







文章目录
一、基于多种静态信息的恶意软件检测思路
1.特征选取
- 选取四种静态信息作为影响因子,包括权限信息、敏感API信息、证书信息以及代码混淆技术使用的信息。
- 权限信息由权限对系统危害程度以及在恶意软件样本中出现的频率构建。
- API敏感信息由API调用频率以及API平均调用路径长度组成。
- 证书的信息由有效性构成。
- 代码混淆技术由三种不同的混淆技术的使用情况构成,使用字符串信息熵、变量名平均长度以及java反射技术的使用作为判断的依据。
2.机器学习方法
- 基于机器学习的Android恶意软件检测技术主要是使用其分类模型通过从恶意软件代码提取的信息作为特征来对恶意代码样本进行分类。通过机器学习分类可以发现恶意软件之间存在一定的类同规律,从而使训练后的模型具备一定的预测能力。
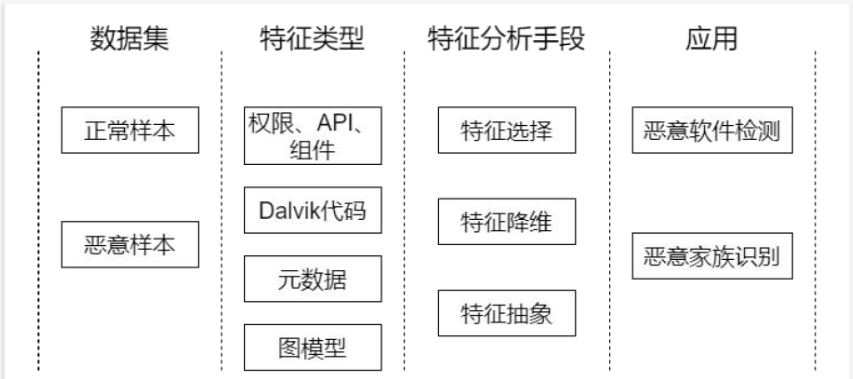
- 基于机器学习的恶意软件检测的方法框架图如下所示。主要特征类型使权限、API、组件、Dalvik字节码、元数据以及拥有各种程序语义及相关信息的图模型。主要的特征分析手段包括特征选择、特征降维以及特征抽象三种。对特征进行处理后通过二分类机器学习对恶意软件进行检测,或者使对收集的恶意软件进行恶意家族多分类识别。
二、信息获取研究
1.静态分析方法以及影响因子的选择
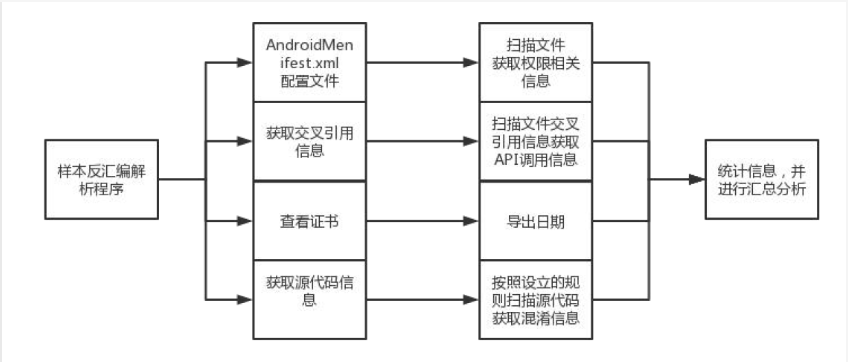
2.基于Androguard的程序信息提取技术
Androguard是一个适用于Android APK静态分析的工具包,可以高效的从程序中提取出想要的静态信息。
# 加载APK文件
a,d,dx = AnalyzeAPK(self.file_path)
# 获取权限
requested_permissions = a.get_permissions()
其中a表示APK文件,d表示DEX文件,dx表示Analysis对象。
官网可查看相应的使用方法,https://androguard.readthedocs.io/en/latest/。
我装的是4.1.3版本androguard。
三、程序权限信息
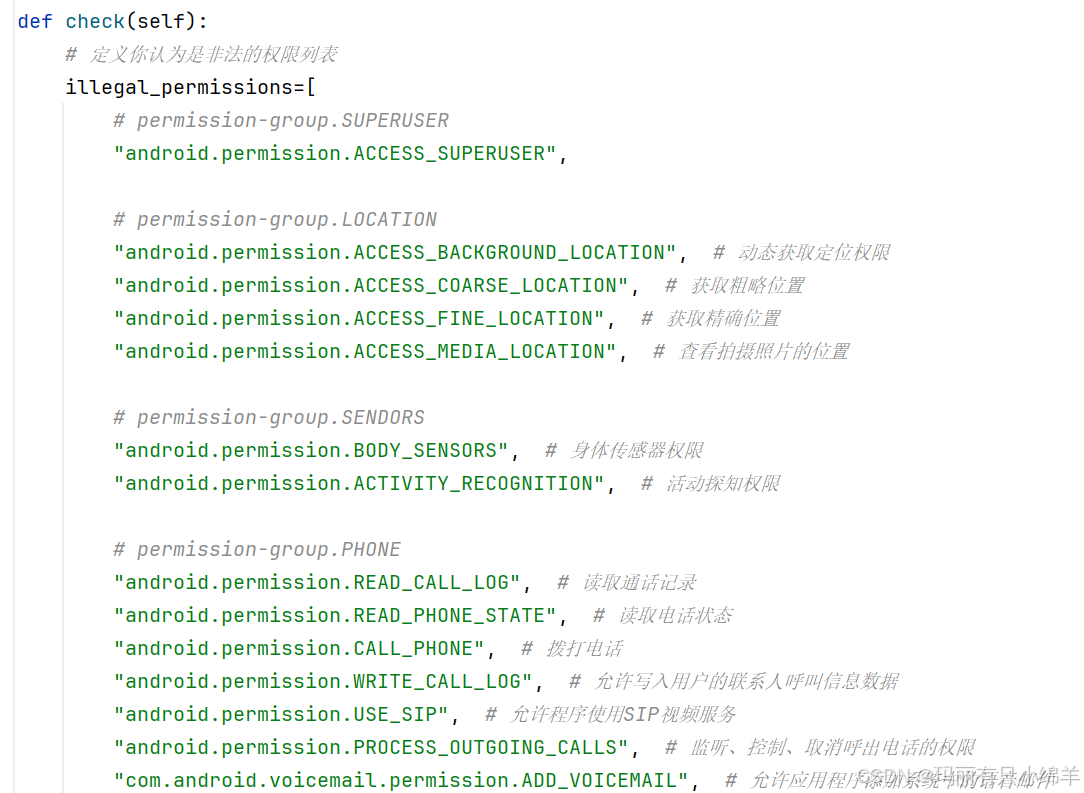
1.恶意权限的界定
(1)对用户的隐私或设备的运行状态产生影响。
(2)危险权限的出现频率通常高于正常应用软件。
(3)通过重打包技术生成的恶意软件,可能会有权限被多次重复请求的情况出现。
