







目录
1、先分析目标网址 首页 - 福布斯中国 | Forbes China
写在前面,最近收到了很多小伙伴们的建议,大屏得展示数据如果采用真实数据分析计算,那就更加贴近小伙伴们的实际工作场景,可以很快在工作中应用,所以应小伙伴需求,就诞生了这篇数据可视化+数据分析的【 Forbes全球富豪榜 - 数据可视化大屏解决方案】。
之前小伙伴们建议我出一些视频课程来学习Echarts,这样可以更快上手,所以我就追星赶月的录制了《Echart-0基础入门》系列课程(共14节课) ,希望小伙伴们多多支持。
精彩案例汇总
YYDatav的数据可视化《精彩案例汇总》_YYDataV的博客-CSDN博客
效果展示
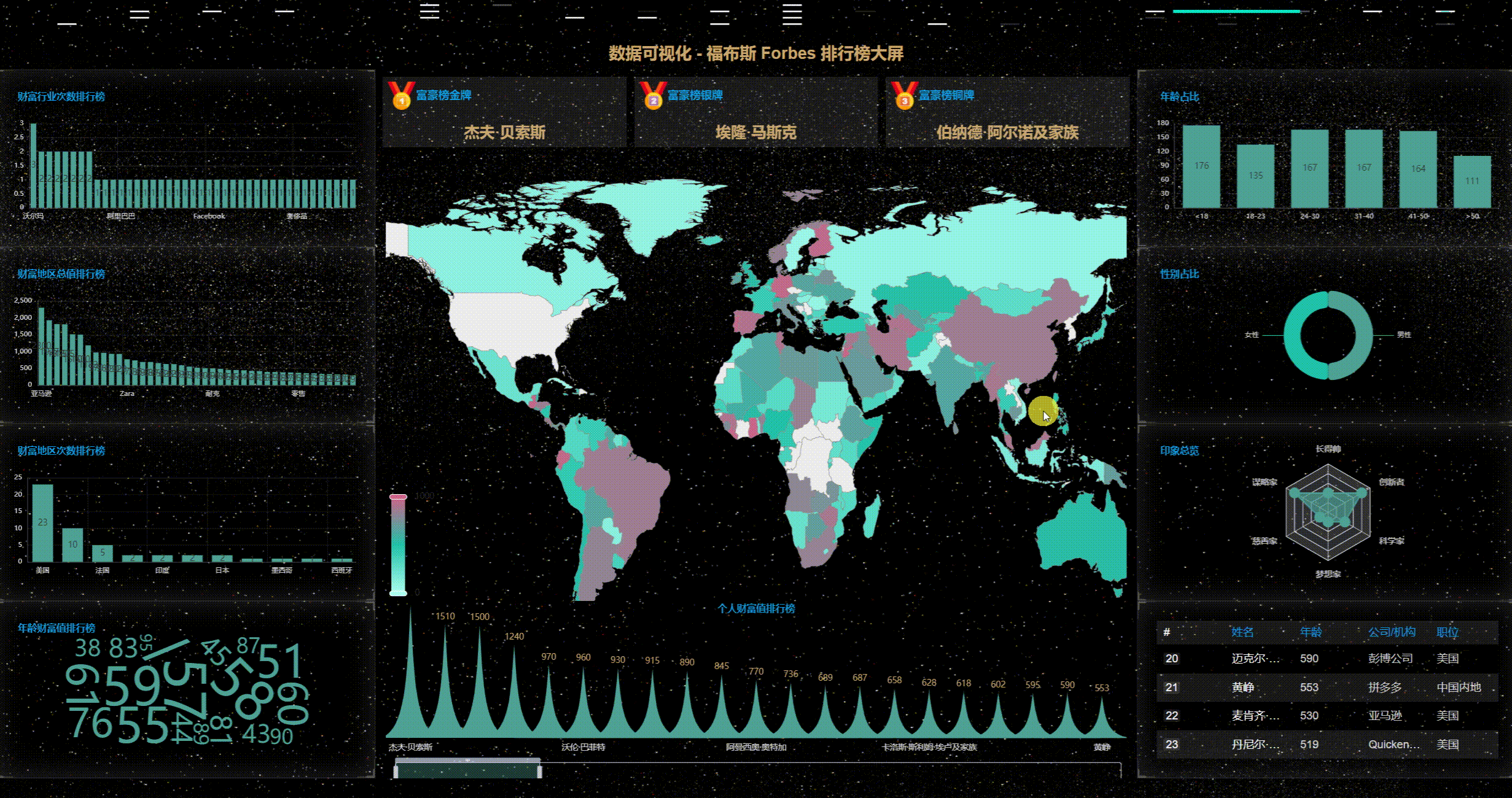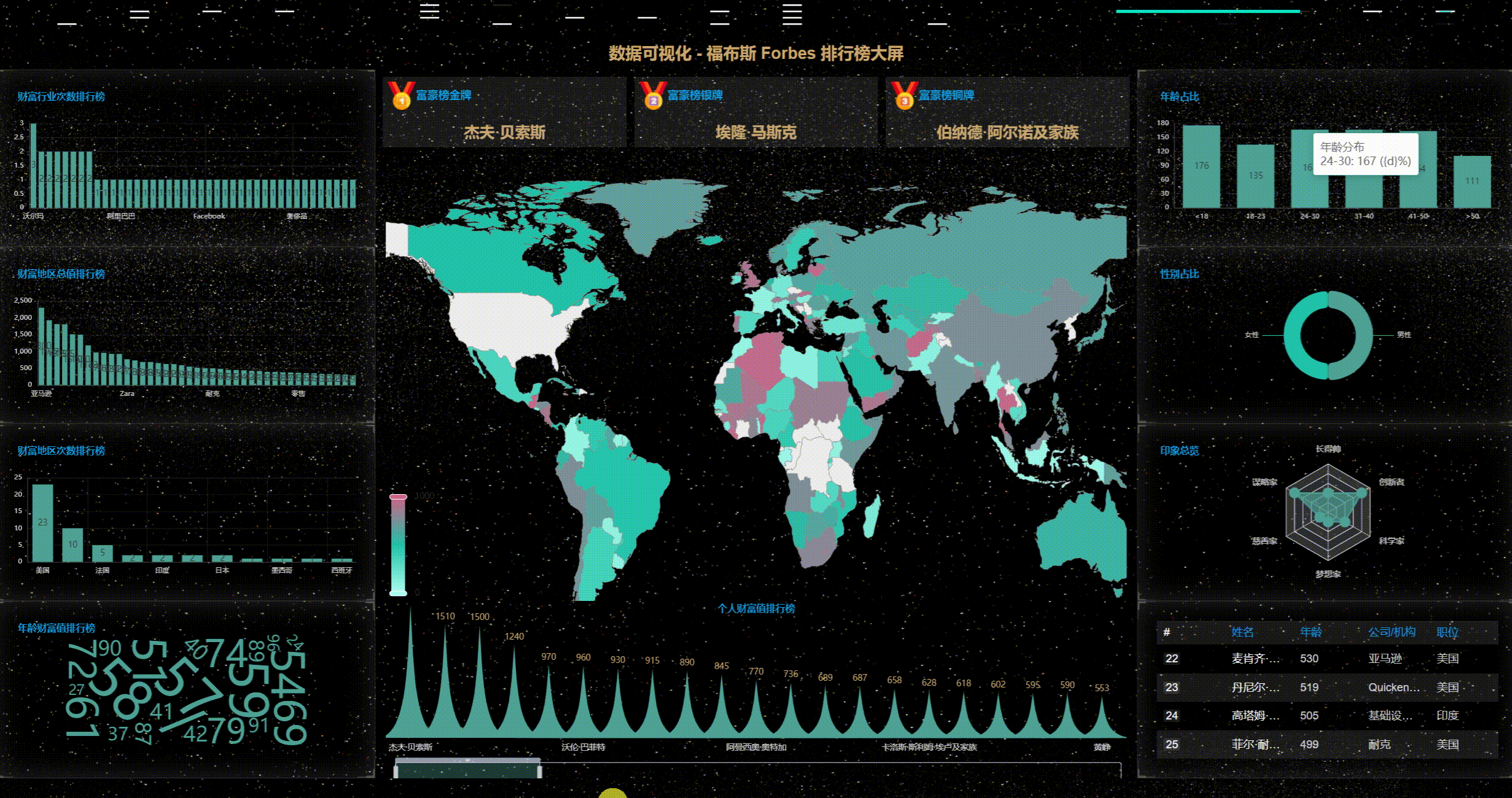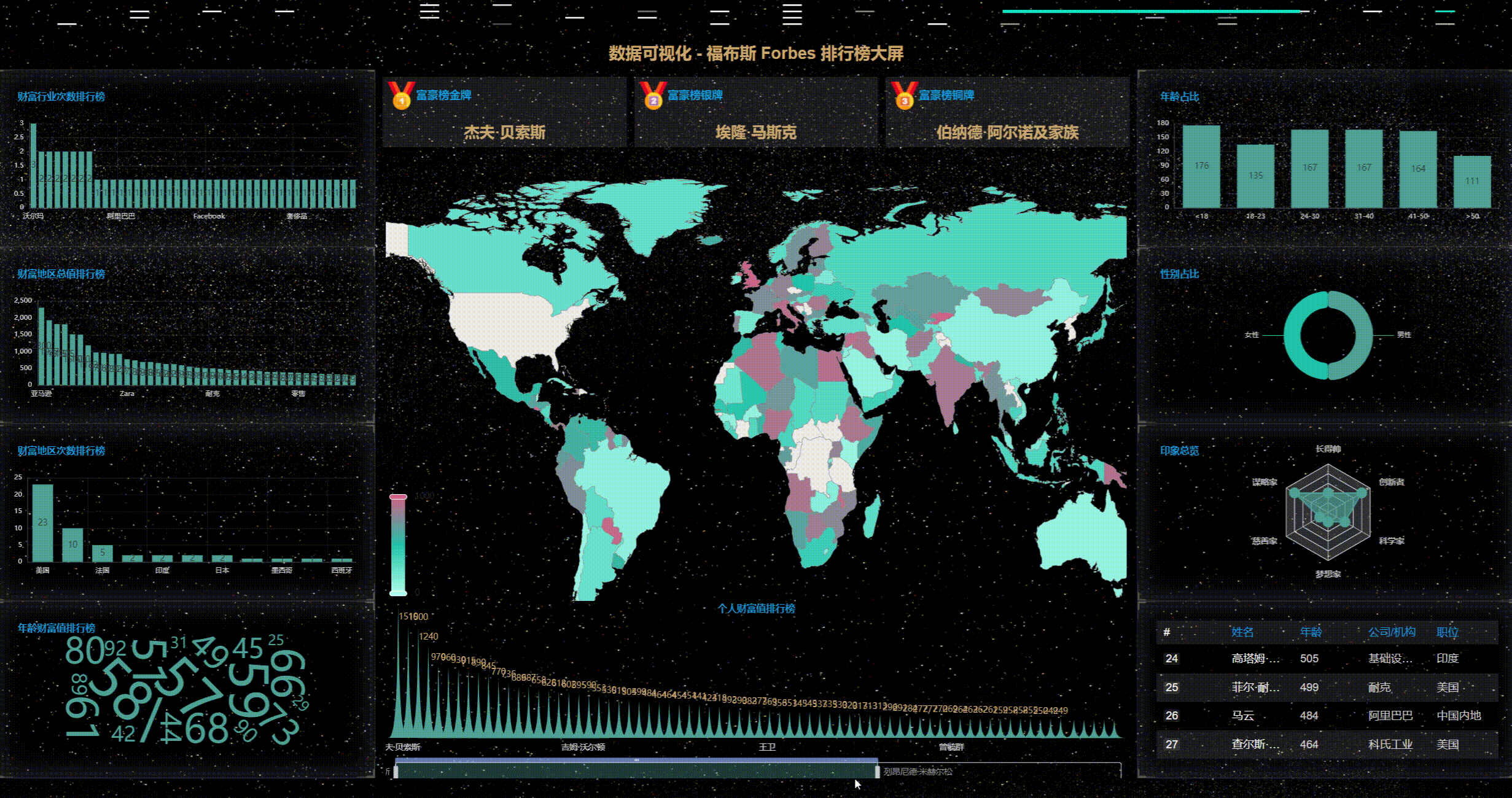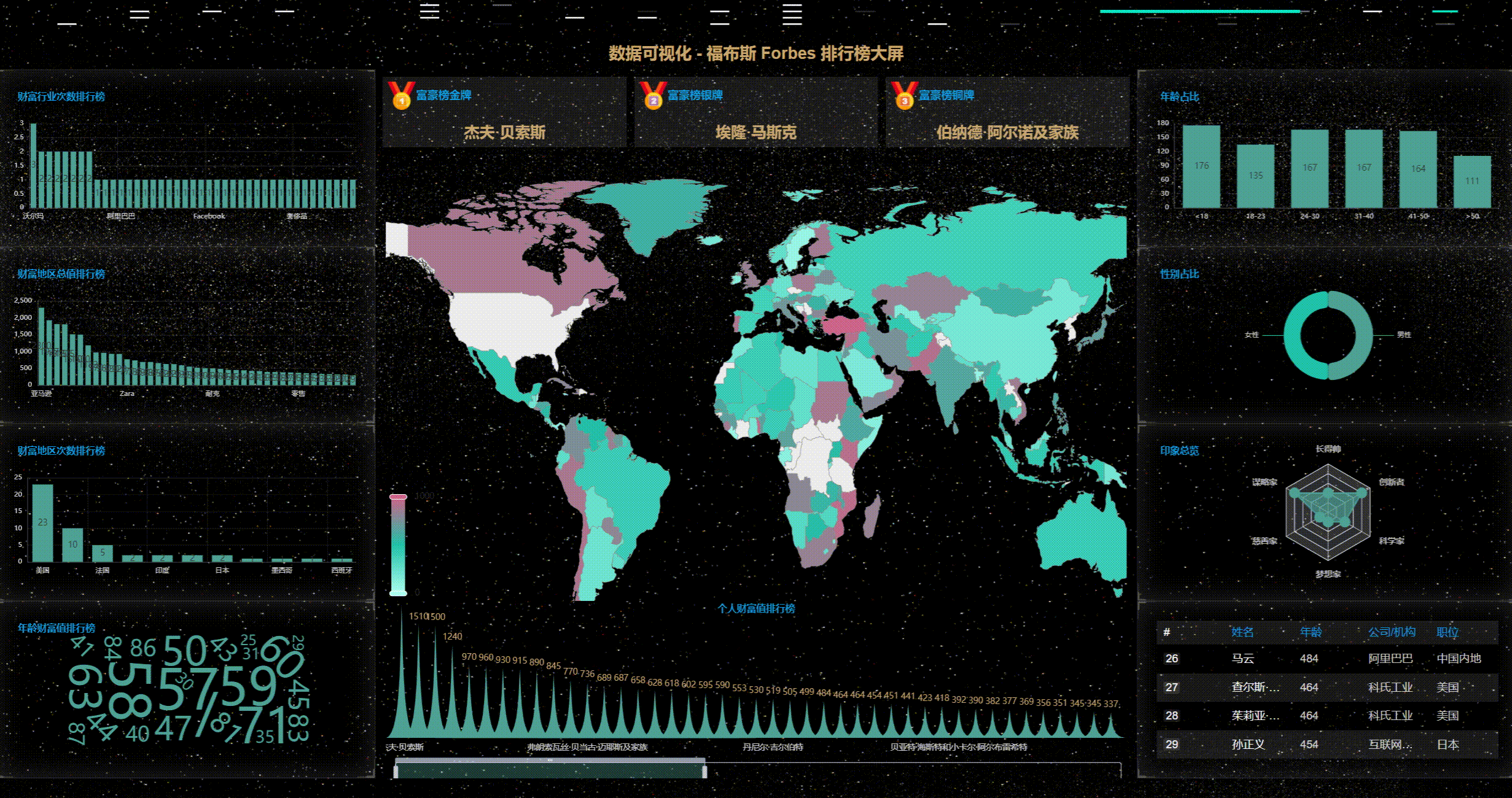
1、首先看动态效果图
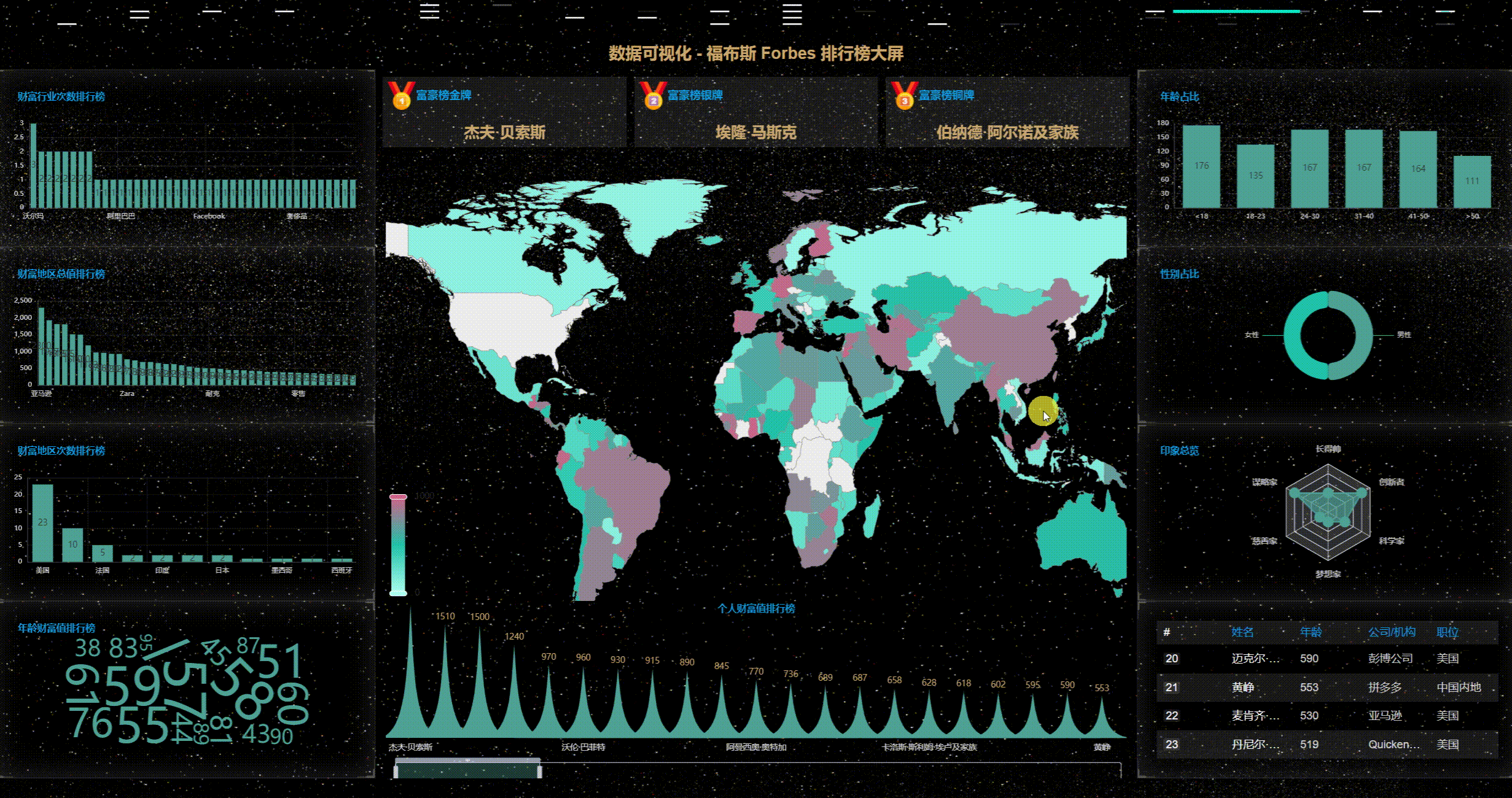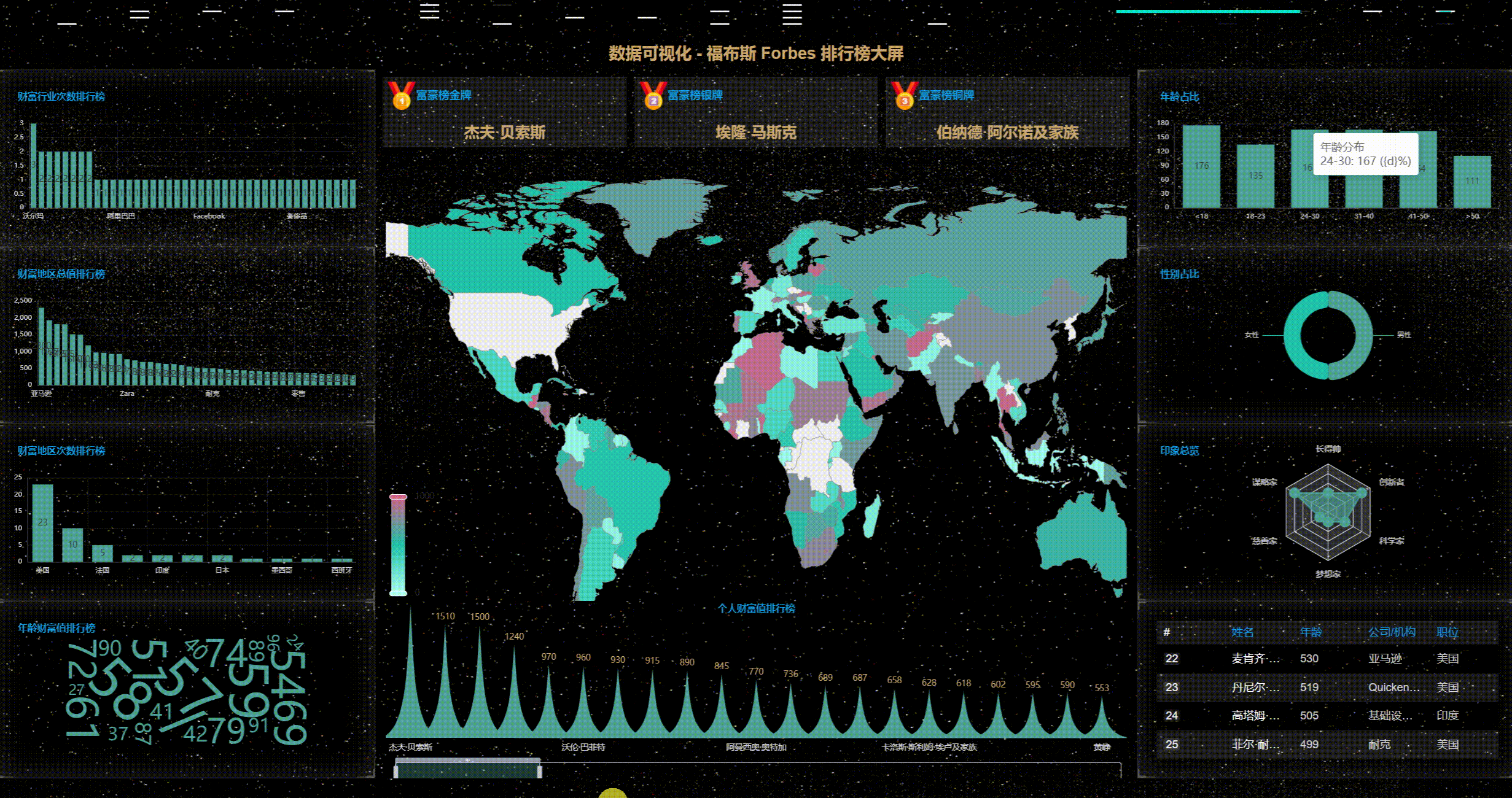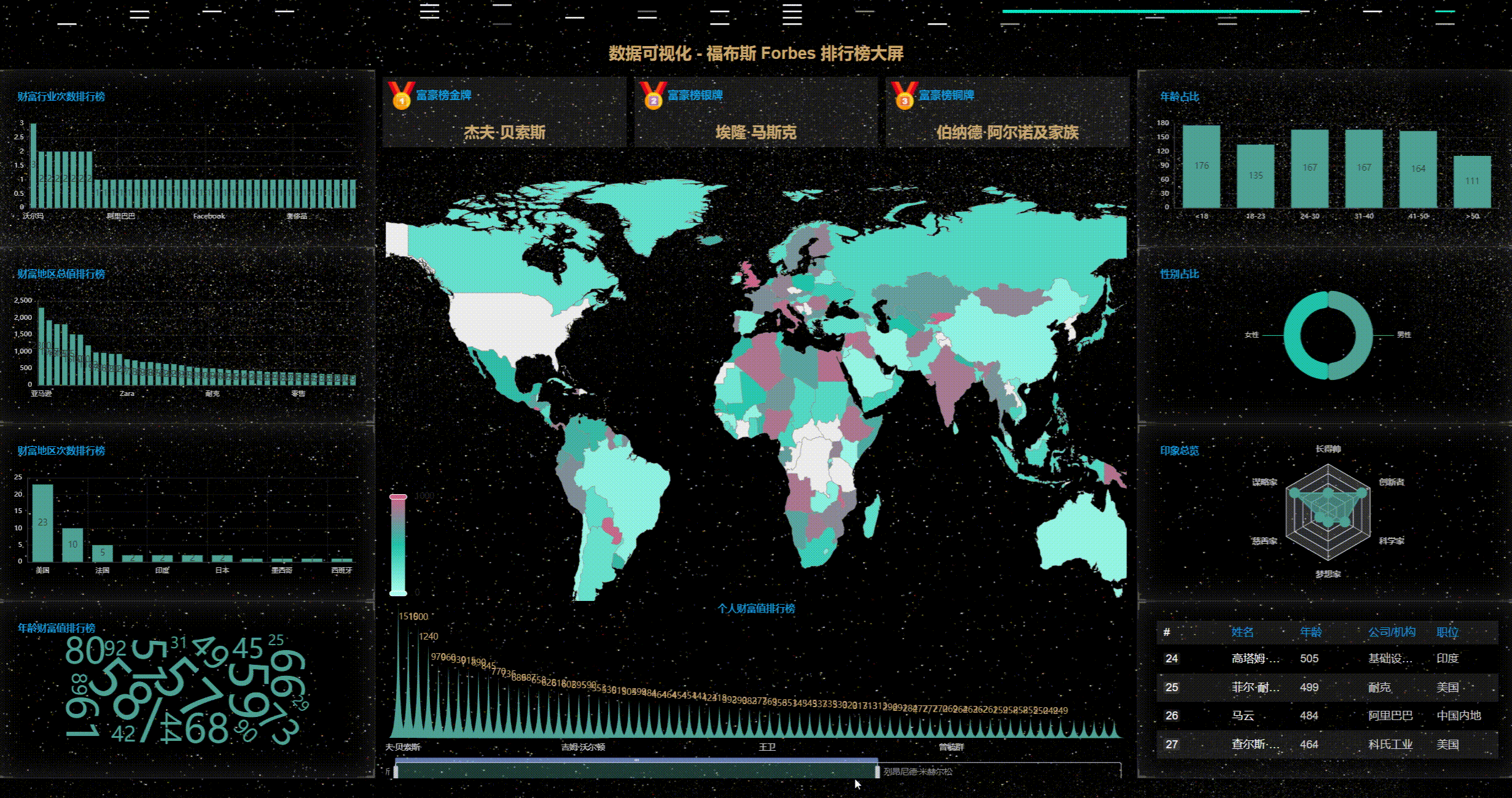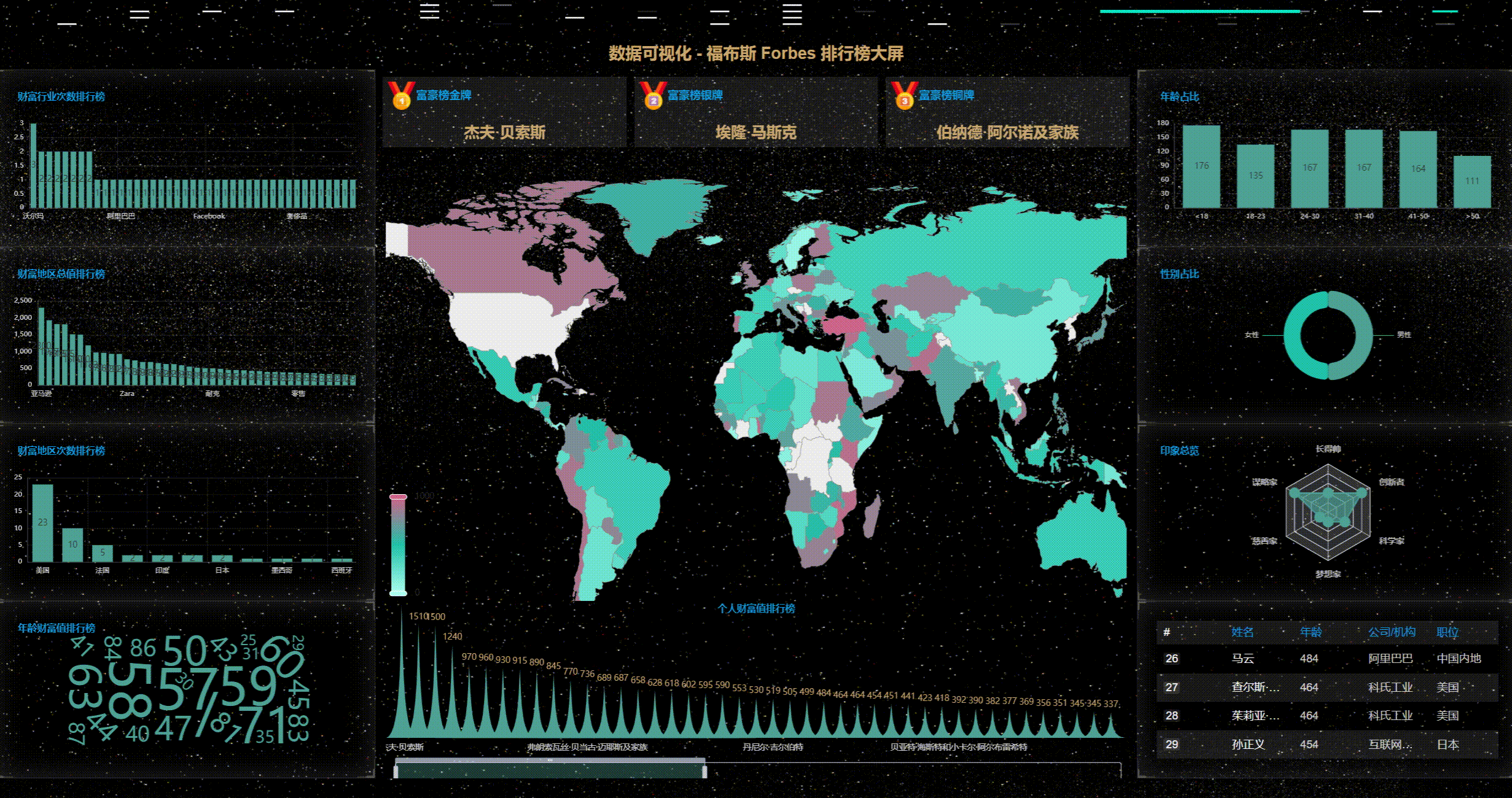
2、丰富的主题样式
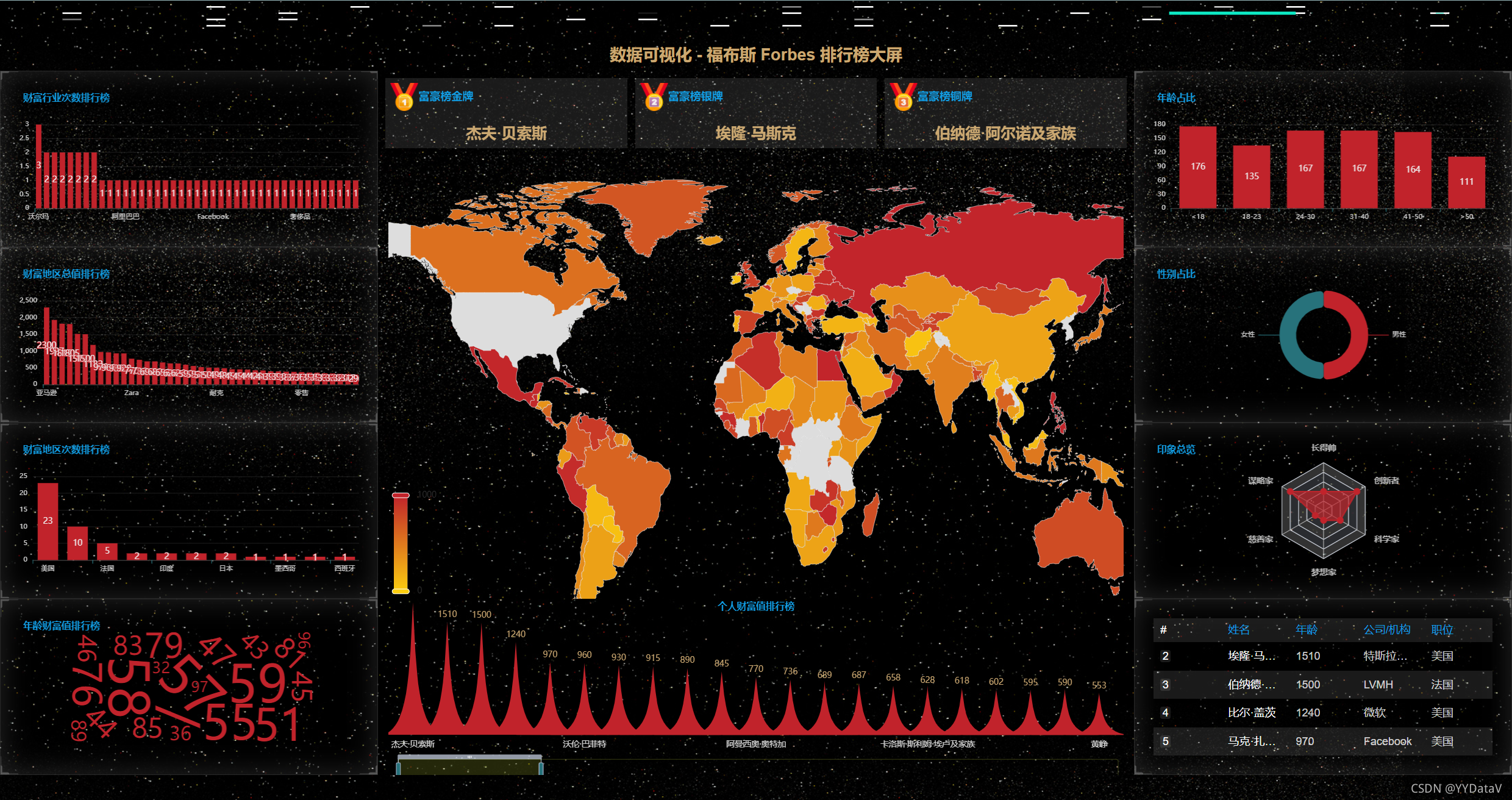
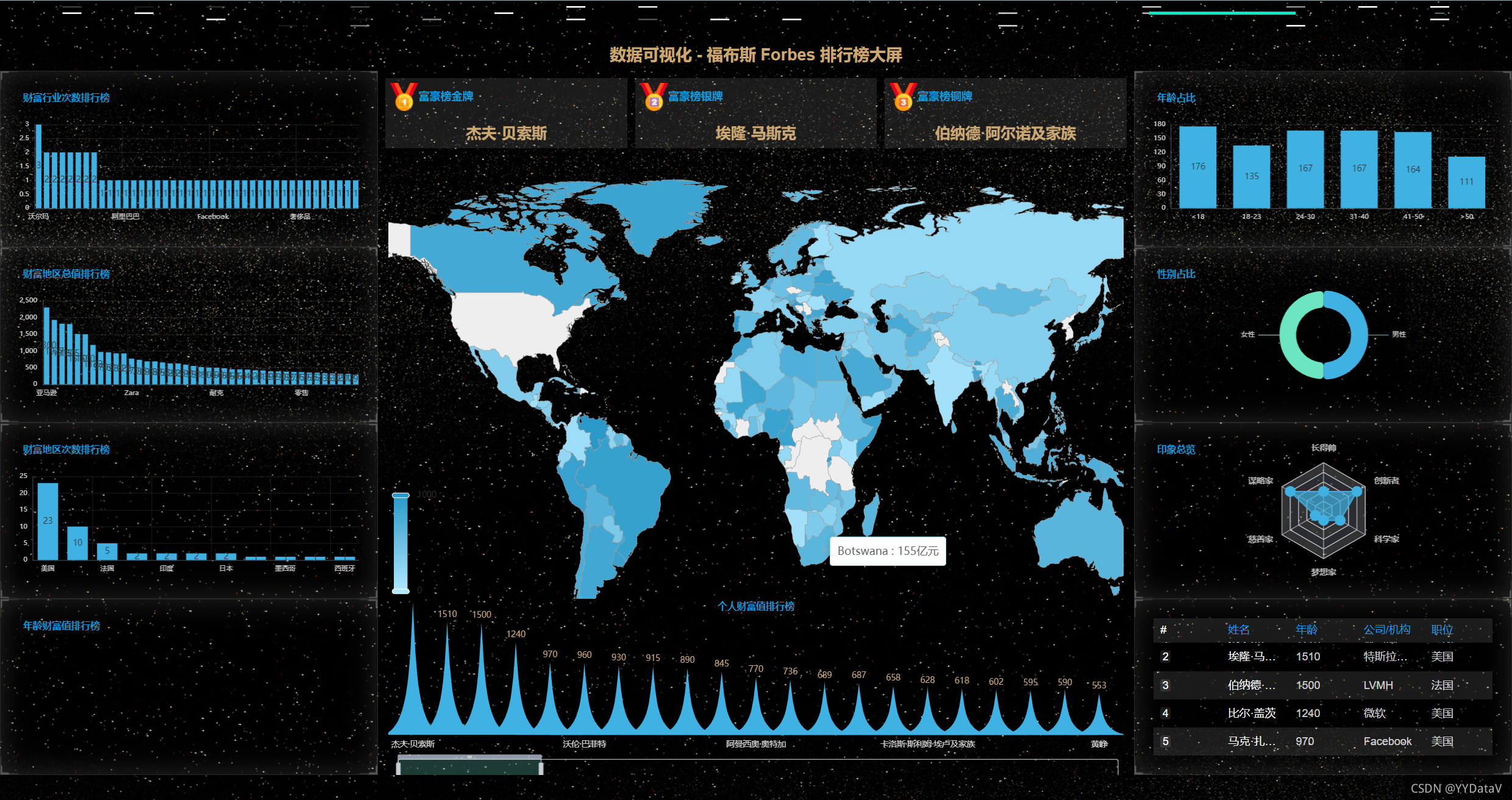

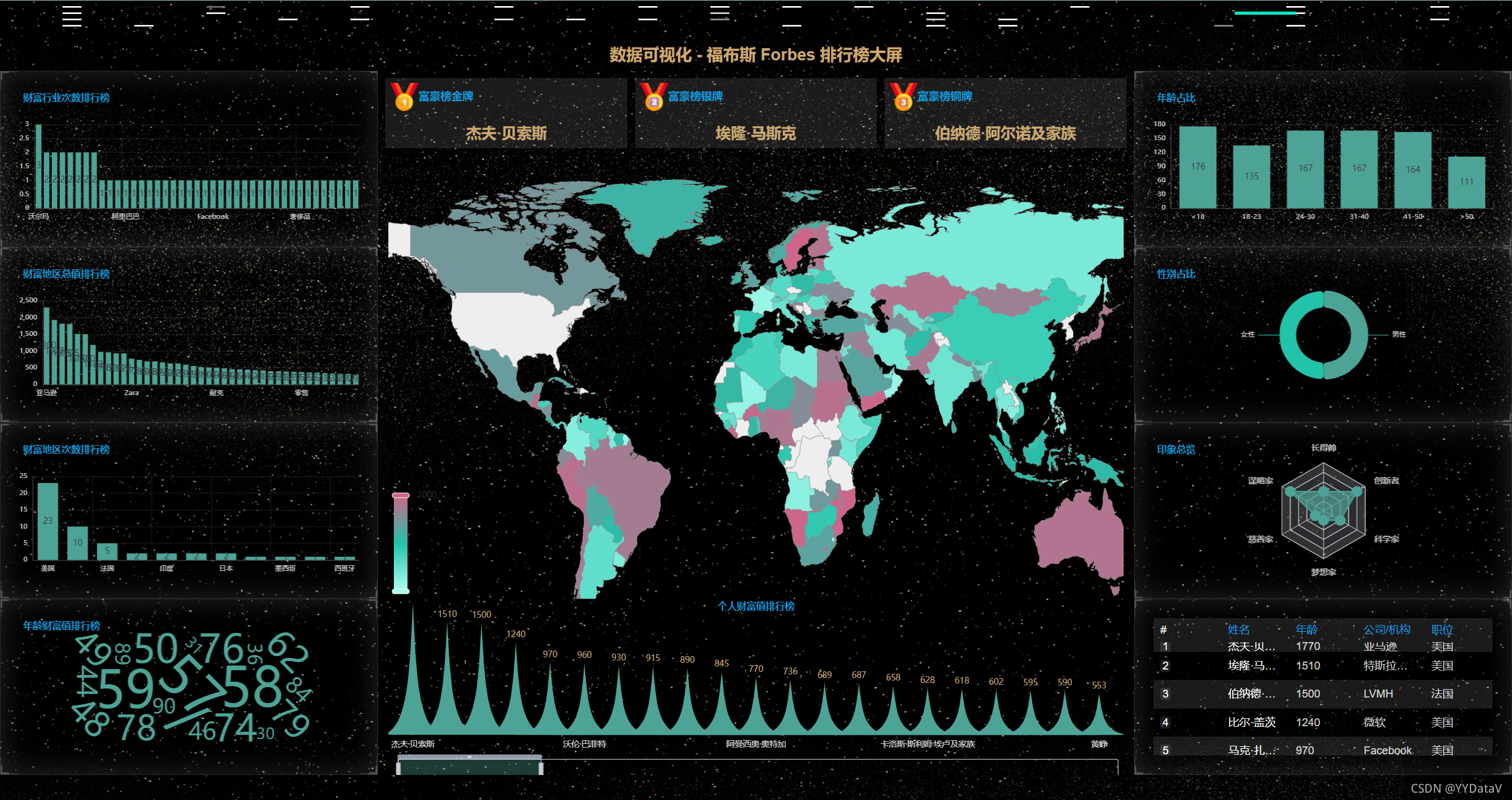
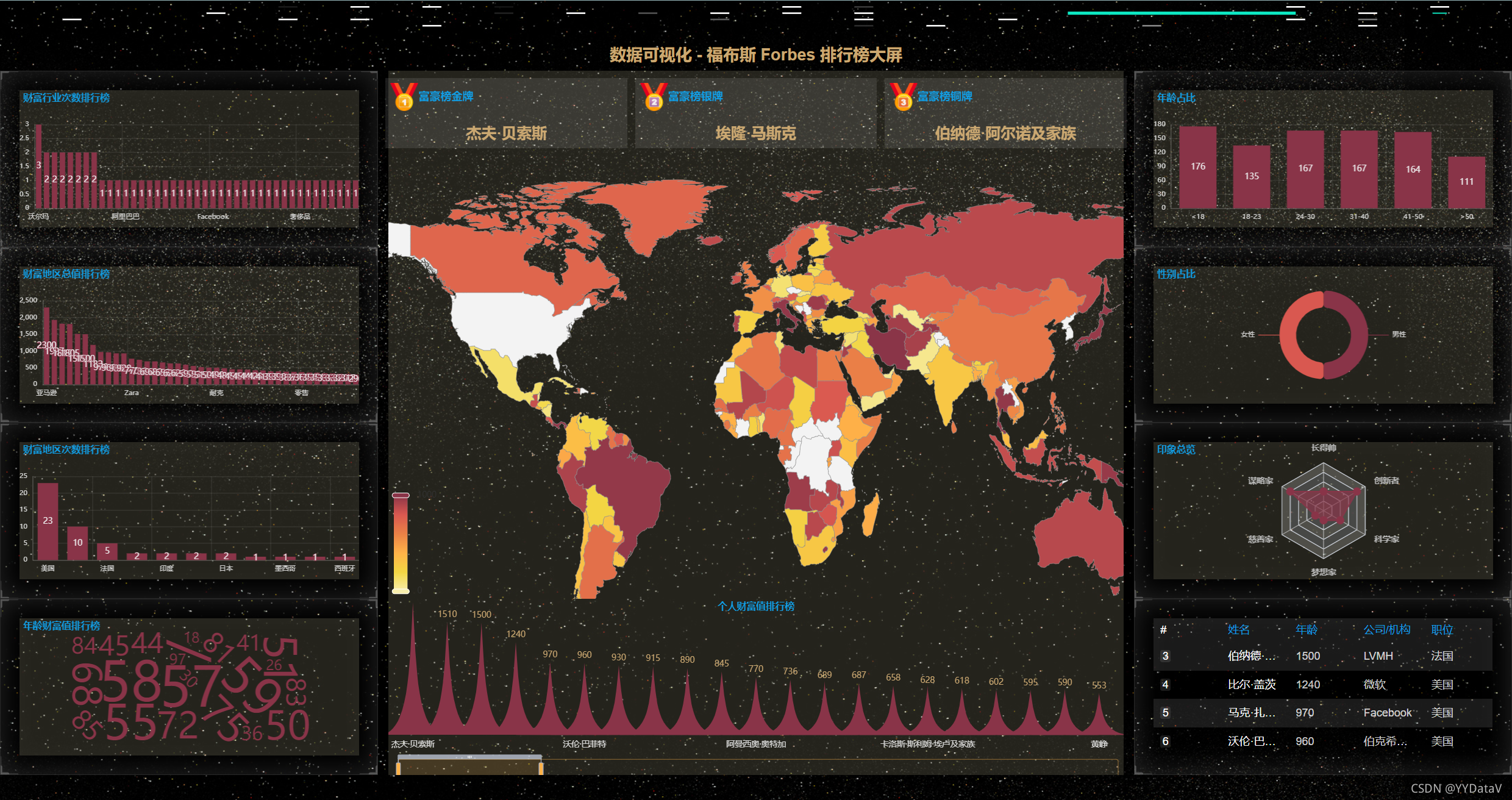
一、 确定需求方案
1、确定产品上线部署的屏幕LED分辨率
1280px*768px,F11全屏后占满整屏无滚动条;其它分辨率屏幕可自适应显示。
2、部署方式
- 基于免安装可执行程序:支持Windows、Linux、Mac等各种主流操作系统;将可执行程序exe复制到服务器上即可,无需其它环境依赖;
- 观看方式:既可在服务器上直接观看程序界面,也可远程使用浏览器打开播放,支持Chrome浏览器、360浏览器等主流浏览器。
二、整体架构设计
- 前端基于Echarts开源库设计,使用WebStorm编辑器;
- 后端基于Python Web实现,使用Pycharm编辑器;
- 数据传输格式:JSON;
