






感谢过年的时候的openai 给全世界带来了一份大礼SORA,一直以来的业界都很关心,怎么讲图片的生成能力推广到视频上,openai 就给出了这个问题的答案
Sora: Creating video from textopenai.com/sora
从给出的视频效果来看,达到了sd 推广到视频的高端效果,而且对于一些场景的变换和文字理解的程度也达到了一个全新的高度。
作为一个算法工程师,当然会很好奇他是怎么样实现的,那从给出来的技术报告来看
Video generation models as world simulatorsopenai.com/research/video-generation-models-as-world-simulators#fn-26
更像是一个宣传用的广告,用来告诉大家,随着数据量的增加,Transformer 可以scale 然后会有神奇的效果发生,就是告诉大家,分辨率什么的都不是问题,只要计算量上来了,模型参数上来了,效果就会变得很好。这个很符合openai 最近的大力出奇迹的特性,猜想openai 就是想告诉大家,在绝对的算了和数据面前,技巧没有那么重要咯
从技术文档里面的为数不多的细节,我来斗胆猜想一下具体模型的大概的样子
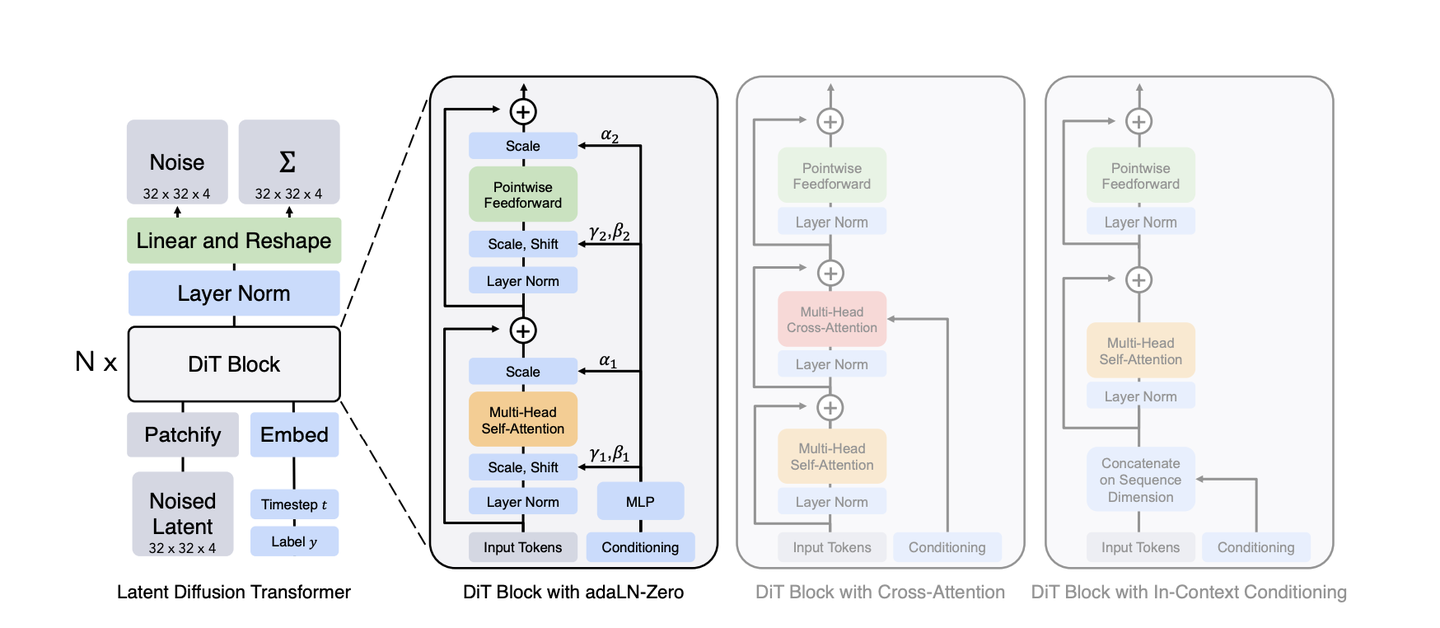
Scalable Diffusion Models with Transformers
整个核心的算法应该就是基于meta 这篇文章中的Dit 的架构,具体细节不好推测。整体的流程是利用一个图像的特征提取器将图像像素的值映射到一个隐空间(latent space),然后在这个空间中利用Transfmer 将各种语言等token 进行融合在进行生成模型的训练
在这个模型基础上sora 可能从几个方面进行了改进:
-
为了支持视频的训练,从时间轴的维度,对于多张的图片进行了重排,技术报告里面称为(Spacetime latent patches)
