







1. 前言
IO 在 Java SE 的 jdk 中 单独占据了一个 包 ,其重要性可见一斑 ,而且 IO 流的操作 也经常让人 摸不着头脑,今特 总结,以备后续翻阅。
本次 测试 皆 基于 jdk1.8 , log 基于 slf4j + simple 包
gradle 依赖:
testCompile group: 'junit', name: 'junit', version: '4.11'
compile group: 'org.slf4j', name: 'slf4j-api', version: '1.7.22'
compile group: 'org.slf4j', name: 'slf4j-simple', version: '1.7.22'2. 总览
IO 包下 接口 ,类 ,异常 如下分类
接口
Closeable : 用于关闭数据对象, 释放对象所持有的资源
DataInput:用于从二进制流中读取相应字节,并且重新构造为 java 的 基础类型
DataOutput : 与 DataInput 相反,用于将 java 基础类型转换为 二进制,并写出到二进制流
Externalizable:
FileFilter:功能接口
FilenameFilter:功能接口
Flushable :用于将任何 缓冲了的 输出 写出到 流中
ObjectInput : 继承上面的 DataInput ,用于读取对象,数组和字符串
ObjectInputValidation:
ObjectOutput : 继承 DataOutput,用于写对象
ObjectStreamConstants:
Serializable : 用于类的 序列化 ,空接口类:
BufferedInputStream : 用于从字节输入流中读取字节, 增加缓冲区,内部为数组,默认 8192 字节
BufferedOutputStream :写出字节到内部的输出流(output stream),增加缓冲区,先写到缓冲区再写到目的流
BufferedReader :从字符-输入流中读取文本,增加缓冲区
BufferedWriter:写文本 到 字符输出流
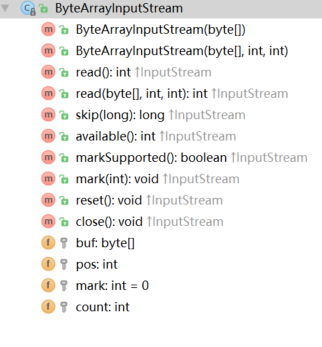
ByteArrayInputStream :包含一个内部的缓冲区,这个缓冲区包含了从流中读取的字节。
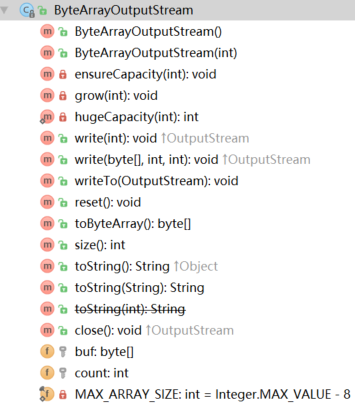
ByteArrayOutputStream:数据被写到 字节数组中保存,当写入数据时,缓冲区会自动增长,数据可以使用 toByteArray() 和 toString() 取得。
CharArrayReader :同 ByteArrayInputStream,只是这里处理字符
CharArrayWriter:同 ByteArrayOutputStream,只是这里处理字符
Console : 始于 1.6
DataInputStream :从输入流中读取 java 基础类型
DataOutputStream :写入 java 基础类型到 输出流
File :文件相关
FileDescriptor
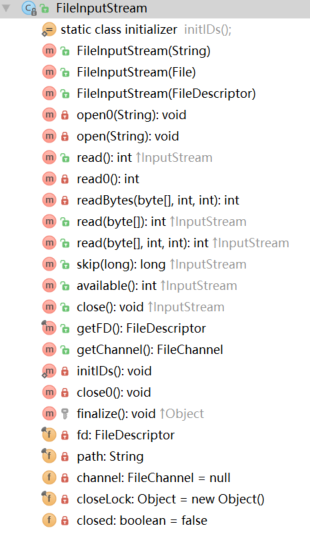
FileInputStream :从文件中获取 输入字节流
FileOutputStream:写数据到 一个文件的 输出流
FilePermission
FileReader:读字符文件的方便类,默认编码,默认字节缓冲
FileWriter:写字符文件的方便类
FilterInputStream:装饰类
FilterOutputStream:装饰类
FilterReader
FilterWriter
InputStream:所有代表字节输入流的父类
