







数据库调优从以下几个方面进行调优
- 数据库配置
- SQL优化
- 硬件设置
- 文件系统
- 操作系统
1. 数据库配置
- InnoDB存储引擎与PostgreSQL非常不同
- InnoDB的缓冲池用来管理所有数据库对象
- 写文件操作通过O_DIRECT选项来避免两次缓存
- InnoDB缓冲池越大性能越好
- 通常是系统内存60%~80%
- PostgreSQL缓冲池仅用来管理最热的数据
- 强烈的依赖操作系统的缓存来处理数据
- PostgreSQL缓存越大性能越差
- 通常是系统内存通常25%~30%
#配置文件
innodb_buffer_pool_size = 100G
innodb_buffer_pool_instances = 16
innodb_page_size = 4096
innodb_flush_method = O_DIRECT
#在线设置buffer pool大小
# MySQL 5.7 online resize buffer pool
mysql> set global innodb_disable_resize_buffer_pool_debug=off;
Query OK, 0 rows affected (0.00 sec)
mysql> set global innodb_buffer_pool_size=256*1024*1024;
Query OK, 0 rows affected (0.00 sec)
- FUZZY CHECKPOINT
- 刷新部分脏页,对系统影响较小
- 5.6:独立的刷新线程
- 5.7:并行刷新线程
- innodb_io_capacity
- SHARP CHECKPOINT
- 刷新全部的脏页,系统hang住
- innodb_fast_shutdown
- Neighbor Page Flush
- innodb_flush_neighbors
innodb_io_capacity = 1000/4000/8000
innodb_page_cleaners = 1 / 4
innodb_fast_shutdown = 0/1
innodb_flush_neighbors = 0/1/2
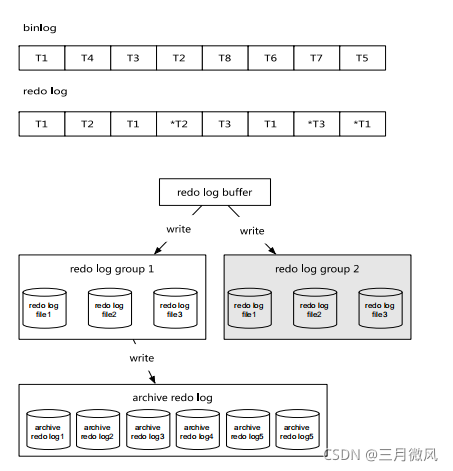
- 重做日志
- 记录页操作的日志
- 与二进制日志完全不同
- 循环覆盖写
- 默认没有类似PG或者Oracle的归档
- 重做日志大小限制
- before 5.6: max 4G
- start from 5.6: max 512G
innodb_log_file_size = 1900M / 4G
innodb_log_buffer_size = 8M / 32M
innodb_log_files_in_group = 2/3
innodb_log_group_home_dir = /redolog/
- undo段
- 实现回滚
- 实现MVCC功能
- PostgreSQL没有undo段!!!
