







余秋雨老师在第12届CCTV青年歌手电视大奖赛作评委时,曾经有过这么一段点评:“……说不出古城在今天的哪里,也许是我们的历史教育的问题。历史是由时间和空间两种坐标组成的,我们光是把注意力集中在历史年代方面,就会忘了在心中沉淀一幅 历史地图。如果不知道今天的城市在古代叫做什么名字,那么我们读起诗文和历史书来,就会遇见不小的障碍,即使是看电视剧也有问题。还是多读一些历史地理 吧。…… ”
个人觉得这段点评非常有意义,在小学和中学的历史课学习中,我们绝大多数人只关注对历史时间和历史人物的学习,并没有对历史地图多加注意,造成的后果是对一些历史名城身在何方都不知道,那么了解历史,关注历史和学习历史根本就无从谈起了。
三国是群雄割据,英雄倍出的时期,对这一时期人和事的研究具有重大的现实意义,因此,我在网上搜了一些三国地图,以补充自己在这方面的缺陷。
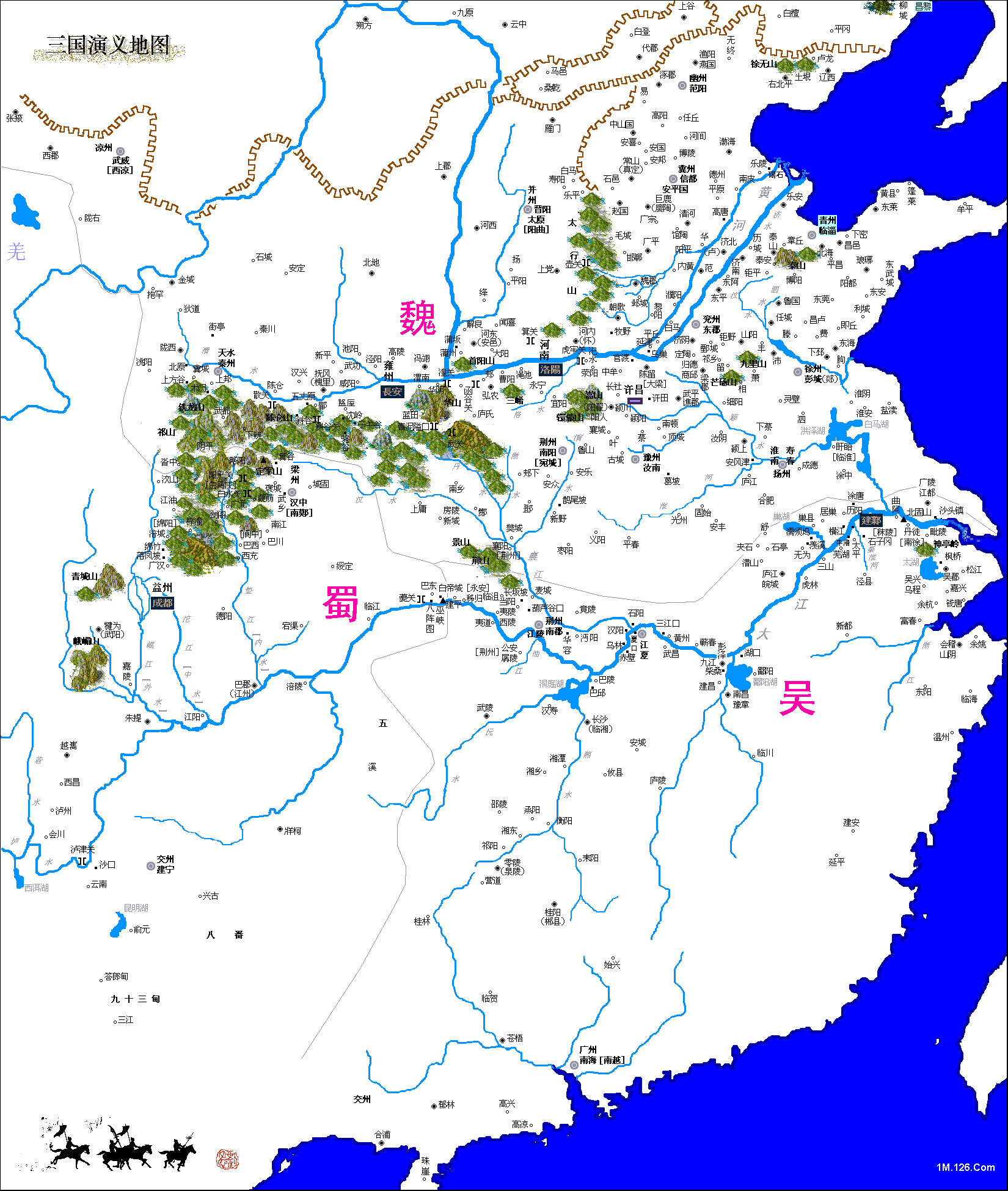
1. 三国详图
