









基于SparkStreaming对银行日志分析,实时技术架构图
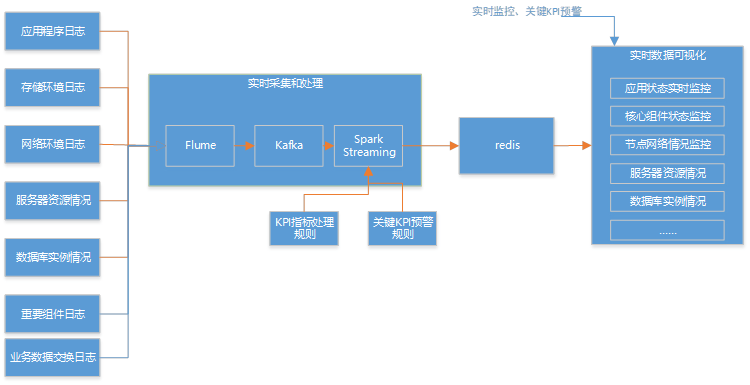
通过flume实时采集原日志,送到kafka缓存,SparkStreaming准实时从kafka拿数据,经过ETL、聚合计算送到redis,供前端展示,具体技术及代码见后面博客;
除了实时部分,还有离线这一块,技术框架如下:
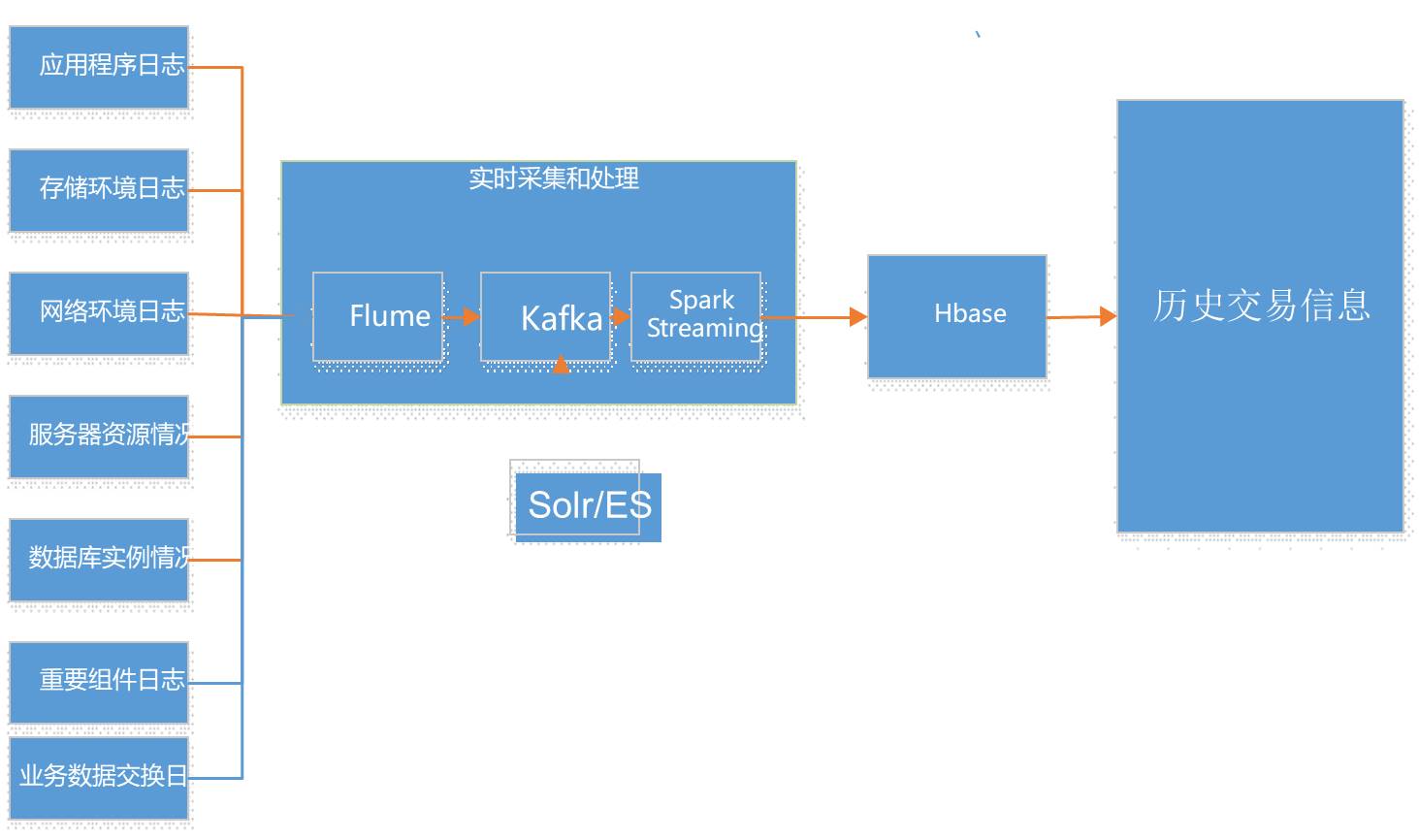
前面都一样,只是通过SparkStreaming ETL后,不聚合计算直接插入hbase,供做离线批量和历史查询,主要是注意Hbase rowkey的设置,具体技术和代码见后面博客。
基于SparkStreaming对银行日志分析,实时技术架构图
通过flume实时采集原日志,送到kafka缓存,SparkStreaming准实时从kafka拿数据,经过ETL、聚合计算送到redis,供前端展示,具体技术及代码见后面博客;
除了实时部分,还有离线这一块,技术框架如下:
前面都一样,只是通过SparkStreaming ETL后,不聚合计算直接插入hbase,供做离线批量和历史查询,主要是注意Hbase rowkey的设置,具体技术和代码见后面博客。
 4781
4781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
























