







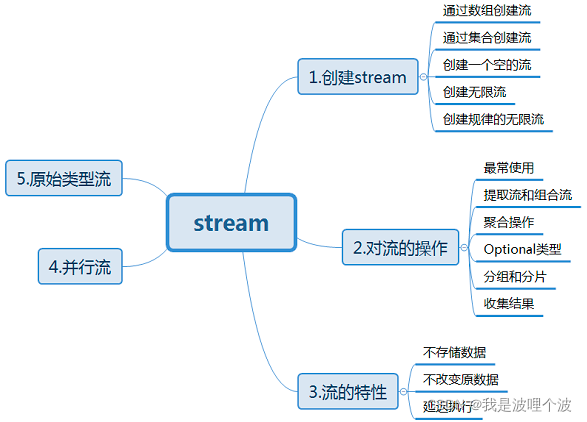
一、Stream流
Lambda表达式是Stream的基础,建议先掌握lambda表达式。
Java 8 给我们提供了强大的Stream API,为什么叫强大的Stream API?接下来我将一一讲解,从中你就会慢慢体会到它的强大。
Java 8 API添加了一个新的抽象称为流Stream,可以让你以一种声明的方式处理数据。
Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象。
Stream API可以极大提高Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。
这种风格将要处理的元素集合看作一种流,流在管道中传输,并且可以在管道的节点上进行处理,比如筛选,排序,聚合等。
元素流在管道中经过中间操作(intermediate operation)的处理,最后由最终操作(terminal operation)得到前面处理的结果。
Stream的操作分为三个步骤:
1、创建Stream
2、中间操作(对数据进行操作)
3、终止操作(如果没有终止操作,中间操作是不执行的)
1.1 初识Stream
东西就是这么多,Stream是java8中加入的一个非常实用的功能,最初看时以为是io中的流(其实一点关系都没有),让我们先来看一个小例子感受一下:
列出班上分数超过85分的学生姓名,并按照分数降序输出学生名字,在java8之前我们需要三个步骤:
1、新建一个List<Student> stuList,在for循环中遍历stuList,将分数超过85分的学生装入新的集合中。
stuList是存储所有学生数据、newList是存放超过85分学生数据;
2、对于新的集合newList进行排序操作(比较器)。
3、遍历打印newList,只输出学生姓名。
这三个步骤在java8中只需要两条语句,如果紧紧需要打印,不需要保存新生产list的话实际上只需要一条,是不是非常方便。
Student类代码:
public class Student {
private String name;
private Integer score;
public Student() {
}
public Student(String name, Integer score) {
super();
this.name = name;
this.score = score;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getScore() {
return score;
}
public void setScore(Integer score) {
this.score = score;
}
@Override
public String toString() {
return "Student [name=" + name + ", score=" + score + "]";
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((name == null) ? 0 : name.hashCode());
result = prime * result + ((score == null) ? 0 : score.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Student other = (Student) obj;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
if (score == null) {
if (other.score != null)
return false;
} else if (!score.equals(other.score))
return false;
return true;
}
}测试类代码:
import java.util.ArrayList;
import java.util.Comparator;
import java.util.List;
import java.util.Random;
import java.util.stream.Collectors;
public class Test_Stream {
public static void main(String[] args) {
// 创建随机类,用来生存随机值
Random random = new Random();
// 创建List集合,用来存储学生
List<Student> stuList = new ArrayList<>();
// 创建100个学生,成绩值是一个随机100以内的整数
for (int i = 0; i < 100; i++) {
int nextInt = random.nextInt(100);
System.out.println(i + "--------------" + nextInt);
stuList.add(new Student("student" + i, nextInt));
}
// 使用Stream列出班上超过85分的学生姓名,并按照分数降序输出用户名字
List<String> filterList = stuList.stream()
.filter(x -> x.getScore() > 85)
.sorted(Comparator.comparing(Student::getScore).reversed())
.map(Student::getName)
.collect(Collectors.toList());
System.out.println(filterList);
}
}1.2 Stream的特性
我们首先列出Stream的如下三点特性,在之后我们会对照着详细说明:
1、Stream不存储数据
2、Stream不改变源数据
3、Stream的延迟执行特性
1.2.1 Stream不存储数据
通常我们在数组或集合的基础上创建Stream,Stream不会专门存储数据,对Stream的操作也不会影响到创建它的数组和集合,对于Stream的聚合、消费或收集操作只能进行一次,再次操作会报错,如下代码:
Stream<String> stringStream = Stream.generate(() -> "user").limit(20);
// 第一次输出
stringStream.forEach(System.out::println);
System.out.println("--------------");
