






共有两种方案及两种优化方案:
1.先更新数据库,再删除缓存。
存在的问题:
1)删除缓存失败存在脏数据
2)难以收拢所有更新数据库入口
使用同步删除方案,你必须在所有更新数据库的地方都进行缓存的删除操作,如果你有一个地方漏掉了,对应的缓存就相当于没有删除了,就会导致脏数据问题。
还有就是如果我们通过命令行直接来更新数据库的数据,或者通过公司提供的数据库管理平台来更新数据库数据,这个时候你就没法删除了,因为你的同步删除其实只是写在你的代码里面,这个时候也就导致脏数据问题了,这也是为什么说同步删除很难覆盖所有的入口,同时存在很大的风险。
3)并发场景下存在脏数据
我们看一个例子:
例子:表A存在数据 a=1,并发情况下可能有以下流程:
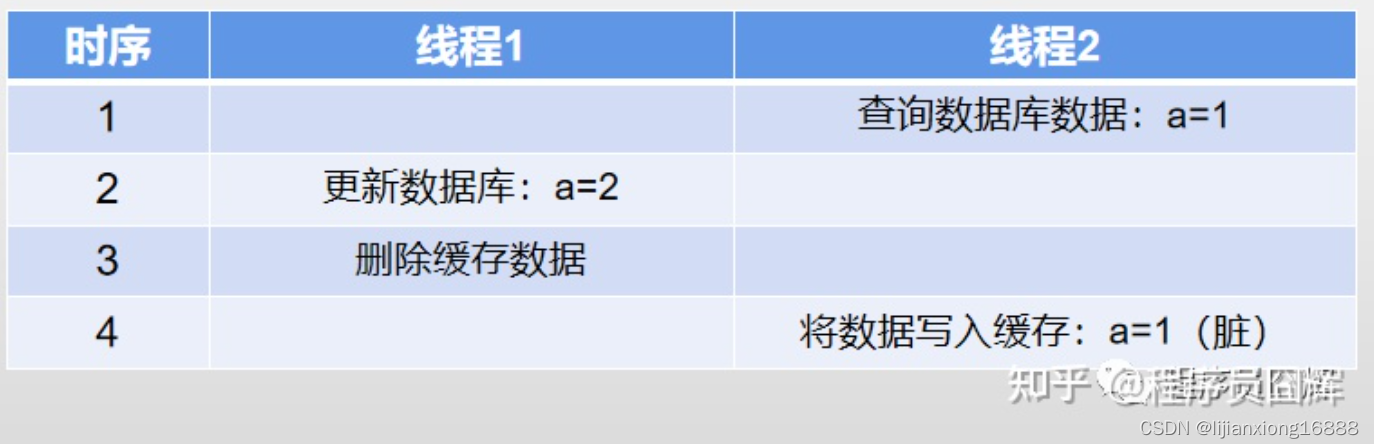
该例子中,由于线程2在查询完数据库数据之后,写入缓存之前,数据库的数据被线程1更新并且执行完同步删除操作了,所以最终导致脏数据问题,并且脏数据可能会持续很久。
当然,由于更新数据库操作耗时一般比写缓存更久,所以该例子发生的概率并不会太大,但还是有可能的。
最典型的场景就是,线程2查询完数据库之后,写缓存之前,线程2所在服务器发生了YGC,这个时候线程2可能就需要等待几十毫秒才能执行写缓存操作,这种情况就很容易出现上面这个例子了。
小结:由于难以收拢所有更新数据库入口,同时可能存在长期的脏数据问题,该方案一般不会被单独使用,但是可以作为一个补充(通过订阅binlog日志),下面的方案会提到。
