







新世纪以来,人工智能作为一个非常热门话题,一直收到大众的广泛的关注。从一开始的图像的分类,检测,到人脸的识别,到视频分析分类,到事件的监测,到基于图片的文本生成,到AI自动写小说,AI 自动作画,AI 超分,再到在围棋上战胜人类的AlphaGo,AlphaZero 每一次都霸占着版面的头条。
最近一段时间,另外一个基于人工智能技术的产品ChatGPT再一次火爆的国内外,以至于现在听不懂什么叫ChatGPT 都感觉自己和时代有点落伍了,那ChatGPT 究竟是什么,它能做什么,它是怎么来的,它会对于我们产生什么样的深远的影响,有人把它作为新的一轮技术革命的代表,它究竟有这么神奇吗?那我们今天就浅谈一下,顺便提出一下对于现有人工智能(AI)的一些思考.
下面的内容将从ChatGPT的前世,ChatGPT的今生,ChatGPT的一些算法细节和Chat的未来应用和一些思考来展开,由于每增加一个数学公式就会让读者的兴趣减50%,所以算法细节就不再这里过多的赘述,有需要了解同学可以多多点赞,后续在看看要不要开专题详细说明.
ChatGPT 的前世
在介绍真正的ChatGPT 前,我想先介绍一下一个通用的概念叫做自然语言处理(NLP),自然语言处理技术是一种计算机科学中的一种常见的技术,主要用于处理文字,提取文字中的包含的语义信息,实现计算机识别感知文字的任务,这种技术应用的常见的任务包括,文本情感的感知,文本翻译,文本的自动生成,问答系统,文字总结之类的语言相关的一系列工作。
之前常见的NLP技术大致会分为两类,一类用于做文本相关的预处理,包括中文的分词,断句,文字转换成词向量(类似于将模拟信号数字化的采样)等技术,一类是直接和最终任务相关的技术,包括情感的分类,文字生成等。在大规模的语言模型(LLM)出现前,一般来说对应不同的任务会训练出不同的模型来进行推理。

添加图片注释,不超过 140 字(可选)
