









数据预处理如下,下文不再重复
import lightgbm as lgb
import xgboost as xgb
from catboost import CatBoostRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
def rmse(y_true, y_pred):
return round(np.sqrt(mean_squared_error(y_true, y_pred)), 5)
def load_preprocessed_dfs(drop_full_visitor_id=True):
"""
Loads files `TRAIN`, `TEST` and `Y` generated by preprocess() into variables
"""
X_train = pd.read_csv(TRAIN, converters={'fullVisitorId': str})
X_test = pd.read_csv(TEST, converters={'fullVisitorId': str})
y_train = pd.read_csv(Y, names=['LogRevenue']).T.squeeze()
# This is the only `object` column, we drop it for train and evaluation
if drop_full_visitor_id:
X_train = X_train.drop(['fullVisitorId'], axis=1)
X_test = X_test.drop(['fullVisitorId'], axis=1)
return X_train, y_train, X_test
X, y, X_test = load_preprocessed_dfs()
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.15, random_state=1)
print(f"Train shape: {X_train.shape}")
print(f"Validation shape: {X_val.shape}")
print(f"Test (submit) shape: {X_test.shape}")

1.XGBoost
官方文档
https://xgboost.readthedocs.io/en/stable/parameter.html
介绍与使用
介绍
高阶树模型,它的出现略晚于随机森林

使用
pip install xgboost
原生接口
def run_xgb(X_train, y_train, X_val, y_val, X_test):
# 参数参考官方文档
params = {'objective': 'reg:linear',
'eval_metric': 'rmse',
'eta': 0.001,
'max_depth': 10,
'subsample': 0.6,
'colsample_bytree': 0.6,
'alpha':0.001,
'random_state': 42,
'silent': True}
xgb_train_data = xgb.DMatrix(X_train, y_train)
xgb_val_data = xgb.DMatrix(X_val, y_val)
xgb_submit_data = xgb.DMatrix(X_test)
model = xgb.train(params, xgb_train_data,
num_boost_round=2000, # 训练轮数
evals= [(xgb_train_data, 'train'), (xgb_val_data, 'valid')],
early_stopping_rounds=100, # 超过100epchos可以提前停止
verbose_eval=500 #每500次打印一次精度
)
y_pred_train = model.predict(xgb_train_data, ntree_limit=model.best_ntree_limit)
y_pred_val = model.predict(xgb_val_data, ntree_limit=model.best_ntree_limit)
y_pred_submit = model.predict(xgb_submit_data, ntree_limit=model.best_ntree_limit)
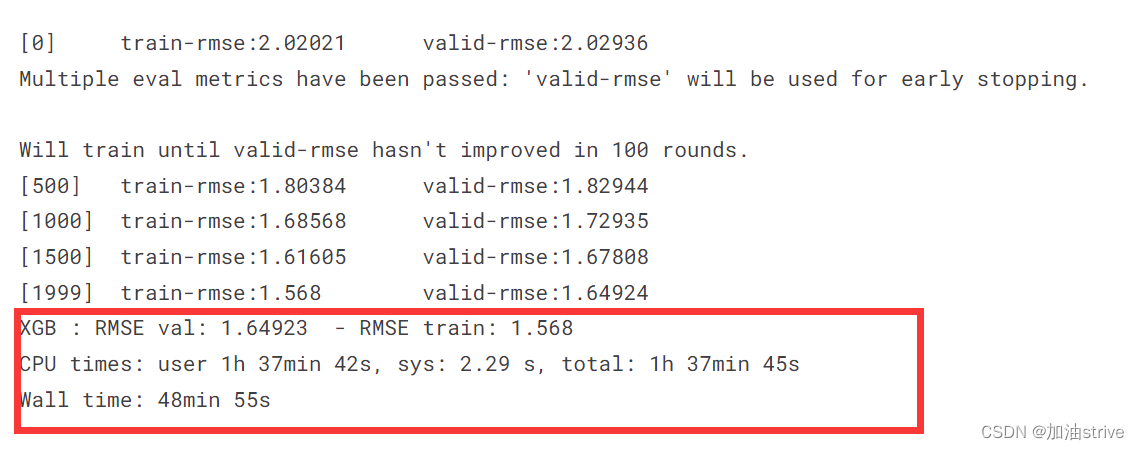
print(f"XGB : RMSE val: {rmse(y_val, y_pred_val)} - RMSE train: {rmse(y_train, y_pred_train)}")
return y_pred_submit, model
%%time
xgb_preds, xgb_model = run_xgb(X_train, y_train, X_val, y_val, X_test)
2.LightGBM
官方文档
https://lightgbm.readthedocs.io/en/latest/
介绍与使用
LightGBM是对XGBoost节点分裂方面的一些改进