InputStreamReader :字节流转换为字符流的桥梁
LineNumberInputStream
LineNumberReader
ObjectInputStream
ObjectInputStream.GetField
ObjectOutputStream
ObjectOutputStream.PutField
ObjectStreamClass
ObjectStreamField
OutputStream
OutputStreamWriter
PipedInputStream
PipedOutputStream
PipedReader
PipedWriter
PrintStream
PrintWriter
PushbackInputStream
PushbackReader
RandomAccessFile
Reader
SequenceInputStream
SerializablePermission
StreamTokenizer
StringBufferInputStream
StringReader
StringWriter
Writer异常类
略
按照数据结构分类:
- 字节流
- 字符流
按照方向分类:
- 输入流:决定了输出的起源地(字节数组,String 对象,文件,管道,其他),即提供了数据源,并提供了输出数据源的一系列方法;
- 输出流:决定了往何处输入,即提供了接收源,并提供了 接收的一系列方法;
3.分析
3.1 输入 | 输出 字节流
输入流 UML 图 (列出了每个类的构造函数):
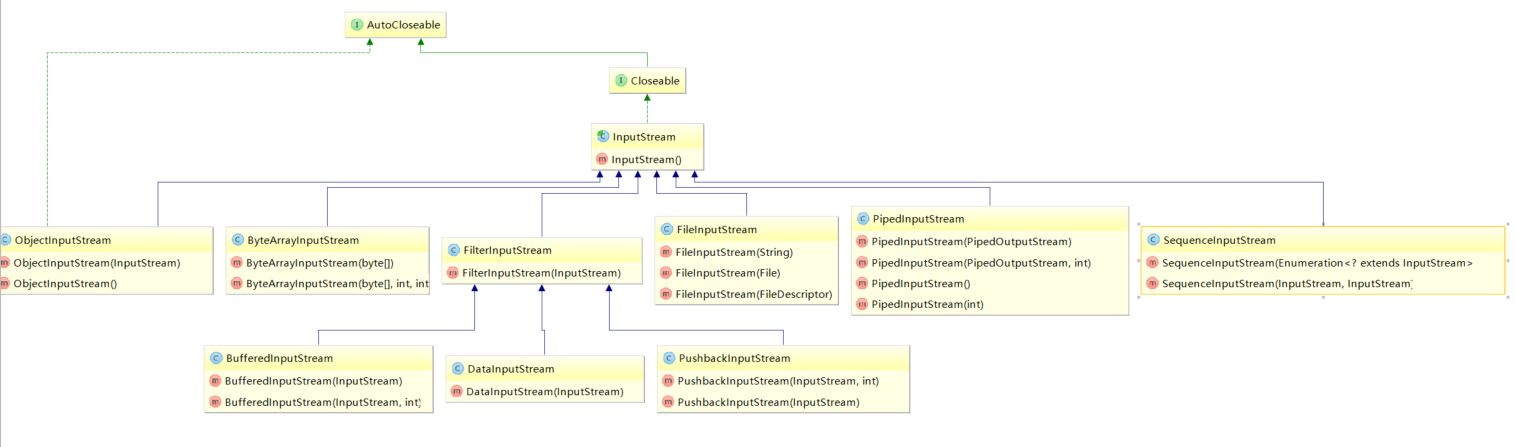
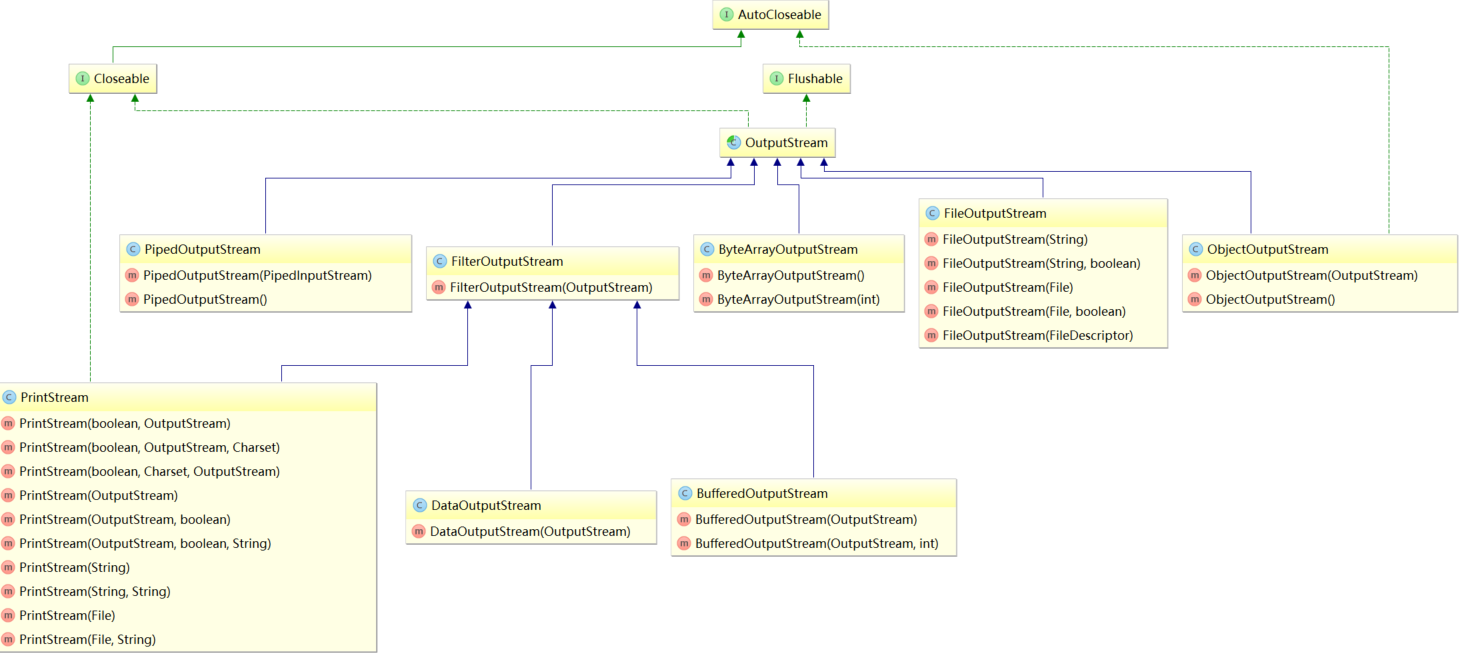
输出流 UML 图
InputStream
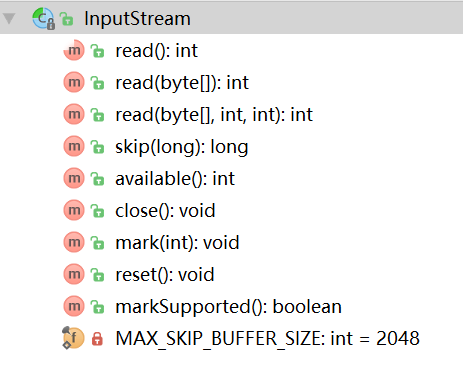
所有 输入字节流的顶层父类 。
方法:
read() 方法 : 从 输入流 中读取 数据的下一个 字节。返回 0-255 的 整型。 如果没有数据则 返回 -1;
此为抽象方法,需要子类实现。
read(byte b[]): 调用下面的方法, read(b, 0, b.length);
read(byte b[], int off, int len):从 输入流中 off 位置开始 读取 len 长度的字节 保存到 字节数组 b 中
方法分析:
read() 方法 需要子类 具体实现;
read(byte b[],int off,int len) : 内部实现方法为 ,使用循环,调用单字节的读方法,将读到的 int 类型强转为 byte 保存到 字节数组 b 中。
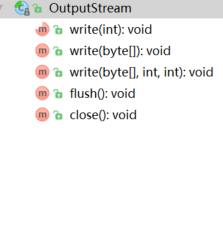
OutputStream
所有 输出字节流的顶层父类 。
方法:
write(int b):将 b 写到 输出流中;参数 b 为 整型,一个 int 有 4个 字节,每个字节有8 位;
这里会将 b 的 低8位 按顺序 写到 输出流中, 而 b 的 高 24 位 将被 忽略 。
此为抽象方法,需要子类实现
write(byte b[]): 调用了下面的方法 write(b, 0, b.length)
write(byte b[], int off, int len):将 数组 b 中 从 off 位置开始 写入 len 个 字节到该 输出流中;flush(): 空方法,没有做任何实现。
方法分析:
write(int b) 为 抽象方法,需要子类实现;
而 write(byte b[]) 和 write(byte b[], int off, int len) 相同, 该方法 的实现是 循环 字节数组 b ,然后调用单字节的写入方法 write(int b) .