从人类历史发展规律来看,利用机器来替代人力参与到社会的劳动的事件贯穿着人类发展的这个过程,并推动着人类逐步走过了两次工业革命(蒸汽动力的使用和电力的使用)。作为第三次的技术革命的核心,计算机技术和在它之上扩展出的互联网技术以及海量的计算机算力,也正在逐步的改变着我们的每个人的日常的生活方式。近年来,针对如何让计算机变得更加智能这个问题,应运而生的人工智能技术,成为当下最时髦的一个话题,并诞生了不少想象级别的产品。所对应的技术也逐渐从基于规则的驱动的专家模型,走向了基于大数据驱动的深度学习模型框架。而chatGPT 就是这样一种基于海量数据训练后的人工智能的深度学习模型。
假如将 ChatGPT 拆开我们发现,它是由两个部分组成的:
一个部分是Chat 表示它的用途是用来聊天的,本质上是一个问答机器人,主要的功能适用于语言文字的问答工作,这个功能本质上来说并不是一个特别新的功能,是一个很久之前就有的概念。相信大家也或多或少在实际的情况下和这类的机器人客服打过交道,之前的机器人客服可以感觉的出大部分的情况下给人的感觉上是基于一些规则在完成类似的任务,比较类似于你问我答,而且答案一般比较死板,给人的感觉上比较像机器人,给人的感觉不是太友好,导致使用的面比较窄。
另外一个关键词是GPT表征的是实际用到的模型的情况。GPT的全称是生成型预训练变换模型,是一个做自然语言处理相关任务的一个大型的模型,最新的GPT-3模型(可以理解为第三代)的参数量高达1750亿,需要利用28500个CPU 和 10000块GPU 在45TB规模的数据集的语料上面(绝大部分是英文,占比超过90%)训练而来,在目前绝大多数的语言类任务中实现了对于人类的超越,类似于在大规模的图片分类的任务上实现了对于人的超越。下面会对于这个GPT 模型进行一个详细的介绍。

添加图片注释,不超过 140 字(可选)
GPT 全称为Generative Pre-trained Transformer, 从名字和实现的技术中可以提炼出下面的四个关键词,这四个关键词就能对于这个模型可以有一个较为全面的认识。
Generative: 生成式模型。 我们一般常见的图像的检测或者分类模型,输入大多是一张图片,输出都是一堆分类的置信度或者是检测框宽高置信度之类的值,这些值是无法直接理解的,需要通过后处理,引入事先的标签信息,才能知道最终的结果是什么。而 生成式的模型在自然语言处理任务中输入的是一段文字,输出也是一段文字,这样的输入输出模式对于正常的使用者来说是一种最为自然的模式,同时也具备了最强的普适性,所以在现有的自然语言处理中得到的了广泛的应用。从最新的模型来看,这种方式也是自然语言处理任务中最常见的一种训练范式