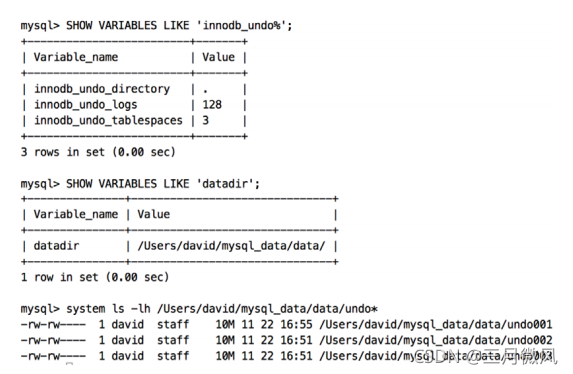
- undo段数量
- before MySQL 5.5: 1024
- start from MySQL 5.5: 128*1024
- undo回收
- purge
innodb_undo_directory = /undolog/
innodb_undo_logs = 128
innodb_undo_tablespaces = 3
innodb_undo_log_truncate = 1
innodb_max_undo_log_size = 1G
innodb_purge_rseg_truncate_frequency = 128
innodb_purge_batch_size = 300
innodb_purge_threads = 4/8
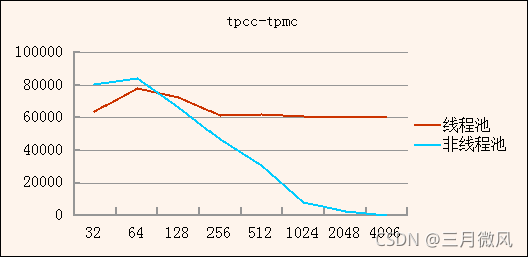
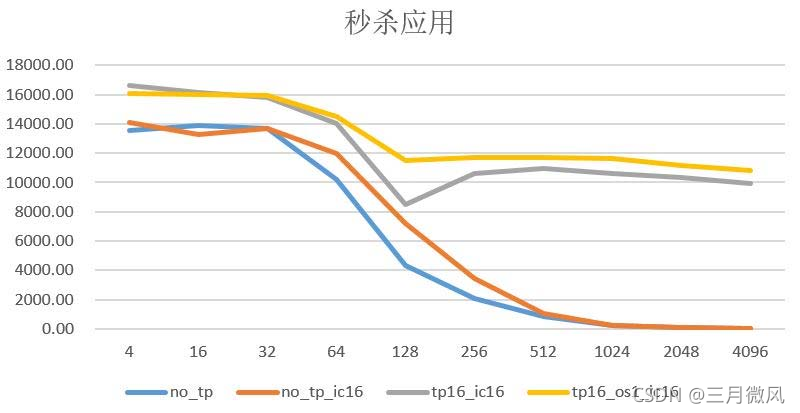
- 线程池
- 保障高并发下的性能平稳
- MariaDB线程池没有优先级队列
- 推荐MySQL/InnoSQL/Percona线程池
- 推荐默认开启用线程池
thread_handling = pool‐of‐threads
thread_pool_size = 32 # CPU
thread_pool_oversubscribe = 3
extra_port = 3333 #额外的端口
- MySQL日志配置
- binary log
- error log
- slow log
- general log(通常不推荐)
events_statements_current
events_statements_history(_long)
# 二进制文件
log‐bin = /binlog/mysqld‐bin
log‐expire‐day = 7
syslog
syslog_tag = stock #mysqld_stock
log‐slow‐queries
long_query_time = 2
log‐queries‐not‐using‐indexes
log‐slow‐admin‐statements
min‐examined‐row‐limit
log_throttle_queries_not_using_indexes
log_slow_slave_statements
[mysqld]
performance_schema
mysql> select * from setup_consumers\G
************************ 1. row ***********************
NAME: events_stages_current
ENABLED: NO
…………
2. SQL优化
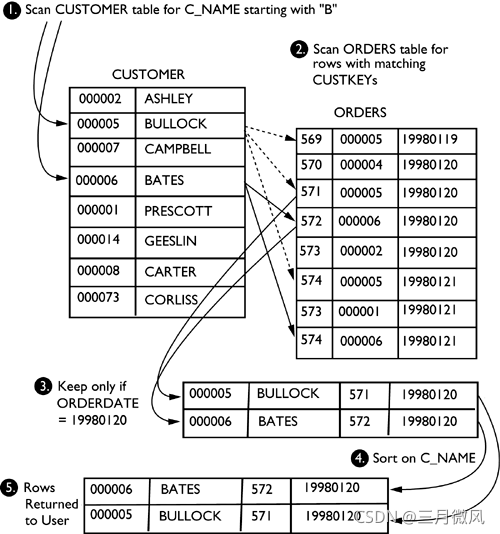
- 子查询
- before 5.6:
lazy: rewrite to exists
poor performance - from 5.6:(MariaDB 5.3)
semi‐join
- before 5.6:
tbs@localhost:[(none)]>show variables like 'optimizer_switch'\G
*************************** 1. row ***************************
Variable_name: optimizer_switch
Value: index_merge=on,index_merge_union=on,index_merge_sort_union=on,
index_merge_intersection=on,engine_condition_pushdown=on,
index_condition_pushdown=on,mrr=on,mrr_cost_based=on,
block_nested_loop=on,batched_key_access=off,materialization=on,
semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,
subquery_materialization_cost_based=on,use_index_extensions=on,
condition_fanout_filter=on,derived_merge=on,prefer_ordering_index=on
1 row in set (0.00 sec)
SELECT o_custkey FROM orders
WHERE o_custkey IN
( SELECT c_custkey FROM customer
WHERE c_acctbal < ‐500 );
select `dbt3`.`orders`.`o_custkey` AS `o_custkey` from
`dbt3`.`customer` join `dbt3`.`orders` where
((`dbt3`.`orders`.`o_custkey` = `dbt3`.`customer`.`c_custkey`)
and (`dbt3`.`customer`.`c_acctbal` < ‐(500)))


SELECT * FROM part
WHERE p_partkey IN
( SELECT l_partkey FROM lineitem
WHERE l_shipdate BETWEEN '1997‐01‐01' AND '1997‐02‐01' )
ORDER BY p_retailprice DESC LIMIT 10;

2.1 JOIN语法
-- 语法1
SELECT … FROM
a,b
WHERE a.x = b.x
-- 语法2
SELECT … FROM a
INNER JOIN b
on a.x = b.x
-- 语法3
SELECT … FROM a
JOIN b
on a.x = b.x
Q:上述这些语法是否有区别?