所有方法:
序列化流
ObjectInputStream
用于 输入流中 基本数据类型 和 对象 的 反序列化,即 读出 其中的 基本数据类型 和 对象。 和 ObjectOutputStream 搭配使用
感觉应该也是提供了一个功能 ,可以在流中 传递 对象 和 基本数据类型的 功能。
构造函数:需要提供一个 介质,可以是文件流 FileInputStream
ObjectInputStream(InputStream in): 使用 输入流构造一个 ObjectInputStream,如果输入流中保存着序列化的对象则可以使用 readObject() 读取
方法:
不仅 对 InputStream 类中的 read 方法 进行了 实现和重写(override),另外还提供了其他的方法,如 readObject(),readByte(),readBoolean() 等对java 基本数据类型的读取;
方法分析:
该输入流 提供了多个 内部类 来实现 这些 读方法,
BlockDataInputStream:InputStream 子类,两种模式
default mode: 数据不会被 缓冲
block mode: 数据在读取的同时 ,会缓冲到 内置的 字节数组中
PeekInputStream :InputStream 子类, 支持 单个字节 peek 操作
read() 方法 会先调用 BlockDataInputStream 的 read() 方法,然后再调用 PeekInputStream 的read()方法,最后调用其 构造函数传入的 InputStream 流的 read() 方法;
read(byte b[],int off,int len) 的流程 同 read(),最后调用 传入的输入流的 read(byte b[],int off,int len)方法;
ObjectOutputStream
将 基本数据类 和 对象的序列 写到 输出流(OutputStream),需要先序列化;和 ObjectInputStream 搭配使用
构造函数: 需要提供一个 介质,可以是文件流
ObjectOutputStream(OutputStream out) :使用输出流构造一个 ObjectOutputStream ,可以向 输出流中 写入序列化的对象数据 writeObject()
方法:
不仅对 父类 的 write 方法 进行了实现 和 重写(override),还提供了其他的写 基本数据类型的方法
方法分析:
提供了内部类 来重写 数据的写出操作:
BlockOutputStream:
write(int b): 调用了 BlockOutputStream 的 write()方法 ,然后 将 数据 保存在 BlockOutputStream 的 内置 字节数组中,容量 1024字节
write(byte [] buf,int off,int len):内部调用了 BlockOutputStream 的 write(byte[] b, int off, int len, boolean copy) 方法,这里会执行while 循环并分情况处理,直至把 buf 中 的数据写完,以达到效率最优:
如果 当前 内置 字节数组 b 中 已经写 满,则 直接调用 构造函数传入的 输出流 的 写操作 ;并将 pos 置为 0,再次循环;
如果 要读取的 数据的 buf 长度 大于 内置 字节数组 的最大长度,则直接调用 构造函数传入的 输出流 的 写操作,将 0-b.length 长度的数据写到输出流中,再次循环;
否则,将 buf 中的数据 保存到 内置 数组 b 中,再次循环;
flush(): 内部调用了 BlockOutputStream 的 close()方法,内部 再次执行将 内置字节数组 b 中的 数据写入到 构造函数传入的 输出流中,然后执行 构造函数传入的 输出流 的 close()方法;
测试:
@Test
public void ObjectInputStream()throws Exception {
//创建序列化对象
User user = new User();
user.setName("xlch");
user.setEmail("xlch@163.com");
user.setCreateTime(Date.from(LocalDateTime.now().atZone(ZoneId.systemDefault()).toInstant()));
try(FileOutputStream fileOutputStream = new FileOutputStream("D:\\test.txt");
ObjectOutputStream out = new ObjectOutputStream(fileOutputStream);
FileInputStream fileInputStream = new FileInputStream("D:\\test.txt");
ObjectInputStream in = new ObjectInputStream(fileInputStream);) { //目录下的文件并不存在, FileOutputStream 会先创建
//写入序列化对象到 文件流中
out.writeObject(user);
//从文件流中写出序列化对象
User user1 = (User) in.readObject();
logger.info("user name is {}",user1.getName());
logger.info("user createTime is {}",user1.getCreateTime());
}
}
字节数组 流
ByteArrayInputStream
包含一个内置的 缓冲区 ,这个缓冲区保存着字节,这些字节可以读取出来 。有一个内置的 计数器 跟踪 下一个字节,用于支持 read() 方法。关闭流对方法调用无影响。
简单的说 : 将 存储内容的字节数组 构造成 输入流,保存的是 字节数组中的内容 。然后利用其中的方法可以 读出 字节数组中的数据
构造函数:内部包含 字节数组 这个 介质 ,但是需要传递数据给这个 介质
ByteArrayInputStream(byte buf[]); //使用 buf 作为 缓冲数组 创建一个 ByteArrayInputStream 对象。初始位置 pos 为 0 ,初始长度为 buf 的长度
ByteArrayInputStream(byte buf[], int offset, int length) // 初始位置为 offset ,初始长度为 length方法:
read() : 从输入流中(介质为 字节数组)读取 下一个字节 ,返回该字节 的 低八位 整型类型,如果返回 -1 说明无数据可读。
read(byte b[], int off, int len) :从 b 的 off 位置开始存储, 读取的长度 为 lenByteArrayOutputStream
构造一个空的 输出流,用于将 外部 字节数据 写到 内置的 字节数组缓冲区中 。内置的 缓冲区 会 随着 数据的写入 而 自动增长 . 其中 的 数据可以使用 toByteArray() 方法 和 toString() 方法 取回 。同样关闭流 对方法的调用无影响 。 相当于一个 容器 ,暂时保存读取到的字节数据。经常会用到
构造函数: 内部包含一个可保存数据的 字节数组的介质 ,不需要提供
ByteArrayOutputStream() // 构造一个默认容量为 32 字节的 输出流
ByteArrayOutputStream(int size) // 指定内置缓冲区容量大小的 输出流方法:
write(int b): 写一个字节到 内置的 buffer 缓冲区 中
writeTo(OutputStream out) : 将 所有数据 写到 另一个 输出流中 ,其实调用了 out.write(buf,0,count)
flush():冲刷 输出流,迫使任何 已缓存的 输出字节 写出 。
唯一的联系是 :调用这个方法代表 之前由 输出流的实现类 写出的 任意的字节 已经被 缓冲,则这些数据必须立即被写到目的地。
如果这些流的 目的地 是由内部操作系统 提供的一个抽象,比如 一个文件 ,
那么 flush 只能保证之前写的数据传递到 操纵系统中等待写,而不会保证直接 写到物理介质上,如 磁盘。
所有方法:
测试:
package com.ycit.io;