Pre-Trained: 统一的预训练模型,当然这个不是GPT的首创,但是GPT 中也应用了这样的范式。所谓的统一预训练模型,就是把之前说的文本情感的感知,文本翻译,文本的自动生成,问答系统,文字总结之类的语言相关的等一系列工作统一为一个生成模型,比如对于情感感知分类的模型本来的输出可能是0 表示负向情感 1 表示正向情感, 2 表示中性的情感,统一为一个预训练模型就把这个输出改为三种类型的文本(正向情感,负向情感,中性情感)来将分类问题转换为文本生成问题,其他类似的功能也可以用类似的方式来进行统一。最终利用海量的数据和统一预训练的模型的方式,大规模的语言模型(LLM)在各个分支的任务上都达到了和超越了目前各个任务最佳水平,从侧面验证了这个训练方式的有效性
Transformer: 上一个阶段最火的一个模型框架,是一种由google提出的基于self-attention的网络基本结构,相比于之前的类似LSTM, RNN 等网络结构,该网络结构具有可以高并发推理和表达能力超强等特点,这个介绍里面的专业词有点多,其实这个结构单拎出来都可以讲好久,如果大家有兴趣,在最后的算法细节的介绍中,会有更加详细的描述
Unsupervised : 无监督学习,目前的GPT-3 模型采用的训练的数据集的数量大概在45TB左右,这样的数据量级想要完成高质量的标注几乎完全是一个不可能的任务,毕竟作为图片数据集的标杆的ImageNet 标注的周期也要好几年,量级也就在百万这个量级,所以GPT模型的训练采用的是无监督的生成式的方法,具体的训练过程会在下一页介绍。受益于超大的数据量和超大的模型和in-context learning 等技术的加持,整体的效果还是达到了不错的效果。
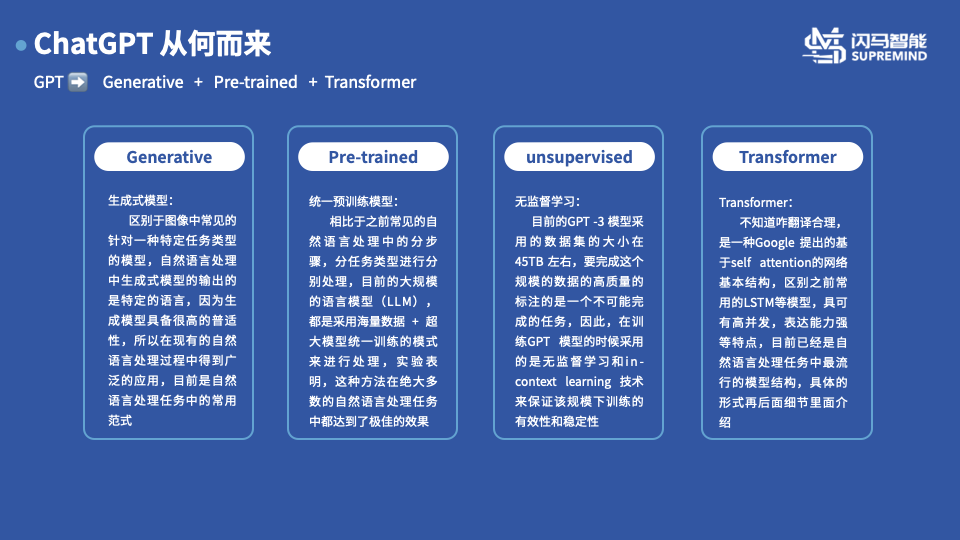
添加图片注释,不超过 140 字(可选)
