






1. 尽管在matlab里面批量读取数据还是比较简单的,但是有时工作需要只能在python里面处理数据。
大文件夹里有两个子文件夹,大文件夹构成如下:
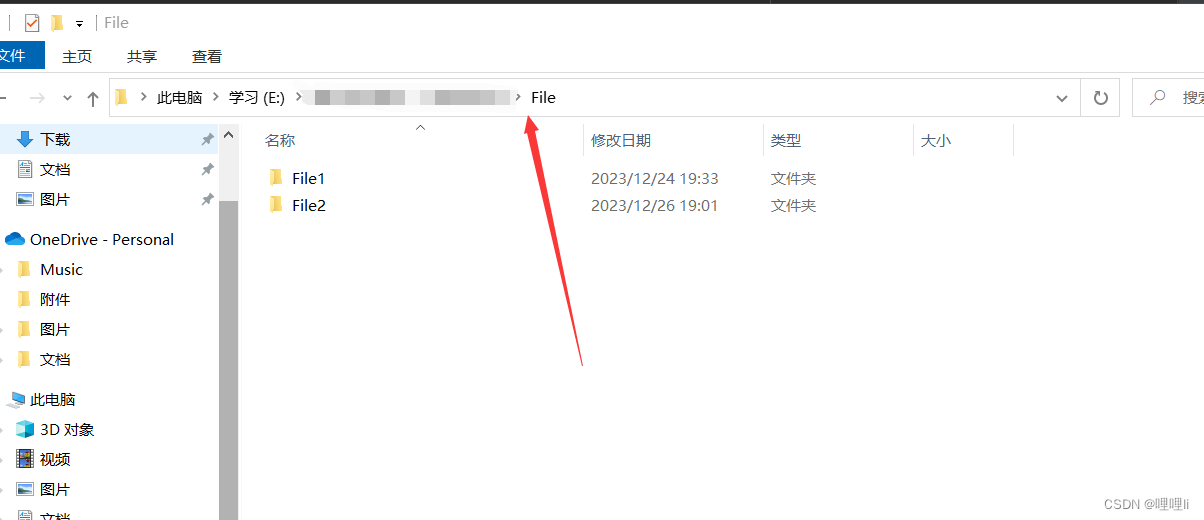
子文件夹构成如下:将所有文件名含有error的文件的第一列储存一起到新的excel中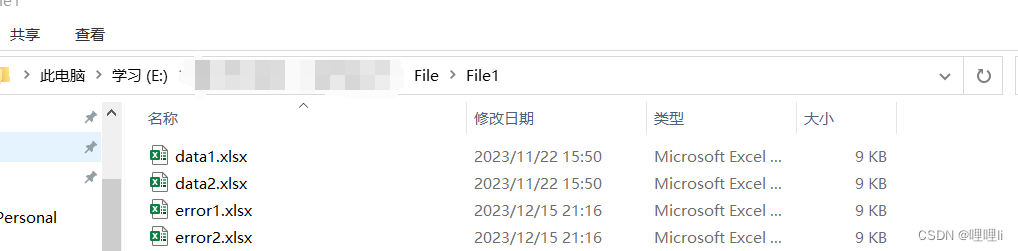
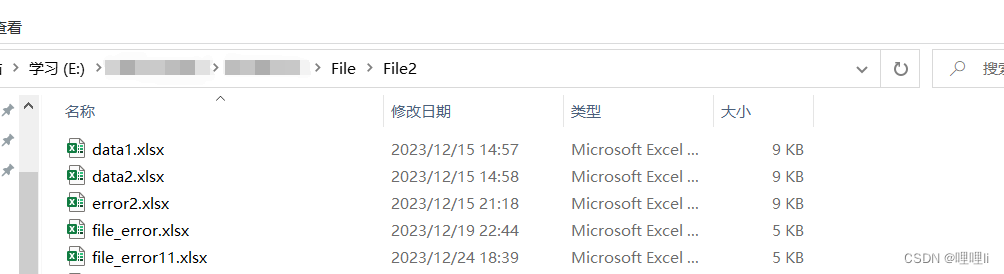
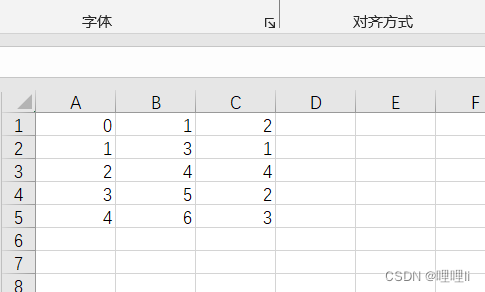
为方便对比,excel都是如下图这样的三列数据
2. python代码如下
import numpy as np
#from sklearn.ensemble import RandomForestRegressor
#from sklearn.model_selection import RandomizedSearchCV
#import scipy.io as scio
import os
import pandas as pd
path = 'E:\学习资料\工作\File'
entries = os.listdir(path)
data_array = []
summ = 0
y_005 = {}
Y_005 = {}
i = 1
m = 1
for entry in entries:
full_path = os.path.join(path, entry)
if os.path.isdir(full_path):
folder_path = full_path
file_paths = []
for file_name in os.listdir(folder_path):
sum_of_error = 0
if "error" in file_name:
target_file = (os.path.join(folder_path, file_name))
errors = pd.read_excel(target_file, header=None).iloc[:, 0:1]
Y_005[m] = errors
m += 1
print(type(errors))
data_array.append(errors.iloc[:, 0])
if "data" in file_name:
file_paths.append(os.path.join(folder_path, file_name))
result_df = pd.concat (data_array, axis = 1)#重要
y_005[i] = result_df
y_006 = pd.concat(y_005, axis=1)
i += 1
t = 1
if os.path.isdir(full_path):
folder_path = full_path
file_paths = []
for file_name in os.listdir(folder_path):
if "error" in file_name:
target_file = (os.path.join(folder_path, "test"+file_name))##这一步是将每个error文件中的第一列数据单独保存到新的excel
Y_005[t].to_excel(target_file, index=False, header=None)
target_file1 = (os.path.join(folder_path, 'file_error111.xlsx'))
result_df.to_excel(target_file1, index=False, header=None)##这一步是将每个error文件中的第一列数据合并保存到新的excel















 6648
6648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