A:没有任何区别
Q:哪个性能更好?
A:没有任何区别
A:好吧,如果要认真算的话,那么3最好,因为字节数最少
Q:那为什么需要不同的语法?
A:ANSI SQL 89、ANSI SQL 92语法标准
A:ANSI 92标准开始支持OUTER JOIN
A:INNER JOIN可以省略INNER关键字
2.2 JOIN算法
- nested_loop join
- simple nested‐loop join
- index nested‐loop join
- block nested‐loop join
- classic hash join
- Only support in MariaDB
- bached key access join
- from MySQL 5.6
- from MariaDB 5.5
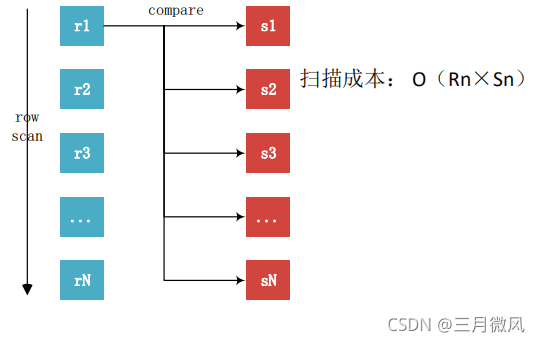
- simple nested_loop join
For each row r in R do
For each row s in S do
If r and s satisfy the join condition
Then output the tuple <r,s>
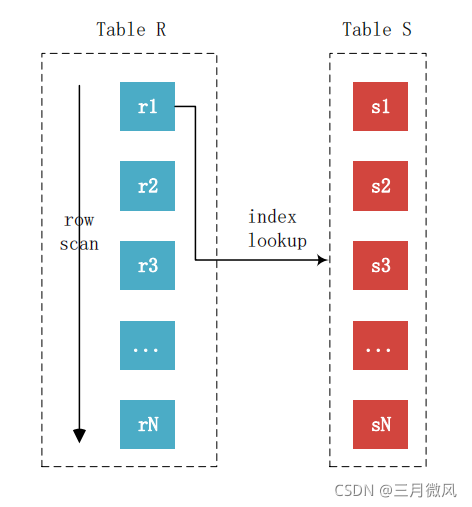
- index nested_loop join
For each row r in R do
lookup r in S index
if found s == r
Then output the tuple <r,s>
扫描成本: O(Rn) 优化器倾向于使用小表做驱动表
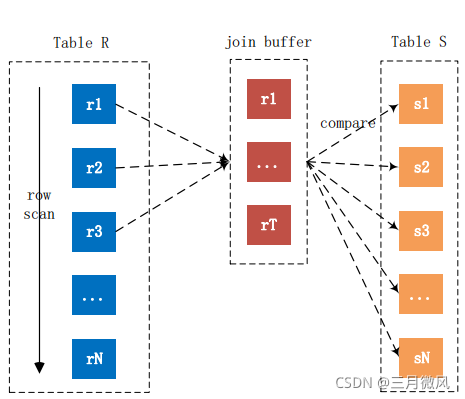
- block nested‐loop join
- 优化simple nested‐loop join
- 减少内部表的扫描次数
For each tuple r in R do
store used columns as p from R in join buffer
For each tuple s in S do
If p and s satisfy the join condition
Then output the tuple <p,s>
系统变量join_buffer_size决定了Join Buffer的大小,Join Buffer可被用于联接是ALL,index,range的类型Join Buffer只存储需要进行查询操作的相关列数据,而不是整行的记录扫描成本呢?