- 数据源类型:本案例采用python request 采集实时数据方式。实际开发需求中,支持定制HTTP API接口方式或其它各种类型数据库,如PostgreSQL、MySQL、Oracle、Microsoft SQL Server、SQLite、Excel表格等。
- 数据更新方式:本案例为了展示数据,采用定时拉取方式。实际开发需求中,采用后端数据实时更新,实时推送到前端展示;
三、数据获取 - 关键编码实现
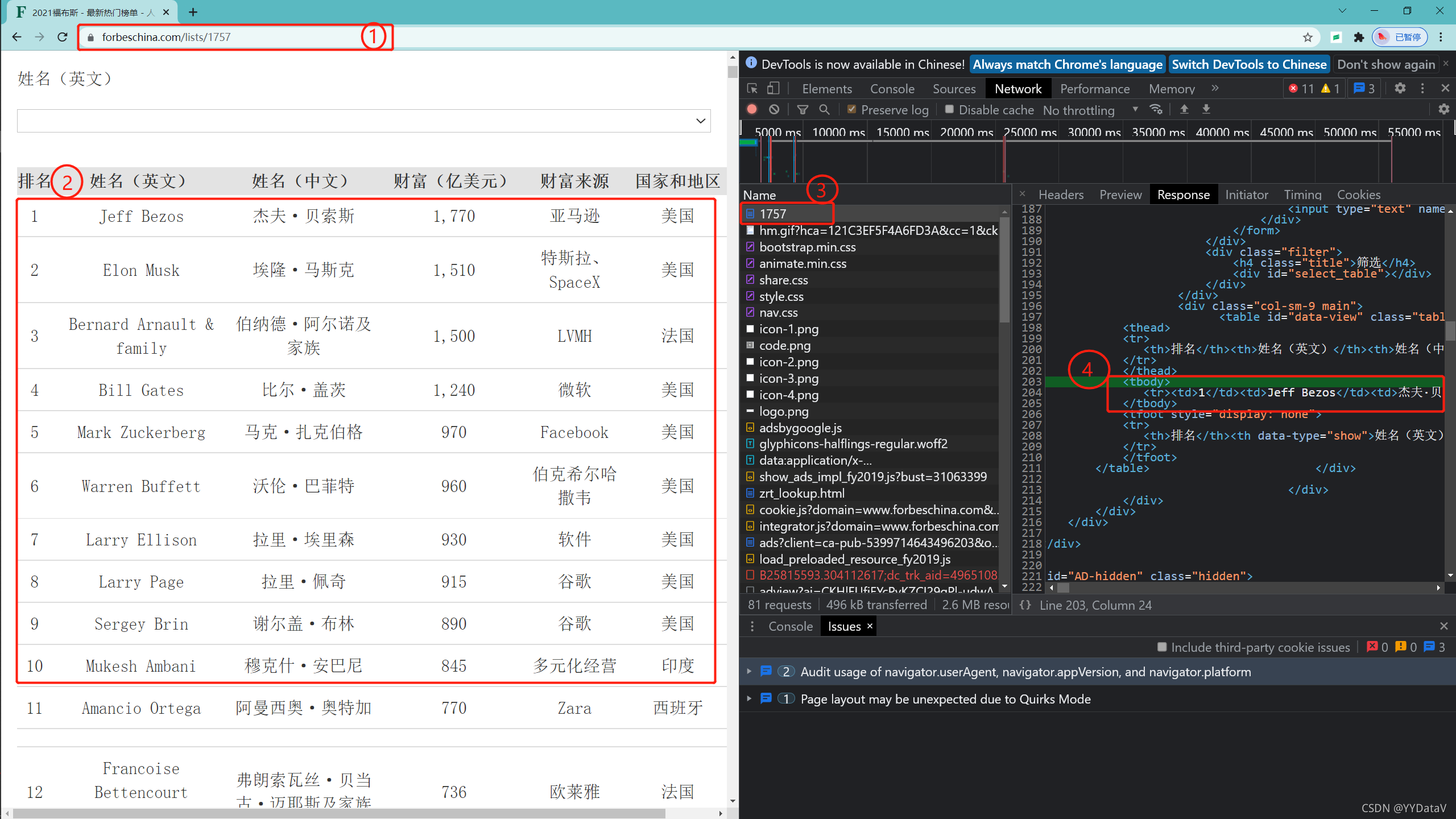
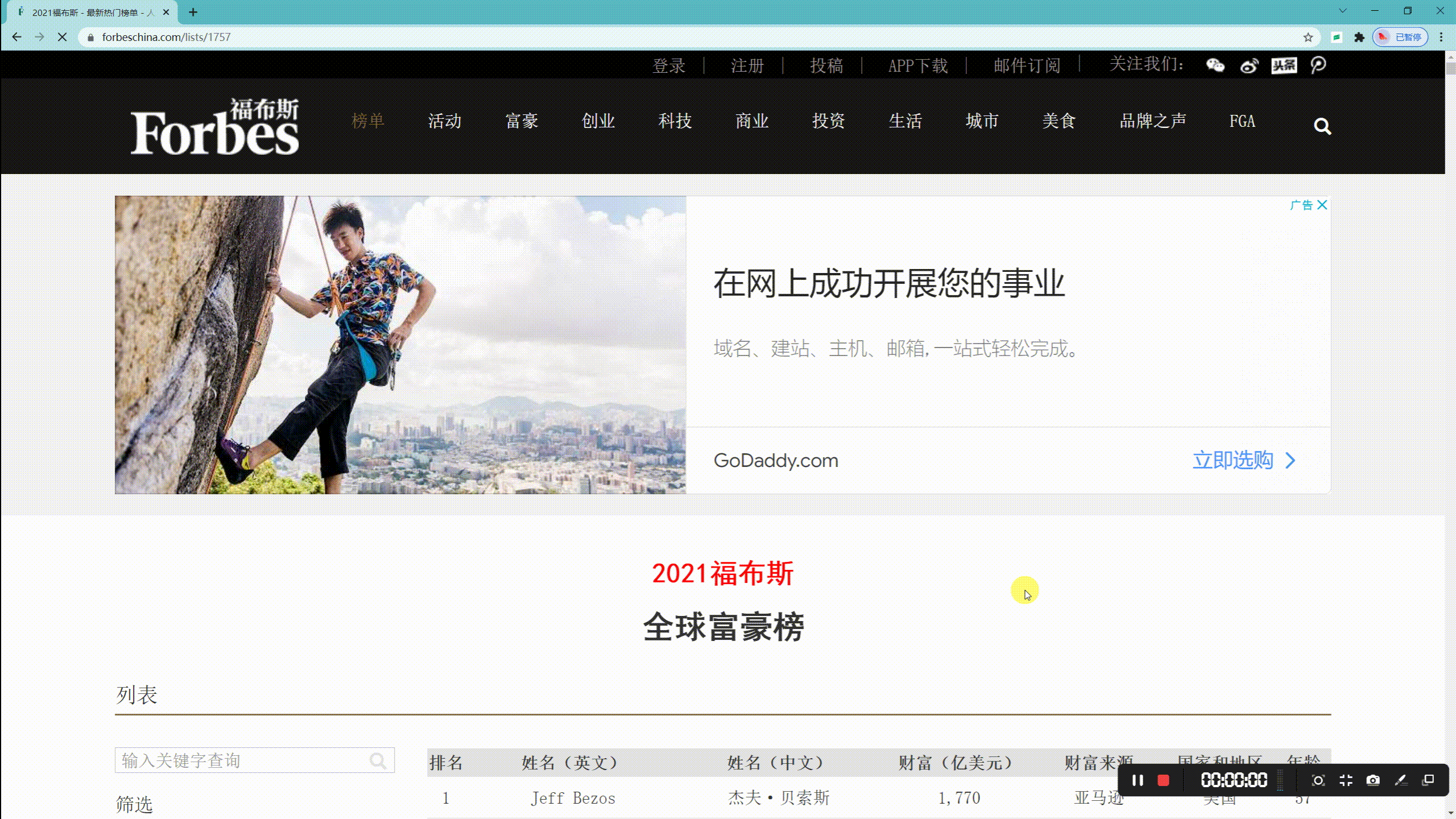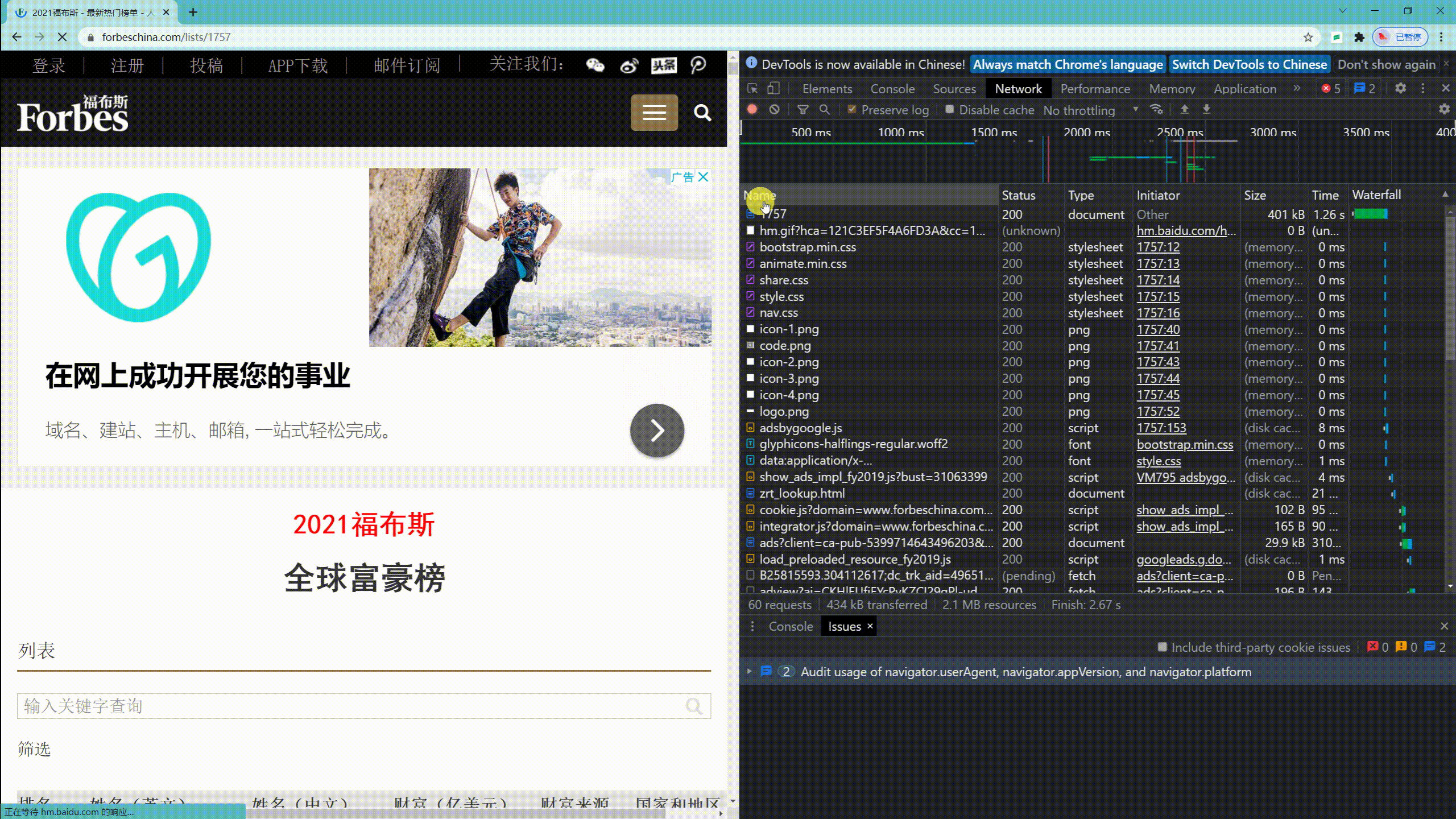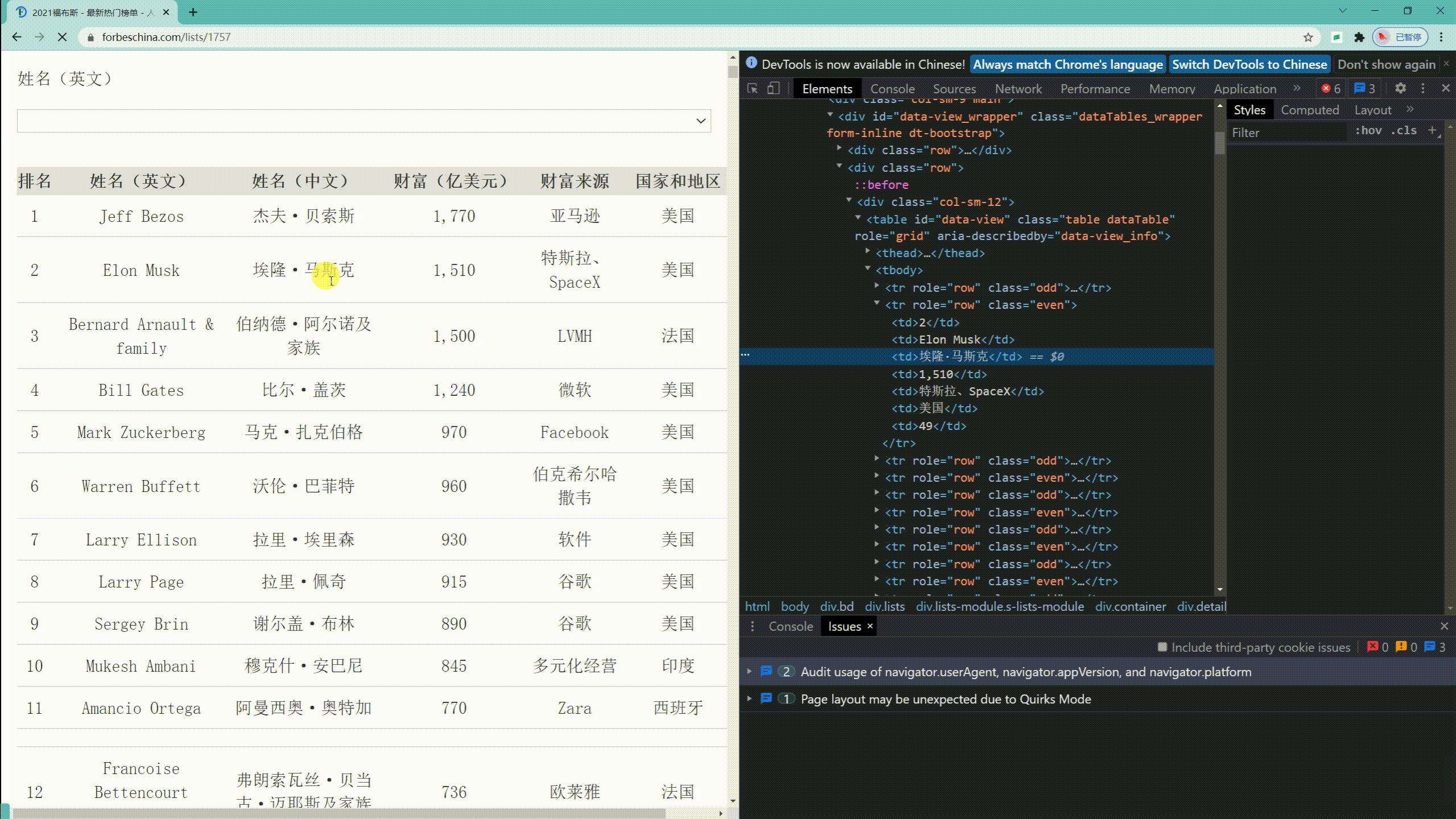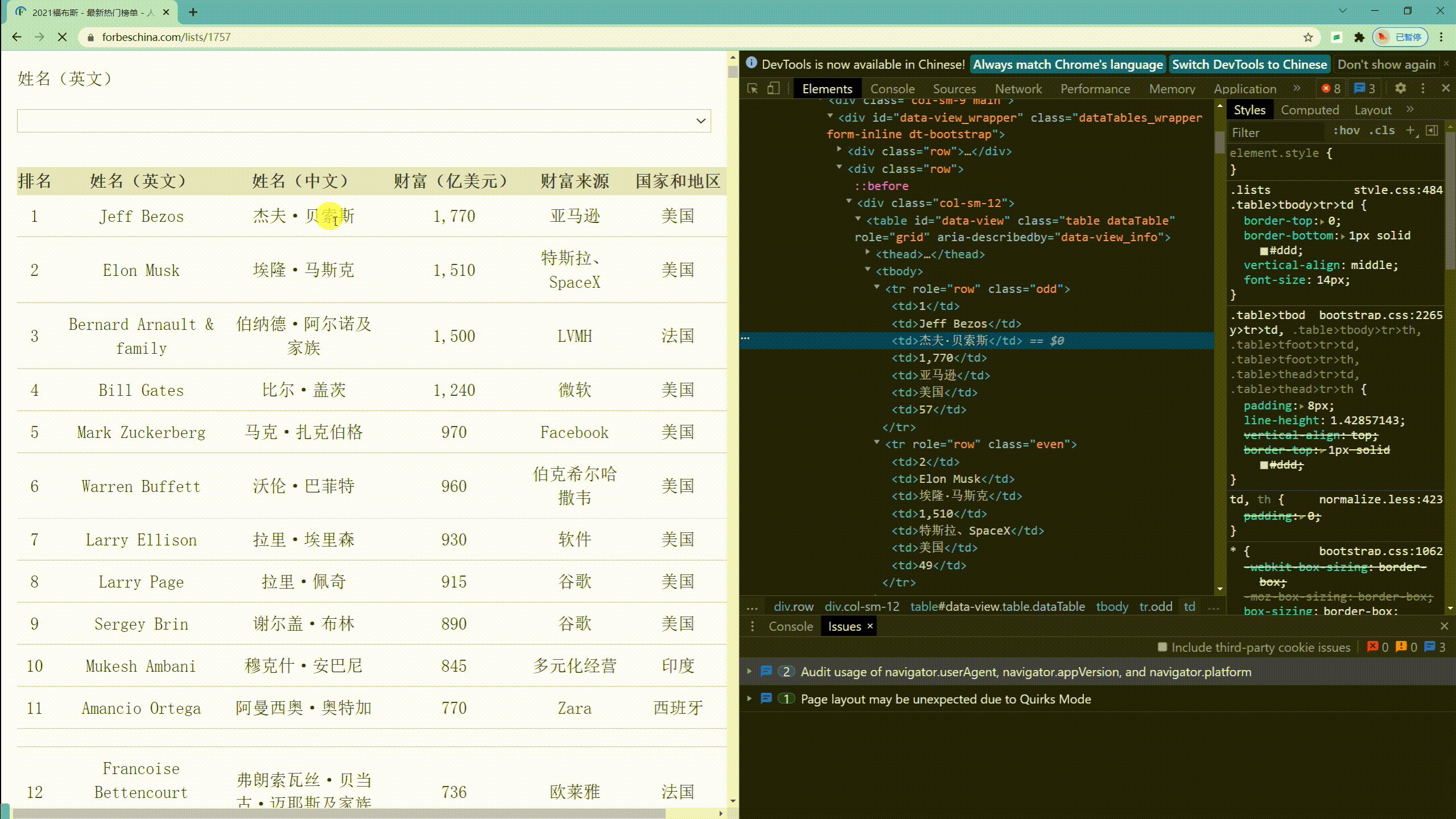
1、先分析目标网址 首页 - 福布斯中国 | Forbes China
打开网页,按下F12调出调试工具,选中Network栏目查看我们需要调用的url,具体操作看下面gif小动画。
经过分析找到本次爬虫要使用的url为 https://www.forbeschina.com/lists/1757
通过Response标签栏可以看出响应为table表格数据,那么我们可以对结果使用正则表达式解析。
2、关键代码
def scrapy(url='https://www.forbeschina.com/lists/1757'):
# 获取tr的正则表达式
pattern_tr = re.compile('<tr><td>.*?</tr>')
# 获取td的正则表达式
pattern_td = re.compile('<td>.*?</td>')
# 发起http请求,获取 response 页面内容
response = requests.get(url)
# 解析出tr列表
trList = pattern_tr.findall(response.text)
# 解析td值
for tr in trList:
nodeList = []
tdList = pattern_td.findall(tr)
tdLen = 0
if tdLen == 0:
tdLen = len(tdList)
i = 0
for td in tdList:
# 处理掉 <td> 和 </td>
value = td[4: len(td)-5]
# 处理掉 财富(亿元)的, 符号
if i == 3:
value = int(value.replace(',', ''))
nodeList.append(value)
i = i + 1
# 生成数组
gDataList.append(nodeList)
return gDataList四、数据分析
现在我们要把采集到的数据渲染到Echarts,这就需要做一些统计分析计算,我这里使用了一款非常有名的数据分析利器Pandas。
1、关键代码 - PictorialBar
这里以象形图PictorialBar为例,后端采集到的数据包括:
# 排名 姓名(英文) 姓名(中文) 财富(亿美元) 财富来源 国家和地区 年龄
echarts需要的数据如下:
姓名(中文) 财富(亿美元)
数据类型如下:
[['nameChinese', 'assets']]
所以,使用pandas对数据进行过滤,代码如下:
def getPictorialBar():
# 将列表生成 DataFrame
df = pd.DataFrame(gDataList[:100], columns=['seq', 'nameEnglish', 'nameChinese','assets', 'industry', 'location', 'age'])
return df[['nameChinese', 'assets']].to_json(orient='values')2、关键代码 - WordCloud
echarts需要的数据如下:
['name', 'value']
所以,使用pandas对年龄数据进行count计数,代码如下:
def getWordCloudAge():
# 将列表生成 DataFrame
df = pd.DataFrame(gDataList, columns=['seq', 'nameEnglish', 'nameChinese', 'value', 'industry', 'location', 'name'])
dfCount = df[['name', 'value']].groupby(by='name', sort=True).count()
data = dfCount['value'].to_json(orient="table")
data2 = eval(data)
return data五、数据可视化 - 关键编码实现
1、前端html代码
<div class="container_fluid">
<div class="row_fluid" id="vue_app">
<div style="padding:0 0" class="col-xs-12 col-md-12">
