







Hadoop MapReduce之jar文件上传
在提交作业时,我们经常会执行下面类似命令:hadoop jar wordcount.jar test.WordCount,然后等待作业完成,查看结果。在作业执行流程中客户端会把jar文件上传至HDFS内,然后由JT初始化作业,并发放给TT执行具体的任务,这里我们主要看客户端的操作,了解这些我们可以自定义更为方便的作业提交方式。hadoop是一个shell脚本,根据不同参数执行不同的分支,在作业提交时,最终会调用org.apache.hadoop.util.RunJar这个类的main函数。
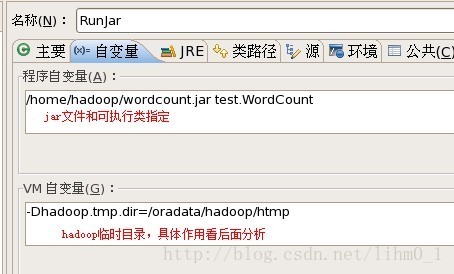
RunJar的main函数可以接受参数,最简单的情况下,我们执行jar文件和main函数类就可以了。在一般流程中,执行该类之前,hadoop脚本会做初始化工作,如设置相关目录、设置classpath、初始化系统变量等操作。
在main函数中会判断参数传入是否正确,解压jar文件,进入作业的main函数
在提交作业时,我们经常会执行下面类似命令:hadoop jar wordcount.jar test.WordCount,然后等待作业完成,查看结果。在作业执行流程中客户端会把jar文件上传至HDFS内,然后由JT初始化作业,并发放给TT执行具体的任务,这里我们主要看客户端的操作,了解这些我们可以自定义更为方便的作业提交方式。hadoop是一个shell脚本,根据不同参数执行不同的分支,在作业提交时,最终会调用org.apache.hadoop.util.RunJar这个类的main函数。
RunJar的main函数可以接受参数,最简单的情况下,我们执行jar文件和main函数类就可以了。在一般流程中,执行该类之前,hadoop脚本会做初始化工作,如设置相关目录、设置classpath、初始化系统变量等操作。
在main函数中会判断参数传入是否正确,解压jar文件,进入作业的main函数
public static void main(String[] args) throws Throwable {
String usage = "RunJar jarFile [mainClass] args...";
//参数个数判断
if (args.length < 1) {
System.err.println(usage);
System.exit(-1);
}
int firstArg = 0;
String fileName = args[firstArg++];
File file = new File(fileName);
String mainClassName = null;
JarFile jarFile;
try {
//建立jar文件
jarFile = new JarFile(fileName);
} catch(IOException io) {
throw new IOException("Error opening job jar: " + fileName)
.initCause(io);
}
//获取jar文件清单
Manifest manifest = jarFile.getManifest();
if (manifest != null) {
mainClassName = manifest.getMainAttributes().getValue("Main-Class");
}
jarFile.close();
if (mainClassName == null) {
if (args.length < 2) {
System.err.println(usage);
System.exit(-1);
}
mainClassName = args[firstArg++];
}
mainClassName = mainClassName.replaceAll("/", ".");
//获取临时目录,用于解压
File tmpDir = new File(new Configuration().get("hadoop.tmp.dir"));
//创建解压目录
tmpDir.mkdirs();
if (!tmpDir.isDirectory()) {
System.err.println("Mkdirs failed to create " + tmpDir);
System.exit(-1);
}
//在临时目录中创建工作目录
final File workDir = File.createTempFile("hadoop-unjar", "", tmpDir);
workDir.delete();
workDir.mkdirs();
if (!workDir.isDirectory()) {
System.err.println("Mkdirs failed to create " + workDir);
System.exit(-1);
}
//设置回调函数,待完成时删除工作目录
Runtime.getRuntime().addShutdownHook(new Thread() {
public void run() {
try {
FileUtil.fullyDelete(workDir);
} catch (IOException e) {
}
}
});
//解压jar文件
unJar(file, workDir);
//设置classpath,注意classes和lib都会加入其中
ArrayList<URL> classPath = new ArrayList<URL>();
classPath.add(new File(workDir+"/").toURL());
classPath.add(file.toURL());
classPath.add(new File(workDir, "classes/").toURL());
File[] libs = new File(workDir, "lib").listFiles();
if (libs != null) {
for (int i = 0; i < libs.length; i++) {
classPath.add(libs[i].toURL());
}
}
ClassLoader loader =
new URLClassLoader(classPath.toArray(new URL[0]));
//获得main函数,通过动态代理调用
Thread.currentThread().setContextClassLoader(loader);
Class<?> mainClass = Class.forName(mainClassName, true, loader);
Method main = mainClass.getMethod("main", new Class[] {
Array.newInstance(String.class, 0).getClass()
});
String[] newArgs = Arrays.asList(args)
.subList(firstArg, args.length).toArray(new String[0]);
try {
//开始调用,进入我们作业的main函数
main.invoke(null, new Object[] { newArgs });
} catch (InvocationTargetException e) {
throw e.getTargetException();
}
}public class WordCount {
public static void main(String[] args) throws Exception {
// 创建一个job