现在开始介绍GPT 是如何进行训练的 :
例如,我们有如上图所示的一条这样的语料,是关于机器人三定律中的第二条的文本语料。总所周知,所有的模型训练目前基于梯度下降的算法,所谓的梯度下降都类似于我们学习知识,一开始我们不知道1+1 等于几,我们随便说一个答案比如10 ,那么老师就会告诉我们这个数字太大了,所以我们下次报的数字就是比这个小,比如8 ,然后逐步逐步的收敛到这个最终正确的结果。 那么我们针对这样的语料如何涉及问题(input)和标签(label)呢,训练GPT的时候采用的方式就特别的鸡蛋,直接使用的利用前面的一段话作为输入(input),以下一个单词作为标签(label) ,这样我们的训练过程就可以如动画所示,每次利用模型得到一个推理的单词,然后计算推理单词和标签之间的相似度作为损失进行回传,然后更新模型,直到最终得到和我们预设的标签一致。
推理的时候,我们就把整段的代码输入到模型中,然后利用高达96层的翻译器(Decoder)进行翻译,然后生成我们想要的结果,有人可能会好奇,为啥每次的结果会不太一样呢,因为在模型的输入中会包含一个随机的初始状态的种子,来保证整个问题的随机性。那有人会问那训练的时候这个怎么办呢,训练的时候一般会固定这个初始状态,或者根据一定的规则来生成这个。
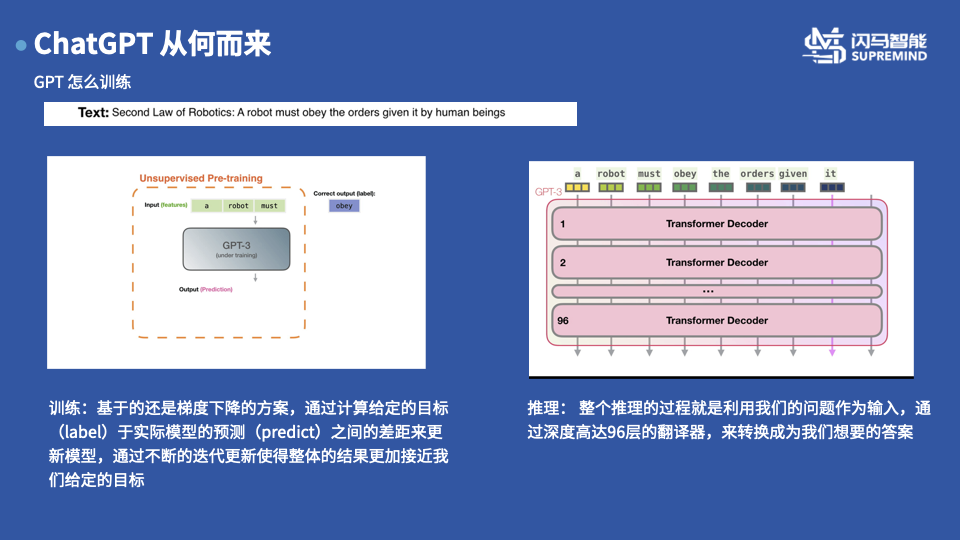
添加图片注释,不超过 140 字(可选)
另外一个在自然语言处理领域比较著名的模型是(BERT)。这个模型和刚才介绍的GPT 大致的情况是类似,就会有几个异同点:
相同点来看,都使用了相同的模型结构(Transformer)架构,同时都使用用生成模型来统一自然语言处理过程,同时模型很大,训练的数据量也很大,
不同的点上来看,GPT 使用的是在名字里面没有B 因此使用的更加简单粗暴的单向模型,单向模型的好处是,训练的时候很简单,不存在后续的信息对于结果的影响而BERT 里面的B 是单词Bidirectional 的 首字母,表示使用的是一个更加具有表达能力的双向Transfomer 的结构,这个结构其实也是有它的道理,比如在一些语言中,倒装啊啥的其实是比较依赖于后续向的结果,因此BERT选用的是双向的结构,但是这个结构在训练中会有一个麻烦就是理论上后续的一些词汇会影响模型训练的效果,因此在训练的时候会利用一个掩膜(mask)来掩盖掉后续的信息,防止产生信息的泄漏