- classic hash join
- based on block nested loop join
inner table may scan many times - not grace hash join
inner table scan only once
- based on block nested loop join
For each tuple r in R do
store used columns as p from R in join buffer
build hash table according join buffer
for each tuple s in S do
probe hash table
if find
Then output the tuple <p,s>
SET join_cache_level=4+;
SET optimizer_switch='join_cache_hashed=on';
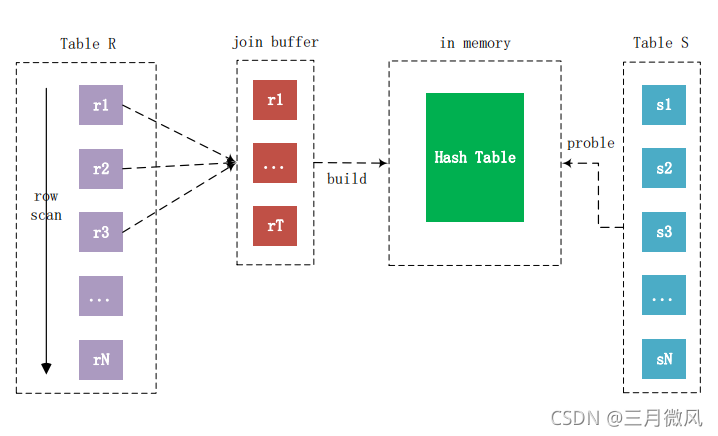
减少外表扫描次数
减少内表比较次数
扫描成本?
SELECT MAX(l_extendedprice) FROM orders, lineitem
WHERE
o_orderdate BETWEEN '1995‐01‐01' AND '1995‐01‐31'
AND l_orderkey=o_orderkey;
MySQL 5.5 125.3sec

MariaDB 5.3 23.104sec ~5x

- batched key access join
- not enabled by default
- optimize random I/O
For each tuple r in R do
store used columns as p from R in join buffer
For each tuple s in S do
If p and s satisfy the join condition
use mrr inter face to sort row Id
Then output the tuple <p,s>
mysql> SET optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';
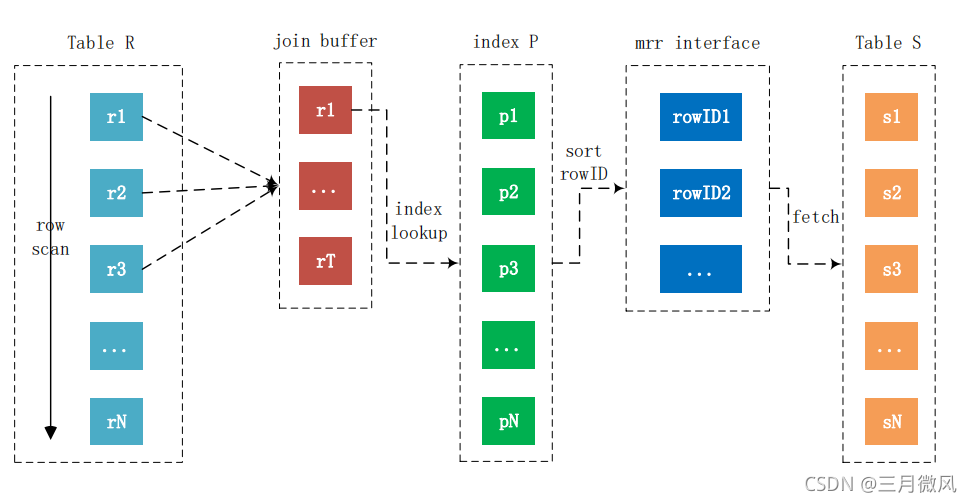
2.3 JOIN经典问题
2.3.1 行号问题
2.3.2 子查询
SELECT emp_no,dept_no,
(SELECT COUNT(1) FROM dept_emp t2
WHERE t1.emp_no<=t2.emp_no) AS row_num
FROM dept_emp t1;

