







Kafka作为一种高吞吐量的分布式发布订阅消息系统,目前已经越来越被广泛的应用。这里介绍下如何在Spring Boot下集成、应用

abstract.png
环境搭建
我们使用Docker来进行实践,其中本机IP为192.168.2.101。其实这里还需要一个ZooKeeper实例用于保存元数据,这里就不赘述ZooKeeper相关配置了
# 拉取镜像
docker pull wurstmeister/kafka
# 创建容器
docker run \
-e KAFKA_BROKER_ID=1 \
-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \ # KafKa监听端口
-e KAFKA_ZOOKEEPER_CONNECT=192.168.2.101:2181/kafka \ # ZooKeeper地址、端口
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.2.101:9092 \ # 暴露给客户端的地址、端口信息
-d -p 9092:9092 \
--name myKafka \
wurstmeister/kafka
由于wurstmeister/kafka镜像使用Alpine Linux作为基础镜像环境,其使用的UTC时间与我们本地时间(北京时间)有8个小时的时差。故这里我们介绍下如何在Alpine Linux设置正确的时区,利用docker exec命令进入容器,然后进行如下设置
# 安装 时区数据
apk add tzdata
# 查看 亚洲可用的时区
ls /usr/share/zoneinfo/Asia
# 复制 亚洲/上海 时区 到 /etc/localtime 下
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
# 设置时区为 亚洲/上海
echo "Asia/Shanghai" > /etc/timezone
# 查看当前时间,验证是否生效
date -R
一切配置好了,现在我们通过命令脚本来验证下看看Kafka是否可以正常工作
生产者操作如下
# 进入容器
docker exec -it myKafka /bin/bash
# 切换目录
cd /opt/kafka/bin
# 使用kafka-console-producer.sh脚本 生产消息
./kafka-console-producer.sh --broker-list localhost:9092 --topic test
# 生产消息1
one
# 生产消息2
hell world
消费者操作如下
# 进入容器
docker exec -it myKafka /bin/bash
# 切换目录
cd /opt/kafka/bin
# 使用kafka-console-consumer.sh脚本 消费消息
./kafka-console-consumer.sh --broker-list localhost:9092 --topic test
效果如下所示,符合预期
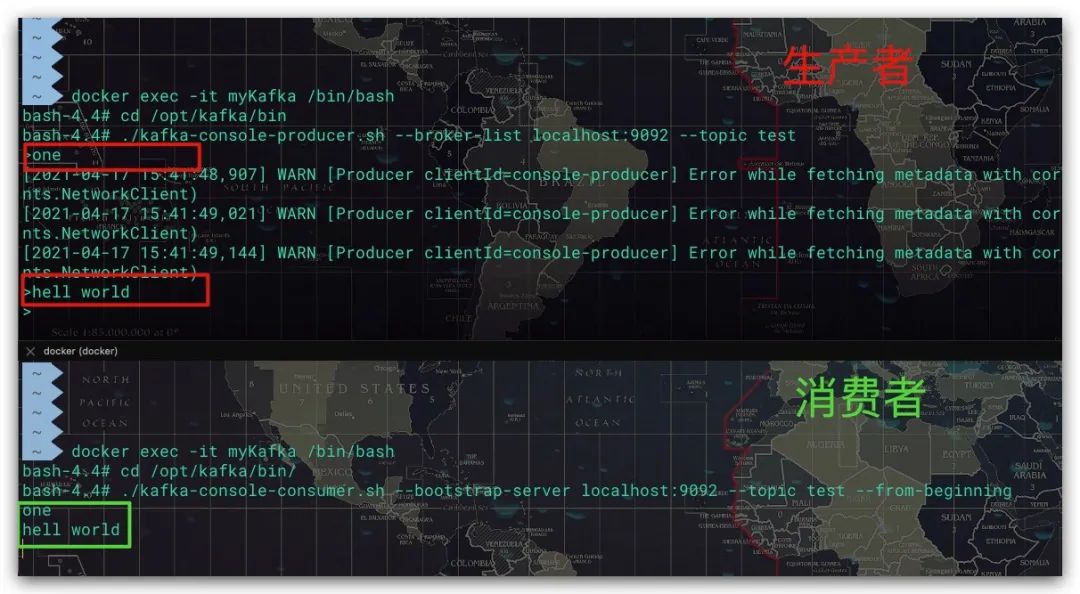
figure 1.jpeg
SpringBoot集成Kafka
依赖
SpringBoot下使用Kafka很方便,直接添加依赖即可。
<!-- Kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.6.4</version>
</dependency>
这里我们需要注意SpringBoot与spring-kafka之间的版本兼容性,具体地可以参考官网(https://spring.io/projects/spring-kafka ),下图红框、蓝框分别为spring-kafka、SpringBoot的版本要求。这里,我们的SpringBoot版本为2.4.1
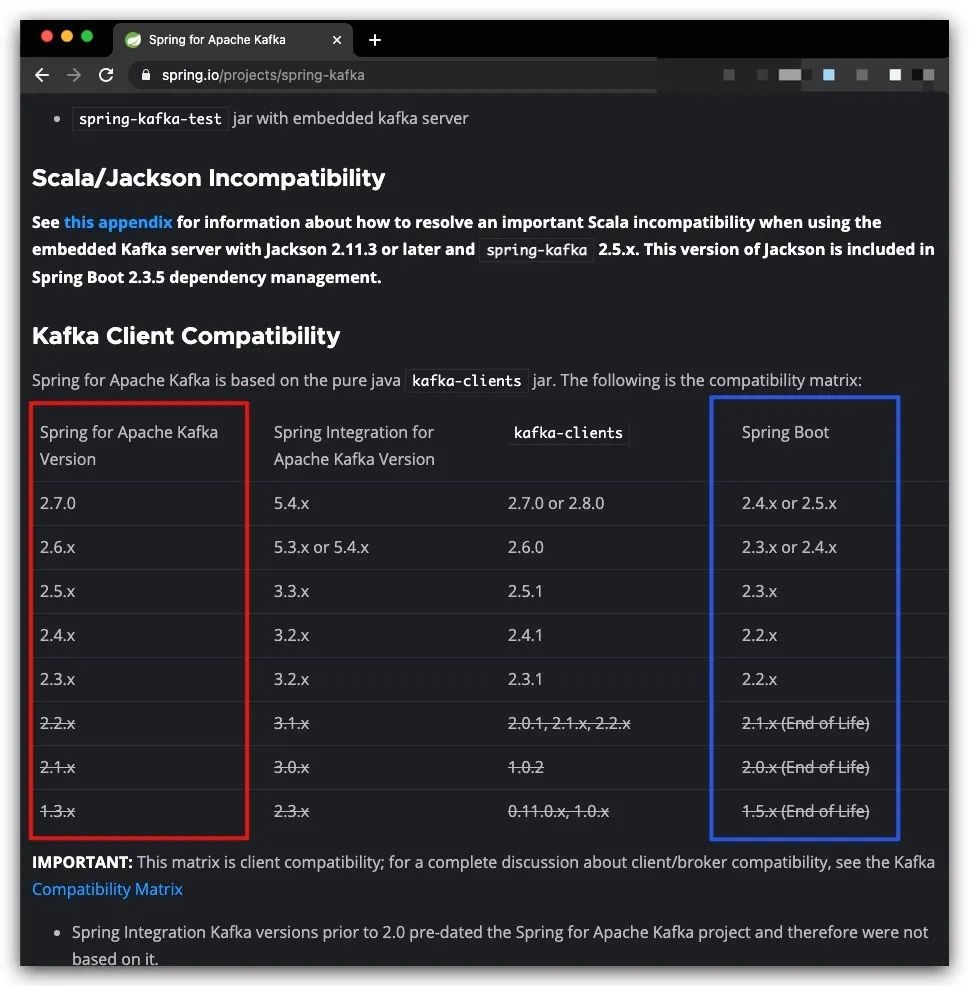
figure 2.jpeg
其实,关于spring-kafka版本的选择问题还有一个小技巧,我们可以在POM依赖中不指定spring-kafka的版本信息,这样其会自动选择合适的版本