Configuration conf = new Configuration();
Job job = new Job(conf, "WordCount");
job.setJarByClass(WordCount.class);
// 设置输入输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 设置map和reduce类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReduce.class);
// 设置输入输出流
FileInputFormat.addInputPath(job, new Path("/tmp/a.txt"));
FileOutputFormat.setOutputPath(job, new Path("/tmp/output"));
//等待作业完成
System.exit(job.waitForCompletion(true)?0:1);
}
}public boolean waitForCompletion(boolean verbose
) throws IOException, InterruptedException,
ClassNotFoundException {
if (state == JobState.DEFINE) {
submit();//提交
}
if (verbose) {
jobClient.monitorAndPrintJob(conf, info);
} else {
info.waitForCompletion();//监控
}
return isSuccessful();//返回
} public void submit() throws IOException, InterruptedException,
ClassNotFoundException {
ensureState(JobState.DEFINE);
setUseNewAPI();
// Connect to the JobTracker and submit the job
connect();
info = jobClient.submitJobInternal(conf);
super.setJobID(info.getID());
state = JobState.RUNNING;
}
public
RunningJob submitJobInternal(final JobConf job
) throws FileNotFoundException,
ClassNotFoundException,
InterruptedException,
IOException {
/*
* configure the command line options correctly on the submitting dfs
*/
return ugi.doAs(new PrivilegedExceptionAction<RunningJob>() {
public RunningJob run() throws FileNotFoundException,
ClassNotFoundException,
InterruptedException,
IOException{
JobConf jobCopy = job;
Path jobStagingArea = JobSubmissionFiles.getStagingDir(JobClient.this,
jobCopy);
JobID jobId = jobSubmitClient.getNewJobId();
Path submitJobDir = new Path(jobStagingArea, jobId.toString());
jobCopy.set("mapreduce.job.dir", submitJobDir.toString());
JobStatus status = null;
try {
populateTokenCache(jobCopy, jobCopy.getCredentials());
//jar文件,配置文件的上传在此完成
copyAndConfigureFiles(jobCopy, submitJobDir);
// get delegation token for the dir
TokenCache.obtainTokensForNamenodes(jobCopy.getCredentials(),
new Path [] {submitJobDir},
jobCopy);
Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir);
int reduces = jobCopy.getNumReduceTasks();
InetAddress ip = InetAddress.getLocalHost();
if (ip != null) {
job.setJobSubmitHostAddress(ip.getHostAddress());
job.setJobSubmitHostName(ip.getHostName());
}
JobContext context = new JobContext(jobCopy, jobId);
// 检测输出目录是否合法
if (reduces == 0 ? jobCopy.getUseNewMapper() :
jobCopy.getUseNewReducer()) {
org.apache.hadoop.mapreduce.OutputFormat<?,?> output =
ReflectionUtils.newInstance(context.getOutputFormatClass(),
jobCopy);
output.checkOutputSpecs(context);
} else {
jobCopy.getOutputFormat().checkOutputSpecs(fs, jobCopy);
}
jobCopy = (JobConf)context.getConfiguration();
// 写入分片文件,会生成job.split job.splitmetainfo
FileSystem fs = submitJobDir.getFileSystem(jobCopy);
LOG.debug("Creating splits at " + fs.makeQualified(submitJobDir));
int maps = writeSplits(context, submitJobDir);
jobCopy.setNumMapTasks(maps);//设置map个数
// write "queue admins of the queue to which job is being submitted"
// 设置队列信息,默认为default队列
String queue = jobCopy.getQueueName();
AccessControlList acl = jobSubmitClient.getQueueAdmins(queue);
jobCopy.set(QueueManager.toFullPropertyName(queue,
QueueACL.ADMINISTER_JOBS.getAclName()), acl.getACLString());
// 写配置文件job.xml
FSDataOutputStream out =
FileSystem.create(fs, submitJobFile,
new FsPermission(JobSubmissionFiles.JOB_FILE_PERMISSION));
try {
jobCopy.writeXml(out);
