








论文标题:LEARNING TO EMBED TIME SERIES PATCHES INDEPENDENTLY
下载地址:https://arxiv.org/pdf/2312.16427v1.pdf
开源代码:https://github.com/seunghan96/pits
前言
之前的文章我们读了Patch TST,建议大家阅读原论文,毕竟是基础,我的论文解读放在下方。
客观讲,Patch方法目前在时间序列领域几乎等同于attention,用了确实比没用好。这篇文章就是继patch TST之后的另一篇,但从题目名字可以看出该文章工作重点是学习patch的特征表示方法。
具体来说,作者对比了 patch independent和patch dependent 两种方法,所产生的特征的优劣。按照作者说法,patch independent 方法结构简单、参数少,效果好。
patch 依赖和独立
理解这个任务,首先要知道为什么对时间序列数据进行patch后,还有依赖和独立一说。这是因为大多数模型,包括patch TST在做预测的时候,为了提高特征表征能力,都增加了自监督表示学习策略。就像训练文本大模型一样,可以遮住一句话中的一些词,然后预测这些被遮住的词,或者用遮住的词预测其周围的词语。在PatchTST中,作者也是故意随机移除输入序列的一部分内容,并训练模型恢复缺失的内容。
-
patch dependent,PD:参考transformer,用周围patch预测被遮住patch,引入attention等交互机制。很好理解,因为对被遮蔽对象的预测依赖于周围的patch。重点:在本文中是预测被遮蔽的patch
-
patch independent,PI:基于重构策略,利用未被遮蔽的patch进行重构(reconstruction,或者说是预测)
按照作者的说法,在时间序列这一领域,预测被mask的patch是不必要的。通过实验其实可以发现,在PD任务上预训练的Transformer,在分布发生变化的情况下无法预测测试数据的,但在PI任务上预训练的模型表现出对此更为鲁棒的特性。换句话说,只需要用patch自己本身的信息就能实现预测,文中称之为patch independent建模。
下图对比了PI和PD方法的差别,PI方法(图2a左),只单独使用Linear或MLP,patch之间没有交互;PD方法,使用MLP-Mixer、Transformer结构融合不同patch信息,这里patch是有交互的。显然,PD方法参数量和模型结构更加复杂,且考虑到了上下文信息,按理说效果应该更好?
