






原文链接:https://medium.com/@JasonWyatt/squeezing-performance-from-sqlite-insertions-971aff98eef2

有时我们需要在应用程序中管理大量的数据。将所有数据导入Android应用程序的SQLite数据库中最快的方式是什么?
在这篇文章中,我将调查向SQLite数据库中插入大量数据的可行方法,评估每种方法的性能,并发现一些最佳实现。
测试方法
每个实验涉及两种或多种将1000,10000和100000个随机生成的记录插入到两种不同类型的表中方法的比较:
- 一个非常简单的表(
simple)由单个整数列组成, - 一个更现实的表(
track),描述了音乐曲目的集合,其中每个包含id,标题,持续时间,歌词等。id列是此表的PRIMARY KEY。
我在16GB Nexus 5X上执行所有测试,运行API为25级(牛轧糖)。
通过跟踪当前迭代的所有插入运行时所使用的时间来计算结果。每次迭代时不包含连接到数据库和擦除表的时间。
可以从GitHub下载源代码,并自行构建/运行测试应用程序,如果你需要!
勘探
db.insert()带或不带显式事务
Android的SQLite绑定的官方培训材料提供了使用SQLiteDatabase对象的insert()方法填充表的示例。不幸的是,对于如何一次插入大量数据,他们并没有提出任何建议。
simple表的简单方法看起来像这样:
ContentValues values = new ContentValues(1);
for (int i = 0; i < numIterations; i++) {
values.put('val', random.nextInt());
db.insert("inserts_1", null, values);
}我认为可以通过在事务中执行db.insert()调用来提高一些性能,所以我做了第一个实验:
db.beginTransaction();
ContentValues values = new ContentValues(1);
for (int i = 0; i < numIterations; i++) {
values.put('val', random.nextInt());
db.insert("inserts_1", null, values);
}
db.setTransactionSuccessful();
db.endTransaction();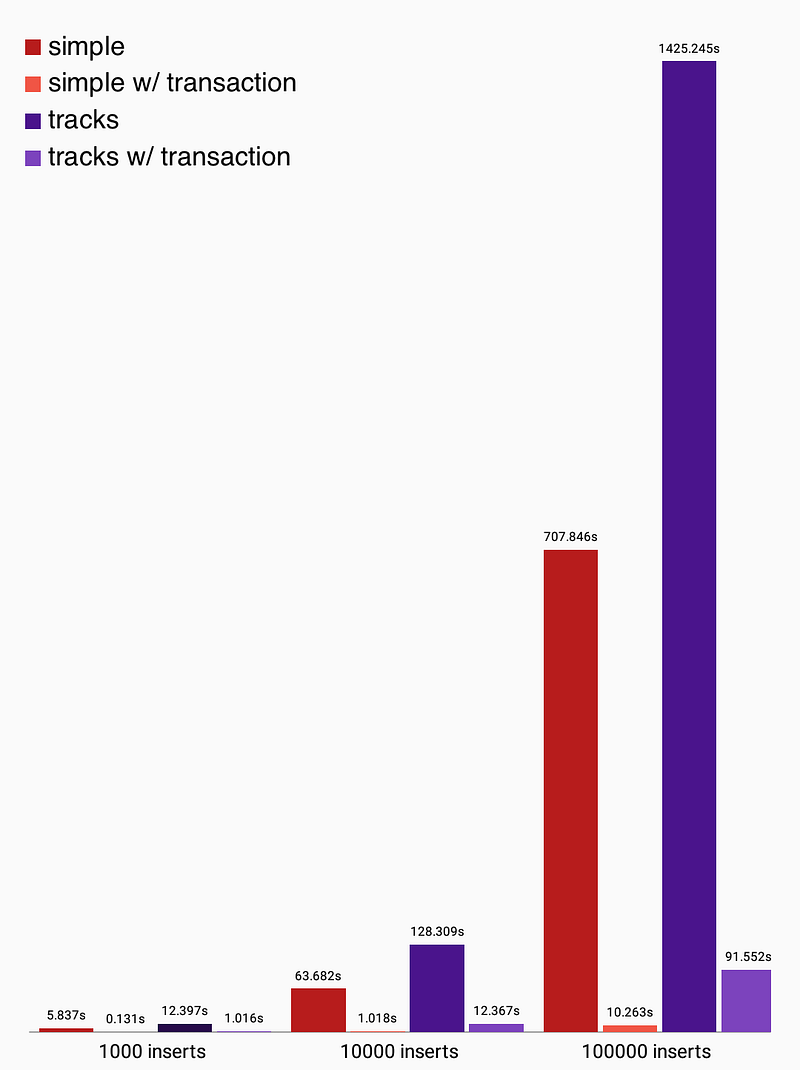
看一下图表,很明显,与不用事务包装比,将一堆insert()调用包装到一个事务中极大地提高了性能。
但为什么这么快呢?