2.样例恶意软件应用
Android系统提供了超过200种权限,通过申请各种权限实现对应的功能。由于恶意应用软件往往觊觎用户的隐私或企图掌握对设备的全面控制,危险权限的出现频率通常高于正常应用软件。除此之外,恶意软件往往会通过重打包技术将恶意代码插入到原有的应用当中。在重打包的过程中,可能会有权限被多次重复请求的情况出现。下图为某恶意软件的权限特征。

恶意软件通常会申请相当多的权限,例如READ_SMS,以及RECEIVE_SMS等权限往往出现在资费小号行为类型的恶意软件中。基于危险权限以及多次请求权限两种情况进行观察,从Android应用的清单文件(AndroidManifest.xml)中抽取权限列表,并统计其中危险权限以及重复权限的出现次数,作为应用权限方面的特征。
图片不完整,请自己按具体情况扩充。使用adb命令,可以查看设备上的危险权限。
./adb shell pm list permissions -d -g
四、API使用信息
- 恶意软件的实现需要调用特定 API 来完成,如恶意计费软件会调用发送短信 API,隐私窃取软件会调用访问通讯录 API,此类 API 被称为敏感 API。
- API使用的频次相较于权限而言较多,API的调用一般能够代表着单次的动作,因而能够更好的表示程序进行了什么行动。如下图所示,GDA对某一恶意软件分析的部分API调用列表。

通过 Androguard,我们能够将样本中的APK调用信息提取出来。Androguard提供了获取交叉引用(XREFs)信息的方法,能够从class、method、Fields、strings四个方面获取交叉引用信息。XREFs工作又两个方向:xref_from(被调用)和xref_to(调用)。
所以与权限类似,相当一部分API的滥用也可能造成用户隐私被窃取或设备系统异常,这部分API被称为敏感API。通常来讲,恶意软件的行为异常,对敏感API的使用与正常程序应有不同,因此我们选择这些API的平均调用次数作为特征之一。除此之外,相比于普通软件,恶意软件因为其具有明确的目的性,所以在Android恶意软件中敏感API被调用的方式通常较为直接单一,调用过程简单也更加容易被触发,因此,选择了敏感API调用路径的平均长度作为特征之二。常见敏感API如下图所示。
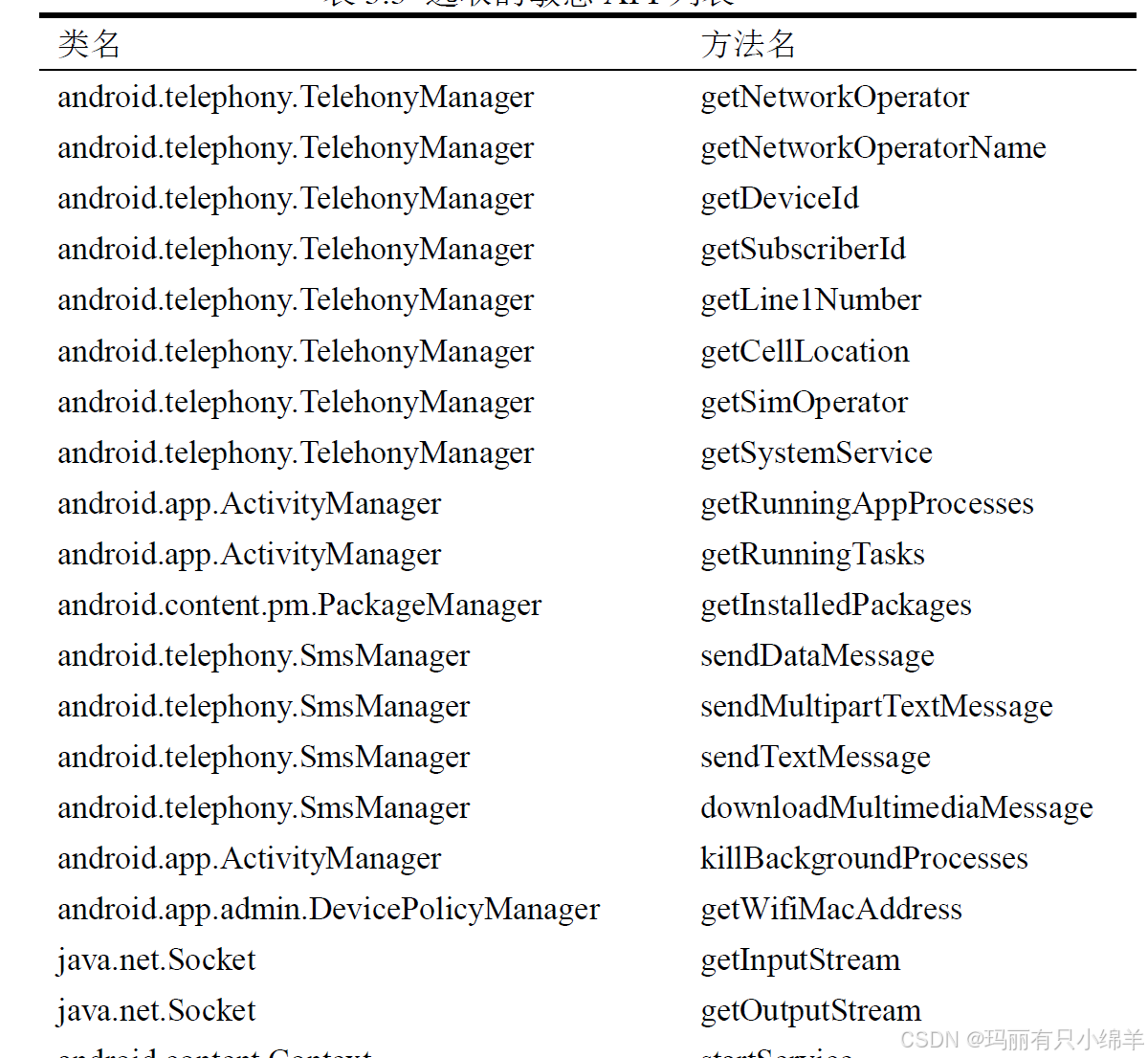