// 第二次输出
stringStream.forEach(System.out::println);程序在正常完成一次打印工作后报错。
1.2.2 Stream不改变源数据
通过初识Stream里面的案例,我们可以输出源集合数据,发现是没有任何改变的。
1.2.3 Stream的延迟执行特性
Stream的操作是延迟执行的,在列出班上超过85分的学生姓名例子中,在collect方法执行之前,filter、sorted、map方法还未执行,只有当collect方法执行时才会触发之前转换操作
看如下代码:
import java.util.ArrayList;
import java.util.Comparator;
import java.util.List;
import java.util.Random;
import java.util.function.Predicate;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class Test_Stream {
public static void main(String[] args) {
// 创建随机类,用来生存随机值
Random random = new Random();
// 创建List集合,用来存储学生
List<Student> stuList = new ArrayList<>();
// 创建100个学生,成绩值是一个随机100以内的整数
for (int i = 0; i < 100; i++) {
int nextInt = random.nextInt(100);
System.out.println(i + "--------------" + nextInt);
stuList.add(new Student("student" + i, nextInt));
}
// 使用Stream列出班上超过85分的学生姓名,并按照分数降序输出用户名字
Stream<String> map = stuList.stream()
.filter(new Predicate<Student>() {
@Override
public boolean test(Student t) {
System.out.println("begin compare");
return t.getScore() > 85;
}
})
.sorted(Comparator.comparing(Student::getScore).reversed())
.map(Student::getName);
System.out.println("执行toList");
List<String> filterList = map.collect(Collectors.toList());
System.out.println(filterList);
}
}我们将filter中的逻辑抽象成方法,在方法中加入打印逻辑,如果Stream的转换操作是延迟执行的,那么“执行toList”会先打印,否则后打印,代码运行结果为:

可见Stream的操作是延迟执行的。
TIP:当我们操作一个流的时候,并不会修改流底层的集合(即使集合是线程安全的),如果想要修改原有的集合,就无法定义流操作的输出。
由于Stream的延迟执行特性,在聚合操作执行前修改数据源是允许的。
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Stream;
public class Test_Stream {
public static void main(String[] args) {
List<String> wordList = new ArrayList<String>() {
{
add("a");
add("b");
add("c");
add("d");
add("e");
add("f");
add("g");
}
};
Stream<String> words = wordList.stream();
wordList.add("END");
long n = words.distinct().count();
System.out.println(n);
}
}最后打印的结果是8。
1.3 创建Stream
1.3.1 通过数组创建
Stream接口静态方法:
static <T> Stream<T> of(T... values) 返回其元素是指定值的顺序排序流。
static <T> Stream<T> of(T t) 返回包含单个元素的顺序 Stream 。
Arrays类静态方法:
static DoubleStream stream(double[] array) 返回顺序DoubleStream与指定的数组作为源。
static IntStream stream(int[] array) 返回顺序IntStream与指定的数组作为源。
static LongStream stream(long[] array) 返回顺序LongStream与指定的数组作为源。
static <T> Stream<T> stream(T[] array) 返回顺序Stream与指定的数组作为源。
/*
* 通过数组创建流
*/
// 1.通过Arrays.stream
// 1.1 基本类型
int[] arr = new int[]{1, 2, 34, 5};
IntStream intStream = Arrays.stream(arr);
intStream.forEach(System.out::println);
// 1.2 引用类型
Student[] studentArr = new Student[]{new Student("s1", 29), new Student("s2", 27)};
Stream<Student> studentStream = Arrays.stream(studentArr);
studentStream.forEach(System.out::println);
// 2.通过Stream.of
Stream<Integer> Stream1 = Stream.of(1, 2, 34, 5, 65);
// 注意生成的是int[]的流
Stream<int[]> Stream2 = Stream.of(arr, arr);
Stream2.forEach(System.out::println);1.3.2 通过集合创建流
Collection接口静态方法:
default Stream<E> parallelStream() 返回可能并行的 Stream与此集合作为其来源。
default Stream<E> stream() 返回以此集合作为源的顺序 Stream 。
