








开篇
近年来,随着人工智能技术的飞速发展,越来越多的企业开始将AI落地应用于业务中。然而,不可忽视的是,企业在落地LLM RAG系统时,常常面临一个令人头痛的问题——数据幻觉。
就像透过雾霭的眼睛,看到了一片迷人的景色,仿佛触手可及,企业往往在这一景象中沉迷并迷失了方向。
不可否认,AI技术在实践中展现出的巨大潜力令人兴奋,但当面对大量数据的时候,企业却往往陷入迷惑与幻觉之中。这一领域因为真正落地者寥寥无几,缺乏可借鉴的行业经验,使得解决数据幻觉这一难题变得异常困难。为了解决这一问题,许多企业开始寄望于LORA微调或Finetune的方法,试图通过微调算法来消除数据幻觉。
然而,他们却忽视了一个至关重要的环节——前期数据的质量处理,这就如同在建造高楼大厦之前,却没有先修筑牢固的地基一样,注定会面临巨大的麻烦。大量的实践事实已然证明,前期数据质量处理对于落地LLM RAG系统至关重要。而正因为这个原因,优秀的企业在推进AI落地过程中,将精力集中在Embedding库数据的质量上。
事实上,良好的前期数据质量处理远比后期LORA微调的效果更为显著,不仅成本更低,耗费的时间也更少。相反地,纵使企业在后期不断进行LORA微调,投入巨大的成本和精力,却只能获得微不足道的3%-5%的提升。而与之相比,前期数据质量处理的优劣直接决定了LLM RAG系统整体性能的90%+的提升。在这个信息爆炸和大数据时代,企业要实现真正的数字化转型,摆脱数据幻觉的困扰,唯有从根源上解决前期数据质量问题。在本文中,我将揭示企业在落地LLMRAG系统时常遇到的问题,并给出一套科学可行的解决方案,帮助您轻松破解数据幻觉之谜。请随我一同踏上这个解谜之旅,让我们共同探索AI落地企业时的数据幻觉,并找到破解的钥匙。
直接用数据幻觉的例子来说明
RAG系统标准架构
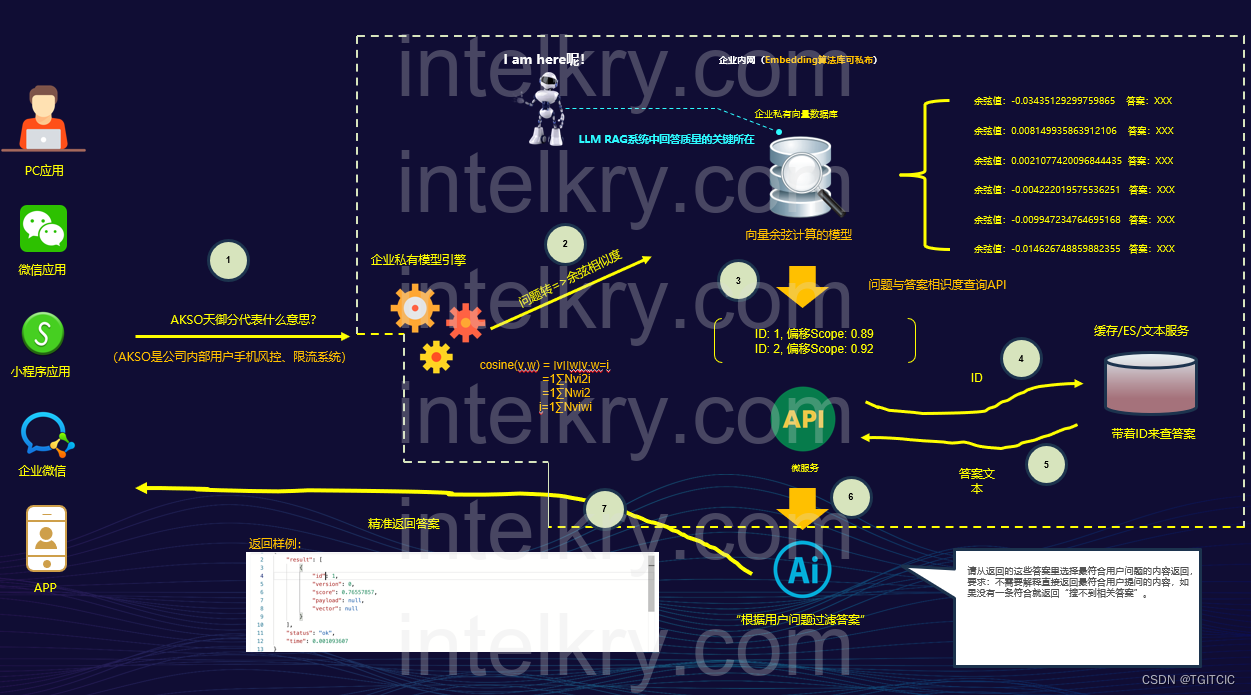
这是一个标准的RAG系统,所有企业业务系统要做AI应用落地必选搭建此架构。
- 原始数据通过向量进入企业私有embedding库;
- 前端通过会话或者是输入内容在embedding库内召回数据;
- 把召回的数据送给AI进行“判定”然后渲染、润色直到回答;
原始数据
假设有500条原始数据通过embedding后存储于向量库。
其中有两条内容如下:
第一条

