










Design a data structure that supports the following two operations:
void addWord(word) bool search(word)
search(word) can search a literal word or a regular expression string containing only letters a-z or .. A . means it can represent any one letter.
For example:
addWord("bad")
addWord("dad")
addWord("mad")
search("pad") -> false
search("bad") -> true
search(".ad") -> true
search("b..") -> true
一看这题目,简单啊,就是一个插入一个查找,插入用vector插,查找就是碰到'.'进行枚举,从a-z,用回溯就行了。
还有就是看着简单,一定要捋清思路,还有就是注意一些细节问题。
code1: Time Limit Exceeded
class WordDictionary{
public:
vector<string>dict;
// Adds a word into the data structure.
void addWord(string word) {
dict.push_back(word);
}
bool check(string word)//检查是否exist
{
for (int i = 0; i < dict.size(); i++)
{
if (dict[i] == word) return true;
}
return false;
}
// Returns if the word is in the data structure. A word could
// contain the dot character '.' to represent any one letter.
string temp;
bool res;
void backtracking(string word, int dep, int pos)
{
if (check(word))
{
res = true;
return;
}
if (dep == word.size())
{
return;
}
if (word[pos] == '.')
{
for (int i = 0; i < 26; i++)//a-z
{
word[pos] = 'a' + i;//把.替换成a-z
if (!res)//找到了就不需要回溯
{
backtracking(word, dep + 1, pos + 1);//回溯
}
}
}
backtracking(word, dep + 1, pos + 1);//这里记得回溯
}
bool search(string word) {
res = false;//每次先置否
if (check(word)) return true;//能直接找到则返回true
backtracking(word, 0, 0);//有没有办法通过.找到
if (res)
{
return true;
}
return false;
}
};结果,超时了;
想了下,查找不能暴力查找啊,用set试试,结果还是超时。
code2: Time Limit Exceeded
class WordDictionary{
public:
set<string>dict;
// Adds a word into the data structure.
void addWord(string word) {
dict.insert(word);
}
// Returns if the word is in the data structure. A word could
// contain the dot character '.' to represent any one letter.
string temp;
bool res;
void backtracking(string word, int dep,int pos)
{
if (dict.find(word) != dict.end())
{
res = true;
return;
}
if (dep==word.size())
{
return;
}
if (word[pos] == '.')
{
for (int i = 0; i < 26; i++)//a-z
{
word[pos] = 'a' + i;//把.替换成a-z
if (!res)//找到了就不需要回溯
{
backtracking(word, dep + 1, pos + 1);//回溯
}
}
}
backtracking(word, dep + 1, pos + 1);//回溯
}
bool search(string word) {
res = false;//每次先置否
if (dict.find(word) != dict.end()) return true;//能直接找到则返回true
backtracking(word, 0,0);//有没有办法通过.找到
if (res)
{
return true;
}
return false;
}
};蛋疼了,看了下提示,要用Trie树,还引出了另外一道实现Trie的题
先看下Trie那道题。
Implement Trie (Prefix Tree)
Implement a trie with insert, search, and startsWith methods.
Note:
You may assume that all inputs are consist of lowercase letters a-z.
粘下别的博客上的说明:Trie (prefix tree) 实现 (Java)
Trie,又称单词查找树或键树,是一种树形结构。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。
它有3个基本性质:
根节点不包含字符,除根节点外每一个节点都只包含一个字符。
从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
每个节点的所有子节点包含的字符都不相同。
下面这个图就是Trie的表示,每一条边表示一个字符,如果结束,就用星号表示。在这个Trie结构里,我们有下面字符串,比如do, dork, dorm等,但是Trie里没有ba, 也没有sen,因为在a, 和n结尾,没有结束符号(星号)。
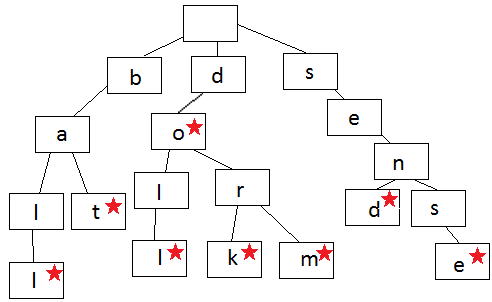
说下三个函数实现的思路:
插入:首先把根节点当做当前节点,然后从unordered_map中查找是否这个字符,如果找到则把找到的节点当做当前节点,没找到则新建一个节点插在原节点上,然后把新建的节点当做当前节点
查找: 查找过程跟插入过程类似,只是没找到直接返回false
查找前缀:根据前缀查找,跟查找一样,只是不需要管isEnd
Trie Code
class TrieNode {
public:
// Initialize your data structure here.
