







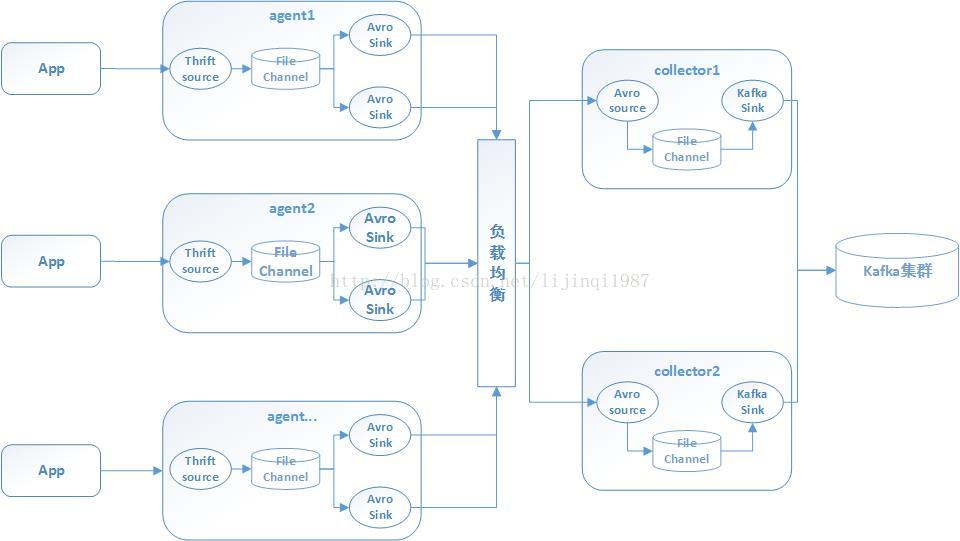
项目需求是将线上服务器生成的日志信息实时导入kafka,采用agent和collector分层传输,app的数据通过thrift传给agent,agent通过avro sink将数据发给collector,collector将数据汇集后,发送给kafka,拓扑结构如下:
现将调试过程中遇到的问题以及解决方法记录如下:
1、 [ERROR - org.apache.thrift.server.AbstractNonblockingServer$FrameBuffer.invoke(AbstractNonblockingServer.java:484)] Unexpected throwable while invoking!
java.lang.OutOfMemoryError: Java heap space
原因:flume启动时的默认最大的堆内存大小是20M,实际环境中数据量较大时,很容易出现OOM问题,在flume的基础配置文件conf下的flume-env.sh中添加
export JAVA_OPTS="-Xms2048m -Xmx2048m -Xss256k -Xmn1g -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:-UseGCOverheadLimit"
并且在flume启动脚本flume-ng中,修改JAVA_OPTS="-Xmx20m"为JAVA_OPTS="-Xmx2048m"
此处我们将堆内存的阈值跳转到了2G,实际生产环境中可以根据具体的硬件情况作出调整
2、 [ERROR - org.apache.thrift.server.TThreadedSelectorServer$SelectorThread.run(TThreadedSelectorServer.java:544)] run() exiting due to uncaught error
java.lang.OutOfMemoryError: unable to create new native thread
原因:如果App给flume的thrift source发送数据时,采用短连接,会无限地创建线程,使用命令 pstree 时发现java的线程数随着发送数据量的增长在不停增长,最终达到了65500多个,超过了linux系统对线程的限制,解决方法是在thrift source配置项中增加一个线程数的限制。
agent.sources.r1.threads = 50
重新启动agent发现java的线程数达到70多就不再增长了
3、 Caused by: org.apache.flume.ChannelException: Put queue for MemoryTransaction of capacity 100 full, consider committing more frequently, increasing capacity or increasing thread count
原因:这是memory channel被占满导致的错误,memory channel默认最多只缓存100条数据,在生产环境中明显不够,需要将capacity参数加大
4、warn:"Thrift source %s could not append events to the channel."。
原因:查看flume的配置文档可以发现,各种类型的sink(thrift、avro、kafka等)的默认batch-size都是100,file channel、memory channel的transactioncapacity默认也都是100,如果修改了sink的batch-size,需要将batch-size设置为小于等于channel的transactioncapacity的值,否则就会出现上面的warn导致数据无法正常发送
5、agent处报
(SinkRunner-PollingRunner-DefaultSinkProcessor) [ERROR - org.apache.flume.SinkRunner$PollingRunner.run(SinkRunner.java:160)] Unable to deliver event. Exception follows.