第二条

实际场景:当数据进入Embedding数据库后发生的幻觉
实际场景如下
用户问
医生说我缺铁,怎么补?根据原始数据RAG召回6条数据
1. (1)需要量成男/女:12/18mg/d孕妇\乳母:28mg/d
2.(2)食物来源 铁的最佳来源——动物肝、动物全血、畜禽肉、鱼类;另外坚果、豆类等;
3. 注:牛奶为缺铁且其中铁吸收率低;果蔬含有一定量的铁但吸收率低,相对高的黑木耳、紫米、黑芝麻等。
4. 铁缺乏是一种常见营养缺乏病,也是全球性公共营养问题之一,特别是婴幼儿、孕妇、乳母更易发生.
5. (T)常见症状:怕冷、疲乏无力、心慌气短、头晕,严重者面色苍白、口唇粘膜和睑结膜苍白、肝脾轻度肿大等;
6. 早产、低出生体重儿及胎儿死亡与孕早期贫血有关(T);
AI回答-反例
铁缺乏是一种常见营养缺乏病,也是全球性公共营养问题之一,特别是婴幼儿、孕妇、乳母更易发生.请问作为用户你的感受如何?人工弱X,是不是有这种感觉?

AI回答-正例
而我们希望的AI回答应该是如何的?
我们根据原数据就知道我们希望AI回答到两层意思:
- 缺少铁元素怎么办会有什么影响?
- 如何补铁元素的建议?
对不对?因此我们来看好的RAG系统中AI的回答:

为什么会出现幻觉呢?
从现象来看问题
以上这只是一个例子,实际情况我在之前的博文中举了很多。
这是为什么呢?
明明我数据有多条,可是AI偏偏选择了那条不该回答的来回答用户?
在我之前的博客《基于AI的RAG需要真正面对商业化场景和落地的几大致命陷井》中我举过这样的例子:
RAG的数据流就是把一大堆内容放入一个本地向量库,以让AI突破上下文窗口获得它本不该有的“长久记忆”。
- 好,我现在放了50条商品进RAG,这个搜索结果赞啊。。。精准啊。
- 好,我现在放了150条商品进RAG,唉。。。为什么我要的是水果,它把水果糖、水果口味的口香糖也带出来啊?
- 好,我现在放了300条商品进RAG,唉。。。我搜水果,TOP1~10排序竟然是矿泉水。