/*
* 通过集合创建流
*/
List<String> strs = Arrays.asList("Hello", "NBA", "Bird", "Good");
//创建普通流
Stream<String> Stream = strs.stream();
//创建并行流
Stream<String> Stream1 = strs.parallelStream();普通流Stream
在使用Stream之前,建义先理解接口化编程,Stream将完全依赖于接口化编程方式。接下来我们以“打印集合中的每一个元素”为例,了解一下 Stream 和 Iterator的区别。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
numbers.stream().forEach(num->System.out.println(num));
// 输出:1 2 3 4 5 6 7 8 9由以上的列子可以看出,Stream 的遍历方式和结果与 Iterator 没什么差别,这是因为Stream的默认遍历是和迭代器相同的,保证以往使用迭代器的地方可以方便的改写为 Stream。
Stream 的强大之处在于其原型链的设计使得它可以对遍历处理后的数据进行再处理。我们以“对集合中的数字加1,并转换成字符串”为例进行演示。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
List<String> strs = numbers.stream().map(num -> Integer.toString(++num)).collect(Collectors.toList());
strs.forEach(System.out::println);其中map()方法遍历处理每一个元素,并且返回一个新的Stream,随后collect方法将操作后的Stream解析为List。
Stream还提供了非常多的操作,如filter()过滤、skip()偏移等等。
并行流parallelStream
parallelStream提供了流的并行处理,它是Stream的另一重要特性,其底层使用Fork/Join框架实现。简单理解就是多线程异步任务的一种实现。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
numbers.parallelStream().forEach(num->System.out.println(num));
// 输出:3 4 2 6 7 9 8 1 5我们发现,使用parallelStream后,结果并不按照集合原有顺序输出。为了进一步证明该操作是并行的,我们打印出线程信息。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
numbers.parallelStream().forEach(num -> System.out.println(Thread.currentThread().getName() + ">>" + num));结果:
main>>6
main>>5
main>>7
main>>9
ForkJoinPool.commonPool-worker-2>>8
main>>2
ForkJoinPool.commonPool-worker-1>>3
main>>4
ForkJoinPool.commonPool-worker-2>>1通过例子可以确信parallelStream是利用多线程进行的,这可以很大程度简化我们使用并发操作。
stream和parallelstream执行效率
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
public class StreamCompareTest {
public static void main(String[] args) {
// 模拟10000条数据 forEach打印测试
List<Integer> list = new ArrayList();
for (int j = 0; j < 10000; j++) {
list.add(j);
}
// 下面测试下各方法执行的时间 检查效率
long startTime = System.currentTimeMillis();
for (int i = 0; i < list.size(); i++) {
try {
TimeUnit.MILLISECONDS.sleep(1);// 睡眠1毫秒
} catch (InterruptedException e) {
e.printStackTrace();
}
}
long endTime = System.currentTimeMillis();
System.out.println("传统for循环运行时间:" + (endTime - startTime) + "ms");
// 测试单管道stream执行效率
startTime = System.currentTimeMillis();
list.stream().forEach(r -> {
try {
TimeUnit.MILLISECONDS.sleep(1);// 睡眠1毫秒
} catch (Exception e) {
e.printStackTrace();
}
});
long streamendTime = System.currentTimeMillis();
System.out.println("stream : " + (streamendTime - startTime) + "ms");
// 测试多管道parallelStream执行效率
startTime = System.currentTimeMillis();
list.parallelStream().forEach(r -> {
try {
TimeUnit.MILLISECONDS.sleep(1);// 睡眠1毫秒
} catch (Exception e) {
e.printStackTrace();
}
});
long parallelStreamendTime = System.currentTimeMillis();
System.out.println("parallelStream : " + (parallelStreamendTime - startTime) + "ms");
}
}对比发现parallelStream执行效率要比传统的for循环和stream要快的多。
那么什么时候要用stream或者parallelStream呢?可以从以下三点入手考虑
是否需要并行?
