






写在前面
对于不熟悉或者刚接触大数据不久的人来说,当听到数据湖这个概念时,可能会感到非常的困惑。即便你对数据湖不太了解的话,你也一定听说过一个名词:数据仓库,其实本质上两者都是企业用来管理不同类型格式数据的方式,以此洞察数据,辅助决策。
本文主要探讨两个概念,对数据仓库和数据湖进行对比分析,希望对你有所帮助。
什么是数据仓库?
关于什么是数据仓库,成为了一个老生常谈的问题。既然是要对比,那还是要说明一下究竟什么是数据仓库?我们先抛开所有关于大数据技术相关的内容,说一下为什么会出现数据仓。
到了20世纪80年代以后,基于关系型数据库的事务处理成为了企业IT应用的主流。在这个阶段,企业的IT应用主要还是着重于业务职能的自动化及信息的存储、汇总、统计、查询等方面,而分析能力是比较薄弱的,因此这样的信息处理模式称之为事务处理。进而,在网络应用和实时交互处理功能日益强大和普遍的今天,基于在线计算的事务处理被称之为在线事务处理(OLTP)。OLTP是事务处理从单机到网络环境发展的新阶段。
OLTP的特点在于事务处理量大,但事务处理的内容比较简单且重复率高。大量的数据操作主要涉及的是增加、删除、修改和查询等操作。OLTP在查找业务数据时是非常有效的,但是在为决策者提供决策分析时显得力不从心。
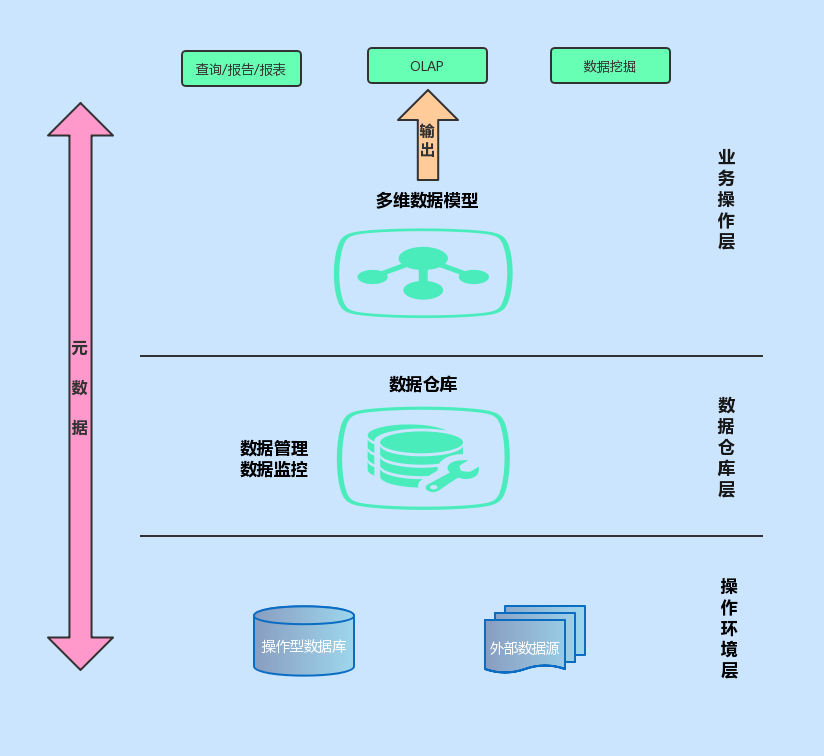
事务处理和OLTP系统主要解决业务自动化和信息查询的基本需求,是基于业务数据库实现的,然而在数据资源开发与利用的分析处理层次上,人们要求信息系统剧透对多方面数据进行综合性分析的能力,这就要求建立一个面向分析、集成保存大量历史数据的新型数据管理机制,这一机制就是数据仓库。数据仓库为数据分析处理提供了基础数据,而分析处理利用多种运算手段,对数据仓库所提供的数据进行面向管理决策的统计、展示和预测。
说完OLTP,再说OLAP,即在线分析处理。事实上,OLAP能够高速发展也得益于数据仓库技术的出现和完善。由于这两者结合的比较紧密,以至于在实际应用中,OLAP应用和数据仓库应用经常指同一个概念。所谓数据仓库,就是把一个组织中的历史数据收集到一个中央仓库中以便处理,它是支持决策过程的、面向主题的、集成的、随时间变化的、持久的数据集合,是当今信息管理中的主流趋势之一。
数据仓库通常存储来自不同源的数据,集成源数据以提供统一的视图。这些资源可以包括事务系统、应用程序日志文件、关系数据库等等。
标准数据仓库通常包括以下要素和功能:
-
数据源
-
一个 ETL 解决方案
-
商业智能
什么是数据湖?