事实证明,除非显式的在beginTransaction()和endTransaction()调用之间执行查询,否则SQLite本身将使用隐式事务来包装每个查询。从文档:
只有在事务中才能对数据库进行更改。任何更改数据库的命令(基本上,除SELECT之外的任何SQL命令)都将自动启动事务(如果尚未生效)。自动启动的事务在最后一个查询完成时被提交。
重要的是要注意,一旦事务提交后,SQLite才会将插入数据写入磁盘。因此,如果可以最小化事务数量(无论是显式还是隐式启动),都将最大限度地减少磁盘访问并最大限度地提高性能。将图表中的数据转换为每秒插入的记录数:
- 隐式事务:每秒大约插入75个
track记录。 - 显式事务:每秒大约插入950
track记录。
只需3行代码,带来了10倍提升!
现在我们知道使用事务是一个巨大的优势,从这里开始当我们用其他方式插入数据时,我们都将使用事务。
db.execSQL()
SQLiteDatabase暴露的另一个将数据插入到表的方法是db.execSQL(String,Object[])。它提供了一种质朴方式来执行非选择语句。 以下是我们的实验代码:
db.beginTransaction();
Object[] values = new Object[1];
for (int i = 0; i < numIterations; i++) {
values[0] = random.nextInt();
db.execSQL("INSERT INTO inserts_1 (val) VALUES (?)", values);
}
db.setTransactionSuccessful();
db.endTransaction();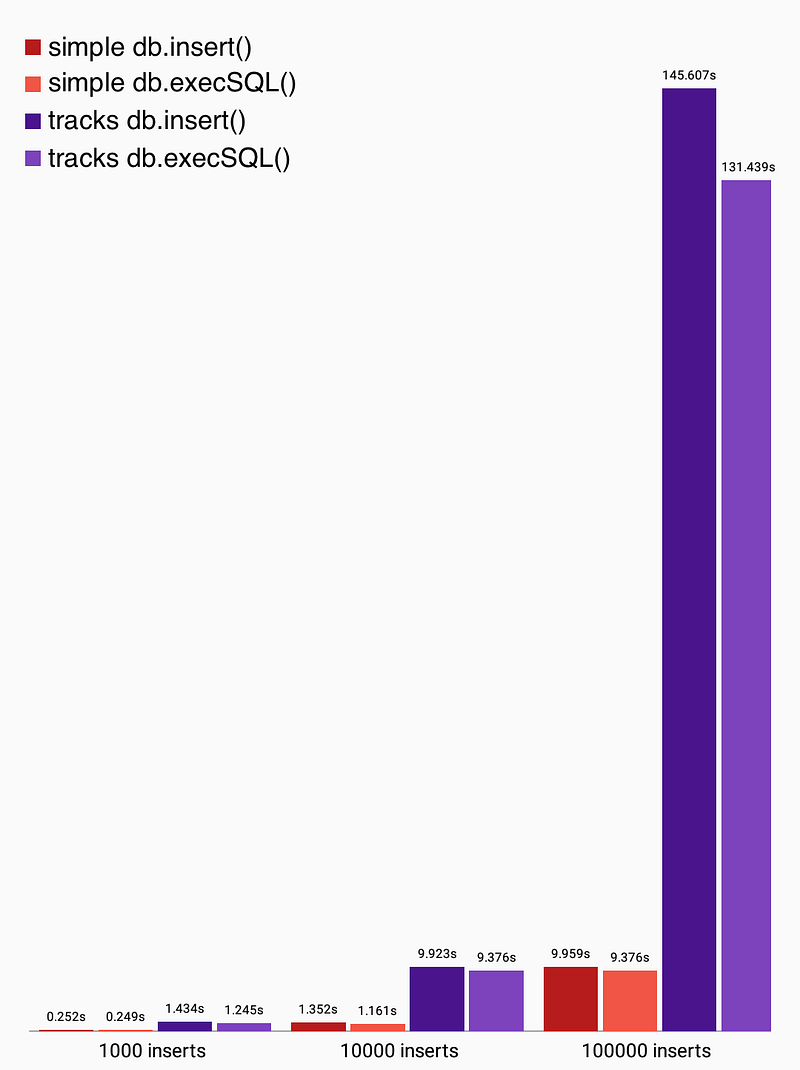
在本实验中,通过使用db.execSQL(),我们可以稍微提升我们每秒插入的记录:
db.insert(): 每秒大约850条track记录。db.execSQL(): 每秒大约925条track记录。
如果你考虑它,这是完美的; db.insert()本质上是语法糖,它抽离出创建SQL语句。这个抽象层虽然不是超级昂贵,但也不是免费的。
使用db.execSQL()进行批量插入
我们使用原始语句和db.execSQL()改进了一些性能,所以现在我想自己构建语句:一次插入多个记录会怎样?