任务之间是否是独立的?是否会引起任何竞态条件?
结果是否取决于任务的调用顺序?
1.3.3 创建空的流
static <T> Stream<T> empty() 返回一个空的顺序 Stream 。
//创建一个空的Stream
Stream empty = Stream.empty();1.3.4 创建无限流
static <T> Stream<T> generate(Supplier<T> s) 返回无限顺序无序流,其中每个元素由提供的 Supplier 。
//创建无限流,通过limit提取指定大小
Stream.generate(() -> "number" + new Random().nextInt()).limit(100).forEach(System.out::println);
Stream.generate(() -> new Student("name", 10)).limit(20).forEach(System.out::println);1.3.5 创建规律的无限流
static <T> Stream<T> iterate(T seed, UnaryOperator<T> f) 返回有序无限连续 Stream由函数的迭代应用产生 f至初始元素 seed ,产生 Stream包括 seed , f(seed) , f(f(seed)) ,等
/**
* 产生规律的数据
*/
Stream.iterate(0, x -> x + 1).limit(10).forEach(System.out::println);
System.out.println("---------------------");
Stream.iterate(0, x -> x).limit(10).forEach(System.out::println);
System.out.println("---------------------");
//Stream.iterate(0,x->x).limit(10).forEach(System.out::println);与如下代码意思是一样的
Stream.iterate(0, UnaryOperator.identity()).limit(10).forEach(System.out::println);1.4 中间操作
首先说一下中间操作:多个中间操作可以连接起来形成一个流水线,除非流水线上触发终止操作,否则中间操作不会执行任何的处理!而在终止操作时一次性全部处理,称为“惰性求值”。
1.4.1 筛选与切片
这里面有以下方法:
Stream<T> filter(Predicate<? super T> predicate) 返回由与此给定谓词匹配的此流的元素组成的流。
Stream<T> distinct() 返回由该流的不同元素(根据 Object.equals(Object) )组成的流。
Stream<T> limit(long maxSize) 返回由此流的元素组成的流,截短长度不能超过 maxSize 。
Stream<T> skip(long n) 在丢弃流的第一个 n元素后,返回由该流的 n元素组成的流。
接下来将用代码的方式一一带领大家去看看这个方法的作用,不然只看文字不看效果觉得学习的效果还是不是很好。
filter(Predicate p)方法:
filter(Predicate p) 其中方法的解释上面也说的很清楚了,这里就不在继续啰嗦了,现在有这么一个需求,就是过滤出年龄大于20岁的员工。
List<Employee> emps = Arrays.asList(
new Employee(101, "张三", 28, 9999.0),
new Employee(102, "李四", 49, 666.0),
new Employee(103, "王五", 38, 333.0),
new Employee(104, "赵六", 12, 7777.0),
new Employee(105, "田七", 6, 222.0)
);
emps.stream()
.filter(e -> e.getAge() > 20)
.forEach(System.out::println);distinct()方法:
distinct()方法就是去重,上面的解释也很清楚,注意的是要重写hashCode()方法和equals()方法。
ArrayList<String> wordList = new ArrayList<String>() {
{
add("a");
add("b");
add("c");
add("d");
add("e");
add("f");
add("e");
}
};
Stream<String> words = wordList.stream();
long n = words.distinct().count();
System.out.println(n);limit(long maxSize)方法:
limit(long maxSize) 截取前面maxSize条数据,在上面的代码的基础上我加了个方法。
List<Employee> emps = Arrays.asList(
new Employee(101, "张三", 28, 9999.0),
new Employee(102, "李四", 49, 666.0),
new Employee(103, "王五", 38, 333.0),
new Employee(104, "赵六", 12, 7777.0),
new Employee(105, "田七", 6, 222.0)
);
emps.stream()
.filter(e -> e.getAge() > 20)
.limit(2)