} finally {
out.close();
}
//
// Now, actually submit the job (using the submit name)
//
printTokens(jobId, jobCopy.getCredentials());
//真正提交作业
status = jobSubmitClient.submitJob(
jobId, submitJobDir.toString(), jobCopy.getCredentials());
JobProfile prof = jobSubmitClient.getJobProfile(jobId);
if (status != null && prof != null) {
return new NetworkedJob(status, prof, jobSubmitClient);
} else {
throw new IOException("Could not launch job");
}
} finally {
if (status == null) {
LOG.info("Cleaning up the staging area " + submitJobDir);
if (fs != null && submitJobDir != null)
fs.delete(submitJobDir, true);
}
}
}
});
}private void copyAndConfigureFiles(JobConf job, Path submitJobDir,
short replication) throws IOException, InterruptedException {
...
...
//前面是作业的一系列校验,下面的代码开始向HDFS中传送jar文件
String originalJarPath = job.getJar();
if (originalJarPath != null) { // copy jar to JobTracker's fs
// use jar name if job is not named.
if ("".equals(job.getJobName())){
job.setJobName(new Path(originalJarPath).getName());
}
//获得需要上传的jar文件
Path submitJarFile = JobSubmissionFiles.getJobJar(submitJobDir);
job.setJar(submitJarFile.toString());
//此处开始拷贝
fs.copyFromLocalFile(new Path(originalJarPath), submitJarFile);
//设置jar文件的副本数,在节点较多的集群中可以设置多个副本,减少TT拷贝文件到本地的时间
fs.setReplication(submitJarFile, replication);
//设置文件权限
fs.setPermission(submitJarFile,
new FsPermission(JobSubmissionFiles.JOB_FILE_PERMISSION));
} else {
LOG.warn("No job jar file set. User classes may not be found. "+
"See JobConf(Class) or JobConf#setJar(String).");
}
} protected long computeSplitSize(long blockSize, long minSize,
long maxSize) {
return Math.max(minSize, Math.min(maxSize, blockSize));
}public List<InputSplit> getSplits(JobContext job
) throws IOException {
//获得分片的设定值
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
long maxSize = getMaxSplitSize(job);
// 生成分片数据,一个作业中的输入文件可以有多个,也可以使用通配符
List<InputSplit> splits = new ArrayList<InputSplit>();
List<FileStatus>files = listStatus(job);
//对每个输入文件进行遍历
for (FileStatus file: files) {
Path path = file.getPath();//获得文件路径
FileSystem fs = path.getFileSystem(job.getConfiguration());
long length = file.getLen();//获得文件长度
//获得文件块分布的情况
BlockLocation[] blkLocations = fs.getFileBlockLocations(file, 0, length);
//判断文件是否可以分割
if ((length != 0) && isSplitable(job, path)) {
long blockSize = file.getBlockSize();
//计算分片尺寸,前面已经贴出了公式
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
long bytesRemaining = length;
//开始逻辑分割文件,注意如果剩余尺寸大于一个分片的1.1倍,则会继续分割,这个值在目前1.x里是写死的
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
//获得当前分片块索引,以便构建FileSplit
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
//加入一个文件分片
splits.add(new FileSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts()));
bytesRemaining -= splitSize;
}
//文件尾巴处理
if (bytesRemaining != 0) {
splits.add(new FileSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkLocations.length-1].getHosts()));
}
} else if (length != 0) {//如果文件不可分割,则只创建一个split
splits.add(new FileSplit(path, 0, length, blkLocations[0].getHosts()));
} else {
//Create empty hosts array for zero length files
splits.add(new FileSplit(path, 0, length, new String[0]));
}
}
// 保存合法文件数量
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
LOG.debug("Total # of splits: " + splits.size());
return splits;
}














 820
820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