-
可能利用了类似LLM的 多token 的Transfomer 的进行参数的生成,这样做其实一直都是可以的,但是计算量实在是大的有些吓人,一般在图像中还是用vit的方式更多一些
-
针对不同分辨率和尺寸的图像,sora 应该是用的不同token 长度或者用一些特定的token作为提示词来进行了联合的训练,这样可以极大程度上利用上已有的样本和保证模型的鲁棒性
在这个的外围,其实还需要有一个将视频中的图像映射到隐空间变量的特征提取器和一个最终将隐空间变量转换为像素的生成器,在技术报告中,称为 Video compression network, 在常见的stable- diffusion中,会使用clip 对于这个进行提取,在这里,不负责任的猜测一下这个模型应该用的是VAE(Variational Autoencoders)
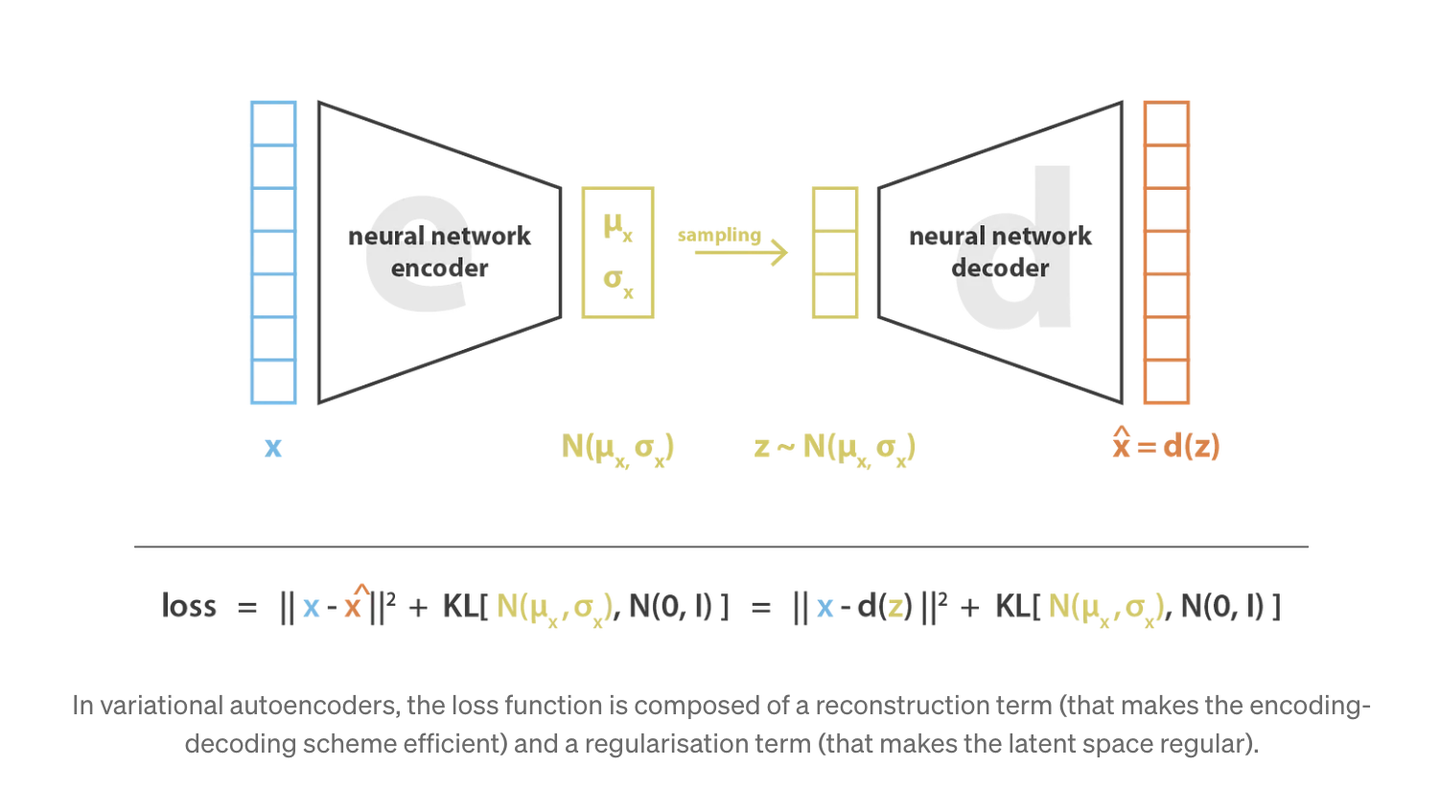
Variational Autoencoders
此外为了提升训练的视频的 prompt 和 视频本身内容的一致性(其实就是保证生成效果的稳定性和收敛性),这里对于视频的图片的caption 其实就是prompt采用和Dalle-3 一样的做法,重新训练了一个好用的标签生成器保证了生成标签的一致性和正确性,(原来的那个从互联网爬下来的标签实在是太差了)
一切就绪之后,再加上高超的训练技巧和调参能力,这个sora 的就诞生了
最后还是感谢一个openai 给大家的送的一份大礼,把人类的技术的前沿又往前推进了一大步,让世界看到了技术能产生的更多的可能
以上都是基于我个人的理解
如果大家有什么想法欢迎讨论哈















 2473
2473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