.forEach(System.out::println);skip(long n)方法:
与limit相反的就是skip(long n),跳过前面几条,代码和上面差不多。
List<Employee> emps = Arrays.asList(
new Employee(101, "张三", 28, 9999.0),
new Employee(102, "李四", 49, 666.0),
new Employee(103, "王五", 38, 333.0),
new Employee(104, "赵六", 12, 7777.0),
new Employee(105, "田七", 6, 222.0)
);
emps.stream()
.filter((e) -> e.getAge() > 20)
.skip(2)
.forEach(System.out::println);1.4.2 映射
<R> Stream<R> map(Function<? super T,? extends R> mapper) 接收函数型接口,将元素转换成其他形式或提取信息;接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。
DoubleStream mapToDouble(ToDoubleFunction<? super T> mapper) 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 DoubleStream。
IntStream mapToInt(ToIntFunction<? super T> mapper) 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 IntStream。
LongStream mapToLong(ToLongFunction<? super T> mapper) 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 LongStream。
<R> Stream<R> flatMap(Function<? super T,? extends Stream<? extends R>> mapper) 接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流。
每一个方法的作用这里都写的很清楚了,在接下来的讲解中就直接给出代码了,如果有需要的地方我会提一下。上面我不会全写,我会先写两个常用的,其他的用法都是类似的。
map(Function f)方法:
把所有的元素转换成大写。关于Map,也可以认为是转换流,将一种类型的流转换为另外一种流。
List<String> strList = Arrays.asList("aaa", "bbb", "ccc", "ddd", "eee");
Stream<String> stream = strList.stream().map(String::toUpperCase);
stream.forEach(System.out::println);flatMap(Funtion f)方法:
flatMap可以认为是拆解流,将流中每一个元素拆解成一个流;将一个字符串转化为一个字符集合,然后通过流的方式返回。
定义用来进行转换的方法:
public class StreamApiTest {
public static Stream<Character> filterCharacter(String str){
List<Character> list = new ArrayList<>();
for (Character ch : str.toCharArray()) {
list.add(ch);
}
return list.stream();
}
}通过map和flatMap实现:
List<String> strList = Arrays.asList("abc", "def", "xyz");
Stream<Stream<Character>> stream2 = strList.stream().map(StreamApiTest::filterCharacter);
stream2.forEach((sm) -> {
sm.forEach(System.out::print);
});
System.out.println("\n---------------------");
Stream<Character> stream3 = strList.stream().flatMap(StreamApiTest::filterCharacter);
stream3.forEach(System.out::print);这两种方式实现的效果是一样的,但是可以看map的返回的是一个Stream流中的泛型是一个流,而flatMap返回的流的泛型的是一个Character,然后冲forEach的方式也可以看出其中的差异。
其中mapToDouble,mapToInt,mapToLong返回的是相对应的流,我就实现其中的一个,其他的原理都是一样的,如果有兴趣的同学可以自己去实现一下看看。
List<Double> doubles = Arrays.asList(1D, 2D, 3D, 4D);
DoubleStream ds = doubles.stream().mapToDouble((d) -> d * 2);
ds.forEach(System.out::println);1.4.3 排序
Stream<T> sorted() 返回由此流的元素组成的流,根据自然顺序排序。