import org.junit.Test;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
/**
* Created by xlch on 2017/1/11.
*/
public class InputStreamTest {
private static final Logger logger = LoggerFactory.getLogger(InputStreamTest.class);
/**
* 一个字节一个字节的读
*/
@Test
public void byteArrayInputStreamTest()throws Exception {
byte [] bytes = new byte[]{'a','b'};
ByteArrayInputStream in = new ByteArrayInputStream(bytes);
int size = in.available();
logger.info("the available size == {}", size); // 2
int binary = in.read();
while (binary != -1) {
logger.info("the binary is {}",binary); //分别 输出 97 98
binary = in.read();
}
in.close();
}
/**
* 一次读取多个数据
*/
@Test
public void readUseBuffer() throws IOException {
byte [] data = new byte[]{'a','b','c'};
try(ByteArrayInputStream in = new ByteArrayInputStream(data)){
byte [] buffer = new byte[1024];
int len = in.read(buffer,2,5);
while (len != -1) {
logger.info("read data size is {}", len); //3
logger.info("buffer[0] is {}", buffer[0]); //0
logger.info("buffer[2] is {}", buffer[2]); //97 即 a 的 Ascii
logger.info("buffer[3] is {}", buffer[3]); //98
logger.info("binary data is {}", new String(buffer));//abc
len = in.read(buffer);
}
}catch (IOException e){
e.printStackTrace();
}
}
@Test
public void byteArrayOutputStream() throws Exception {
ByteArrayOutputStream out = new ByteArrayOutputStream();
out.write('a');
logger.info("out convert string is {}", new String(out.toByteArray(), "utf-8")); // a
logger.info("out convert string is {}", out.toString()); // a
out.write(new byte[]{'b','c','d'}, 1, 2);
logger.info("out convert string is {}", out.toString()); // acd
//将 ByteArrayInputStream 中的数据 写到 ByteArrayOutputStream 中
byte [] bytes = new byte[]{'a','b'};
ByteArrayInputStream in = new ByteArrayInputStream(bytes);
byte [] buffer = new byte[1024];
int len = in.read(buffer);
while (len != -1) {
out.write(buffer);
len = in.read(buffer);
}
logger.info("out convert string is {}", new String(out.toByteArray(), "utf-8")); // acdab
}
}
文件流
FileInputStream
从 一个文件 获取 输入字节 ,文件可读性依赖于 主机环境。 用于读取 原始数据 流 ,比如 图像 数据 。读取字符流 考虑使用 FileReader .
和 ByteArrayInputStream 类似 ,只不过 获取数据来源不同,一个是 字节数组 ,一个是文件。而且难易程度不同,文件的读取和系统硬件相关,需要使用 native 方法读取。
简单的说:由 文件 构造一个 输入流 , 流中的数据 就是 文件中的数据 ,可以 读取 流中的 数据,相当于间接读取了 文件的数据 。
构造函数: 不存在介质 ,需要 提供一个包含数据的 文件 介质,可从中读取
FileInputStream(String name) :提供 文件路径,实际调用下面的构造函数
FileInputStream(File file):直接 提供 File 对象,内部使用 FileDescriptor 代表 该文件的连接
FileInputStream(FileDescriptor fdObj):提供文件描述符对象,该对象充当 通向 代表 一个 打开的文件、打开的 套接字、或者其他的源 的一个不透明句柄 ,
FileDescriptor 主要用来 创建 FileInputStream 或者 FileOutputStream 并且 包含之 。
应用不应该创建 他们自己的文件 描述符方法:
read() : 从输入流中(即文件中) 读取一个字节
read(byte b[]) : 从输入流中读取 b.length 个 字节
read(byte b[], int off, int len)
方法分析:
所有的 read() 方法 的内部实现 都是 调用 内部的 native 方法 ,native 方法 是 通过 底层 的 C/C++ 实现的
FileOutputStream
用于 将 数据 写到一个文件中 或者 写到一个 FileDescriptor 中。
简单的说: 同样是由 文件 构造的 输出流,目的是 向 文件中写数据
构造函数:不存在 介质,需要提供一个文件介质,用于保存即将写入的数据
FileOutputStream(String name):使用文件路径,实际上调用下面的构造函数,第二个参数默认为 false
FileOutputStream(String name, boolean append) : 使用文件路径,同时指定 是覆盖还是 在后面添加
FileOutputStream(File file)
FileOutputStream(File file, boolean append)
FileOutputStream(FileDescriptor fdObj)
write(int b) : 将 b 写入到 文件 输出流中 ,即写入到文件中
write(byte b[]):将 b.length 个 字节 写入到 文件 输出流中
write(byte b[], int off, int len)
方法分析:
所有的 read() 方法 的内部实现 同样都是 调用 内部的 native 方法 ,native 方法 是 通过 底层 的 C/C++ 实现的;flush():并没有对 父类 的 flush 方法 进行重写(override);

NOTE: FileInputStream 指定 文件后 ,如果文件不存在,或者指定的是一个目录,或者其他的原因不能打开 则 抛出 FileNotFoundException 异常
FileOutputStream 指定文件后,如果文件存在,但是是一个目录,或者 文件不存在 但是不能创建,或者因为其他原因不能打开,则抛出 FileNotFoundException
也就是说 ,FileOutputStream 在发现文件不存在后可以 自动创建文件 ,而 FileInputStream 在 发现文件不存在后则 直接 抛出异常 !