我们从原理来看问题
我们要RAG是因为AI没有长期记忆,再长也只有几百K。
这个问题将一直伴随人类至少10年,这是受制于计算机硬件水平不可能有质上的突破决定的,如果可以突破这个上下文记忆窗口,人类将可以冲出太阳系殖民外星。
其实这个道理和计算机原理中的:计算机寄存器、二级缓存道理一样。它只能用来存储有限的东西。要企业落地因此我们在“后世”才有了缓存、才有了ehcache、才有了Redis。
而ehcache和redis出现了有10多年了吗?依然吃相。
如果真的相信现有人类的Transformer技术造就的LLM(其实说LLM更合适而不要说AI)有长久的记忆那么在现实项目和落地时将裁一个无比大的跟头。
所以需要有RAG来帮助LLM做长久记忆+召回。
这就涉及到我们需要把原始数据存储于向量并在实际使用时使用embedding检索把那些符合的数据尽量、尽高质量的召回。
理想中我们认为当原始数据进入向量库后,到再被召回是以下这样的形式的。这是理想状况。

而实际呢?实际我们的数据在向量库内是以下这个样地

正是因为原始数据并不是计算机或者说AI理想中的数据,而是到处有“断链”、“语义上的漏洞”所以才导致了“幻觉”。
这就是在RAG系统中幻觉严重的root cause。
解决之道中的矛与盾-鹬蚌之争
“鹬”的进击
为了解决数据幻觉,由于2023-2024这段时间的“百模大战”中蕴含了一部分商业原因。绝大多数落地但不成功(因此造成了后来:AI上不能顶天下不能落地一说的由来)企业掉入了一个“坑 ”,即认为AI是万能的,因此就准备把100样东西扔给AI,因此就有了:拥有开源的AI可以LORA可以Finetuning。
于是接着上面这个“RAG系统中因为原始数据问题导致的各种断链、漏洞”我们需要做这么一件事:

我们把它称为“补链”。
然后围绕着“补链”,业界于2023年提到了Finetuning,要知道Finetuning是先出台的一种技术手段。这是因为随着embedding技术一同出现的正好有一个finetuning。
进而由finetuning演变成了LORA微调。
在当时网上充斥着“奥运会数据”那个例子,然后用finetuning取得了怎么怎么样的提高。可是,那个例子只有400~1,000来条数据,已经耗费了200多美元,取得的效果大约是把准确度提高了5%左右。
而实际在我们的生产落地,动辄就是1万条数据、几十万、百万条数据那真的是和吃家常便饭一样。
在实际应用过程中人们发觉随着数据量的增涨为了finetune所付出的成本陡然上升,而效果永远突破不了5%。
于是LORA出现了。LORA试图通过借助于开源的模型,通过各种手段(技术名词我就不满天飞了,因为事实证明你不是顶尖头部拥有海量资源的LLM提供商,大多数企业现在已经很少再提LORA了)来在某个垂直领域试图“纠偏模型”。
而实际效果呢?
我在之前一系列博文中已经给大家明确指出了各种例子,如果你的企业不是一个专业型LLM提供商并且你不具备拥有一座水电站的资源,请你不要轻易开口说:LORA微调。
我们拿百度paddle来举例,在4090卡上对11万个样本数据进行精准的BIRT LORA微调,首先4090卡是什么价格你是知道的,大约消耗了8小时左右吧。
如果没有4090卡,只是一般的高性能服务器如:32C CPU,耗费时间我这有一个记录:17小时。
这11万个样本其实真正涉及到有效数据的不会超过1万条,因为在微调时,涉及到2-8分折或者是3-7分折样本、Test Case以及叠代步骤等因素,因此总样本参于计算的共计是11万。如果真的是一个企业业务部门如:零售中采购部门的主数据相应的一些语义,恐怕这个样本得要在千万级(至少)。于是。。。我们发觉一些落地了最后还是失败了或者项目无法实际投入真正使用都是因为:过于偏重在LORA微调上而忽视了另一样重要的事物-数据清洗。
“蚌”的出现
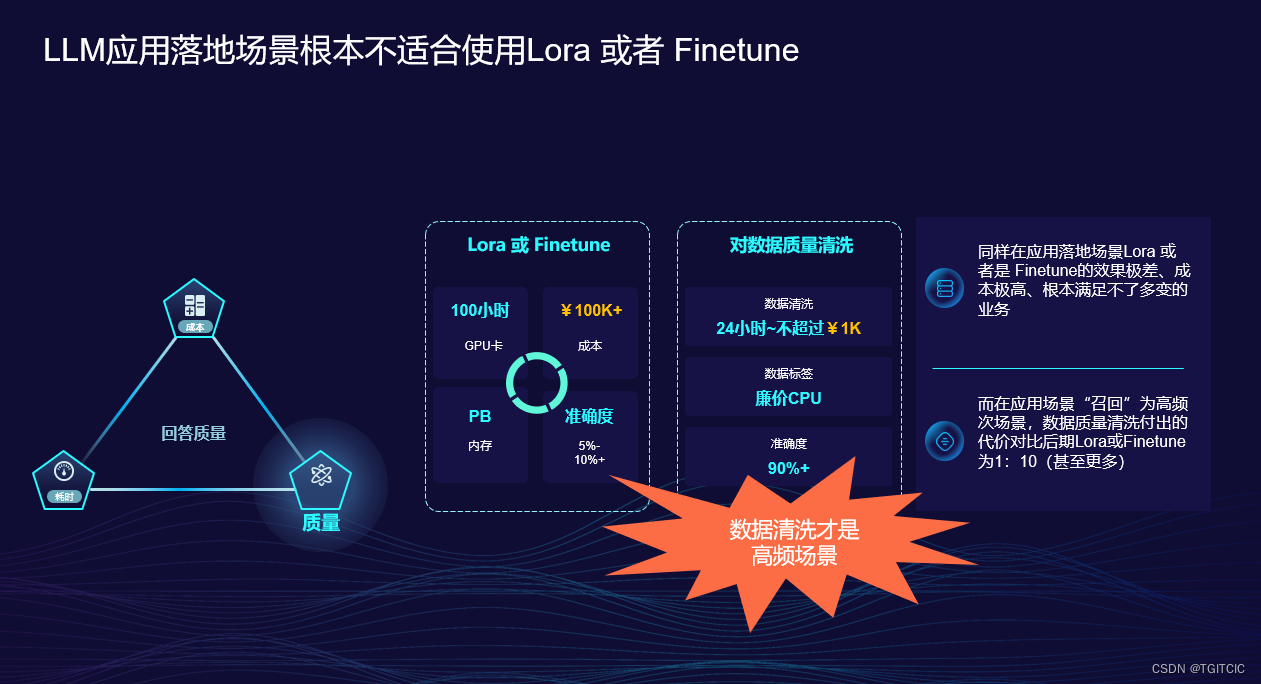
现实情况中LORA微调极耗成本,这不是大众企业AI落地之道。
真正有效的是“数据进入向量库”前的清洗。
各位如果有AZURE OPENAI资源(这个一直稳定且合规)的如果用到过相应的功能的一定知道,你上AZURE OPENAI,申请Finetune,它会提示什么:
我们不建议您轻易使用finetune,而更多关注于数据质量的清洗。
就是上面这么一句话!
要知道数据质量的清洗实际在LLM落地领域被奉为了“神寓”。吴恩达李飞飞都在2023-2024超过5次重要会议中提到了:企业落地AI必须着重于前期数据清洗。
要知道,数据清洗正是“补链”的科学手段,也是最完美的“补链”手段。如果你前期在数据清洗上付出的成本是1,对比后期LORA的成本是10。而你在实际生产应用时得到的效果是“反过来的”。
太多企业疏忽了数据清洗这一块内容了。而实际在我们的生产落地时通过数据清洗提高数据准确度的提升有过统计,高达90%+。
鹬和蚌-的组合应用
我们不一味强调只用数据清洗而忽视LORA、Finetune!
我们也不可以一味只使用LORA、Finetune而对数据清洗视而不见!
事实上数据清洗技术才是最值得希望落地AI类项目的企业去思考的,这个领域是有高技术含量的且可以通过廉价手段落得高精度的AI回答。
一定不能沉迷于:LORA微调很技术,很爽,好复杂因此我喜欢。
TOGAF架构师原则以及IT告诉了我们什么?
什么是技术?技术是用于赋能业务的、技术是用来普惠人类的。正因为它可以降低成本、提高效率、普惠人类,所以这个东西称为技术!