Stream<T> sorted(Comparator<? super T> comparator) 返回由该流的元素组成的流,根据提供的 Comparator进行排序。
还是拿一个员工的集合:
List<Employee> emps = Arrays.asList(
new Employee(101, "张三", 28, 9999.0),
new Employee(102, "李四", 49, 666.0),
new Employee(103, "王五", 38, 333.0),
new Employee(104, "赵六", 12, 7777.0),
new Employee(105, "田七", 6, 222.0)
);sorted()方法:
如果是基本类型,那就是自然顺序,由小到大。如果是对象,那就是比较哈希值,由小到大。
@Test
public void test1() {
emps.stream()
.map(Employee::getName)
.sorted()
.forEach(System.out::println);
}根据名字去进行一个自然排序,也就是流中是什么顺序,然后输出的就是什么顺序,看一下排序的结果:
张三
李四
王五
田七
赵六结果和我们期待的是一样的,在看看带有参数的排序的方式。
sorted(Comparator comp)方法:
这个排序是先按照年龄进行排序,如果年龄一样就按照名字进行排序。
@Test
public void test2() {
emps.stream().sorted((x, y) -> {
if (x.getAge() == y.getAge()) {
return x.getName().compareTo(y.getName());
} else {
return Integer.compare(x.getAge(), y.getAge());
}
}).forEach(System.out::println);
}排序的结果:
Employee [id=105, name=田七, age=6, salary=222.0]
Employee [id=104, name=赵六, age=12, salary=7777.0]
Employee [id=101, name=张三, age=28, salary=9999.0]
Employee [id=103, name=王五, age=38, salary=333.0]
Employee [id=102, name=李四, age=49, salary=666.0]1.5 Stream的终止操作
Stream终止操作大概分为这几种:
查找与匹配
归约
收集
1.5.1 查找与匹配
boolean allMatch(Predicate<? super T> predicate) 返回此流的所有元素是否与提供的谓词匹配。
boolean anyMatch(Predicate<? super T> predicate) 返回此流的任何元素是否与提供的谓词匹配。
boolean noneMatch(Predicate<? super T> predicate) 返回此流的元素是否与提供的谓词匹配。
Optional<T> findFirst() 返回描述此流的第一个元素的Optional如果流为空,则返回一个空的Optional 。
Optional<T> findAny() 返回描述流的一些元素的Optional如果流为空,则返回一个空的Optional 。
long count() 返回此流中的元素数。
Optional<T> max(Comparator<? super T> comparator) 根据提供的 Comparator返回此流的最大元素。
Optional<T> min(Comparator<? super T> comparator) 根据提供的 Comparator返回此流的最小元素。
针对于上面的API,我将选几个举例子说明,其他的都是类似的。
1、allMatch
boolean b1 = emps.stream().allMatch((e) -> e.getName().contains("五"));
System.out.println(b1);这个意思就是说,查看每个名字中是否都包含"五",从上面的集合中显而易见,不是每个员工名字中都包含"五",所以打印出false。
2、anyMatch
这个和上面的代码的差不多,allMatch换成anyMatch就好了,根据他的意思,只要有一个匹配,这个应该返回一个true。
boolean b1 = emps.stream().anyMatch((e) -> e.getName().contains("五"));
System.out.println(b1);3、noneMatch
这个和上面的代码的差不多,allMatch换成noneMatch就好了,根据他的意思,这个应该返回一个false。
4、findFirst
Optional<Employee> op = emps.stream()
.sorted((e1,e2) -> Double.compare(e1.getSalary(), e2.getSalary()))
.findFirst();
System.out.println(op.get());其他的用法都是类似的,很简单,这里就不多啰嗦了。
// findAny——返回当前流中的任意元素
// 这个操作的行为显然是不确定的; 可以自由选择流中的任何元素。
Optional<Employee> findAny = emps.stream().findAny();
System.out.println("流里面的某个员工是:"+findAny.get());
//工资最大值
