






1.使用requests库请求网站
网页请求方式:(1)get :最常见的方式,一般用于获取或者查询资源信息,也是大多数网站使用的方式,响应速度快。
(2)post:多以表单形式上传参数,因此除了查询信息外,还可以修改信息。
2.怎么确定用什么方式请求?
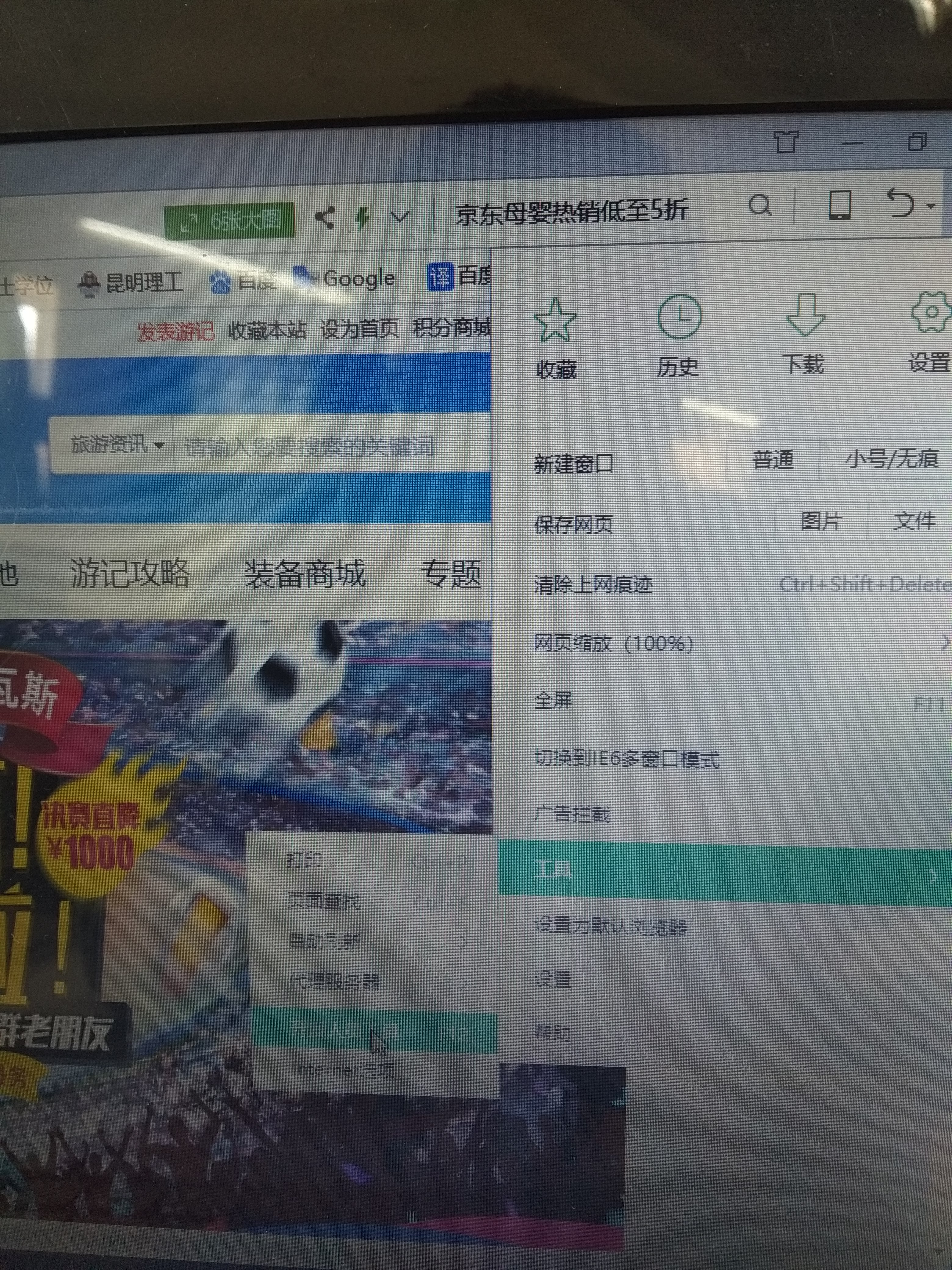
(1)打开网页,用开发者模式,我的浏览器是360,图示:
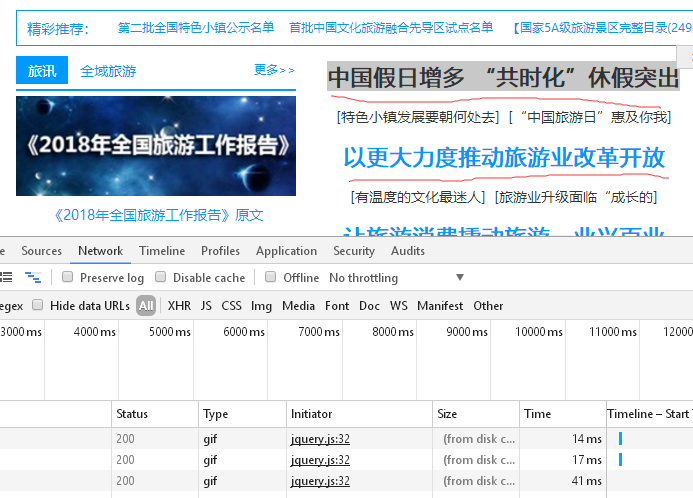
(2)任意复制一条首条新闻标题,粘贴到搜索框里;
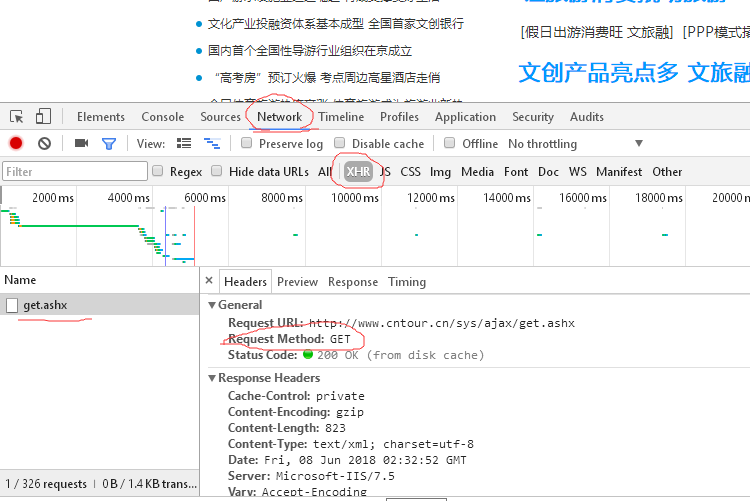
(3)开发者模式,依次点击‘network’,‘XHR’找到翻译数据,点击Headers,请求为get方式。图示:
3.使用Beautiful soup解析网页
(1)安装bs
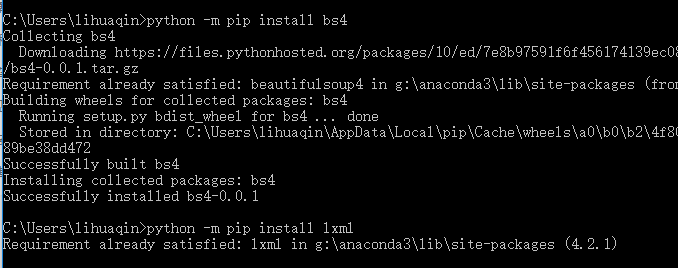
通过requests库可以爬取到网页源码,接下来要从源码中找到并提取数据; Beautiful soup 是python 的一个库,最主要的功能是从网页中抓取数据。 Beautiful soup 目前已经被移植到bs4库中,即导入Beautiful soup时需要先安装bs4库 bs4安装:打开cmd:python -m pip install bs4
图示:
(2)Beautiful soup 指定xlml解析器进行解析。 soup=BeautifulSoup(strhtml.text,'lxml')
(3)使用select(选择器)定位数据,使用浏览器的开发者模式,将鼠标停留在对应数据位置并右击,“审查元素“,开发者界面会有被选中部分,右击 copy ---> copy selector; 将路径粘贴在文档中,代码如下:
#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li:nth-child(1) > a
这是选中的第一条路径,但我们要获取所有的新闻头条,因此将:li:nth-child(1)中冒号(包含冒号)后面的删掉。如下:
#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a
4.清洗和组织数据
for item in data: # soup匹配到的有多个数据,用for循环取出 result = { 'title': item.get_text(), # 标签在<a>标签中,提取标签的正文用get_text()方法 'link': item.get('href'), # 链接在<a>标签的href中,提取标签中的href属性用get()方法,括号指定属性数据 'ID': re.findall('\d+', item.get('href')) # 每一篇文章的链接都有一个数字ID。可以用正则表达式提取这个ID;\d 匹配数字; + 匹配前一个字符1次或者多次 }
5.用正则表达式提取链接数字ID。python调用正则表达式使用re库,不用安装,可直接调用。
6.完整代码如下:
""" 通过requests库可以爬取到网页源码,接下来要从源码中找到并提取数据; Beautiful soup 是python 的一个库,最主要的功能是从网页中抓取数据。 Beautiful soup 目前已经被移植到bs4库中,即导入Beautiful soup时需要先安装bs4库 bs4安装:打开cmd:python -m pip install bs4 """ import requests from bs4 import BeautifulSoup import re # 在python中调用正则表达式用re库,这个库不用安装,可直接调用 