/**
* 一个字节一个字节的读
* @throws Exception
*/
@Test
public void FileInputStreamTest()throws Exception {
String sourcePath = "E:\\study\\jdk\\io\\InputStream.PNG";
String destinationPath = "E:\\study\\jdk\\io\\11.PNG";
try(FileInputStream in = new FileInputStream(sourcePath); FileOutputStream out = new FileOutputStream(destinationPath)){ // 这个时候 流中已经包含了这张图片
int binary = 0;
while ((binary = in.read()) != -1) {
out.write(binary);
}
}catch (Exception e) {
e.printStackTrace();
}finally {
logger.info("流已关闭");
}
}
/**
* 一次读取多个,并不是缓冲
* @throws Exception
*/
@Test
public void useBuffer()throws Exception {
String sourcePath = "E:\\study\\jdk\\io\\InputStream.PNG";
String destinationPath = "E:\\study\\jdk\\io\\11.PNG";
try(FileInputStream in = new FileInputStream(sourcePath); FileOutputStream out = new FileOutputStream(destinationPath)){ // 这个时候 流中已经包含了这张图片
byte [] buffer = new byte[32];
int len = 0;
while ((len = in.read(buffer)) != -1) {
out.write(buffer);
}
}catch (Exception e) {
e.printStackTrace();
}finally {
logger.info("流已关闭");
}
}PipedInputStream
管道输入流 应该和 管道输出流 相连 , 管道输入流 提供 字节数据 ,这些数据被 写到 管道输出流中 。通常 和 多线程有关
测试:略
PipedOutputStream
测试:略
SequenceInputStream
用于 批量处理 多个 输入流
构造函数:
SequenceInputStream(Enumeration<? extends InputStream> e)
SequenceInputStream(InputStream s1, InputStream s2) :内部同样是使用 Vevtor 转为 Enumeration
FilterInputStream
包含一些其他的 输入流的 实例 ,通常用于转化数据 或者 提供额外的功能 (所谓的 装饰模式中的 Decorator 角色,参看案例),重写(override)了 InputStream 的所有方法.
FilterOutputStream
同上,扮演 装饰模式 中的 Decorator 角色。
功能性 流
BufferedInputStream
用来 给 另一个 输入流 提供 缓冲 输入的能力。先缓冲一般部分数据到内置的缓冲区数组中,然后从 缓冲区数组中读取字节。 参看 源码分析
当对象创建时,内置的 缓冲区 数组 也被创建,当从 流中读取 字节或者 跳过字节时,内置 的 缓冲区数组如果有必要的话 会 重新从 提供的输入流中重新装填 数据。
构造函数:
BufferedInputStream(InputStream in):调用下面的构造函数,默认缓冲区容量为 8192字节
BufferedInputStream(InputStream in, int size): 为 in 输入流 增加 缓冲功能,缓冲区数组大小为 size
方法分析:
主要是 利用 内置 字节数组 缓冲区 buf 来 缓冲数据
read(int b):从内置字节数组缓冲区中读取一个字节,如果缓冲区没有可读数据,则 调用 fill()方法填充;
read(byte b[], int off, int len):如果 len 长度 大于 内置字节数组缓冲区的长度,则 直接调用 构造函数传入的 输入流 参数 调用 read 方法;
BufferedOutputStream
将要写的字节 先写到 缓冲区数组中,然后一起写到 目的 流中。
构造函数:
BufferedOutputStream(OutputStream out) :调用下面的构造函数,默认初始容量 8192字节
BufferedOutputStream(OutputStream out, int size):指定内置缓冲区数组的初始容量
方法分析:
/**
* 文件 copy 使用缓冲
* @throws Exception
*/
@Test
public void userBuffered() throws Exception {
String sourcePath = "E:\\study\\jdk\\io\\InputStream.PNG";
String destinationPath = "E:\\study\\jdk\\io\\11.PNG";
try(BufferedInputStream in = new BufferedInputStream(new FileInputStream(sourcePath));
BufferedOutputStream out = new BufferedOutputStream(new FileOutputStream(destinationPath));){
byte[] buffer = new byte[1024];
int len = 0;
while ((len = in.read(buffer)) != -1) {
out.write(buffer);
out.flush();
}
}
}DataInputStream
提供一个功能,用来 读取 java 中基本数据类型的功能 ,输入流的原型 只能读取 字节。和 DataOutputStream 对接
构造函数:
DataInputStream(InputStream in)DataOutputStream
提供一个功能,用来直接写入 java 的基本数据类型;和 DataInputStream 对接
构造函数:
DataOutputStream(OutputStream out)测试:
@Test
public void dataInputStreamTest() {