通过对这20个敏感API在程序中调用深度和调用次数进行获取,然后得出敏感API在函数中的平均调用次数,以及敏感API的平均路径长度。从程序入口到敏感API中间的函数节点个数的计算方式为:A函数调用B函数,B函数再调用C函数,则设定其节点数为3。
五、签名证书信息
在Android应用给开发的过程中,需要对应用进行签名,签名后将会产生一个证书文件,通常以.RSA作为后缀。当应用被上传到应用市场上进行审核时,证书将会被用来验证程序的相关信息,包括开发者等。但是恶意软件通常不通过正规渠道发布,因此其证书中包含的信息通常含有伪造信息。由于使用了加密技术的证书信息难以调取,因此可以选用证书有效期作为证书是否有误的判断条件,并且作为判断应用软件是否为恶意的因素。合法的良性软件证书年限往往比较长,通常在18年以上,而恶意软件使用的签名年限一般比较短,同时一般仅在恶意软件中会出现证书过期的情况。但由于证书未过期时,恶意软件无法区分。可以考虑将证书作为先验信息,放入数据集中。
六、代码混淆技术使用信息
代码混淆技术在良性Android应用与恶意软件应用的使用有着明显的差异。
1.字符串加密信息
字符串加密时将程序运行的字符串加密,待到需要使用的时候才解密应用,一般恶意软件可以通过这种行为把带有恶意信息的字符串加密隐藏。信息熵用于量化表示信息的不确定性,当某条信息被加密后,其信息熵将会增大。恶意软件的字符串信息熵,整体比通常软件较低。
2.标识符混淆信息
可以将应用程序中标识符名称的平均长度作为特征检验。
3.java反射使用信息
可以将应用程序中Java反射API调用次数作为特征检验。
七、代码分析
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from tkinter import Tk, Label, Button, filedialog
def load_data():
# 从文件中加载数据集
# 这里假设数据集已经准备好,包括样本特征和标签
# 返回特征矩阵和标签向量
pass
def train_model(X, y):
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练机器学习模型
model = RandomForestClassifier(n_estimators=100)
model.fit(X_train, y_train)
