsigned int baseminor,
int minorct, const char *name)
{
...
if (major == 0) {
for (i = ARRAY_SIZE(chrdevs)-1; i > 0; i--) {
if (chrdevs[i] == NULL)
break;
}
if (i == 0) {
ret = -EBUSY;
goto out;
}
major = i;
ret = major;
}
...
}上述的逻辑很简单,它在for循环中从chrdevs数组的最后一项(也就是第254项)一次向前扫描,如果发现该数组中的某项,比如第i项,对应的数值为NULL,那么就把该项对应的索引值i作为分配的主设备号返回给驱动程序,同时生成一个struct char_device_struct节点,并将其加入到chrdevs[i]对应的哈希链表中。如果从第254项一直到第一项,其中所有的项对应的指针都不为NULL,那么函数失败并返回一非0值,表明动态分配设备号失败,分配成功后通过将新分配的设备号返回给函数的调用者。
设备号作为一种资源,当所对应的设备驱动程序被卸载时,就需要把设备号归还给系统,以便分配给其他内核模块使用。无论是静态分配还是动态分配,系统都是通过unregister_chrdev_region负责释放设备号。
下面分析下设备号的释放函数:
void unregister_chrdev_region(dev_t from, unsigned count)
{
dev_t to = from + count;
dev_t n, next;
for (n = from; n < to; n = next) {
next = MKDEV(MAJOR(n)+1, 0);
if (next > to)
next = to;
kfree(__unregister_chrdev_region(MAJOR(n), MINOR(n), next - n));
}
}static struct char_device_struct *
__unregister_chrdev_region(unsigned major, unsigned baseminor, int minorct)
{
struct char_device_struct *cd = NULL, **cp;
int i = major_to_index(major);
mutex_lock(&chrdevs_lock);
for (cp = &chrdevs[i]; *cp; cp = &(*cp)->next)
if ((*cp)->major == major &&
(*cp)->baseminor == baseminor &&
(*cp)->minorct == minorct)
break;
if (*cp) {
cd = *cp;
*cp = cd->next;
}
mutex_unlock(&chrdevs_lock);
return cd;
}函数在chrdevs数组中查找参数from和count所对应的struct char_device_struct 对象节点,找到以后将其从链表中删除并释放该节点所占用的内存,从而将对应的设备号释放以供其他设备驱动模块使用。
以上就是Linux设备号的构成和分配的内核机制,设备号的管理主要通过chrdevs数组来跟踪系统中设备号的使用情况,以防止实际使用中出现设备号冲突的情况。















 1889
1889

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