url = 'http://www.cntour.cn/' strhtml = requests.get(url) # 所有在源码中的数据请求方式都是get soup = BeautifulSoup(strhtml.text, 'lxml') # lxml解析器进行解析,解析之后的文档保存到变量soup #print(soup) # 使用soup.select引用这个路径 data = soup.select('#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a') #print(data) # 清洗和组织数据,完成上面的步骤只是获得了一段目标HTML代码,但没有把数据提取出来 for item in data: # soup匹配到的有多个数据,用for循环取出 result = { 'title': item.get_text(), # 标签在<a>标签中,提取标签的正文用get_text()方法 'link': item.get('href'), # 链接在<a>标签的href中,提取标签中的href属性用get()方法,括号指定属性数据 'ID': re.findall('\d+', item.get('href')) # 每一篇文章的链接都有一个数字ID。可以用正则表达式提取这个ID;\d 匹配数字; + 匹配前一个字符1次或者多次 } print(result)
7.结果如下:
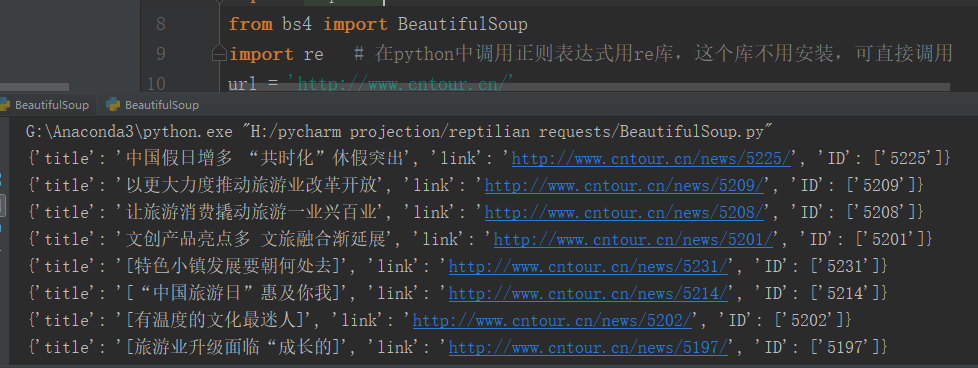
本文是:学习《python3 爬虫,数据清洗与可视化实战 》第二章的学习笔记















 9741
9741











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