try(FileOutputStream out = new FileOutputStream("D:\\test.txt");DataOutputStream dataOut = new DataOutputStream(out);//文件不存在,先调用 FileOutputStream 会创建文件
FileInputStream in = new FileInputStream("D:\\test.txt");DataInputStream dataIn = new DataInputStream(in);){//文件不存在,如果先调用 FileInputStream 会 抛出 FileNotFoundException
dataOut.writeDouble(0.12);
Double d = dataIn.readDouble();
logger.info("the double is {}", d);//0.12
}catch (Exception e) {
e.printStackTrace();
}
}
PrintStream
提供一个功能,可以向 输出流中 方便的写 各种数据值 ,不在局限于 byte 类型;
System.out.println 中 的 System.out 返回的 即是 PrintStream 对象
构造函数:
PrintStream(OutputStream out):调用下面的构造函数 ,boolean 默认为 false
PrintStream(OutputStream out, boolean autoFlush) : autoFlush 是否自动刷新
PrintStream(OutputStream out, boolean autoFlush, String encoding):
PrintStream(String fileName): 指定一个文件路径,如果不存在会自动创建
PrintStream(String fileName, String csn):指定编码方式
PrintStream(File file)
PrintStream(File file, String csn):指定编码方式
测试:
@Test
public void printStream() {
String path = "D:\\test.txt";
try(PrintStream out = new PrintStream(path);){
out.print(true); //向 文件中写入 boolean 值
out.println("新年快乐"); //向文件中写入 字符串,并且 换行 ,相当于执行了写操作和 newLine()
out.flush();
}catch (Exception e) {
e.printStackTrace();
}
}
3.2 输入 | 输出 字符流
输入字符流 UML
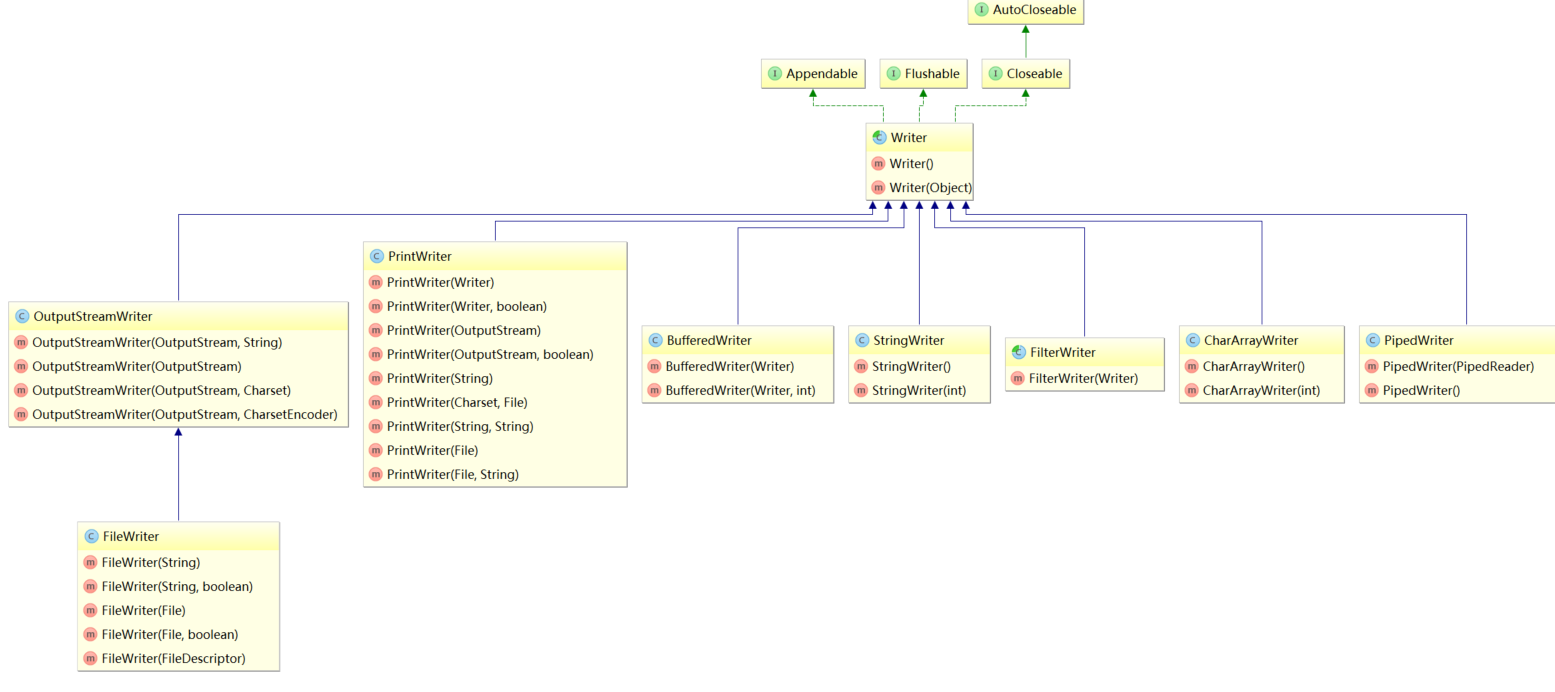
输出字符流 UML

Reader
读数据到 字符流中
方法:
read(java.nio.CharBuffer target) :1.5 后添加的方法,读字符串到 字符缓冲区
read():读取 单个字符,实际上也是调用了read(char cbuf[], int off, int len) 方法),返回 低 16位
read(char cbuf[]) :调用下面的构造函数,read(cbuf, 0, cbuf.length);
read(char cbuf[], int off, int len):从 cbuf 的 off 位置开始存储,读取 len 个 字符到 cbuf 数组 中;返回读取字符个数
该方法为抽象方法,需要子类实现
方法分析:
都是依赖于 read(char cbuf[], int off, int len) 抽象方法的实现;
read(): 内部构造一个空的 字符数组 ,然后调用 read(char cbuf[], int off, int len) 方法读取;
Writer
写数据到 字符流中
方法:
write(int c) : 写 单独的字符 。c 的 低 16位 字节被写入到 字符流中,c 的 高 16位 被忽略。
write(char cbuf[]):调用下面的构造函数,write(cbuf, 0, cbuf.length):写字符数组到 流中。
write(char cbuf[], int off, int len):从 cbuf 的 off 位置开始, len 的长度 写到 流中。抽象方法
write(String str): 写一个字符串 到 流中,调用下面的构造函数,write(str,0,str.length())
write(String str, int off, int len):将 str 的 off位置,到len 的长度 的 字符串 写到流中
append(CharSequence csq): 字符序列 csq 添加到 输出流的后端,返回这个输出流,内部使用的是 write(csq.toString())方法
append(CharSequence csq, int start, int end):内部调用: write(cs.subSequence(start, end).toString());
Writer append(char c):内部调用 write(c)flush() :抽象方法方法分析:
都调用了 write(char cbuf[], int off, int len) 抽象方法;
所有方法图:
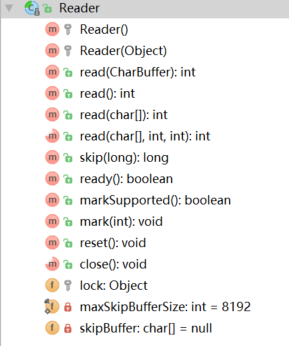
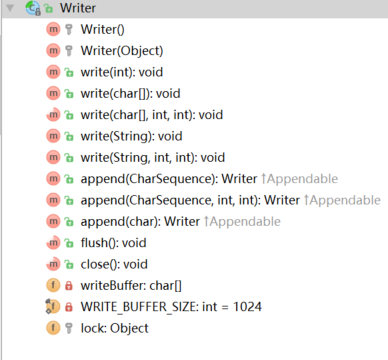
StringReader
源是 字符串的 字符流。通过字符串构造对象,提供数据
类似于 字节流的 ByteArrayInputStream
构造函数:
StringReader(String s) :内部含有一个字符串对象保存 sStringWriter
将需要输出的数据 保存在 内部的 StringBuffer 中 ,后续可以通过 toString() 和 getBuffer().toString() 方法 获取字符串。
类似于 字节流的 ByteArrayOutputStream ,可以充当 字符的容器
构造函数:
StringWriter() : 未指定内部 StringBuffer 容量
StringWriter(int initialSize):指定内部StringBuffer 容量为 initialSize
分析:write 写方法 都是 直接 append 到 内置的 StringBuffer 中 , flush 方法 没有具体实现
/**
* 单字节的从输入流中读出,并写入到 输出流中保存
*/
@Test
public void stringReaderTest() {
String data = "hello world~~";