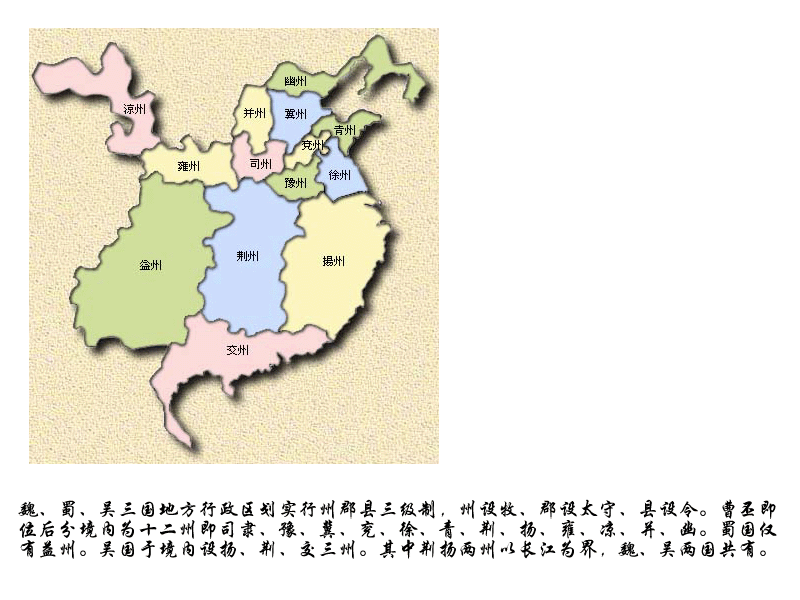
2. 三国州郡图
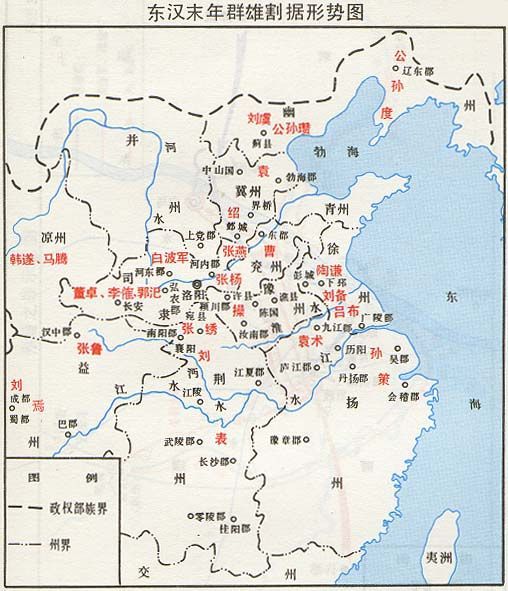
3. 三国割据图
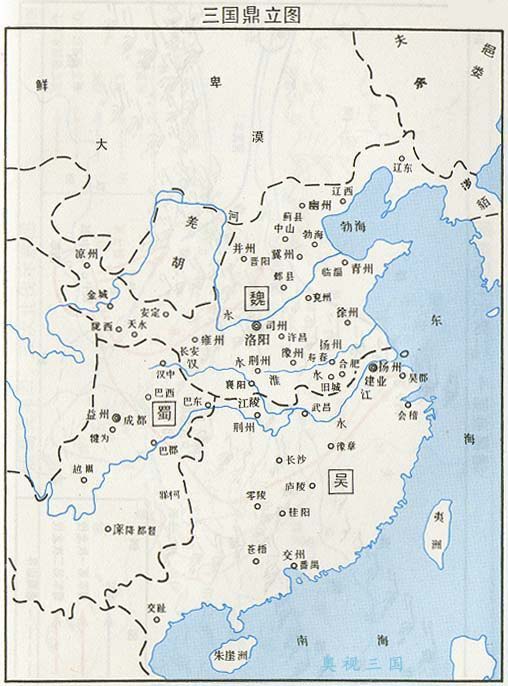
4. 三国地图
个人觉得这段点评非常有意义,在小学和中学的历史课学习中,我们绝大多数人只关注对历史时间和历史人物的学习,并没有对历史地图多加注意,造成的后果是对一些历史名城身在何方都不知道,那么了解历史,关注历史和学习历史根本就无从谈起了。
三国是群雄割据,英雄倍出的时期,对这一时期人和事的研究具有重大的现实意义,因此,我在网上搜了一些三国地图,以补充自己在这方面的缺陷。
1. 三国详图
2. 三国州郡图
3. 三国割据图
4. 三国地图

















 878
878

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