配置
在 application.properties 中添加相关的必要配置
# Kafka
# Kafka 地址、端口
spring.kafka.bootstrap-servers=127.0.0.1:9092
# 自定义Kafka分区器
spring.kafka.producer.properties.partitioner.class=com.aaron.SpringBoot1.Kafka.KafkaPartitioner
# 生产者 key、value的序列化器
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
# 消费者 key、value的反序列化器
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
实践
手动声明一个Topic,并设置分区数为4
@Configuration
public class KafkaConfig {
public static final String TOPIC_ALARM_IN = "topic_alarm_in";
/**
* 声明Topic,设置其分区数为4
* @return
*/
@Bean
public NewTopic topic1() {
return TopicBuilder.name(TOPIC_ALARM_IN)
.partitions(4)
.build();
}
}
在上文的配置中,我们定义了一个自定义的Kafka分区器。我们需要实现Partitioner接口,在partition方法中实现我们的分区逻辑。如下所示
/**
* 自定义Kafka分区器
*/
public class KafkaPartitioner implements Partitioner {
@Override
public void configure(Map<String, ?> configs) {
}
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 获取该主题的分区数量
int size = cluster.partitionsForTopic(topic).size();
// 分区号
int index = -1;
switch ( (String) key) {
case "996":
index = 1;
break;
case "247":
index = 2;
break;
case "965":
index = 3;
break;
default:
index = 0;
}
return index;
}
@Override
public void close() {
}
}
消息的生产者就比较简单了,我们直接使用kafkaTemplate发送即可,这里我们简单地对其进行了封装
@Component
public class Producer {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@Autowired
private KafkaSendResultHandler kafkaSendResultHandler;
public void sendMsg(String topic, String key, String value) {
try{
// 设置消息发送结果的回调
kafkaTemplate.setProducerListener(kafkaSendResultHandler);
kafkaTemplate.send(topic, key, value);
}catch (Exception e) {
e.printStackTrace();
}
}
}
其中,send方法会返回一个Future,可进一步地通过get方法获取发送结果。但我们既希望能够了解消息发送是否成功,又不希望被阻塞。幸好Kafka提供了一个回调接口用于处理发送结果,KafkaSendResultHandler实现如下所示
@Component
public class KafkaSendResultHandler implements ProducerListener {