# 在测试集上评估模型性能
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("模型准确率:", accuracy)
return model
def detect_malware(file_path, model):
# 对给定文件进行恶意软件检测
# 这里需要使用与训练模型时相同的特征提取方法将文件转换为特征向量
# 然后使用训练好的模型进行预测
pass
def open_file_dialog():
# 打开文件选择对话框,选择要检测的文件
root = Tk()
root.withdraw()
file_path = filedialog.askopenfilename()
root.destroy()
return file_path
def main():
# 加载数据集
X, y = load_data()
# 训练模型
model = train_model(X, y)
# 打开文件选择对话框,选择要检测的文件
file_path = open_file_dialog()
# 检测恶意软件
detection_result = detect_malware(file_path, model)
# 显示检测结果
root = Tk()
result_label = Label(root, text=detection_result)
result_label.pack()
root.mainloop()
if __name__ == "__main__":
main()
```python
在这里插入代码片
load_data():从数据文件加载特征矩阵和标签向量。
train_model(X,y):使用随机森林分类器训练机器学习模型,并返回训练好的模型。
detect_malware(file_path, model):对给定文件进行恶意软件检测,返回检测结果。
open_file_dialog():打开文件选择对话框,选择要检测的文件。
main():主函数,负责整个流程的控制。
首先加载数据集,然后训练模型。接下来,通过打开文件选择对话框,选择要检测的文件。最后,调用detect_marlware()函数对选定的文件进行恶意软件检测,并将结果显示在GUI界面上。
# 总结
先看懂别人的代码,一个一个来。

















 438
438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