<dv-decoration-1 style="height:4%;">
</dv-decoration-1>
<h3 id="container_h"></h3>
</div>
<div style="padding:0 0" class="col-xs-12 col-md-3">
<dv-border-box-7 style="height:22%;padding:0 0" class="col-xs-12 col-md-12">
<div style="height:100%;padding:5% 5% 5% 5%;" id="container_1"></div>
</dv-border-box-7>
<dv-border-box-7 style="height:22%;padding:0 0" class="col-xs-12 col-md-12">
<div style="height:100%;padding:5% 5% 5% 5%;" id="container_2"></div>
</dv-border-box-7>
<dv-border-box-7 style="height:22%;padding:0 0" class="col-xs-12 col-md-12">
<div style="height:100%;padding:5% 5% 5% 5%;" id="container_3"></div>
</dv-border-box-7>
<dv-border-box-7 style="height:22%;padding:0 0" class="col-xs-12 col-md-12">
<div style="height:100%;padding:5% 5% 5% 5%;" id="container_4"></div>
</dv-border-box-7>
</div>
<div style="padding:0 0" class="col-xs-12 col-md-6">
<div style="height:66%;" id="container_5" class="col-xs-12 col-md-12"></div>
<div style="height:22%;" id="container_10" class="col-xs-12 col-md-12"></div>
<div class="div-title-1">
<p class="p-titile">
<img src="myimg/1.png" style="height: 40%; ">富豪榜金牌