org.apache.flume.EventDeliveryException: Failed to send events
at org.apache.flume.sink.AbstractRpcSink.process(AbstractRpcSink.java:392)
at org.apache.flume.sink.DefaultSinkProcessor.process(DefaultSinkProcessor.java:68)
at org.apache.flume.SinkRunner$PollingRunner.run(SinkRunner.java:147)
at java.lang.Thread.run(Thread.java:744)
Caused by: org.apache.flume.EventDeliveryException: NettyAvroRpcClient { host: 10.200.197.82, port: 5150 }: Failed to send batch
at org.apache.flume.api.NettyAvroRpcClient.appendBatch(NettyAvroRpcClient.java:315)
at org.apache.flume.sink.AbstractRpcSink.process(AbstractRpcSink.java:376)
... 3 more
Caused by: org.apache.flume.EventDeliveryException: NettyAvroRpcClient { host: 10.200.197.82, port: 5150 }: Exception thrown from remote handler
at org.apache.flume.api.NettyAvroRpcClient.waitForStatusOK(NettyAvroRpcClient.java:397)
at org.apache.flume.api.NettyAvroRpcClient.appendBatch(NettyAvroRpcClient.java:374)
at org.apache.flume.api.NettyAvroRpcClient.appendBatch(NettyAvroRpcClient.java:303)
... 4 more
Caused by: java.util.concurrent.ExecutionException: java.io.IOException: Connection reset by peer
at org.apache.avro.ipc.CallFuture.get(CallFuture.java:128)
at org.apache.flume.api.NettyAvroRpcClient.waitForStatusOK(NettyAvroRpcClient.java:389)
... 6 more
Caused by: java.io.IOException: Connection reset by peer
at sun.nio.ch.FileDispatcherImpl.read0(Native Method)
at sun.nio.ch.SocketDispatcher.read(SocketDispatcher.java:39)
at sun.nio.ch.IOUtil.readIntoNativeBuffer(IOUtil.java:223)
at sun.nio.ch.IOUtil.read(IOUtil.java:192)
at sun.nio.ch.SocketChannelImpl.read(SocketChannelImpl.java:379)
at org.jboss.netty.channel.socket.nio.NioWorker.read(NioWorker.java:59)
at org.jboss.netty.channel.socket.nio.AbstractNioWorker.processSelectedKeys(AbstractNioWorker.java:471)
at org.jboss.netty.channel.socket.nio.AbstractNioWorker.run(AbstractNioWorker.java:332)
at org.jboss.netty.channel.socket.nio.NioWorker.run(NioWorker.java:35)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
... 1 more
collector报
2017-08-21 16:36:43,010 (New I/O worker #12) [WARN - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.exceptionCaught(NettyServer.java:201)] Unexpected exception from downstream.
org.apache.avro.AvroRuntimeException: Excessively large list allocation request detected: 349070535 items! Connection closed.
at org.apache.avro.ipc.NettyTransportCodec$NettyFrameDecoder.decodePackHeader(NettyTransportCodec.java:167)
at org.apache.avro.ipc.NettyTransportCodec$NettyFrameDecoder.decode(NettyTransportCodec.java:139)
at org.jboss.netty.handler.codec.frame.FrameDecoder.callDecode(FrameDecoder.java:422)
at org.jboss.netty.handler.codec.frame.FrameDecoder.cleanup(FrameDecoder.java:478)
at org.jboss.netty.handler.codec.frame.FrameDecoder.channelDisconnected(FrameDecoder.java:366)
at org.jboss.netty.channel.Channels.fireChannelDisconnected(Channels.java:399)
at org.jboss.netty.channel.socket.nio.AbstractNioWorker.close(AbstractNioWorker.java:721)
at org.jboss.netty.channel.socket.nio.NioServerSocketPipelineSink.handleAcceptedSocket(NioServerSocketPipelineSink.java:111)
at org.jboss.netty.channel.socket.nio.NioServerSocketPipelineSink.eventSunk(NioServerSocketPipelineSink.java:66)
at org.jboss.netty.handler.codec.oneone.OneToOneEncoder.handleDownstream(OneToOneEncoder.java:54)
at org.jboss.netty.channel.Channels.close(Channels.java:820)
at org.jboss.netty.channel.AbstractChannel.close(AbstractChannel.java:197)
at org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.exceptionCaught(NettyServer.java:202)
at org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:173)
at org.jboss.netty.handler.codec.frame.FrameDecoder.exceptionCaught(FrameDecoder.java:378)
at org.jboss.netty.channel.Channels.fireExceptionCaught(Channels.java:533)
at org.jboss.netty.channel.AbstractChannelSink.exceptionCaught(AbstractChannelSink.java:48)
at org.jboss.netty.channel.Channels.fireMessageReceived(Channels.java:268)
at org.jboss.netty.channel.Channels.fireMessageReceived(Channels.java:255)
at org.jboss.netty.channel.socket.nio.NioWorker.read(NioWorker.java:84)
at org.jboss.netty.channel.socket.nio.AbstractNioWorker.processSelectedKeys(AbstractNioWorker.java:471)
at org.jboss.netty.channel.socket.nio.AbstractNioWorker.run(AbstractNioWorker.java:332)
at org.jboss.netty.channel.socket.nio.NioWorker.run(NioWorker.java:35)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
原因:当agent到collector的数据在agent的avro sink处进行压缩时,在collector的avro source处必须解压,否则数据无法发送
6、org.apache.kafka.common.errors.RecordTooLargeException: There are some messages at [Partition=Offset]: {ssp_package-0=388595} whose size is larger than the fetch size 1048576 and hence cannot be ever returned. Increase the fetch size, or decrease the maximum message size the broker will allow.