我最初认为,因为SQLite是一个进程内数据库引擎,我们不一定会通过批量插入来保存任何东西(与数据库服务器不同,每个语句会引起网络延迟)。
我第一次尝试将所有插入放人一个批量操作:
db.beginTransaction();
Object[] values = new Object[numIterations];
StringBuilder valuesBuilder = new StringBuilder();
for (int i = 0; i < numIterations; i++) {
if (i != 0) {
valuesBuilder.append(", ");
}
values[i] = mRandom.nextInt();
valuesBuilder.append("(?)");
}
db.execSQL(
"INSERT INTO inserts_1 (val) VALUES "+valuesBuilder.toString(),
values
);
db.setTransactionSuccessful();
db.endTransaction();
太多的SQL变量
事实证明,在SQLite源代码中,它们对准备语句中允许的变量数量设置了硬编码限制。 从sqlite3.c:
/*
** The maximum value of a ?nnn wildcard that the parser will accept.
*/
#ifndef SQLITE_MAX_VARIABLE_NUMBER
# define SQLITE_MAX_VARIABLE_NUMBER 999
#endif如果你不介意狡猾点,用这个方法来解决这个问题并不难:
db.beginTransaction();
doInsertions(db, numIterations);
db.setTransactionSuccessful();
db.endTransaction();
// ... elsewhere in the class ...
void doInsertions(SQLiteDatabase db, int numInsertions) {
if (total > 999) {
doInsertions(db, numInsertions - 999);
numInsertions = 999;
}
Object[] values = new Object[numInsertions];