</p>
<p id="container_dom_1" class="p-value">
</p>
</div>
<div class="div-title-2">
<p class="p-titile">
<img src="myimg/2.png" style="height: 40%; ">富豪榜银牌
</p>
<p id="container_dom_2" class="p-value">
</p>
</div>
<div class="div-title-3">
<p class="p-titile">
<img src="myimg/3.png" style="height: 40%; ">富豪榜铜牌
</p>
<p id="container_dom_3" class="p-value">
</p>
</div>
</div>
<div style="padding:0 0" class="col-xs-12 col-md-3">
<dv-border-box-7 style="height:22%;padding:0 0" class="col-xs-12 col-md-12">
<div style="height:100%;padding:5% 5% 5% 5%;" id="container_6"></div>
</dv-border-box-7>
<dv-border-box-7 style="height:22%;padding:0 0" class="col-xs-12 col-md-12">
<div style="height:100%;padding:5% 5% 5% 5%;" id="container_7"></div>
</dv-border-box-7>
<dv-border-box-7 style="height:22%;padding:0 0" class="col-xs-12 col-md-12">
<div style="height:100%;padding:5% 5% 5% 5%;" id="container_8"></div>
</dv-border-box-7>
<dv-border-box-7 style="height:22%;padding:0 0" class="col-xs-12 col-md-12">
<div style="height:100%;padding:5% 5% 5% 5%;" id="container_9">
<dv-scroll-board :config="config" />