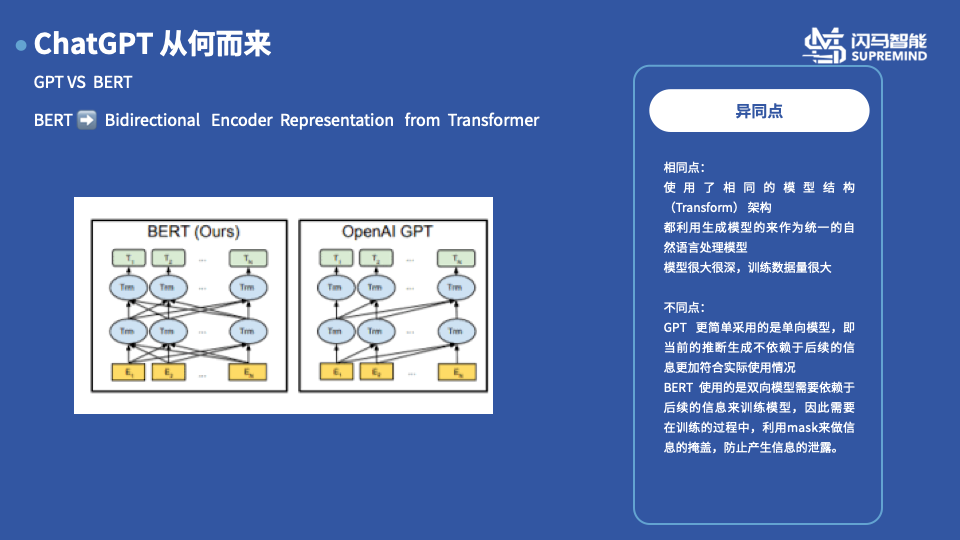
添加图片注释,不超过 140 字(可选)
最终GPT以及和它类似的BERT 等大规模语言模型框架完成了自然语言任务的的统一。统一带来的意义主要是在自然语言处理的各个任务中,不再需要针对各个任务单独的考虑模型设计等问题,都可以利用这样的统一范式来进行处理。同时由于模型具备的超级强悍的表达能力,即使对于一些较为复杂的任务,可以利用一些简单的引导就可以完成各种类型的工作,比如帮忙写代码,调试代码,生成报告,写ppt啥,并且在很多的任务中完全不需要引导也可以实现很好的效果,这种就被称为Zero-shot Generalization。
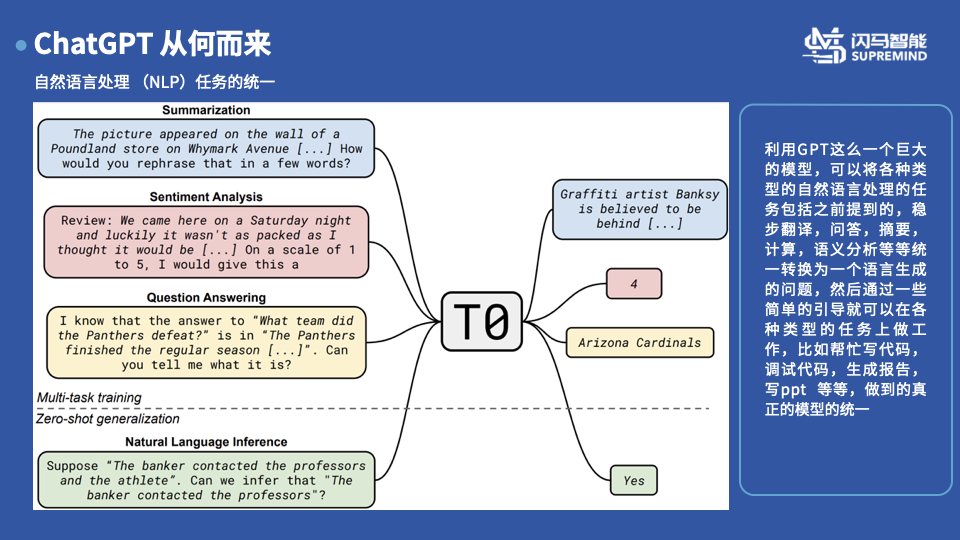
添加图片注释,不超过 140 字(可选)
2. ChatGPT 的今生今世
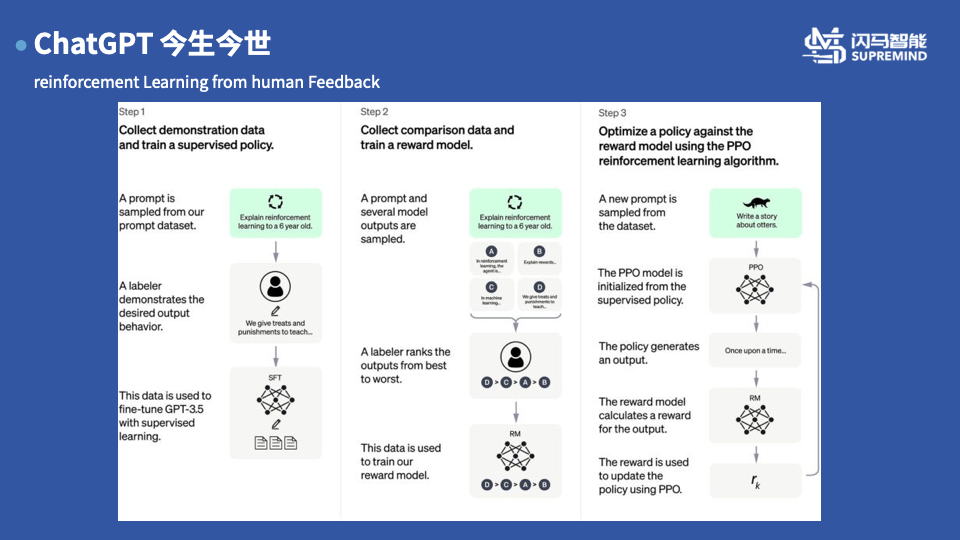
介绍完了GPT 我们来介绍真正的主角ChatGPT。之前提到的GPT-3模型虽然在很多的任务中表现出来特别牛的效果,同时在一些领域包括写代码,理解shell 脚本含义等任务下有着出乎意料的效果,但是在作为对话机器人的领域,总感觉和人类的感官差异较大,感觉不是特别的智能,OpenAI的专家经过分析发现这类缺陷主要的原因实现训练GPT 模型的时候没有和人类的行为做对齐导致的,因此后续设计了一款和人类对齐的InstructGPT ,其中利用了一种称之为Reinforcement Learning from Human Feadback 简称为RLHF 的技术使得模型的输出更加的贴近于实际的人类的效果。

添加图片注释,不超过 140 字(可选)
在关于InstructGPT的论文中,详细介绍了openAI 是具体是如何利用人类的反馈来提升的模型的主要来说,整个步骤分为三个部分