@Override
public void onSuccess(ProducerRecord producerRecord, RecordMetadata recordMetadata) {
String info = "[发送成功]: ";
String resultStr = buildResult(producerRecord);
System.out.println( info + resultStr );
}
@Override
public void onError(ProducerRecord producerRecord, RecordMetadata recordMetadata, Exception exception) {
String info = "[发送失败]: ";
String resultStr = buildResult(producerRecord);
System.out.println( info + resultStr );
exception.printStackTrace();
System.out.println();
}
private String buildResult(ProducerRecord<String, String> producerRecord) {
String topic = producerRecord.topic();
String key = producerRecord.key();
String value = producerRecord.value();
String str = " <topic>: " + topic + ", <key>: " + key + ", <value> :" + value;
return str;
}
}
这里为了简便,使用一个Controller用于控制消息的发送,并将id作为key
@RequiredArgsConstructor(onConstructor = @__(@Autowired))
@Controller
@ResponseBody
@RequestMapping("Kafka")
public class KafkaController {
@Autowired
private Producer producer;
@RequestMapping("/saveAlarmIn")
public String test1(@RequestBody AlarmIn alarmIn) {
System.out.println("\n------------------------------------");
String topic = TOPIC_ALARM_IN;
String key = alarmIn.getId().toString();
try {
String jsonStr = new ObjectMapper().writeValueAsString(alarmIn);
producer.sendMsg(topic, key, jsonStr);
} catch (Exception e) {
e.printStackTrace();
}
return "OK";
}
}
...
/**
* 进入告警
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
public class AlarmIn {
/**
* ID
*/
private Integer id;
/**
* 进入告警的人员姓名
*/
private String personName;
/**
* 进入告警的区域名称
*/
private String areaName;
/**
* 告警级别
*/
private Integer level;
}
通过@KafkaListener注解即可实现消息的监听消费,具体地可通过topics、groupId等属性设置主题、消费者群组名等信息
@Component
public class Consumer {
@KafkaListener(topics = TOPIC_ALARM_IN, groupId = "myGroup1" )