TrieNode(char input='#'):isEnd(false) {
}
bool isEnd;//需要一个end标志判断是否到达结尾
unordered_map<char, TrieNode*> child;//将一个节点下的所有节点存在unordered_map中
};
//插入:首先把根节点当做当前节点,然后从unordered_map中查找是否这个字符,如果找到则把找到的节点当做当前节点,没找到则新建一个节点插在原节点上,然后把新建的节点当做当前节点
class Trie {
public:
Trie() {
root = new TrieNode();
}
// Inserts a word into the trie.
void insert(string word) {
TrieNode *iter=root;
for (int i = 0; i < word.size(); i++)
{
if (iter->child.find(word[i]) != iter->child.end())//找到,则把找到的当做待处理节点
{
iter = iter->child[word[i]];
}
else//找不到,新建节点
{
TrieNode *temp = new TrieNode(word[i]);
iter->child[word[i]] = temp;
iter = temp;
}
}
iter->isEnd = true;
}
// Returns if the word is in the trie.
// 查找过程跟插入过程类似,只是没找到直接返回false
bool search(string word) {
TrieNode *iter = root;
for (int i = 0; i < word.size(); i++)
{
if (iter->child.find(word[i]) != iter->child.end())//找到,则把找到的当做待处理节点
{
iter = iter->child[word[i]];
}
else//找不到,新建节点
{
return false;
}
}
if (iter->isEnd) return true;
return false;//只是前缀也是false
}//search()end
//根据前缀查找,跟查找一样,只是不需要管isend
// Returns if there is any word in the trie
// that starts with the given prefix.
bool startsWith(string prefix) {
TrieNode *iter = root;
for (int i = 0; i < prefix.size(); i++)
{
if (iter->child.find(prefix[i]) != iter->child.end())//找到,则把找到的当做待处理节点
{
iter = iter->child[prefix[i]];
}
else//找不到,新建节点
{
return false;
}
}
return true;
}
private:
TrieNode* root;
};Code 3 AC:
class TrieNode {
public:
TrieNode(bool end=false) {
isEnd = end;
memset(children, 0, sizeof(children));
}
bool isEnd;//需要一个end标志判断是否到达结尾
TrieNode* children[26];
};
class WordDictionary{
public:
vector<string>dict;
// Adds a word into the data structure.
void addWord(string word) {
TrieNode *iter = root;
for (int i = 0; i < word.size(); i++)
{
if (iter->children[word[i]-'a'])//找到一样的节点
{
iter = iter->children[word[i] - 'a'];
}
else//找不到,新建节点
{
TrieNode *temp = new TrieNode(i == word.size() - 1 ? true : false);
iter->children[word[i]-'a'] = temp;
iter = temp;
}
}
iter->isEnd = true;
}
// Returns if the word is in the data structure. A word could
// contain the dot character '.' to represent any one letter.
string temp;
bool res;
void backtracking(string word, int dep, TrieNode *node)
{
if (!node)
{
return;
}
if (dep == word.size())
{
if (node->isEnd)
{
res = true;
}
return;
}
if (word[dep] == '.')
{
for (int i = 0; i < 26; i++)//1-26
{
if (!res)//找到了就不需要回溯
{
backtracking(word, dep + 1, node->children[i]);//回溯
}
}
}
else{
backtracking(word, dep + 1, node->children[word[dep]-'a']);//这里记得回溯
}
}
bool search(string word) {
res = false;//每次先置否
backtracking(word, 0,root);//有没有办法通过.找到
if (res)
{
return true;
}
return false;
}
private:
TrieNode* root = new TrieNode();
};















 3411
3411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