-
有监督的学习: openai从网上大家调用API的问题中通过大数据的去重和人为的筛选,精选了22000条样例进行了人工的标定,人工的标定的时候尽量的试图去理解样例中的隐含的含义和给出尽量公正正确的答案,然后利用这些进行一个有监督的学习,保证模型推理的结果尽量的和这些样本保持一致
-
训练一个奖励模型: 有监督的标注实在成本是不低的,第二步的标注相对于第一步进行了一定的简化,利用多个模型的多次推理可以得到不同的生成结果,对于这些生成结果进行相互的比较排序,根据这样的排序得到的结果,我们可以利用rank-loss 这类的技术训练出一个reward model 用来对于每一条结果进行打分,用来区分结果的好坏,这里的数据量其实不大也就几万条
-
利用强化学习更新策略模型:最后有了奖励模型,大概率大家都可以猜到会使用强化学习的方法,以奖励模型给出的分数作为评价,第三步利用强化学习中的ppo算法(强化学习可是openai 最擅长的)利用全部的数据集进行学习,最终使得模型学习到一种策略,用来生成出我们reward model 打分更高的结果,这样就实现我们想把模型输出和人对齐的想法
第二步和第三步在实际的操作过程中是可以不断的循环迭代,即利用第二步的结果训练出第三步的策略模型,然后在用第三步的策略模型生成出跟多的样本进行排序的打标训练新的reward model 然后在用来训练第三步的策略模型,如此循环往复,最终可以得到一个和我们期望的输出更加的一致的模型达到对齐的效果
在训练的过程中还是有一些小细节的,在训练中发现如果仅仅依赖于人类标定的那些样本进行调整的话,其实会导致在一些标准的数据集上的效果会出现下降,因此在训练的时候加入了最为原始的GPT-3 的结果输出一起计算最终的损失,这样的会可以保证在标注数据集上的结果。同时训练后发现,利用这样的训练模型在一个参数量减少了100倍的模型也能达到不错的效果,最终上线的chatGPT的模型的版本大概是参数量在10亿级别的模型
添加图片注释,不超过 140 字(可选)
那么ChatGPT的效果究竟如何呢,其实在知乎上也给出不少很有意思的例子:
比如:
模拟terminal