</div>
</dv-border-box-7>
</div>
</div>
</div>
2、前端JS代码
var idContainer_10 = "container_10";
var chartDom = document.getElementById(idContainer_10);
var myChart = echarts.init(chartDom, window.gTheme);
var option;
option = {
title: {
text: "个人财富值排行榜",
textStyle: {
fontSize: 14,
fontWeight: "bold",
color: "hsl(200, 86%, 48%)",
},
left: "center",
},
grid: {
left: "1%",
right: "1%",
bottom: "15%",
top: "1%",
containLabel: true,
},
tooltip: {
trigger: "axis",
axisPointer: {
type: "none",
},
formatter: function (params) {
return params[0].value + " 亿美元";
},
},
dataZoom: [
{
type: "slider",
xAxisIndex: 0,
start: 0,
end: 20,
bottom: "0",
},
],
dataset:{
source:[]
},
xAxis: {
type: 'category',
splitLine: { show: false },
axisTick: { show: false },
axisLine: { show: false },
axisLabel: {
color: "rgba(255,255,255,.8)",
},
},
yAxis: {
splitLine: { show: false },
axisTick: { show: false },
axisLine: { show: false },
axisLabel: { show: false },
},
series: [
{
type: "pictorialBar",
barCategoryGap: "-100%",
label: {
normal: {
show: true,
position: "top",
textStyle: {
color: ["#cba871"],
},
},
},
