










第一章:人工智能之不同数据类型及其特点梳理
第二章:自然语言处理(NLP):文本向量化从文字到数字的原理
第三章:循环神经网络RNN:理解 RNN的工作机制与应用场景(附代码)
第四章:循环神经网络RNN、LSTM以及GRU 对比(附代码)
第五章:理解Seq2Seq的工作机制与应用场景(附代码)
第六章:深度学习架构Seq2Seq-添加并理解注意力机制(一)
第七章:深度学习架构Seq2Seq-添加并理解注意力机制(二)
第八章:深度学习模型Transformer初步认识整体架构
第九章:深度学习模型Transformer核心组件—自注意力机制
第十章:理解梯度下降、链式法则、梯度消失/爆炸
第十一章:Transformer核心组件—残差连接与层归一化
第十二章:Transformer核心组件—位置编码
第十三章:Transformer核心组件—前馈网络FFN
第十四章:深度学习模型Transformer 手写核心架构一
第十五章:深度学习模型Transformer 手写核心架构二
上一篇《循环神经网络RNN:理解 RNN的工作机制与应用场景(附代码)》讲解实际的案例,使用酒店评论数据集,RNN 训练一个模型,同时也看到RNN 的不足,本文对 RNN 的局限性以及 LSTM/GRU 的改进的进行分析。再次对生成酒店评论这个案例,使用LSTM改写,在看看效果。
一、RNN 的不足
-
梯度消失/爆炸
- 问题:RNN 在反向传播时,梯度需要沿时间步连乘。当序列较长时:
- 如果梯度值 <1 → 多次连乘后趋近于零(梯度消失),无法更新早期层的参数;
- 如果梯度值 >1 → 多次连乘后趋向无穷大(梯度爆炸),参数更新不稳定。
- 影响:难以捕捉长距离依赖(如句子开头和结尾的关系)。
- 问题:RNN 在反向传播时,梯度需要沿时间步连乘。当序列较长时:
-
短期记忆
- 原因:RNN 的隐藏状态通过简单加权和更新,早期输入信息会被后续输入逐步稀释。
- 示例:在句子“The cat, which ate a lot of fish, was very hungry”中,RNN 可能遗忘主语 “cat”,导致无法正确关联 “was hungry”。
-
参数更新冲突
- 问题:同一组权重需要同时学习短期和长期依赖,导致优化困难。
二、LSTM(长短期记忆网络)
- 核心改进:门控机制
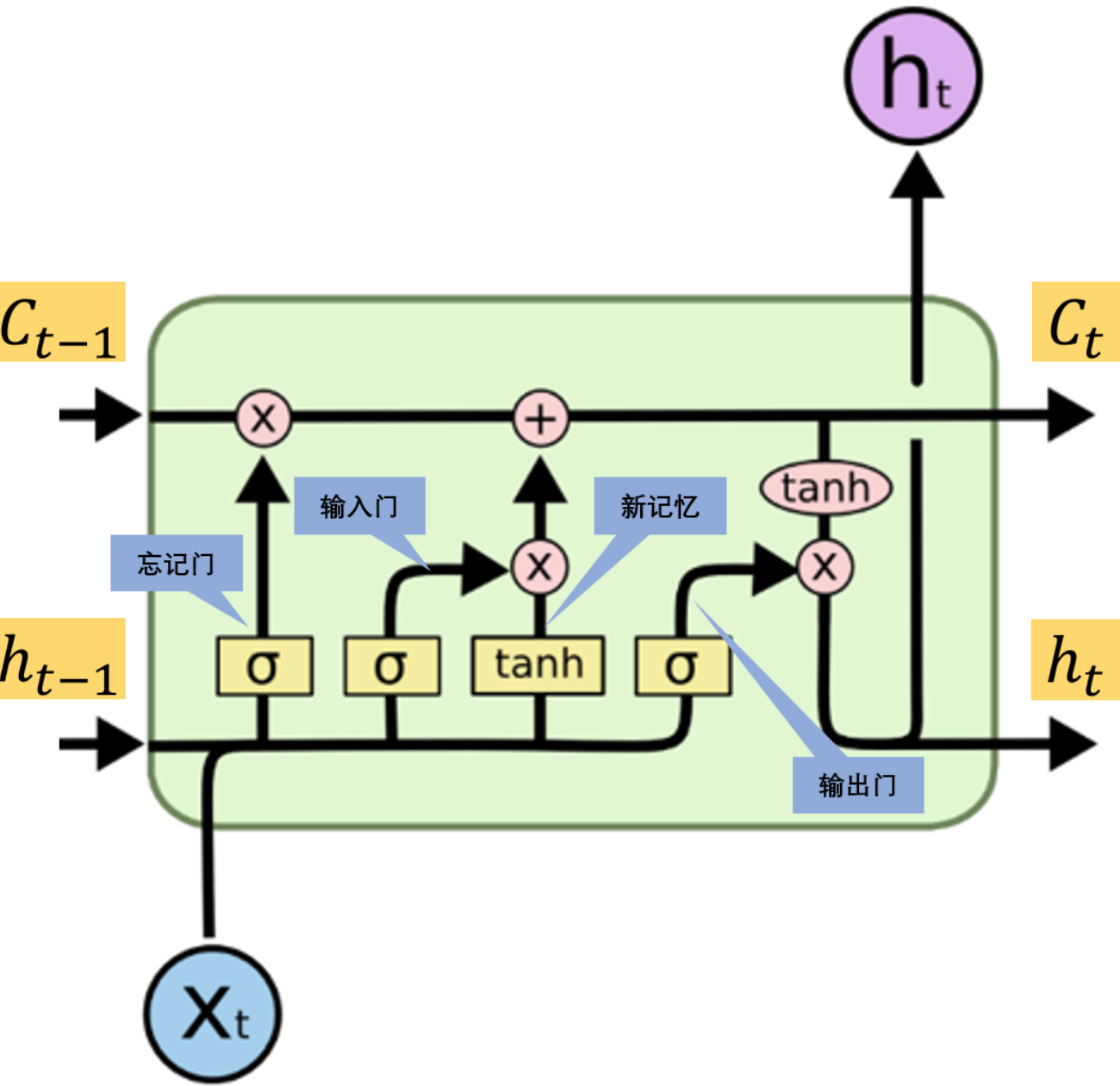
LSTM 通过三个门控单元(输入门、遗忘门、输出门)控制信息流动,结构如下:
- 关键组件
- 细胞状态(Cell State):贯穿整个序列的“记忆通道”,通过门控选择性保留信息。
- 遗忘门(Forget Gate):决定从细胞状态中丢弃哪些信息。
f t = σ ( W f ⋅ [ h t − 1 , x t ] + b f ) f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f) ft=σ(Wf⋅[ht−1,xt]+bf) - 输入门(Input Gate):决定将哪些新信息存入细胞状态。
i t = σ ( W i ⋅ [ h t − 1 , x t ] + b i ) i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i) it=σ(Wi⋅[ht−1,xt]+bi)
C ~ t = tanh ( W C ⋅ [ h t − 1 , x t ] + b C ) \tilde{C}_t = \tanh(W_C \cdot [h_{t-1}, x_t] + b_C) C~t=tanh(WC⋅[ht−1,xt]+bC) - 输出门(Output Gate):决定输出的隐藏状态。
o t = σ ( W o ⋅ [ h t − 1 , x t ] + b o ) o_t = \sigma(W_o \cdot [h_{t-1}, x_t] + b_o) ot=σ(Wo⋅[ht−1,xt]+bo)
-
细胞状态更新
C t = f t ⊙ C t − 1 + i t ⊙ C ~ t C_t = f_t \odot C_{t-1} + i_t \odot \tilde{C}_t Ct=ft⊙Ct−1+it⊙C~t
h t = o t ⊙ tanh ( C t ) h_t = o_t \odot \tanh(C_t) ht=ot⊙tanh(Ct)