2.先删缓存后更新数据库 (优化:延时双删)
先删除缓存,数据库还没有更新成功,此时如果读取缓存,缓存不存在,去数据库中读取到的是旧值,然后更新缓存,缓存不一致发生。如图:
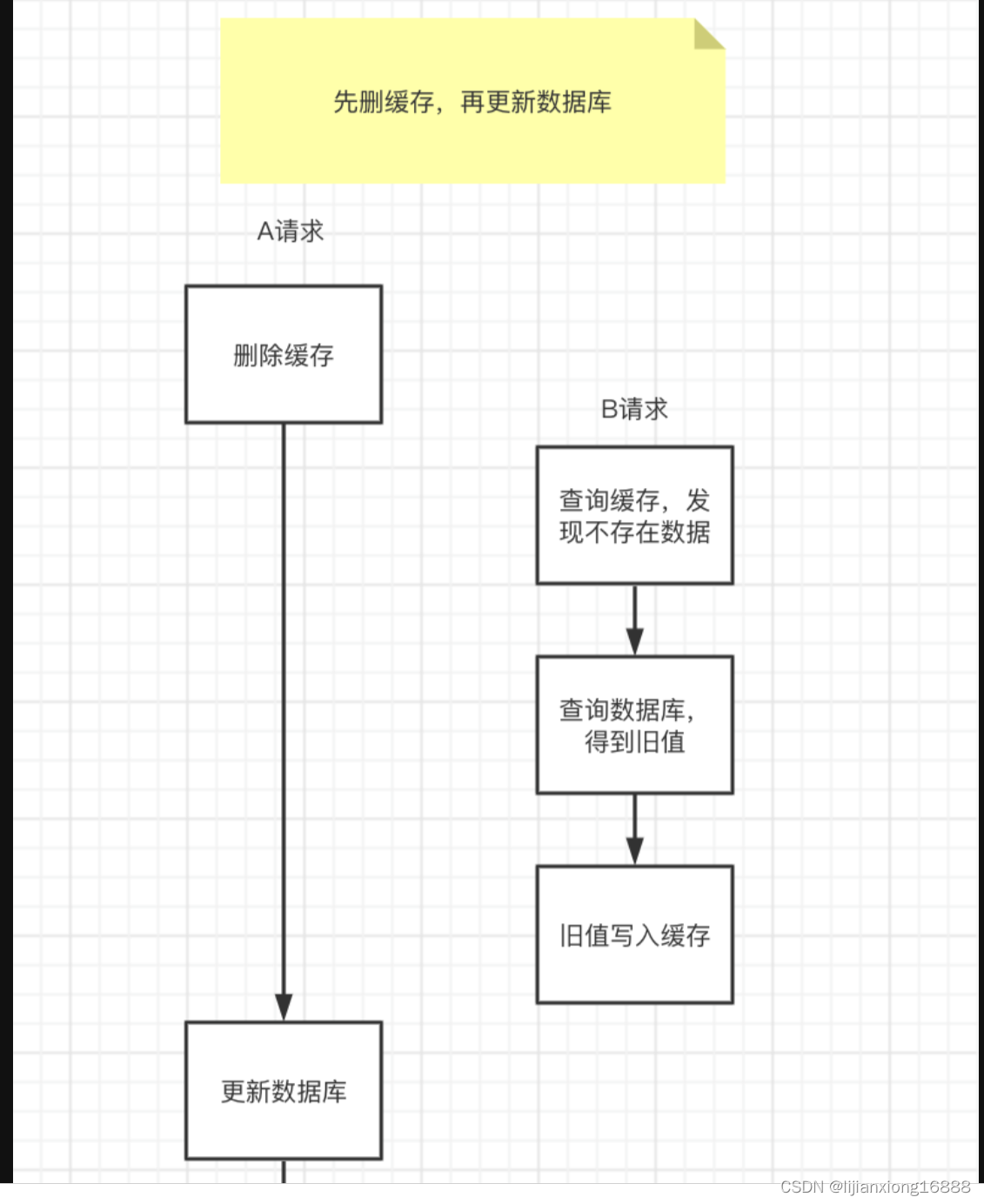
极端情况下会出现缓存不一致问题
请求A先过来,把缓存删除了。但由于网络原因,卡顿了一下,还没来得及更新数据库。
这时请求B过来了,先查询缓存发现没数据,再查数据库,有数据,但是旧值。
请求B将数据库中的旧值,更新到缓存中。
此时,请求A卡顿结束,把新值写入数据库。
3.延时双删
核心流程:
删除缓存数据
更新数据库数据
等待一小段时间
再次删除缓存数据
存在的问题:
1)延迟时间难以确认
到底是延迟一秒或者是几秒,这个其实很难确认,你总不能延迟几分钟吧,因为你如果延迟几分钟,那这几分钟可能就存在脏数据了,所以这个时间很难确定。
2)无法绝对保障数据的一致性
我们看下面这个例子:
例子:表A存在数据 a=1,并发情况下可能有以下流程
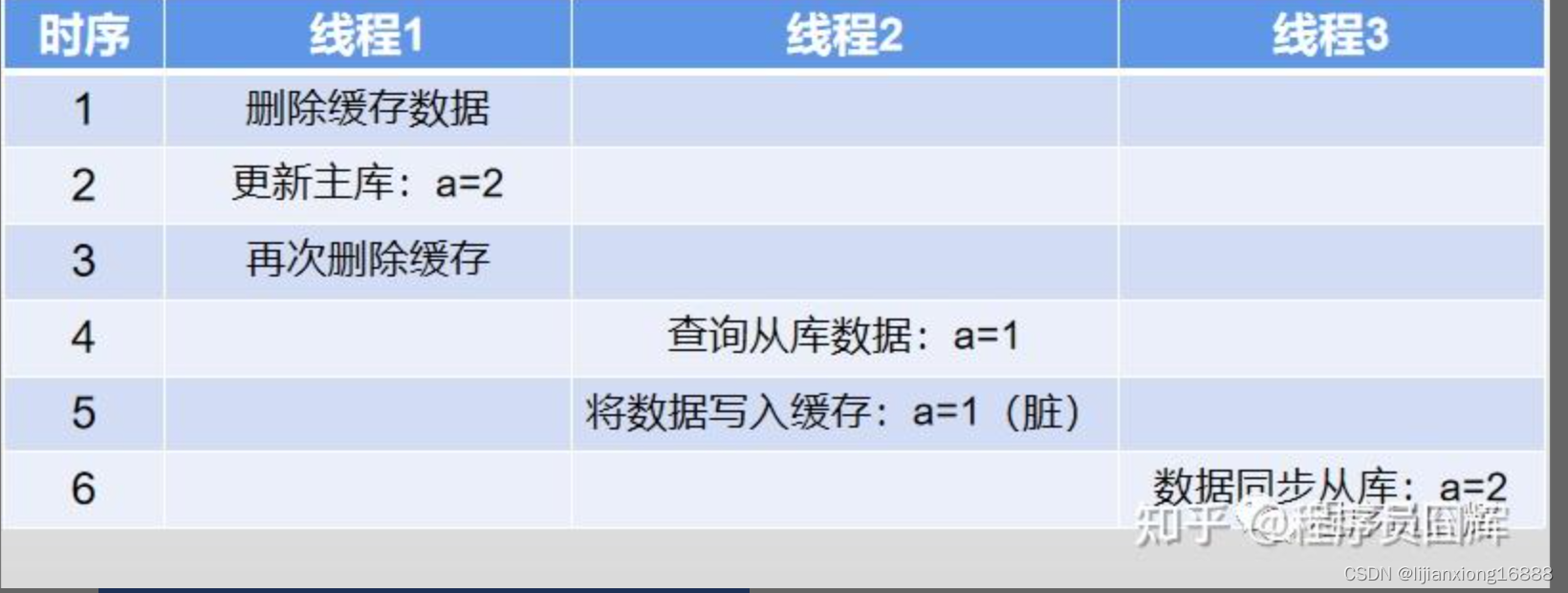
该例子中,由于数据库主从同步完成之间,存在并发的请求,从而导致脏数据问题,并且脏数据可能会持续很久。
可能有的同学觉得稍微调大点延迟时间就可以解决这个问题,但是其实主库在写压力比较大的时候,主从之间的同步延迟甚至可能是分钟级的。