2.3.3 CROSS JOIN
SELECT emp_no,dept_no,@a:=@a+1 AS row_num
FROM dept_emp,(SELECT @a:=0 ) t;

2.3.4 实现类似Oracle的rank()函数
SET @prev_value = NULL;
SET @rank_count = 0;
SELECT id, rank_column, CASE
WHEN @prev_value = rank_column THEN @rank_count
WHEN @prev_value := rank_column THEN @rank_count := @rank_count + 1
END AS rank
FROM rank_table
ORDER BY rank_column
+‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐+
| id | rank_column | rank |
+‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐+
| 1 | 10 | 1 |
| 2 | 20 | 2 |
| 3 | 30 | 3 |
| 4 | 30 | 3 |
| 5 | 30 | 3 |
| 6 | 40 | 4 |
| 7 | 50 | 5 |
| 8 | 50 | 5 |
| 9 | 50 | 5 |
+‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐ ‐‐+‐‐‐‐‐‐+
3. 软硬件设置
3.1 内存
3.1.1 NUMA
- Non‐Uniform Memory Access
- 非一致存储访问结构
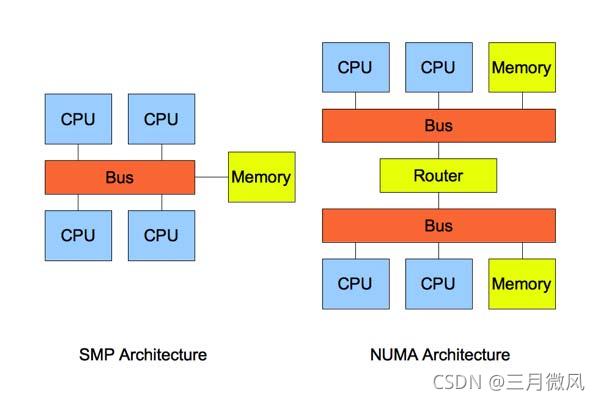
3.1.2 NUMA的内存分配策略有四种:
- default:总是在本地节点分配
- bind:强制分配到指定节点上
- interleave:在所有节点或者指定的节点上交织分配
- preferred:在指定节点上分配,失败则在其他节点上分配
- 单实例MySQL
- 考虑关闭NUMA特性
BIOS中关闭
内存启动关闭numa=off
MySQL启动时关闭
- 考虑关闭NUMA特性
- 多实例MySQL
- 通过NUMA绑定到指定CPU
kernel /vmlinuz‐2.6.32‐220.el6.x86_64 ro
root=/dev/mapper/VolGroup‐root rd_NO_LUKS
LANG=en_US.UTF‐8 rd_LVM_LV=VolGroup/root rd_NO_MD