patch 依赖和独立
Patch Independence for Time Series,PITS
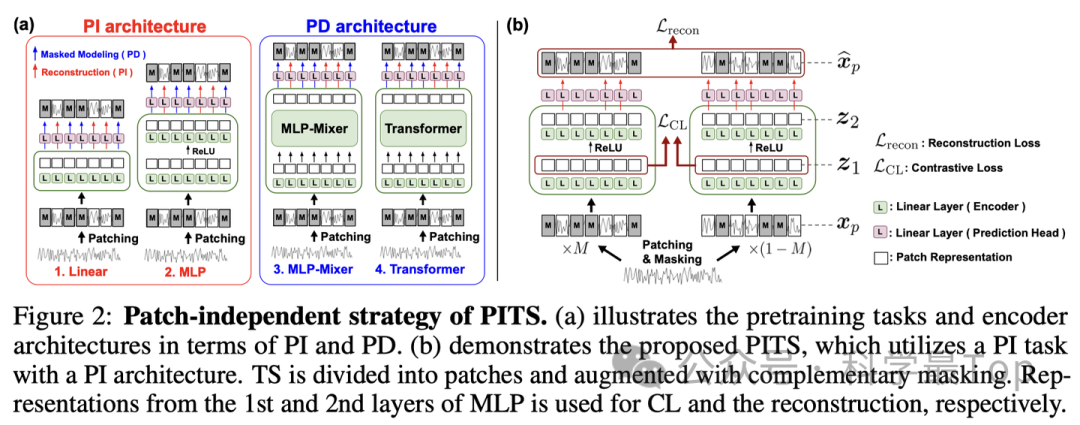
本文的模型结构部分如图所示,由于摒弃了MLP- Mixer和Transformer,模型结构非常清晰(简单),就是Linear+MLP,核心就是编码然后重构。注意重构有两种策略:一种所有patch拼接后,过FC和MLP,然后重构;第二种是每个patch过FC和MLP,然后逐个重构,作者采用了第二种,即channel /Patch independent建模重构。
为什么说是channel /Patch independent?因为每个变量单独过MLP,多个变量共享MLP参数,同样的,每个patch单独过MLP,多个patch共享MLP参数。
对比学习
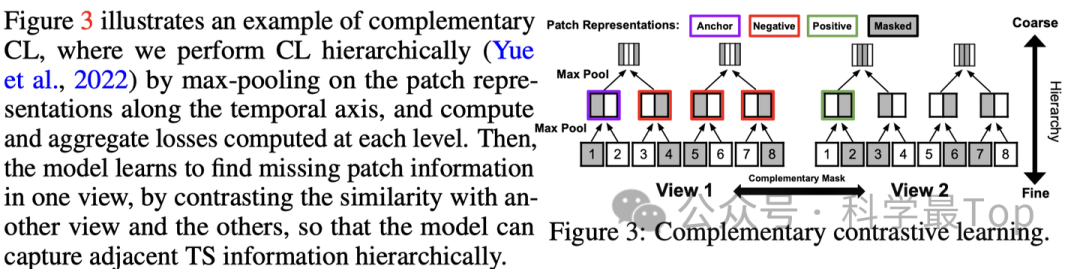
按作者论文中的说法,对比学习主要用来学习patch之间的关系,分层次地捕捉相邻的时间序列信息,所以我个人认为“独立”也是相对而言的。
对比学习需要两个视图来生成正样本,作者通过如下遮蔽策略实现了这一点:mask掉50%的patch,将该序列及与其mask完全相反的序列作为两个视图,使用对比学习的目标进行优化。需要注意的是,遮蔽的目的是为了为对比学习生成两个视图;它不影响提出的补丁独立任务,并且在使用提出的补丁独立架构时不需要额外的前向传播,因此额外的计算成本可以忽略不计。
如上图所示,论文使用了一种层次建模方法进行对比学习,并计算每个层次上的最大池化和聚合损失。然后,模型学习在一个视图中找到缺失的补丁信息,通过将与另一个视图和其他视图的相似性进行对比,从而使模型能够层次化地捕捉相邻的时间序列信息,实现从细粒度到粗粒度的对比学习。
实验结果
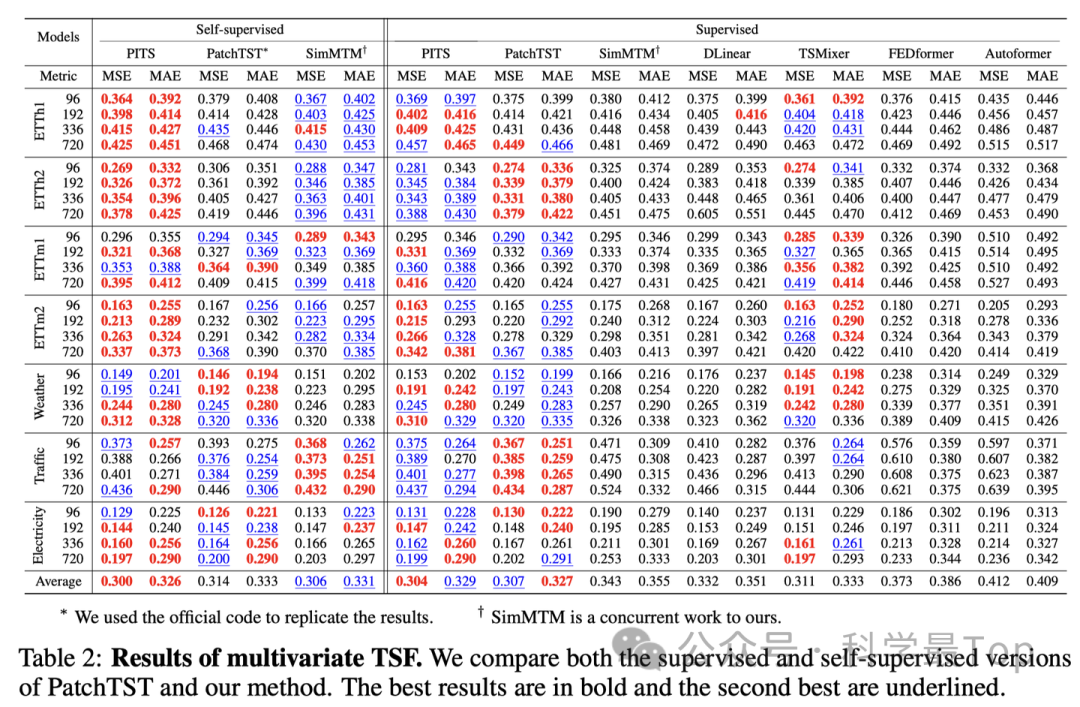
从实验结果来看,本文提出的方法相对于最先进的基于Transformer的模型,在时间序列预测和分类性能上都有所提升,同时在参数数量、训练和推断时间方面更为高效。
欢迎大家关注我的公众号【科学最top】,专注于时序高水平论文解读,回复‘论文2024’可获取,2024年ICLR、ICML、KDD、WWW、IJCAI五个顶会的时间序列论文整理列表和原文。


















 2413
2413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









