










一、基于JVM的大数据生态圈
1.bigdata on jvm
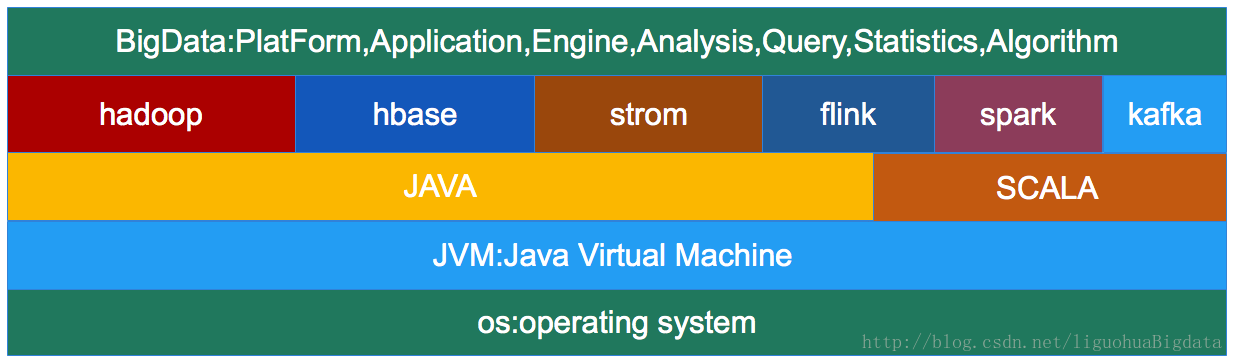
1.现在大多数开源大数据处理框架都是基于jvm的,像 Apache Hadoop,Apache Spark,Apache Hbase,
Apache Kafka,Apache Flink等。
2.JVM上的程序一方面享受着它带来的好处,也要承受着JVM带来的弊端。2.jvm的弊端

1.JVM的OOM问题
利用JVM平台开发的程序都会受到OutOfMemoryError的困扰,特别是大数据领域分布式计算框架,他们需要大量的内存,
不得不经常面临这个头疼的问题,当JVM中所有对象大小超过分配给JVM的内存大小时,就会发生OutOfMemoryError错误,
导致JVM崩溃,所有在JVM上工作的程序都将无一幸免的受到影响。
2.Full GC
JVM的GC机制一直都是让人又爱又恨的东西。一方面,JVM自己管理内存,减轻开发者的负担,提高开发效率,保障内存安全。
另一方面,不受开发者控制的GC想一颗定时炸弹一样,一旦JVM进行大规模的垃圾回收,所有基于jvm的程序都不再工作,这将
极大的影响实时应用的可靠交付。特别是大数据领域,在处理大量数据的时候,不可避免的的创建了大量的临时对象,一旦对象
使用完毕后,JVM就不定期的进行大规模的垃圾回收工作,这对大数据应用影响很大。
3.Java对象存储密度低
例一:一个只包含boolean属性的对象占用了16个字节内存:对象头占了8个,boolean 属性占了1个,对齐填充占了7个。
而实际上只需要一个bit(1/8字节)就够了。
例二:“abcd”这样简单的字符串在UTF-8编码中需要4个字节存储,但Java采用UTF-16编码存储字符串,需要8个字节存储
“abcd”,同时Java对象还对象header等其他额外信息,一个4字节字符串对象,在Java中需要48字节的空间来存储。
对于大部分的大数据应用,内存都是稀缺资源,更有效率的内存存储,则意味着CPU数据访问吞吐量更高,及更少的磁盘落地。注意:
现在很多大数据处理引擎,开始自动动手管理内存。比如 Apache Drill,Apache Ignite,Apache Geode,Apache Spark等。 














 803
803











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