quiet SYSFONT=latarcyrheb‐sun16 rhgb crashkernel=auto
rd_LVM_LV=VolGroup/swap rhgb crashkernel=auto quiet
KEYBOARDTYPE=pc KEYTABLE=us rd_NO_DM numa=off
numactl ‐‐interleave=all mysqld &
numactl –hardware
numactl –cpubind=0 –localalloc
echo "vm.swappiness = 0" >>/etc/sysctl.conf
3.2 网卡
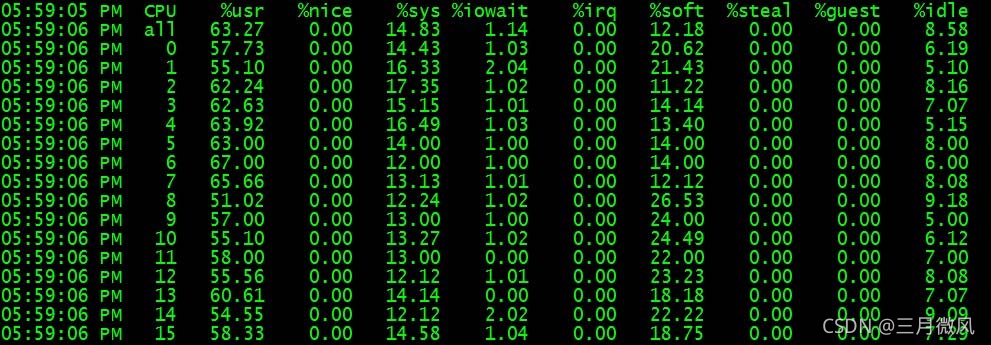
3.2.1 网卡软中断
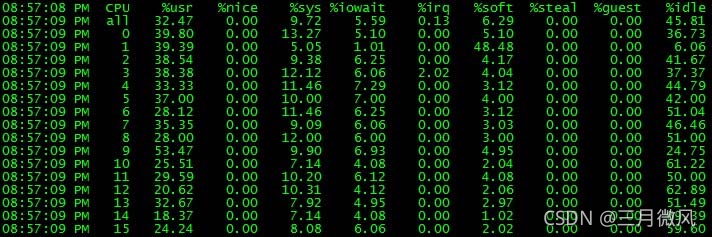
- 解决方案
- 启用网卡多队列
set_irq_affinity.sh
service irqbalance stop
- 启用网卡多队列
#./set_irq_affinity.sh 0 eth0
#./set_irq_affinity.sh 8 eth1
3.3 RAID卡

3.3.1 BBU
- Battery Backup Unit
- 非低端RAID卡都带BBU
- 需要电池保证写入的可靠性
- 电池有充放电时间
3.3.2 RAID卡缓存
- Write Backup
- Write Through
- 写缓存并非默认开启
查看电量百分比
[root@test_raid ~]# megacli ‐AdpBbuCmd ‐GetBbuStatus ‐aALL |grep "Relative State of Charge"
Relative State of Charge: 100 %
查看充电状态
[root@test_raid ~]# megacli ‐AdpBbuCmd ‐GetBbuStatus ‐aALL |grep "Charger Status"
Charger Status: Complete
查看缓存策略
[root@test_raid ~]# megacli ‐LDGetProp ‐Cache ‐LALL ‐a0
Adapter 0‐VD 0(target id: 0): Cache Policy:WriteBack, ReadAdaptive, Direct, No Write Cache if bad BBU
缓存策略
WT (Write through)
WB (Write back)
NORA (No read ahead)
RA (Read ahead)
ADRA (Adaptive read ahead)
Cached
Direct
‐RW|RO|Blocked|RemoveBlocked | WT|WB|ForcedWB [‐Immediate]