因此,该方案整体来说还是有明显的问题,所以说一般也不会使用这个方案。
小结:由于延迟时间难以确认,同时无法绝对保障数据的一致性,该方案一般不会使用。
4.异步监听binlog删除 + 重试
核心流程:
更新数据库
监听binlog(canal?)删除缓存
缓存删除失败则通过MQ不断重试,直至删除成功
整体流程图如下:
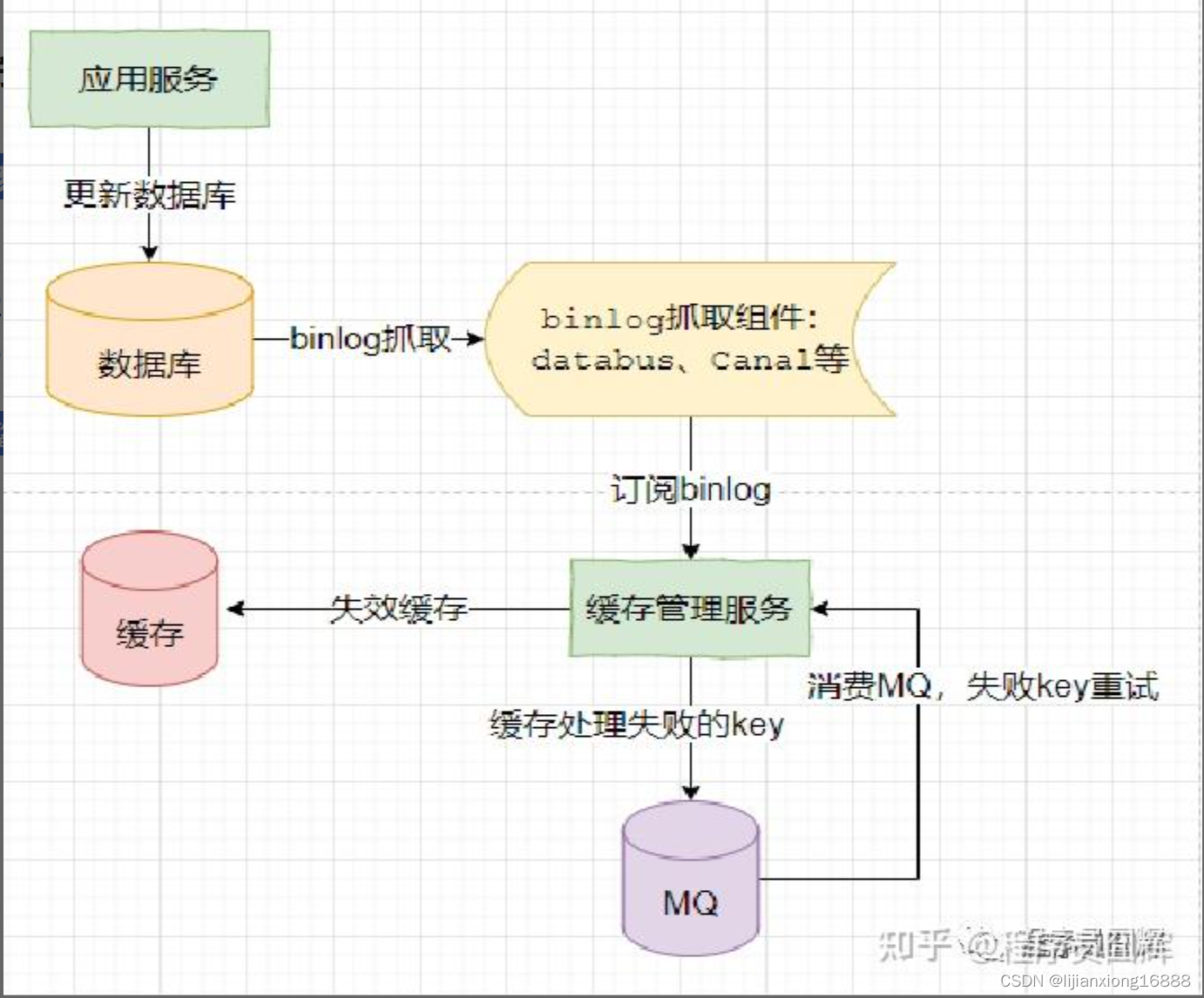
该方案是当前的主流方案,整体上没太大的问题,但是极端场景下可能还是有一些小问题。
存在的问题:
1)脏数据时间窗口“较大”
这个脏数据时间窗口较大,是相对同步删除来说。在你收到binlog之前,他中间要经过:binlog从主库同步到从库、binlog从库到binlog监听组件、binlog从监听组件发送到MQ、消费MQ消息,这些操作每个都是有一定的耗时的,可能是几十毫秒甚至几百毫秒,所以说它其实整体是有一个脏数据的时间窗口。
而同步删除是在更新完数据库后马上删除,时间窗口大概也就是1毫秒左右,所以说binlog的方式相对于同步删除,可能存在的脏数据窗口会稍微大一点。
2)极端场景下存在长期脏数据问题
binlog抓取组件宕机导致脏数据。该方案强依赖于监听binlog的组件,如果监听binlog组件出现宕机,则会导致大量脏数据。
拆库拆表流程中可能存在并发脏数据
拆库拆表流程中并发脏数据问题
我们来看下面这个例子:
表A正在进行数据库拆分,当前进行到灰度切读流量阶段:部分读新库,部分读老库