使用
pip install lightgbm
原生接口
def run_lgb(X_train, y_train, X_val, y_val, X_test):
# 参数作用参考官方文档
params = {
"objective" : "regression",
"metric" : "rmse",
"num_leaves" : 40,
"learning_rate" : 0.005,
"bagging_fraction" : 0.6,
"feature_fraction" : 0.6,
"bagging_frequency" : 6,
"bagging_seed" : 42,
"verbosity" : -1,
"seed": 42
}
# 数据集封装
lgb_train_data = lgb.Dataset(X_train, label=y_train)
lgb_val_data = lgb.Dataset(X_val, label=y_val)
# train的参数如上
model = lgb.train(params, lgb_train_data,
num_boost_round=5000,
valid_sets=[lgb_train_data, lgb_val_data],
early_stopping_rounds=100,
verbose_eval=500)
y_pred_train = model.predict(X_train, num_iteration=model.best_iteration)
y_pred_val = model.predict(X_val, num_iteration=model.best_iteration)
y_pred_submit = model.predict(X_test, num_iteration=model.best_iteration)
print(f"LGBM: RMSE val: {rmse(y_val, y_pred_val)} - RMSE train: {rmse(y_train, y_pred_train)}")
return y_pred_submit, model
结果:
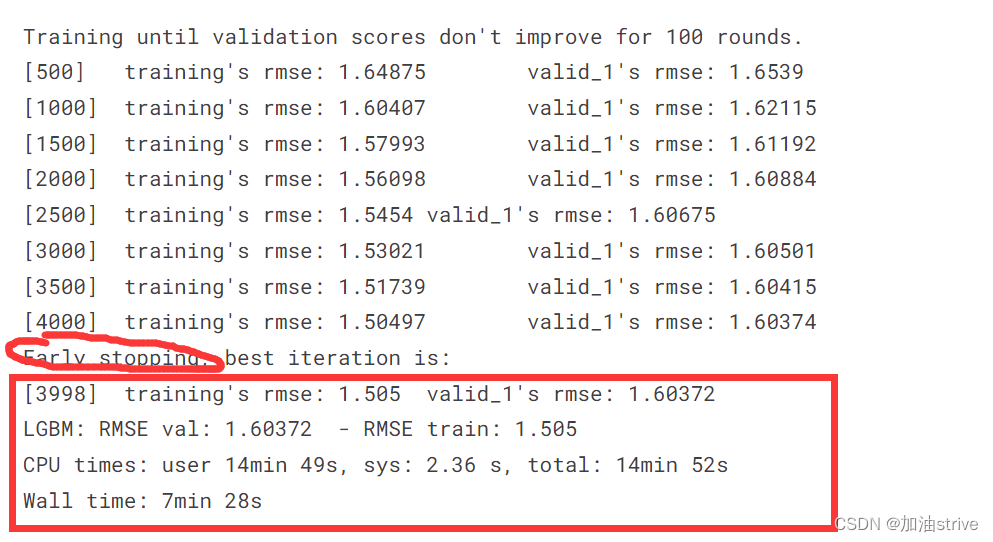
最优解相关数据
print("LightGBM features importance...")
gain = lgb_model.feature_importance('gain')
featureimp = pd.DataFrame({'feature': lgb_model.feature_name(),
'split': lgb_model.feature_importance('split'),
'gain': 100 * gain / gain.sum()}).sort_values('gain', ascending=False)
print(featureimp[:10])
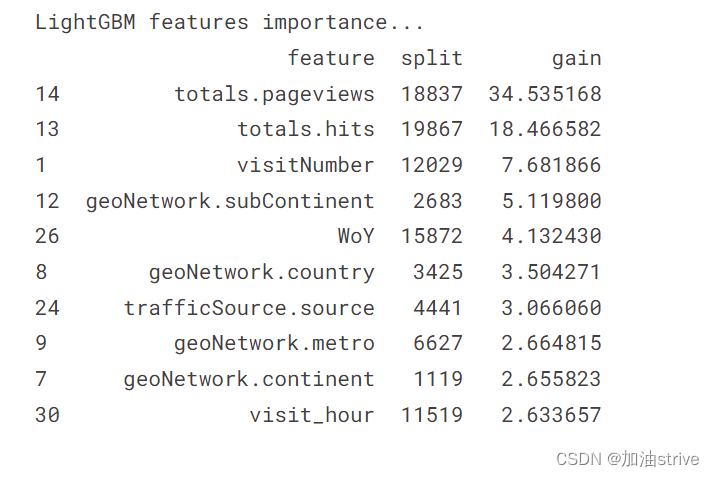
扩展:
选择gain还是split作为特征重要性衡量
https://zhuanlan.zhihu.com/p/168742240
3.CatBoost
官方文档
介绍与使用
最近几年推出的