public void g1c1(ConsumerRecord<String, String> record) {
AlarmIn alarmIn = parseAlarmIn(record);
int index = record.partition();
System.out.println("[myGroup1] <c1>: alarmIn: " + alarmIn + ", partition: " + index);
}
@KafkaListener(topics = TOPIC_ALARM_IN, groupId = "myGroup1" )
public void g1c2(ConsumerRecord<String, String> record) {
AlarmIn alarmIn = parseAlarmIn(record);
int index = record.partition();
System.out.println("[myGroup1] <c2>: alarmIn: " + alarmIn + ", partition: " + index);
}
@KafkaListener(topics = TOPIC_ALARM_IN, groupId = "myGroup2" )
public void g2c3(ConsumerRecord<String, String> record) {
AlarmIn alarmIn = parseAlarmIn(record);
int index = record.partition();
System.out.println("[myGroup2] <c3>: alarmIn: " + alarmIn + ", partition: " + index);
}
/**
* 解析进入告警信息
* @param record
* @return
*/
private AlarmIn parseAlarmIn(ConsumerRecord<String, String> record) {
String key = record.key();
String value = record.value();
AlarmIn alarmIn = null;
try {
alarmIn = new ObjectMapper().readValue(value, AlarmIn.class);
} catch (Exception e) {
e.printStackTrace();
}
return alarmIn;
}
}
测试结果如下,符合预期
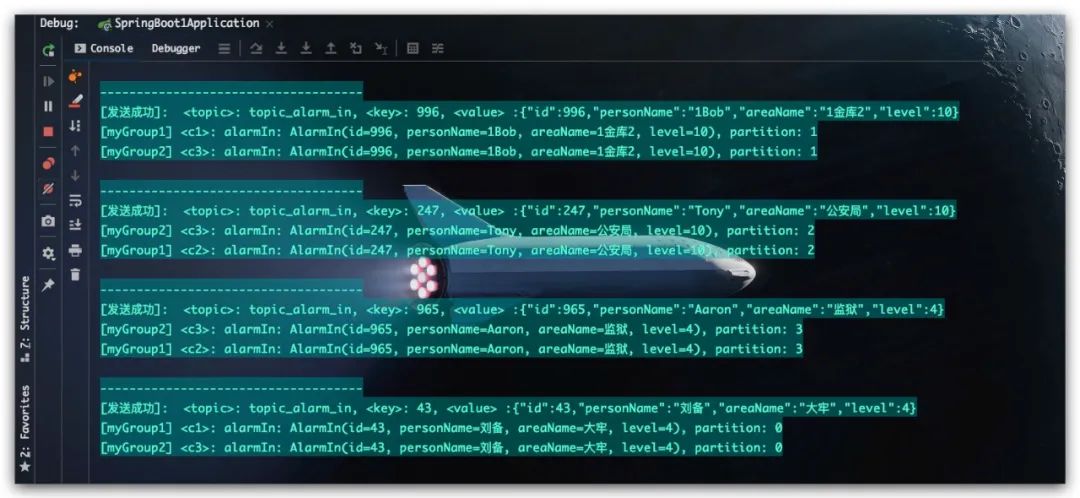
figure 3.jpeg
Note
-
Kafka将一个消费群组内的所有消费者视为同一个整体,他们均订阅同一个主题。一条消息只会被群组内的一个消费者进行消费。但消费者组之间不会相互影响,换言之,如果另外一个消费者组也订阅了该主题,其同样也会收到该消息并进行处理。上文的测试结果也佐证了这一点
-
Kafka中一个主题Topic虽然可以拥有多个分区,但一个分区不能被同一个消费者群组下的多个消费者进行消费。所以当 某个消费者群组中消费者的数量 多于 其订阅的主题Topic的分区数 时,该群组多出来的消费者只会被闲置、浪费
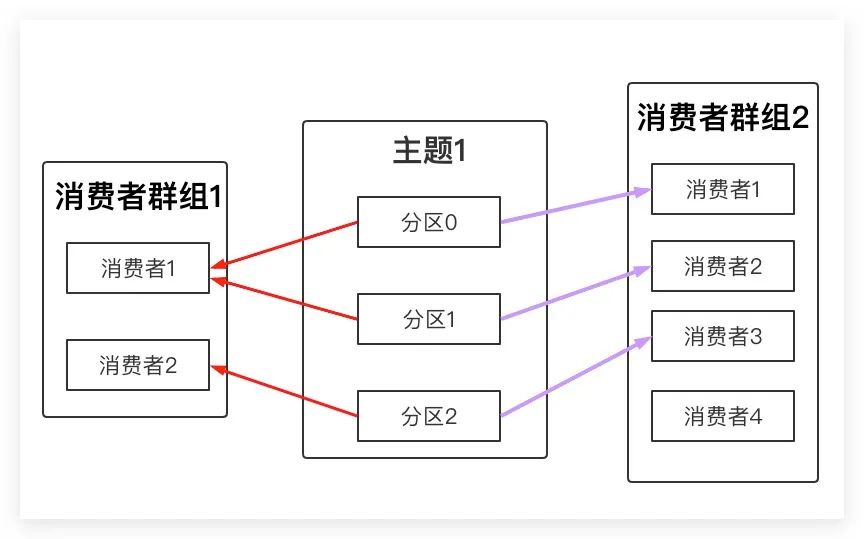
figure 4.jpeg
-
上文我们自定义了一个Kafka的分区器,事实上这并不是必须的。一方面我们在发送时可以显式地将消息发送到指定的分区;另一方面,如果发送时未直接指定分区,Kafka也会使用默认的分区器进行分区。具体地,如果key不为null, 默认分区器则通过哈希计算来保证相同key键的消息可以被映射到同一个分区下;如果key为null,默认分区器则使用轮询算法将消息均衡地分布到各个分区
参考文献
-
Kafka权威指南 Neha Narkhede/Gwen Shapira/Todd Palino著
















 6567
6567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