try(StringReader in = new StringReader(data);
StringWriter out = new StringWriter();){
int len = 0;
while ((len = in.read()) != -1) {
out.write(len);
}
logger.info("the data is {}", out.toString());//hello world~~
logger.info("the data is {}", out.getBuffer().toString());//hello world~~
}catch (Exception e) {
}
}
/**
* 一次读取多个字符
*/
@Test
public void readMore() {
String data = "新年快乐~~";
char [] buf = new char[1024];
try(StringReader in = new StringReader(data);){
int len = 0;
while ((len = in.read(buf)) != -1) {
logger.info("character is {}", new String(buf));//新年快乐~~
}
}catch (Exception e) {
e.printStackTrace();
}
}
CharArrayReader
源为 字符 数组 ,类似于 上面的 StringReader
CharArrayWriter
源为 字符数组 ,类似与 StringWriter
分析: write 写方法 都是直接 写到 字符数组 中 ,flush 方法 没有具体 实现
测试:
略
转换流
InputStreamReader
读取 字节数据,并使用指定的编码方式 把 读取的字节数据 解码成 字符串。提升效率 可以考虑使用 缓冲输入流(BufferedReader)。
字节流 → 字符流 。
BufferedReader in = new BufferedReader(new InputStreamReader(System.in));构造函数:
参数为 字节输入流 和 编码方式
InputStreamReader(InputStream in):使用默认的编码方式 创建一个 对象
InputStreamReader(InputStream in, String charsetName):指定编码方式
InputStreamReader(InputStream in, Charset cs):指定编码方式
InputStreamReader(InputStream in, CharsetDecoder dec)
方法分析:
内部使用 java.nio.cs 包中的 类 StreamDecoder 实现读取 单个字节和 多个字节
OutputStreamWriter
使用 指定的 编码方式 将被写入的字符 编码成 字节。 内置 了 StreamEncoder 类
字符流 → 字节流 ,提高性能 可以使用 缓冲流
Writer out = new BufferedWriter(new OutputStreamWriter(System.out));构造函数:参数为 字节输出流 和 编码方式
OutputStreamWriter(OutputStream out) :使用默认的编码方式
OutputStreamWriter(OutputStream out, String charsetName)
OutputStreamWriter(OutputStream out, Charset cs)
OutputStreamWriter(OutputStream out, CharsetEncoder enc)
方法分析:
内部使用 java.nio.cs 包中的 类 StreamEncoder 实现写 单个字节和 多个字节 到 目标流中
测试:
@Test
public void inputStreamReaderTest()throws Exception {
String path = "D:\\test.txt";
byte [] buffer = new byte[1024];
try(FileOutputStream out = new FileOutputStream(path);
OutputStreamWriter outputStreamWriter = new OutputStreamWriter(out,"utf-8");
FileInputStream fileInputStream = new FileInputStream(path);) {
outputStreamWriter.write("新年快乐~~");// 将字符串写到了字节流 FileOutputStream 中,即所谓的 字符 → 字节
outputStreamWriter.flush();//此时如果不 冲洗 则 下面读不到。
fileInputStream.read(buffer);
logger.info("result is {}", new String(buffer, "utf-8"));//新年快乐~~
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
/**
* copy 文件
*/
@Test
public void useTogether() {
String path = "D:\\test.txt";
String copyPath = "D:\\copy.txt";
char buffer[] = new char[1024];
try(FileInputStream inputStream = new FileInputStream(path);Reader in = new InputStreamReader(inputStream, "utf-8");//保持和文件保存时的 编码方式相同
FileOutputStream outputStream = new FileOutputStream(copyPath, false);Writer out = new OutputStreamWriter(outputStream, "utf-8")) {
int len = 0;
while ((len = in.read(buffer)) != -1) {
out.write(buffer);
logger.info("the buffer string is {}", new String(buffer));
}
} catch (IOException e) {
e.printStackTrace();
}
}FileReader
读取字符文件 的方便类 , 相当于 构造 InputStreamReader 的两个参数 InputStream 为 FileInputStream ,编码方式 使用 默认的编码方式 ,生成的类定义为 FileReader