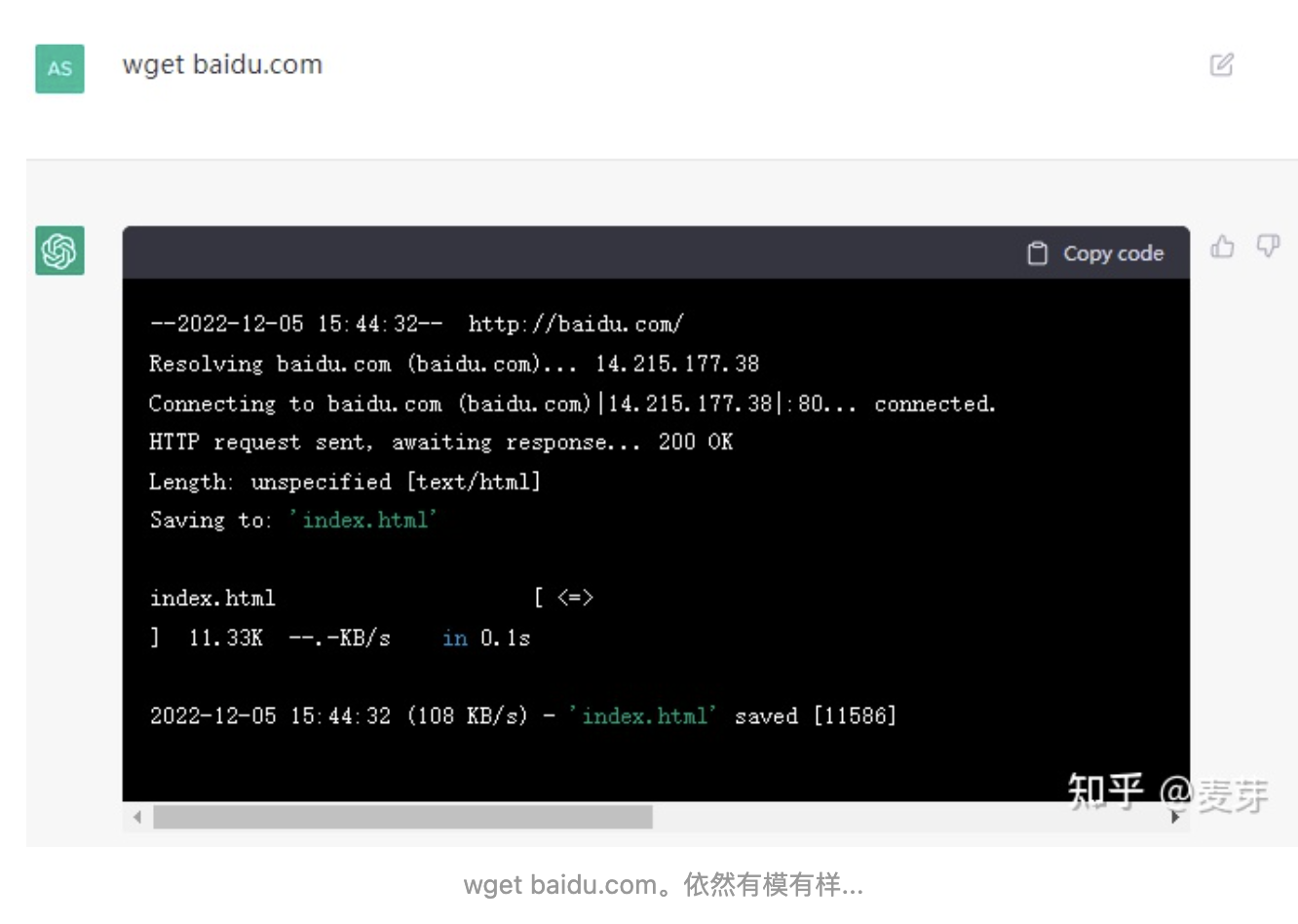
添加图片注释,不超过 140 字(可选)
做一些语言任务:

添加图片注释,不超过 140 字(可选)
教你做菜 :

添加图片注释,不超过 140 字(可选)
自己给自己找一个例子
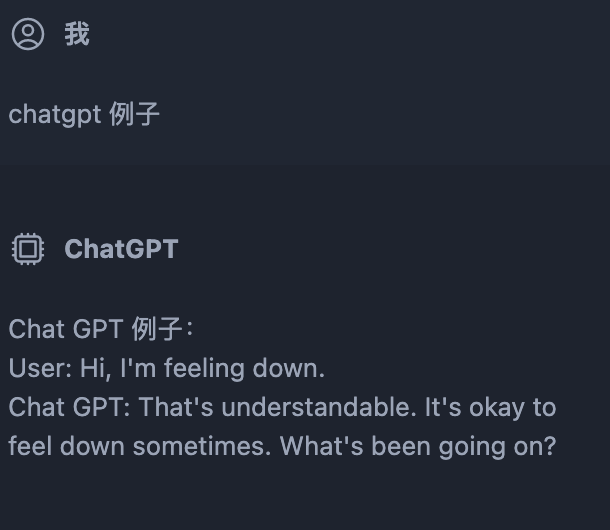
添加图片注释,不超过 140 字(可选)
当然也会有一些一本正经的胡说八道:
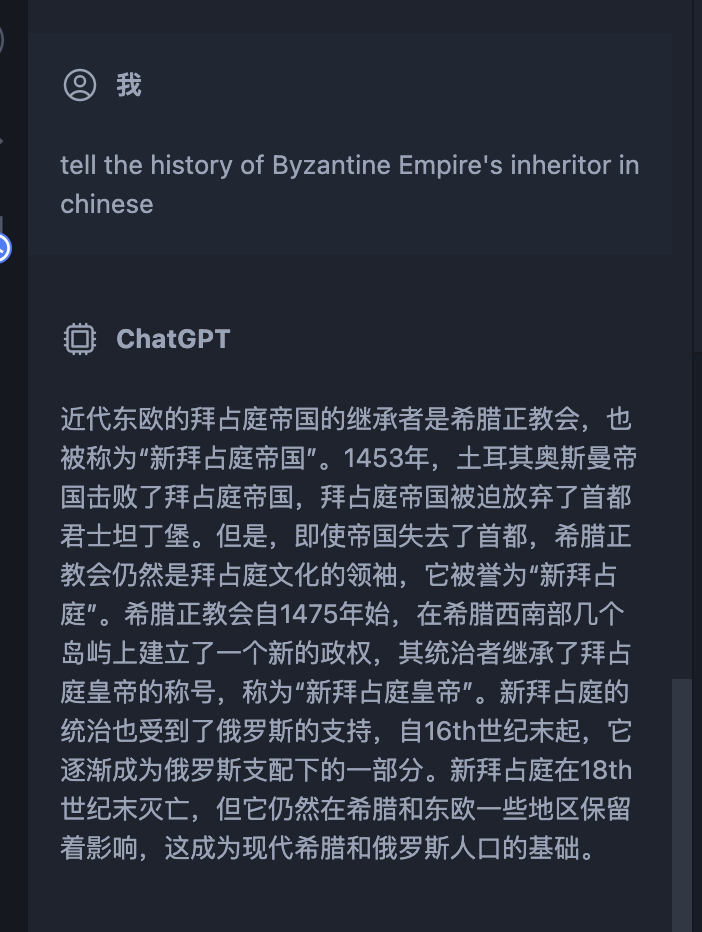
添加图片注释,不超过 140 字(可选)
大家可以自行感受一下这个效果,个人觉得这样的效果还是非常令人惊喜的,特别是得知模型的语料基本上都是英文的前提下
ChatGPT 给我带来的一些思考:
最后想谈一谈ChatGPT 给我打来的一些思考
首先从一本正经的胡说八道让我联想起了一个问题,关于什么知识的问题。从小我们收到的教育就其实就是在默认老师或者父母交给我们的就是正确的知识,知识我们理解就是一种关于生活现象的经验的总结,长大后我们会从各种书籍里面获得知识,学习到一些道理,但是一个人的专业的知识领域总是有限的,直到遇到了这么一个ChatGPT的怪物。它似乎懂得所有的东西,从写代码到教做菜到教你打游戏似乎无所不知,但是很遗憾,真正到了你的专业领域其实你发现和你之前的认知是完全不是一回事,作为能够独立判断的人,其实目前还是比较容易判别或者自己认为比较容易判别这些哪些是对的,哪些是有问题的,但是随着技术的发展呢?或者说不是自己熟悉的领域呢?会不会就被这样的生成的内容误导了呢。
之前在互联网中会有一个概念叫做信息茧房,就是随着搜索推荐技术的革新和更加精准化的推荐,每个人从推荐算法中获得的信息是高度重复,一些app的推荐算法会精准的知道你想看的是什么然后给你推荐相关的内容,这样就导致每个人容易活在自己认为的世界里面。那其实再扩大一些,如果每天都和ChatGPT这样的生成模型交流,是不是会更加加剧这样的现象,毕竟这个模型更加的多变,像一个全知全能的聊天工具,一定会提供你想听到的内容,所以在未来AI 肯定会更加进入我们生活的大浪潮不可改变的情况下,我们该如何鉴别或者说如何重新定义我们所谓的知识,从而不受巨大的信息茧房的影响,能够更加客观全面的看待问题。