StringBuilder valuesBuilder = new StringBuilder();
for (int i = 0; i < numInsertions; i++) {
if (i != 0) {
valuesBuilder.append(", ");
}
values[i] = mRandom.nextInt();
valuesBuilder.append("(?)");
}
db.execSQL(
"INSERT INTO inserts_1 (val) VALUES "
+valuesBuilder.toString(),
values
);
}使用递归让它超级容易,但如果这不是你的风格或不适合你的情况,循环也很酷。我猜。
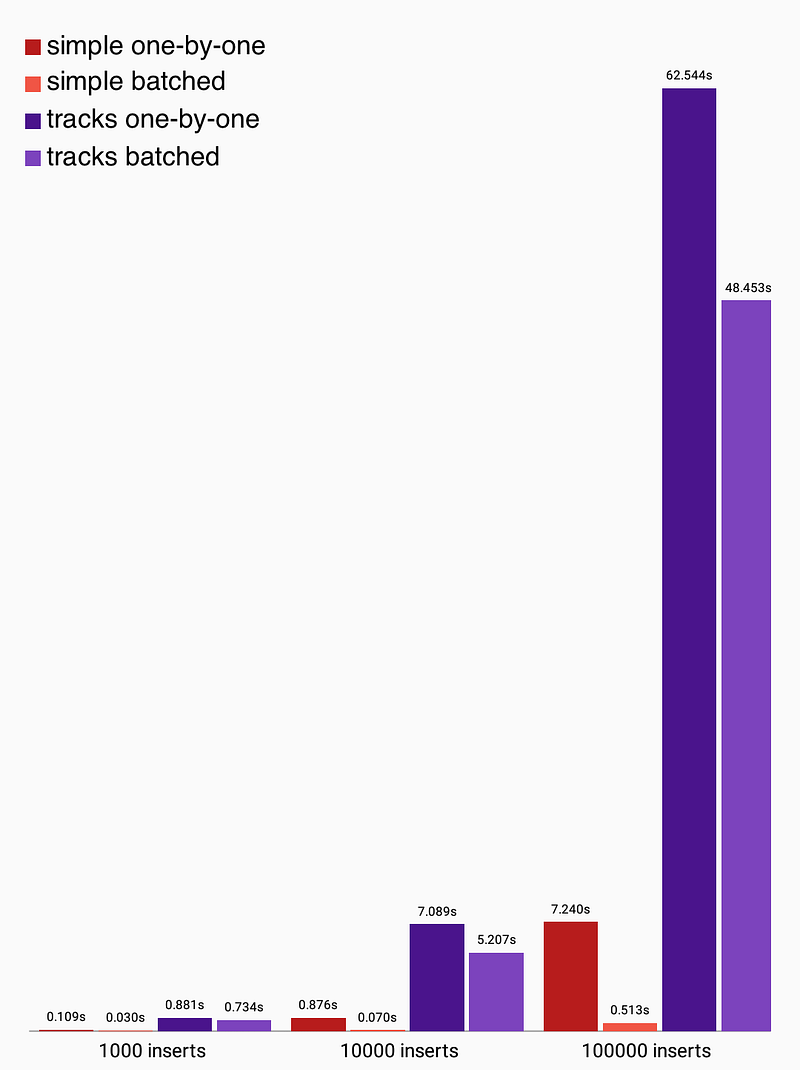
哇!事实证明,即使我们不通过批量插入来节省任何网络延迟,也不需要做这么多单独的语句,就获得了一些额外的性能提升。
然而,需要注意的一点是:表的列数越多,插入的批处理操作就越少。这是因为每个语句可以插入的记录数等于999 / # 列。track表有9列,这意味着对db.execSQL()的每个批量插入调用只能插入111个记录。同时,简单的情况只有一列——允许每批插入999条记录。
再次运行吞吐量数据:
- 逐条插入:每秒~1400条
track记录 - 批量插入:每秒~1800条
track记录
直接使用SQLiteStatment
在我发布了这篇博客的第一稿之后,我发现了#AndroidChat的一个朋友,他还指出了一个我应该运行的实验:
不使用SQLiteDatabase的可用方法,直接尝试使用底层的SQLiteStatement类又会怎样呢?
这个想法与从insert()到execSQL()的逻辑是一样的:跨过中间人。当调用这两种方法时,底层都使用了SQLiteStatement,因此直接使用语句对象可能会加快速度。
另外,如果可以重复使用SQLiteStatement对象,可能能够看到更多的性能提升,因为不必创建这么多对象。
我使用SQLiteStatement写了两个版本的测试用例:一个每次执行相同的单记录插入语句,一个重用批量插入语句。
SQLiteStatement的单记录/逐一插入代码:
SQLiteStatement stmt = db.compileStatement(
"INSERT INTO inserts_1 (val) VALUES (?)"