|RA|NORA | DsblP | Cached|Direct | ‐EnDskCache|DisDskCache |
CachedBadBBU|NoCachedBadBBU
‐Lx|‐L0,1,2|‐Lall ‐aN|‐a0,1,2|‐aALL
[root@test_raid ~]# megacli ‐LDSetProp WT ‐L0 ‐a0
Set Write Policy to WriteThrough on Adapter 0, VD 0 (target id: 0) success
3.4 SSD


3.4.1 SSD与传统磁盘差别
SSD优点
- 纯电设备
- 由Flash Memory组成
- 没有读写磁头
- IOPS高 • 50000+ IOPS
- 读写速度非对称
性能指标
- RPM (rotations per minute)
- 5400
- 7200
- 10000
- 15000
- SATA(串口硬盘)
- 120 ~ 150 IOPS
- SAS
- 150 ~ 200 IOPS
性能下降
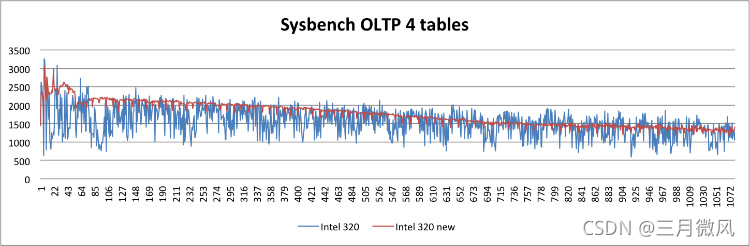
莫名的性能波动
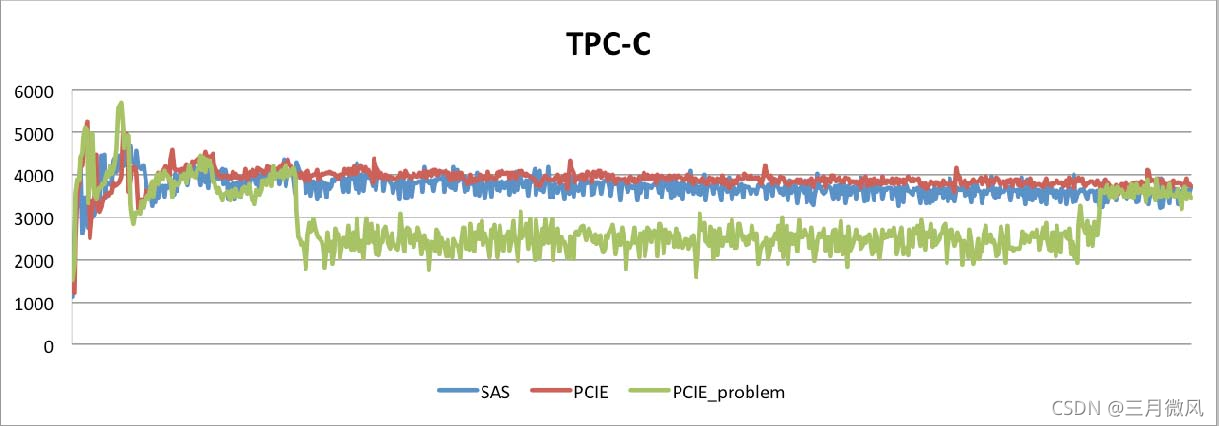
SSD与数据库优化
- 磁盘调度算法设置为:deadline或者noop
- InnoDB存储引擎参数设置
- innodb_flush_neighbors=0
- innodb_log_file_size=4G
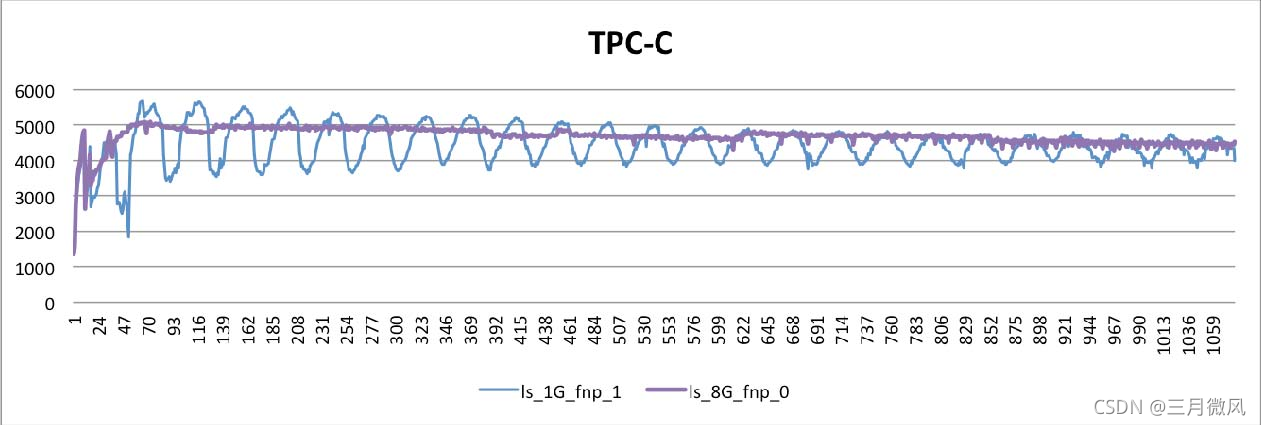
结论:
- 性能更平稳
- 可以有大约15%的性能提升
SSD选择
• PCIE or SATA/SAS
• SATA/SAS益于安装与升级
• SATA/SAS与PCIE的性能差距逐渐缩小
• PCIE的性能很少有应用可以完全使用
• 优先选择SATA/SAS接口的SSD
SSD品牌推荐
• Intel
• FusionIO
• 宝存
选购时注意“寿命”指标
• Intel 3500:275T
• Intel 3700:每天全量写10次,保证5年
4. 文件系统与操作系统
4.1 文件系统
- 推荐xfs/ext4
- noatime
- nobarrier
4.2 操作系统
- 推荐Linux操作系统
- 关闭swap
- 磁盘调度算法
mount ‐o noatime,nobarrier /dev/sdb1 /data
















 4866
4866











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