其中 ⊙ \odot ⊙表示逐元素相乘。 -
优势
解决梯度消失:细胞状态的加法更新(而非连乘)保留长期记忆。
选择性记忆:通过门控过滤无关信息(如遗忘门清除非关键历史)。
三、GRU(门控循环单元)
- 核心改进:简化门控
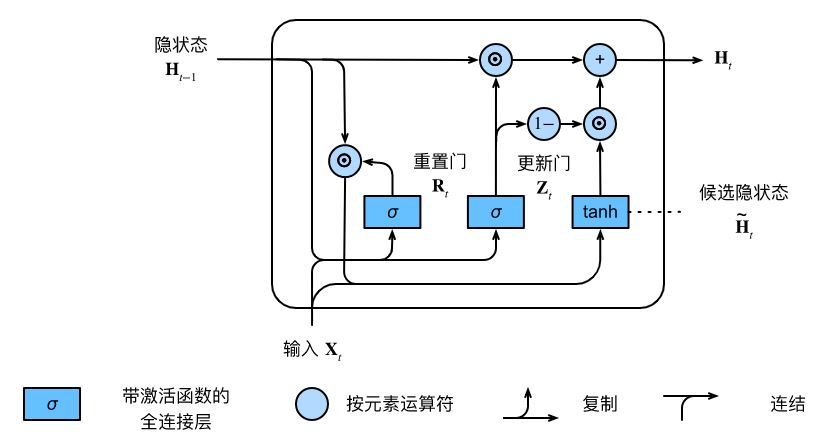
GRU 是 LSTM 的简化版本,合并了细胞状态和隐藏状态,并减少为两个门(重置门、更新门):
- 关键组件
- 更新门(Update Gate):平衡历史信息和新输入的影响。
z t = σ ( W z ⋅ [ h t − 1 , x t ] + b z ) z_t = \sigma(W_z \cdot [h_{t-1}, x_t] + b_z) zt=σ(Wz⋅[ht−1,xt]+bz) - 重置门(Reset Gate):决定忽略多少历史信息。
r t = σ ( W r ⋅ [ h t − 1 , x t ] + b r ) r_t = \sigma(W_r \cdot [h_{t-1}, x_t] + b_r) rt=σ(Wr⋅[ht−1,xt]+br) - 候选隐藏状态:
h ~ t = tanh ( W ⋅ [ r t ⊙ h t − 1 , x t ] + b ) \tilde{h}_t = \tanh(W \cdot [r_t \odot h_{t-1}, x_t] + b) h~t=tanh(W⋅[rt⊙ht−1,xt]+b)
- 状态更新
h t = ( 1 − z t ) ⊙ h t − 1 + z t ⊙ h ~ t h_t = (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t ht=(1−zt)⊙ht−1+zt⊙h~t
4. 优势
- 参数量更少:比 LSTM 少一个门控,计算效率更高。
- 性能接近 LSTM:在多数任务中效果与 LSTM 相当。
四、RNN vs LSTM vs GRU 对比
| 特性 | RNN | LSTM | GRU |
|---|---|---|---|
| 门控机制 | 无 | 输入门、遗忘门、输出门 | 更新门、重置门 |
| 参数量 | 少 | 多(3个门) | 中等(2个门) |
| 长期依赖处理 | 差 | 优秀 | 优秀 |
| 训练速度 | 快 | 慢 | 中等 |
| 适用场景 | 短序列任务 | 长序列复杂任务(如机器翻译) | 资源受限或需快速训练的任务 |
五、代码示例对比
- PyTorch 中模型定义
# RNN
rnn = nn.RNN(input_size=128, hidden_size=256, num_layers=2)
# LSTM
lstm = nn.LSTM(input_size=128, hidden_size=256, num_layers=2)
# GRU
gru = nn.GRU(input_size=128, hidden_size=256, num_layers=2)
- 参数量对比
假设input_size=128,hidden_size=256:
-
RNN 参数:
W x h ∈ R 256 × 128 W_{xh} \in \mathbb{R}^{256 \times 128} Wxh∈R256×128, W h h ∈ R 256 × 256 W_{hh} \in \mathbb{R}^{256 \times 256} Whh∈R256×256, b h ∈ R 256 b_h \in \mathbb{R}^{256} bh∈R256
总计: 256 × 128 + 256 × 256 + 256 = 98 , 304 256 \times 128 + 256 \times 256 + 256 = 98,304 256×128+256×256+256=98,304 -
LSTM 参数:
每个门有独立的 W W W 和 b b b,共 4 组(输入门、遗忘门、输出门、候选状态):
4 × ( 256 × 128 + 256 × 256 + 256 ) = 4 × 98 , 304 = 393 , 216 4 \times (256 \times 128 + 256 \times 256 + 256) = 4 \times 98,304 = 393,216 4×(256×128+256×256+256)=4×98,304=393,216 -
GRU 参数:
3 组(更新门、重置门、候选状态):
3 × 98 , 304 = 294 , 912 3 \times 98,304 = 294,912 3×98,304=294,912
六、案例:生成酒店评论
把上一篇《循环神经网络RNN:理解 RNN的工作机制与应用场景(附代码)》内容中讲到的, 自动生成酒店评论的案例,改写成 LSTM,在和 RNN 生成的内容做一个对比。酒店评论的文件merged_hotel_comment.txt需要参考上一篇内容。
相比 RNN,LSTM 的主要修改点
- 模型定义:将self.rnn更改为self.lstm,并相应地更新了forward方法以接受和返回(hidden, cell)状态。
- 训练代码:初始化hidden_and_cell为包含两个全零张量的元组,分别代表初始隐藏状态和细胞状态。在每次迭代中,传递给模型的是这个元组而不是单独的隐藏状态。
- 生成函数:同样需要更新以处理LSTM特有的隐藏状态和细胞状态。
这样,就将原始基于RNN的模型转换成了一个基于LSTM的版本,这有助于改进模型在捕捉长期依赖方面的性能。
6.1 分词以及建索引
import torch
import torch.nn as nn
import numpy as np
# 超参数调整
hidden_size = 512 # 增大隐藏层维度以适应中文复杂性
num_layers = 2
seq_length = 50 # 加长序列长度
batch_size = 1
learning_rate = 0.005
epochs = 2000
# 读取中文文本
with open('merged_hotel_comment.txt', 'r', encoding='utf-8') as f:
text = f.read().replace('\n', '')[:10000] # 截取部分数据
# 创建字符到索引的映射
chars = sorted(list(set(text)))
# print(chars[:100])
char_to_idx = {ch: i for i, ch in enumerate(chars)}
idx_to_char = {i: ch for i, ch in enumerate(chars)}
vocab_size = len(chars) # 实际字符数
print("实际字符数",vocab_size)
# 将文本转换为索引序列
data = [char_to_idx[ch] for ch in text]
6.2 自定义模型
# 自定义模型 LSTM
class CharLSTM(nn.Module):
def __init__(self, vocab_size, hidden_size, num_layers):
super(CharLSTM, self).__init__()
self.embedding = nn.Embedding(vocab_size, hidden_size) # 添加嵌入层
self.lstm = nn.LSTM(
input_size=hidden_size, # 使用嵌入层的输出维度作为LSTM输入大小
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True
)
self.fc = nn.Linear(hidden_size, vocab_size) # 输出应映射回vocab_size
def forward(self, x, hidden_and_cell):
embeds = self.embedding(x)
out, (hidden, cell) = self.lstm(embeds, hidden_and_cell)
out = self.fc(out) # 不要在这里调整视图,让损失计算时再调整
return out, (hidden, cell)
# 初始化模型、损失函数和优化器
model = CharLSTM(vocab_size, hidden_size, num_layers)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
6.3 训练模型
# 训练模型
for epoch in range(epochs):
start_idx = np.random.randint(0, len(data) - seq_length)