概念
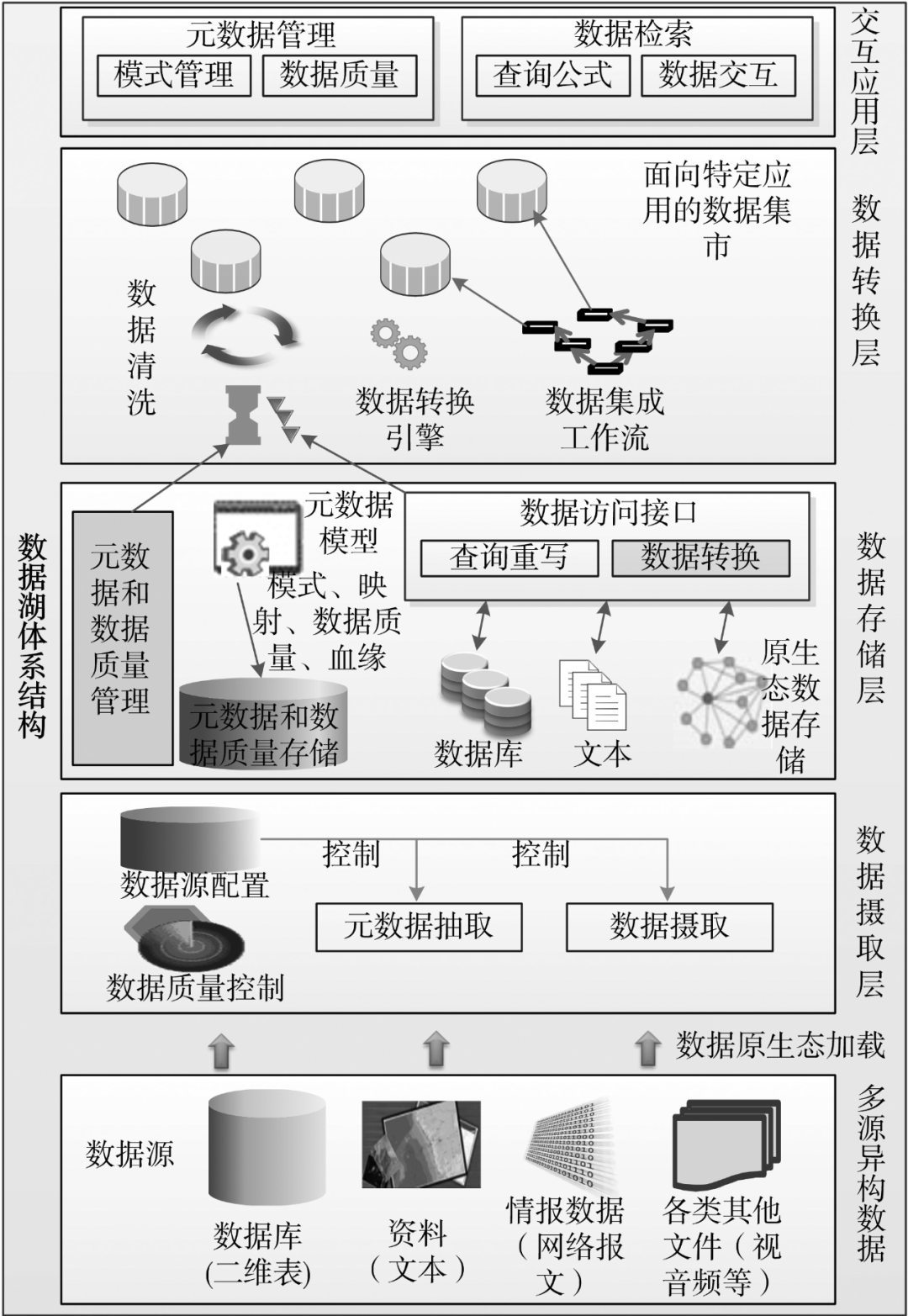
数据湖概念首次于2010年被James Dixon在 其博客帖子(https://jamesdixon.wordpress.com/2010/ 10/14/pentahohadoop-and-data-lakes/)中 提 及 ,他把数据集比喻为瓶装水,经过清洗、包装和构造化处理后便于饮用,与之相反,数据湖则管理从各类数据源引接汇聚来的原生态数据。数据湖是一个数据存储库,其中来自于多个数据源的数据以它们原生态的方式进行存储。数 湖提供从异构数据源中提取数据和元数据的功能, 并能将它们吸纳汇聚到混合存储系统中去 。数据湖提供数据转换引擎,支持数据集转换、清洗以及与其他数据集的集成,并提供用于检索和查询数 据湖数据和元数据的接口。
数据湖是一个存储库,它允许存储大量的原始数据,也就是说,没有按照特定的模式进行准备、处理或操作的数据。
数据湖的一个关键特征是不会拒绝任何数据,这意味着结构化格式和非结构化数据格式都可以存储。由于数据湖中的数据在从源获取时不受数据结构的约束,因此在需要时应用“读取”模式来促进数据分析。
数据湖具有以下特点:
-
容量大
数据湖汇 聚吸收各个业务数据源流,容纳散落在各处的数 据,理论上,存储空间巨大。
-
格式多
数据湖架构面向多数据源的信息存储,可以快 速高效地采集、存储、处理大量来源不同、格式不同 的原始数据,这其中包括文本、图片、视频、音频、网 页等各类无序的非结构化数据,能把不同种类的数 据汇聚存储在一起,并对汇聚后的数据进行管理, 建立数据之间的关联关系,具有很强的兼容性。
-
处理速度快
数据湖技术能将各类原始数据快速转化为可 以直接提取的、分析、使用的标准格式,统一优化数 据结构并对数据进行分类存储,根据业务需求,对 存储的数据进行快速的查询、挖掘、关联和处理,并实时传输给末端用户。
体系结构
由于Hadoop也能基于分布式文件系统来存储处理多类型数据,因此许多人认为Hadoop的工作机理就是数据湖的处理机制。当然,Hadoop基于其分布式、可横向扩展的文件系统架构,可以管理和处理海量数据,但是它无法提供数据湖所需要的复杂元数据管理功能,最直观的表现是,数据湖的体系结构表明数据湖是由多个组件构成的生态系统,而Hadoop仅仅提供了其中的部分组件功能。