此外ChatGPT 在很多使用的时候会让人以为他是一个搜索引擎,是一个代码生成器,是一个代码调试器,是一个terminal,其实根据刚才的介绍,其实它就是一个模型而已,只是生成的内容过于百遍和实际,让人产生了这样那样的错觉。要表现出这样的能力,它肯定是在模型的一些地方存下这些信息,但是这些信息是以怎么样的形式存在的,是如何发挥工作的,这里面的原理性的内容还是需要后续的不断探索
最后关于知识,其实我们小时候的一些知识比如世界上有多少个国家之类的知识,其实在长大的过程中已经发生了变化,世界其实是一个变化的过程,因此知识也需要不断迭代,相比于我们可以不断修改我们的知识,作为模型要做这样的工作就难上了很多,而且训练一个这样的模型,据说OpenAI 花费在1600W 刀,看着也不是能够没事随便训练一个的,那么如何小成本的精准更新也是一个后续的重要问题

添加图片注释,不超过 140 字(可选)
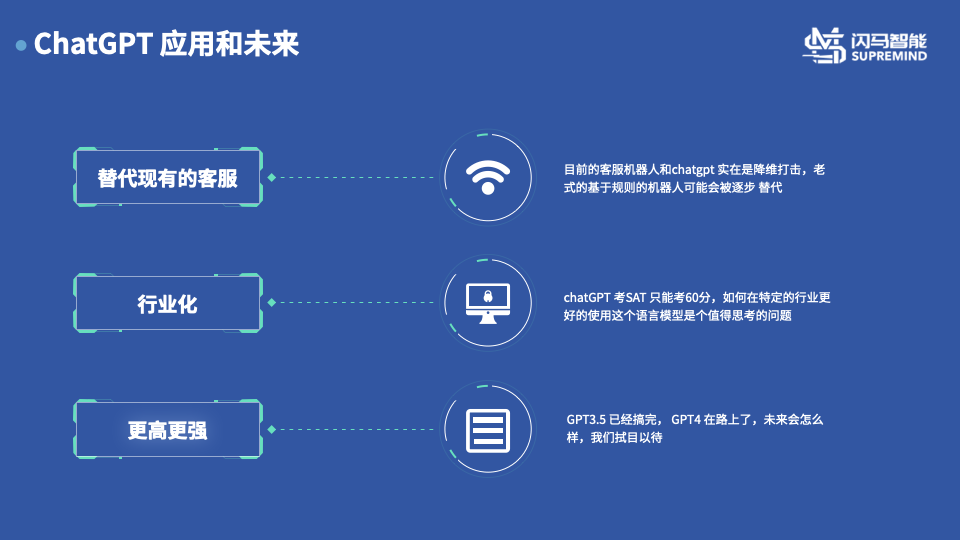
最后我们来展望一下ChatGPT的应用和未来:
首先ChatGPT 对于现有的一些客服机器人绝对是一个很大的冲击,对于 目前的一些基于规则的聊天机器人基本上是这个降维打击,一些更加智能更加符合人类习惯的客服机器人眼见应该是在上线的路上了
其次,ChatGPT 是一个通用的模型,但是在专业领域目前还无法和人类的相比,在未来一定会有人将这个技术和行业做结合做行业化,在行业中发挥这项技术的优势,最终实现真正能在专业领域使用的机器人
最后GPT3.5 已经完成,GPT-4 第四代已经在开发的路上了,以后更高更快更大更强的语言模型会不会再一次给人类带来惊喜,值得我们拭目以待
添加图片注释,不超过 140 字(可选)
简要介绍和一些思考就到这里,如果想了解后续的一些算法细节知识,请多多点赞,如果大家兴趣很高,后面单独更新


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