即
InputStreamReader in = new InputStreamReader(new FileInputStream(path));
等同于
FileReader in = new FileReader(path);InputStreamReader 的 子类
构造函数:
FileReader(String fileName)
FileReader(File file)
FileReader(FileDescriptor fd)
FileWriter
类同 FileReader
BufferedReader
功能性流,提供缓冲的功能
构造函数:
BufferedReader(Reader in): 使用默认容量的 缓冲区字符数组 创建一个缓冲了的字符 输入流,默认为 8192 ,调用下面的构造函数
BufferedReader(Reader in, int sz):内置的字符数组容量为 sz方法:
readLine(boolean ignoreLF) : 读取文本的一行,"\r","\n" 或者回车 代表 一行的末端。参数表示下一个"\n" 是否被跳过
BufferedWriter
功能性流,提供缓冲的功能,内置了 一个字符数组 char cb[]
BufferedWriter(Writer out):使用默认容量的输出缓冲 创建一个 缓冲字符的输入流
BufferedWriter(Writer out, int sz):容量为 sz方法:
newLine():另起一行
分析:
BufferedWriter 类中的 写方法(write(int b))是将 要写的数据 写入到内置的 字符数组 cb 中 ,当达到 cb 规定的长度后(默认 8192,可自定义)调用flushbuffer() ,将 cb 中数据一起写入到 目的流 out 中; write(byte cbuf[], int off, int len):如果请求的 buffer 长度 没有超出内置 字符数组 cb 的 长度,则会先将 cbuf 中的数据保存到 cb 中 ,等cb 达到 cbuf 长度 ,再调用flushbuffer();如果请求的 buffer 长度 超过了 cb 的 长度 ,会先清洗(flushbuffer()) 再 直接 将 cbuf 写入到 目的流 out 中。
@Test
public void bufferedTest() {
String path = "D:\\test.txt";
String copyPath = "D:\\copy.txt";
char buffer[] = new char[1024];
try(Reader in = new BufferedReader(new FileReader(path));Writer out = new BufferedWriter(new FileWriter(copyPath))) {
int len = 0;
while ((len = in.read(buffer)) != -1) {
out.write(buffer);
logger.info("the buffer string is {}", new String(buffer));
}
}catch (IOException e) {
e.printStackTrace();
}
}
PrintWriter
PrintStream 用于处理 字节输出流 , PrintWriter 既可以处理 字节输出流 , 也可以处理 字符输出流 。即 构造函数增加了 Writer 参数。
4. 总结
个人觉得要想 灵活使用,死记硬背那些 口诀是不够的,关键是要掌握 每个流的 构造函数,其次闻其类名知 其意,而同一类流 提供的方法基本一致。
构造函数 可以让我们快速的构造一个 流来使用 ,而通过构造方法 也可以确定其 主要用途。
个人理解,流 相当于 把 存有数据的 载体(介质) 流化,这个流化的目的是 提供 一套 对 载体 操纵数据的方法(读写)。
输入流
输入流用于提供数据,提供 读出操作,可以单个的读 出( read() ),也可以一次读取多个 read(<...>);
InputStream Reader 之类,输入流的构造 需要 提供 已存在的 数据存储载体(介质),以便从载体中读取(read())数据,如字节输入流 有的需要提供 一个 字节数组;有的需要提供一个已存在的文件的文件路径或者文件对象;亦或是直接提供 已创建的 输入流 构造另一个输入流,这类流还是基于 上面提到的 流 。
明白了这些就可以轻松 构造出 输入流 对象 ;
其次
闻其名知其意,如 ObjectInputStream ,观其构造函数,传入的是另一个输入流,这个输入流中保存着对象。字面上理解就是 与对象相关的字节输入流,应该可以想到 其功能是 从构造其对象的 输入流的载体中读取 序列化的对象 ,这个过程应该叫做 反序列化。
输出流
输出流用于 保存数据,提供写入操作,可以单个的写入(write()),也可以一次写入多个(write( <...> ));
OutputStream Writer 之类,输出流 需要指定数据保存的介质,如 内置的 缓冲区(可以不用指定),文件路径等。
字节流
读 和 写 的 操作 是以· 字节 为 单位 (其中的 write( int b) 是 为了 和 read() 返回的 int 类型对应),如
read(); // 读一个字节,返回 int ,读取字节的 低八位
read(byte [] buffer); //读多个字节,返回读取个数
read(byte [] buffer, int off, int len); //读多个字节,返回读取个数
write(int b); // 写一个字节,需要写入字节的低八位
write(byte [] buffer); // 写多个字节
write(byte [] buffer, int off, int len);//写多个字节
字符流
读 和 写的 操作 是以 字符 为单位 (其中的 write( int b) 是 为了 和 read() 返回的 int 类型对应),如
read(); //读一个字符,返回 int, 低 16位
read(char cbuf[]); //读多个字符,返回个数
read(char cbuf[], int off, int len); //读取多个,返回个数
write(int c); // 写一个字符, c 代表 字符的 低16位
write(char cbuf[]); //写多个字符
write(char cbuf[], int off ,int len); //写多个字符
write(String) // 写 一个字符串
。。 














 9316
9316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