Optional<Employee> max = emps.stream().max((o1,o2)->Double.compare(o1.getSalary(), o2.getSalary()));
System.out.println("最大工资是:"+max.get().getSalary());
//工资最小值
Optional<Employee> min = emps.stream().min((o1,o2)->Double.compare(o1.getSalary(), o2.getSalary()));
System.out.println("最小工资是:"+min.get().getSalary());1.5.2 归约
T reduce(T identity, BinaryOperator<T> accumulator) 使用提供的身份值和 associative累积功能对此流的元素执行 reduction ,并返回减小的值。
Optional<T> reduce(BinaryOperator<T> accumulator) 使用 associative累积函数对此流的元素执行 reduction ,并返回描述减小值的 Optional (如果有)。
备注:map 和 reduce 的连接通常称为 map-reduce 模式,因 Google 用它来进行网络搜索而出名。
看下面的例子:
List<Integer> list = Arrays.asList(1,2,3,4,5,6,7,8,9,10);
Integer sum = list.stream().reduce(0, (x, y) -> x + y);
System.out.println(sum);一个整数集合,然后通过reduce,从0开始,0会被当做x,然后在集合中取1当做y值,然后进行x+y操作返回1,然后在把1当做x值,在到集合中取一个2当做y值,以此类推,然后求和sum就是等于55。
再举一个例子:
Optional<Double> op = emps.stream().map(Employee::getSalary).reduce(Double::sum);
System.out.println(op.get()); //显示员工薪水的总和。1.5.3 收集
<R,A> R collect(Collector<? super T,A,R> collector) 将流转换为其他形式。接收一个 Collector接口的实现,用于给Stream中元素做汇总的方法,Collector 接口中方法的实现决定了如何对流执行收集操作(如收集到 List、Set、Map)。
但是 Collectors 实用类提供了很多静态方法,可以方便地创建常见收集器实例。这里面的静态方法有很多。大家可以去查看一下API。接下来我将举几个栗子让大家看看效果。
我先列举一些方法:
static <T> Collector<T,?,List<T>> toList() 返回一个 Collector,它将输入元素 List到一个新的 List 。
static <T> Collector<T,?,Set<T>> toSet() 返回一个 Collector ,将输入元素 Set到一个新的 Set 。
static <T,C extends Collection<T>> Collector<T,?,C> toCollection(Supplier<C> collectionFactory) 返回一个 Collector ,按照遇到的顺序将输入元素累加到一个新的 Collection中。
static <T> Collector<T,?,Long> counting() 返回 Collector类型的接受元件 T计数输入元件的数量。
Double summingDouble(ToDoubleFunction<? super T> mapper) 对流中元素的整数属性求和。
Integer averagingInt(ToIntFunction<? super T> mapper) 计算流中元素Integer属性的平均值。
summarizingInt IntSummaryStatistics 收集流中Integer属性的统计值。
将员工中的名字全部拿出来放到集合中,如果名字有重复的,而你又想去重,你可以放到Set集合中。
List<String> list = emps.stream()
.map(Employee::getName)
.collect(Collectors.toList());
list.forEach(System.out::println);
Set<String> set = emps.stream()
.map(Employee::getName)
.collect(Collectors.toSet());
set.forEach(System.out::println);比如对员工的薪水求和,平均值,这些都可以。到这里Stream API也就将的差不多了,有需要的可以看看。
Double sum = emps.stream()
.collect(Collectors.summingDouble(Employee::getSalary));
Double avg = emps.stream()
.collect(Collectors.averagingDouble(Employee::getSalary));其他例子
String[] arr1 = {"abc","a","bc","abcd"};/**
* Comparator.comparing是一个键提取的功能
* 以下两个语句表示相同意义
*/
@Test
public void testSorted1_(){
/**
* 按照字符长度排序
*/
Arrays.Stream(arr1).sorted((x,y)->{