使用
pip install catboost
sklearn接口
def run_catboost(X_train, y_train, X_val, y_val, X_test):
model = CatBoostRegressor(iterations=1000,
learning_rate=0.05,
depth=10,
eval_metric='RMSE',
random_seed = 42,
bagging_temperature = 0.2,
od_type='Iter',
metric_period = 50,
od_wait=20)
# sklearn特点 fit 和 predict
model.fit(X_train, y_train,
eval_set=(X_val, y_val),
use_best_model=True,
verbose=True)
#
y_pred_train = model.predict(X_train)
y_pred_val = model.predict(X_val)
y_pred_submit = model.predict(X_test)
print(f"CatB: RMSE val: {rmse(y_val, y_pred_val)} - RMSE train: {rmse(y_train, y_pred_train)}")
return y_pred_submit, model
对比
在相同数据集下,相同机器下,训练结果如下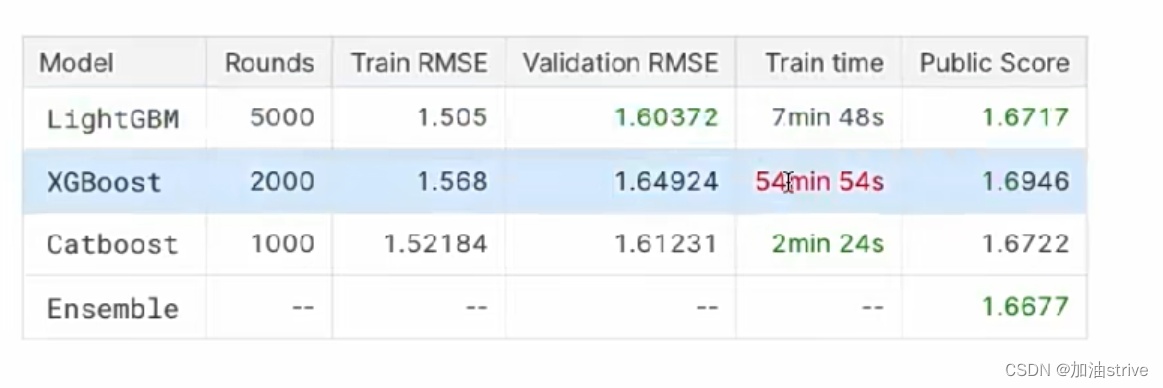
LightGBM 验证集上的RMSE最短
XGBoost上的训练时间最长
Catboost的训练时间最短
其他属性均类似,没有太大区别



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