symbol: "path://M0,10 L10,10 C5.5,10 5.5,5 5,0 C4.5,5 4.5,10 0,10 z",
itemStyle: {
opacity: 1,
},
emphasis: {
itemStyle: {
opacity: 1,
},
},
z: 10,
},
],
};
function asyncData_10() {
$.getJSON("/json/pictorial_bar.json").done(function (data) {
var myChart = echarts.init(document.getElementById(idContainer_10));
myChart.setOption({'dataset':{'source':data}});
//金银铜前三名富豪
topData = [data[0][0], data[1][0], data[2][0]];
asyncData_dom(topData);
}); //end $.getJSON
}
window.addEventListener("resize", function () {
myChart.resize();
});
myChart.setOption(option);
3、后端python服务器代码
# -*- coding:utf-8 -*-
from http.server import HTTPServer, SimpleHTTPRequestHandler, ThreadingHTTPServer
import json
import scrapyForbes as scrapyForbes
ip = "localhost" # 监听IP,配置项
port = 8820 # 监听端口,配置项
class MyRequestHandler(SimpleHTTPRequestHandler):
protocol_version = "HTTP/1.0"
server_version = "PSHS/0.1"
sys_version = "Python/3.7.x"
target = "./" # 监听目录,配置项
# 生成一个爬虫实例
scrapyForbes = scrapyForbes.scrapy()
def do_GET(self):
url = ""
data = []
# 处理客户端的爬虫数据请求
if self.path.find("/json/pictorial_bar.json") >= 0:
data = scrapyForbes.getPictorialBar()
