







Redis是现在最受欢迎的NoSQL数据库之一,Redis是一个使用ANSI C编写的开源、包含多种数据结构、支持网络、基于内存、可选持久性的键值对存储数据库。
一、使用内存进行存储
redis是使用内存来进行数据存储的,所以redis的访问速度要远远快于mysql,因为是使用内存存储数据,可以避免频繁的进行写盘操作,大大降低响应时间:

二、单线程结构
在使用多线程的过程中,对于共享变量的访问,会将多线程操作变成单线程进行操作,并且还需要增加额外的同步术语(例如java中的锁),存在的一定的性能开销,并且多个线程在进行锁竞争的时候,也会影响系统的吞吐性
redis采用单线程来处理主要的响应命令,既不需要考虑数据安全问题,不需要额外去使用锁来降低性能开销,同时可以避免多线程的上下文切换的开销
redis的单线程并不是指,在整个redis的服务端只有一个线程在进行工作,只是在接受客户端的IO请求响应进行读写的时候是单线程的操作;redis本身是存在多线程的使用场景的,比如:异步删除、持久化、集群同步。
三、高性能的多路复用IO模型
redis一个线程可以处理多个客户端连接,并且通过事件监听的机制,并通过基于事件的回调机制,即针对不同事件的发生,调用相应的处理函数,通过这种事件回调机制,可以避免redis去一直轮询关注是否有对应的事件发生,避免cpu的浪费
相当于redis单线程不会阻塞在某一个特定的操作上,所以一个redis的服务端,可以提供给多个客户端进行连接

四、丰富的数据结构
redis是一个键值对存储的关系型数据库,对于key来说就是单一的string结构,但对于value,提供了丰富的数据结构:string、list、hast、set、sorted set。
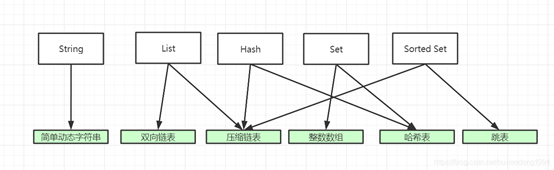
• String的底层是(简单动态字符串)
• List的底层是(双向链表和压缩链表)
• Hash的底层是(压缩链表和哈希表)
• Set的底层是(整数数组和哈希表)
• Sorted Set底层(压缩链表和跳表)
为了保证数据的快速查找redis的键值对采用的是哈希表的存储方式,来进行数据的存储,但因为其value的多样性,哈希表中存储的并不是具体的值,而是一个内存引用地址,在通过内存引用的地址查找到对应的具体的值。其结构如下图所示:

因为hash的结构,所以其查找数据的时间复杂度为O(1)。















 420
420











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