);
db.beginTransaction();
for (int i = 0; i < numIterations; i++) {
stmt.bindLong(1, random.nextInt());
stmt.executeInsert();
stmt.clearBindings();
}
db.setTransactionSuccessful();
db.endTransaction();批处理插入的代码,使用递归技巧,从之前存储在基于HashMap的大小索引缓存中的语句:
Map<Integer, SQLiteStatement> statementCache = new HashMap<>();
db.beginTransaction();
doInsertions(db, numInsertions, statementCache);
db.setTransactionSuccessful();
db.endTransaction();
// ... elsewhere in the class ...
void doInsertions(SQLiteDatabase db, int numInsertions,
Map<Integer, SQLiteStatement> statementCache) {
if (numInsertions > 999) {
doInsertions(db, numInsertions - 999, statementCache);
total = 999;
}
SQLiteStatement stmt;
if (statementCache.containsKey(numInsertions)) {
stmt = statementCache.get(numInsertions);
} else {
StringBuilder valuesBuilder = new StringBuilder();
for (int i = 0; i < numInsertions; i++) {
if (i != 0) {
valuesBuilder.append(", ");
}
valuesBuilder.append("(?)");
}
stmt = db.compileStatement(
"INSERT INTO inserts_1 (val) VALUES "
+ valuesBuilder.toString()
);
statementCache.put(numInsertions, stmt);
}
for (int i = 0; i < numInsertions; i++) {
stmt.bindLong(i+1, random.nextInt());
}
stmt.executeInsert();
stmt.clearBindings();
}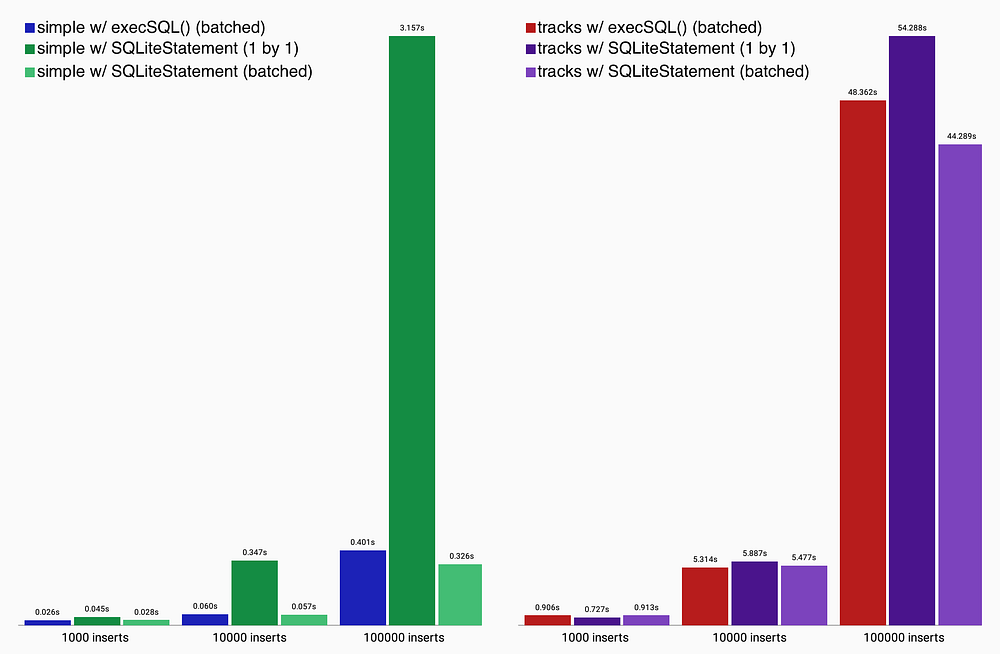
从图表中可以清楚的看出,重用SQLiteStatement对象单记录插入并不比使用db.execSQL()的批处理插入快。然而,重用批处理插入语言的范式似乎在性能上得到了一些提升,代价是增加了代码的复杂度。
结论
从这篇文章中脱颖而出的第一件最重要的事情是将插入操作明确地封装在一个事务中,使得性能得到巨大而明确的改进。
之后,您可以通过使用db.execSQL()与批量插入语句来获得一些合理的速度改进,特别是表的列数很小。
最后,如果确实希望在插入数据时最大限度地压榨SQLite:请考虑直接重SQLiteStatement批量插入对象,从而剔除更多的中间人代码。
延伸阅读:压榨SQLite性能:解释虚拟数据库引擎















 4295
4295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