inputs = torch.tensor(data[start_idx:start_idx+seq_length]).long().unsqueeze(0) # 增加批次维度
targets = torch.tensor(data[start_idx+1:start_idx+seq_length+1]).long()
hidden_and_cell = (torch.zeros(num_layers, batch_size, hidden_size),
torch.zeros(num_layers, batch_size, hidden_size))
outputs, (hidden, cell) = model(inputs, hidden_and_cell)
loss = criterion(outputs.view(-1, vocab_size), targets.view(-1)) # 确保形状匹配
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 500 == 0:
print(f'Epoch {epoch}, Loss: {loss.item():.4f}')
6.4 验证模型
# 生成函数(需适配中文字符)
def generate_chinese_text(seed_str, length=100, temperature=0.5):
# 初始化隐藏状态和细胞状态,确保批次大小为1
hidden_and_cell = (torch.zeros(num_layers, batch_size, hidden_size),
torch.zeros(num_layers, batch_size, hidden_size))
generated = seed_str
# 初始化输入序列为种子字符串,并调整形状以适应模型输入要求(batch_size, seq_length)
input_seq = torch.tensor([[char_to_idx[ch]] for ch in seed_str]).long() # 形状应为(1, len(seed_str))
input_seq = torch.permute(input=input_seq, dims=(1, 0))
with torch.no_grad(): # 禁用梯度计算提高效率
for _ in range(length):
outputs, (hidden, cell) = model(input_seq, hidden_and_cell) # 不需要调用.float()
prob = torch.softmax(outputs[0, -1, :] / temperature, dim=0).detach()
next_char_idx = torch.multinomial(prob, 1).item()
generated += idx_to_char[next_char_idx]
input_seq = torch.tensor([[next_char_idx]], dtype=torch.long) # 形状应为(1, 1)
hidden_and_cell = (hidden, cell) # 更新隐藏状态和细胞状态
return generated
# 示例生成
print(generate_chinese_text(seed_str="早餐", length=50))
输出结果:
早餐都还不错。闹中取静的一个地方,在窗前能看到不错的风景。\
酒店价格的确有些偏高价格偏高,好象连云港这地方
从生成结果上来看,确实比 基于 RNN 训练出来的模型,效果要好很多,
从训练时间上来看,基于LSTM训练模型的时间也增加了不少。
RNN训练耗时: 35 秒,生成耗时: 0.0038 秒
LSTM训练耗时:170 秒,生成耗时: 0.0482 秒
GRU训练耗时:120 秒,生成耗时: 0.0498 秒
七、总结
- RNN:适合短序列任务,计算简单但无法处理长依赖。
- LSTM:通过门控机制解决长依赖问题,适合复杂任务但计算成本高。
- GRU:在 LSTM 基础上简化,平衡性能和效率。
根据任务需求和资源限制,选择合适模型:优先尝试 GRU,若效果不足再换 LSTM。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