2017-10-11 01:30:10,000 (PollableSourceRunner-KafkaSource-r1) [ERROR - org.apache.flume.source.kafka.KafkaSource.doProcess(KafkaSource.java:314)] KafkaSource EXCEPTION, {}
原因:配置kafka source时,flume作为kafka的consumer,在consumer消费kafka数据时,默认最大文件大小是1m,如果文件大小超过1m,需要手动在配置里面调整参数,
但是在flume官网的配置说明-kakka source中,并没有找到配置fetch size的地方,但是在配置的最后一行有一个
Other Kafka Consumer Properties--These properties are used to configure the Kafka Consumer. Any consumer property supported by Kafka can be used. The only requirement is to prepend the property name with the prefix kafka.consumer. For example: kafka.consumer.auto.offset.reset
此处配置用的是kafka的配置方法,在kafka官网的配置文档-consumer configs-max.partition.fetch.bytes有相关说明
agent.sources.r1.kafka.consumer.max.partition.fetch.bytes = 10240000
此处将consumer的fetch.byte加到10m
7、2017-10-13 01:19:47,991 (SinkRunner-PollingRunner-DefaultSinkProcessor) [ERROR - org.apache.flume.sink.kafka.KafkaSink.process(KafkaSink.java:240)] Failed to publish events
java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.RecordTooLargeException: The message is 2606058 bytes when serialized which is larger than the maximum request size you have configured with the max.request.size configuration.
at org.apache.kafka.clients.producer.KafkaProducer$FutureFailure.<init>(KafkaProducer.java:686)
at org.apache.kafka.clients.producer.KafkaProducer.send(KafkaProducer.java:449)
at org.apache.flume.sink.kafka.KafkaSink.process(KafkaSink.java:212)
at org.apache.flume.sink.DefaultSinkProcessor.process(DefaultSinkProcessor.java:67)
at org.apache.flume.SinkRunner$PollingRunner.run(SinkRunner.java:145)
at java.lang.Thread.run(Thread.java:745)
Caused by: org.apache.kafka.common.errors.RecordTooLargeException: The message is 2606058 bytes when serialized which is larger than the maximum request size you have configured with the max.request.size configuration.
原因:与上一点类似,此处是kafka sink时,flume作为producer,也要设置文件的fetch大小,同样是参考kafka官网的配置
agent.sinks.k1.kafka.producer.max.request.size = 10240000
8、java.io.IOException: Too many open files
at sun.nio.ch.ServerSocketChannelImpl.accept0(Native Method)
at sun.nio.ch.ServerSocketChannelImpl.accept(ServerSocketChannelImpl.java:250)
at org.mortbay.jetty.nio.SelectChannelConnector$1.acceptChannel(SelectChannelConnector.java:75)
at org.mortbay.io.nio.SelectorManager$SelectSet.doSelect(SelectorManager.java:686)
at org.mortbay.io.nio.SelectorManager.doSelect(SelectorManager.java:192)
at org.mortbay.jetty.nio.SelectChannelConnector.accept(SelectChannelConnector.java:124)
at org.mortbay.jetty.AbstractConnector$Acceptor.run(AbstractConnector.java:708)
at org.mortbay.thread.QueuedThreadPool$PoolThread.run(QueuedThreadPool.java:582)
原因:文件句柄占用太多,首先查看flume占用句柄个数
lsof -p pid | wc -l
pid是flume进程号,
vim /etc/security/limits.conf
在最后加入
* soft nofile 4096
* hard nofile 4096
最前的 * 表示所有用户,改完后重启下flume服务
9、(kafka-producer-network-thread | producer-1) [ERROR - org.apache.kafka.clients.producer.internals.Sender.run(Sender.java:130)] Uncaught
error in kafka producer I/O thread:
org.apache.kafka.common.protocol.types.SchemaException: Error reading field 'throttle_time_ms': java.nio.BufferUnderflowException
at org.apache.kafka.common.protocol.types.Schema.read(Schema.java:71)
at org.apache.kafka.clients.NetworkClient.handleCompletedReceives(NetworkClient.java:439)
at org.apache.kafka.clients.NetworkClient.poll(NetworkClient.java:265)
at org.apache.kafka.clients.producer.internals.Sender.run(Sender.java:216)
at org.apache.kafka.clients.producer.internals.Sender.run(Sender.java:128)
at java.lang.Thread.run(Thread.java:744)
原因:kafka集群版本较老,flume版本较新,此处kafka使用的版本是较老的0.8.2, flume使用1.7则会报上述错误,只能将flume降为1.6版本
9、sink到kafka上的数据没有均匀的分布在各个partition上,而是全部放在了同一个partition上
原因:这是老版本flume遗留下的一个bug,需要在event中构造一个包含key为 key 的header 键值对就能达到目的
a1.sources.flume0.interceptors.i1.type = org.apache.flume.sink.solr.morphline.UUIDInterceptor$Builder
a1.sources.flume0.interceptors.i1.headerName = key
















 448
448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