数据湖和数据仓库之间的差异
数据类型
-
数据湖
未经处理或转换的原始数据包括结构化、非结构化或半结构化数据
-
数据仓库
在转换过程中结构化的数据
目的
-
数据湖
数据湖旨在存储大量的数据和数据格式,以备将来需要时使用
-
数据仓库
仅用于执行大量历史数据的查询和分析
用户
-
数据湖
作为原始数据,非结构化数据的数据库,数据湖的主要使用对象是数据科学家。
-
数据仓库
结构化数据,使用非常方便,主要的使用对象是数据分析师、数据工程师、运营人员等等。
作用
-
数据湖
非结构化数据的灵活性和可扩展性意味着它们有利于大数据分析和一些深度学习项目。
-
数据仓库:
支持数据报表、产品,扩展商业智能能力
存储容量
-
数据湖
由于包含所有数据,通常是PB级别的。
-
数据仓库
数据仓库对存储的数据更有选择性,一般比数据湖要小,但与传统数据库相比仍然很大
数据质量
-
数据湖
由于缺少模式, 所有数据都允许输入,因此,数据湖包含较低级别的数据质量。
-
数据仓库
通常经过ETL之后,都是格式化的高质量的数据。
处理方式
-
数据湖
先装载至数据湖,当访问时才会去解析成所需要的格式,即读模式。
-
数据仓库
进入数仓需要经过ETL,转换成固定模式的数据,即写模式。
敏捷性
-
数据湖
敏捷性是数据湖的标准,数据湖不需要等待很长的开发周期就能满足数据洞察的需求。
-
数据仓库
数据仓库的本质是高度结构化的,用于存储特定的数据格式并回答特定的问题,因此,在敏捷性方面不如数据湖。
总结
尽管存在差异,但是数据湖和数据仓库可以用来互补,数据湖可以在非结构化数据处理方面扩展业务能力。对于许多公司来说,通过数据湖来增强现有的数据仓库,已经被证明是一种高效的方式。
















 566
566











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









