










DateSet的API详解十六
writeAsCsv
def writeAsCsv(filePath: String, rowDelimiter: String = ...,
fieldDelimiter: String = ..., writeMode: WriteMode = null): DataSink[T]
参数说明:
rowDelimiter:行分隔符
fieldDelimiter:列分隔符
Writes this DataSet to the specified location as CSV file(s).
将DataSet以CSV格式写出到存储系统。路径写法参考writeAsText。
执行程序:
//1.创建 DataSet[Student]
case class Student(age: Int, name: String,height:Double)
val input: DataSet[Student] = benv.fromElements(
Student(16,"zhangasn",194.5),
Student(17,"zhangasn",184.5),
Student(18,"zhangasn",174.5),
Student(16,"lisi",194.5),
Student(17,"lisi",184.5),
Student(18,"lisi",174.5))
//2.将DataSet写出到存储系统
input. writeAsCsv("hdfs:///output/flink/dataset/testdata/students.csv","#","|")
//3.执行程序
benv.execute()hadoop web ui中的执行效果:
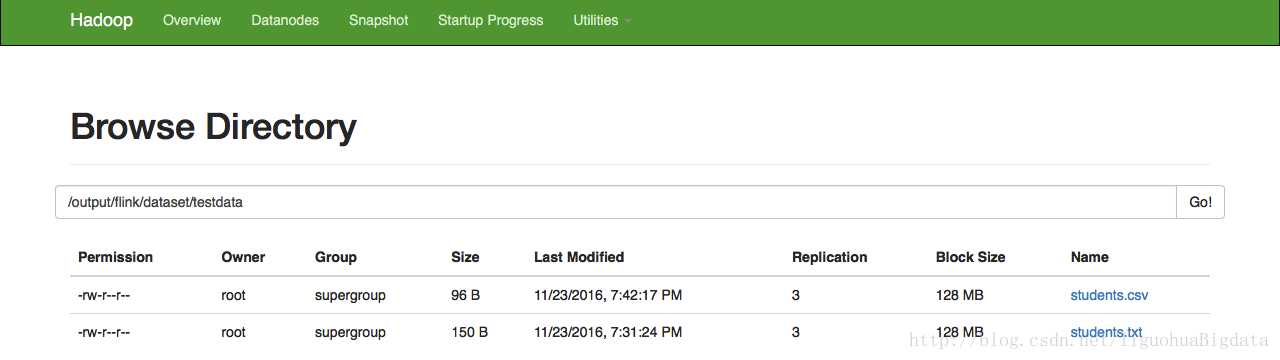
terminal中查看文件效果:

getExecutionEnvironment
def getExecutionEnvironment: ExecutionEnvironment
Returns the execution environment associated with the current DataSet.
获取DataSet的执行环境上下文,这个歌上下文和当前的DataSet有关,不是全局的。执行程序:
//1.创建一个 DataSet其元素为String类型
val input0: DataSet[String] = benv.fromElements("A", "B", "C")
val input1: DataSet[String] = benv.fromElements("A", "B")
//2.获取DataSet的执行环境上下文。
benv
val env0=input0.getExecutionEnvironment
val env1=input1.getExecutionEnvironment
env0==env1执行结果:
Scala-Flink> benv
res96: org.apache.flink.api.scala.ExecutionEnvironment =
org.apache.flink.api.scala.ExecutionEnvironment@2efd2f21
Scala-Flink> val env0=input0.getExecutionEnvironment
env0: org.apache.flink.api.scala.ExecutionEnvironment =
org.apache.flink.api.scala.ExecutionEnvironment@4f87dfc6
Scala-Flink> val env1=input1.getExecutionEnvironment
env1: org.apache.flink.api.scala.ExecutionEnvironment =
org.apache.flink.api.scala.ExecutionEnvironment@1a46d614
Scala-Flink> env0==env1
res97: Boolean = falseAggregate
def aggregate(agg: Aggregations, field: String): AggregateDataSet[T]
def aggregate(agg: Aggregations, field: Int): AggregateDataSet[T]
Creates a new DataSet by aggregating the specified tuple field using the given aggregation function.CoGroup
def
coGroup[O](other: DataSet[O])(implicit arg0: ClassTag[O]): UnfinishedCoGroupOperation[T, O]
For each key in this DataSet and the other DataSet, create a tuple
containing a list of elements for that key from both DataSets.combineGroup
def combineGroup[R](fun: (Iterator[T], Collector[R]) ⇒
Unit)(implicit arg0: TypeInformation[R], arg1: ClassTag[R]): DataSet[R]
def combineGroup[R](combiner: GroupCombineFunction[T, R])
(implicit arg0: TypeInformation[R], arg1: ClassTag[R]): DataSet[R]
Applies a GroupCombineFunction on a grouped DataSet.














 661
661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