if (x.length()>y.length())
return 1;
else if (x.length()<y.length())
return -1;
else
return 0;
}).forEach(System.out::println);
Arrays.Stream(arr1).sorted(Comparator.comparing(String::length)).forEach(System.out::println);
}
/**
* 倒序
* reversed(),java8泛型推导的问题,所以如果comparing里面是非方法引用的lambda表达式就没办法直接使用reversed()
* Comparator.reverseOrder():也是用于翻转顺序,用于比较对象(Stream里面的类型必须是可比较的)
* Comparator. naturalOrder():返回一个自然排序比较器,用于比较对象(Stream里面的类型必须是可比较的)
*/
@Test
public void testSorted2_(){
Arrays.Stream(arr1).sorted(Comparator.comparing(String::length).reversed()).forEach(System.out::println);
Arrays.Stream(arr1).sorted(Comparator.reverseOrder()).forEach(System.out::println);
Arrays.Stream(arr1).sorted(Comparator.naturalOrder()).forEach(System.out::println);
}
/**
* thenComparing
* 先按照首字母排序
* 之后按照String的长度排序
*/
@Test
public void testSorted3_(){
Arrays.Stream(arr1).sorted(Comparator.comparing(this::com1).thenComparing(String::length)).forEach(System.out::println);
}public char com1(String x){
return x.charAt(0);
}二、接口的default/static方法
JDK8之前的接口中通常只声明方法的声明,方法的具体实现在子类中进行。JDK8打破了这样的用法:接口中可以实现具体的方法体,只需要加上关键字static 或者 default修饰即可。
1、使用static来修饰的称之为静态方法,静态方法通过接口名来调用;
2、使用default来修饰的称之为默认方法,默认方法通过对象实例来调用;
一个接口可以有多个静态方法和default方法,没有个数限制。
静态方法和默认方法都有自己的方法体,用于提供一套默认的实现,这样,子类对于该方法就不需要强制来实现,可以选择使用默认的实现,也可以重写自己的实现。当为接口扩展方法时,只需要提供该方法的默认实现即可。至于对应实现类可以重写也可以使用默认的实现,这样所有的实现类就不会报语法错误;
使用示例:
IGreeting接口定义了三个方法:一个普通的抽象方法,一个静态方法,一个默认方法。
public interface IGreeting {
// 抽象方法
public abstract void sayGoodMorning();
// 静态方法
public static void sayGoodAfternoon(){
System.out.println("静态方法: sayGoodAfternoon");
}
// 默认方法
public default void sayGoodEvening(){
System.out.println("默认方法: sayGoodEvening");
}
}定义接口的实现类,通过idea的提示我们可以看到子类只能实现抽象方法和默认方法,而不能实现静态方法。
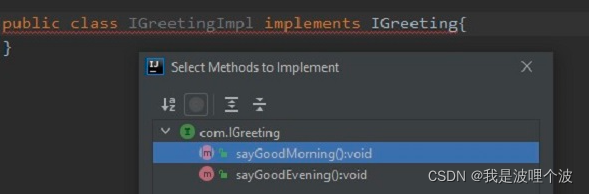
实现抽象方法和默认方法:
public class IGreetingImpl implements IGreeting{
/*
* 实现抽象方法
* */
@Override
public void sayGoodMorning() {
System.out.println("实现类IGreetingImpl: sayGoodMorning");
}
/*
* 实现默认方法
* */
@Override
public void sayGoodEvening() {
System.out.println("实现类IGreetingImpl: sayGoodEvening");
}
}总结:
1、接口中的abstract抽象方法通过实例对象来调用。
2、接口中的default方法通过实例对象来调用;default方法可以重写也可以不重写,关于default的方法的重写,我们在实现类中不需要继续出现default关键字也不能出现default关键字。
3、接口中的静态方法通过接口名.方法名()的方式来调用。
4、接口是不允许直接使用new的方式来获取实例的,如果new可以使用匿名实现类的方式:new后面跟上一对花括号来实现接口中的抽象方法。(匿名实现类:顾名思义没有名称的实现类,优点是不用再单独声明一个类;缺点是没有名字,不能重复使用,只能使用一次。)
















 249
249











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