数据库拆分大致流程:增量数据同步(双写)、全量数据迁移、数据一致性校验、灰度切读、切读完毕后停写老库。
此时表A存在数据 a=1,并发情况下可能有以下流程
该例子中,灰度切读阶段中,我们还是优先保障老库的流程,因此还是先写老库,由于写新库和写老库之间存在时间间隔,导致线程2并发查询到新库的老数据,同时在监听binlog删除缓存流程之后将老数据写入缓存,从而导致脏数据问题,并且脏数据可能会持续很久。
双写的方式有很多种,我们使用的是通过公司的中间件直接将老库数据通过binlog的方式同步到新库,该方案通过监控发现在写压力较大的情况下,延迟可能会达到几秒,因此出现了上述问题。
而如果是使用代码进行同步双写,双写之间的时间间隔会较小,该问题出现的概率会相对低很多,但是还是无法保障绝对不会出现,就像上面提过的,写老库和写新库2个操作之间如果发生了YGC或者FGC,就可能导致这两个操作之间的时间间隔比较大,从而可能发生上面的案例。
还有就是代码双写的方式必须收敛所有的写入口,上文提到过的,通过命令行或者数据库管理平台的方式修改的数据,代码双写也是无法覆盖的,需要执行者在新老库都执行一遍,如果遗漏了新库,则可能导致数据问题。
小结:该方案在大多数场景下没有太大问题,业务比较小的场景可以使用,或者在其基础上进行适当补充。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









