






刚看文章说HDFS的特点有:
a.能够运行在廉价机器上,硬件出错常态,需要具备高容错性
b.流式数据访问,而不是随机读写
c.面向大规模数据集,能够进行批处理、能够横向扩展
d.简单一致性模型,假定文件是一次写入、多次读取忽然对流式数据访问和随机读写的区别记不太清楚了,度娘了两篇文章,罗列如下:
1、随机读写
存储的数据在磁盘中会占用空间,对于一个新磁盘,操作系统会将数据文件依次写入磁盘,当有些数据被删除时,就会空出该数据原来占有的存储空间,时间长了,不断的写入、删除数据,就会产生很多零零散散的存储空间,就会造成一个较大的数据文件放在许多不连续的存贮空间上,读写些这部分数据时,就是随机读写,磁头要不断的调整磁道的位置,以在不同位置上的读写数据,相对于连续空间上的顺序读写,要耗时很多。
在开机时、启动大型程序时,电脑要读取大量小文件,而这些文件也不是连续存放的,也属于随机读取的范围。
改善方法:做磁盘碎片整理,合并碎片文件,但随后还会再产生碎片造成磁盘读写性能下降,而且也解决不了小文件的随机存取的问题,这只是治标。更好的解决办法:更换固态硬盘(SSD),固态硬盘由于免除了机械硬盘的磁头运动,对于随机数据的读写极大的提高。
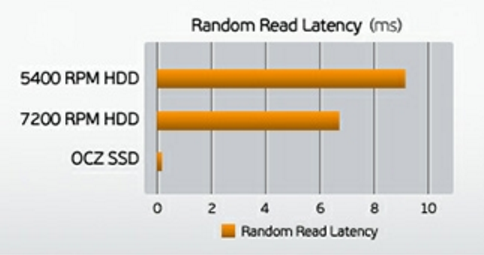
举个例子,SSD的随机读取延迟只有零点几毫秒,而7200RPM的随机读取延迟有7毫秒左右,5400RPM硬盘更是高达9毫秒之多,体现在性能上就是开关机速度。
2、流式数据访问
流式数据访问就像勤快的小弟,来了一点数据,就立马处理掉,立马分发到各个存储节点来响应分析、查询。
与之相反的是,非流式数据访问,就像是职场混了多年的老油条,来了一点数据,懒得处理,等堆成一堆,再一起处理。等堆成一堆,处理完,再分发到各个存储节点,响应分析、查询。
如果把数据访问比作网上看片,那么:
a.流式数据访问,就相当下载10G的电影,用迅雷边下边播的模式。
b.非流式数据访问,就相当于,10G的电影,完全下好了,再播放。
参考地址,侵删















 1041
1041











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