elif self.path.find("/json/bar_industry.json") >= 0:
data = scrapyForbes.getIndustry()
elif self.path.find("/json/bar_location.json") >= 0:
data = scrapyForbes.getGeoMapWorld()
elif self.path.find("/json/wordcloud_age.json") >= 0:
data = scrapyForbes.getWordCloudAge()
elif self.path.find("/json/bar_assets.json") >= 0:
data = scrapyForbes.getAssets()
elif self.path.find("/json/table.json") >= 0:
data = scrapyForbes.getTable()
else:
SimpleHTTPRequestHandler.do_GET(self)
return
# 响应http header
self.send_response(200)
self.send_header("Content-type", "json")
self.end_headers()
# 响应http response
# rspstr = json.dumps(data)
self.wfile.write(data.encode("utf-8"))
def HttpServer():
try:
server = HTTPServer((ip, port), MyRequestHandler)
listen = "http://%s:%d" % (ip, port)
print("服务器监听地址: ", listen)
server.serve_forever()
except Exception as e:
print("Exception", e)
server.socket.close()
if __name__ == "__main__":
HttpServer()
六、上线运行
启动命令参考Readme.md文件。
七、源码下载
20【源码】数据可视化:基于Echarts+Python动态实时大屏范例(含爬虫代码)-福布斯排行榜大屏.zip-企业管理文档类资源-CSDN下载



















 1034
1034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