如果一个东西,动辄天文数字、它不能被普遍大众所掌握,那么这样的东西在企业内部并不称为技术,它恰恰失去了其核心竞争力。
但这就带来我的另一个观点,即:万事不可走极端,要走平衡。
我在这边提倡的是我们需要有选择的使用LORA和数据清洗。
如何选择LORA微调还是数据清洗呢?
直接给出例子。
例一
电话号码:02188888888识别这是一个电话号码
可是当遇到了这样的格式的输入
8888-8888或者是这样的格式的
086-(021)8888,8888亦或者是这样的格式
086-021-88888888我们需要让AI识别以上这些格式都叫“电话”。怎么办?
这就不是数据清理的活了!此时就得用LORA微调了。
看。。。这种从底层元数据的缺陷出发,通过微调增强LLM/AI底层基础推理、识别能力,就得必须使用LORA。
换而言之,对于这种场景你使用数据清洗。。。你觉得可能么?我再变换一种格式怎么办?
LORA微调在没有LLM出现前其实已经存在了,它是一种“机器自学习”,只是它现在用的BIRT、Transformer、NLU等模式远比之前的“self-learning”要高效以及训练后可以覆盖到的场景更多。
例二
维生素含有铁元素
鸡蛋含有铁元素
XXXX也含有铁元素从业务出发我希望搜集全现在在食补领域,那些含有铁元素的食品或者说农作物或者说动植物。此时你该怎么办?
如果我说是一家连锁大药房,我们算它全国有1千家门店好了?
LORA微调。。。
介个。。。可以也是可以。。。它得关个20来家店才能支撑,但是时间不保证,可能得几个月,效果是否好呢?
介个。。。也不能保证。
此时就是“数据清洗”,要知道数据清洗可不只是指:把重复的、无关的数据清除哦!它还包括了“数据的完善、抓取、补链、打标签”。
而实际1个月,成本非常有限,6位数内,取得的效果是90%+的提升。
此时该用LORA还是数据清洗呢?
再说了更直白一些我们用一个更直观的一个例子来说明LORA还是前期数据清洗:
气象预报的例子
你LORA了一个月后,这还是实时气象预报吗?黄花菜都凉了!
换一种思路:用一套科学的、高度自动化的工具在1秒内把当前的气象值实时的“洗”进RAG,以取得这个系统:既拥有预报功能还能围绕着当前天气指数做出各种如:洗车指数、雾霾指数的额外功能呢!
因此,它的区别在于:高频、多变的垂直业务领域知识必须走数据清洗这条路而不能是高频的去LORA,如果高频的LORA可能你拥有一座水电站都不够!
结语
由于数据幻觉是一个系列,它带有着理论、架构设计、实操一系列后续博客,因此每一篇不易说多,说多不容易接受。我会把数据清洗以及会遇到什么样的坑和应对手法单独剥离出来作为另一个篇章来讲。
但是本文给出的实例、理论与架构设计要说明的一个点就是:
企业需要根据实际业务场景组合应用工具,不是舍弃这个选那个,也不是硬性地搞“一刀切”,而是要学会组合应用。
这是我一直以来所倡导的理念。
在解决数据幻觉问题时,我们不能依赖于单一的工具或方法,而是要灵活运用多种工具和方法,适应不同的场景。这个问题的解决并不容易,需要我们不断地实践、思考和探索。
正如本文所讲述的,理论、架构设计和实操都是一个系列,需要我们多方面学习。我们要引导企业走上正确的道路,让他们明白组合应用才是解决数据幻觉的关键。
让我们一起勇敢地面对挑战,不断学习和实践,以科学的态度去解决问题。我们要善于思考、创新,灵活运用各种工具和方法,打造高质量的数据。只有这样,企业才能在落地LLM RAG系统中获得真正的成功。
结束今天的博客,下一篇我们讲着重讲述:在打造企业数据清洗工具、平台和落地过程中又会遇到什么挑战。

















 733
733











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











