







实例:
假设你办了个广播节目,要让全美50个州的听众都听到。为次,你需要决定哪些广播台播出。在每个广播台播出都需要支付费用,因此你要尽可能少的在广播台播出。。
其中每个广播台覆盖特定的区域,不同广播台的覆盖区域可能重叠
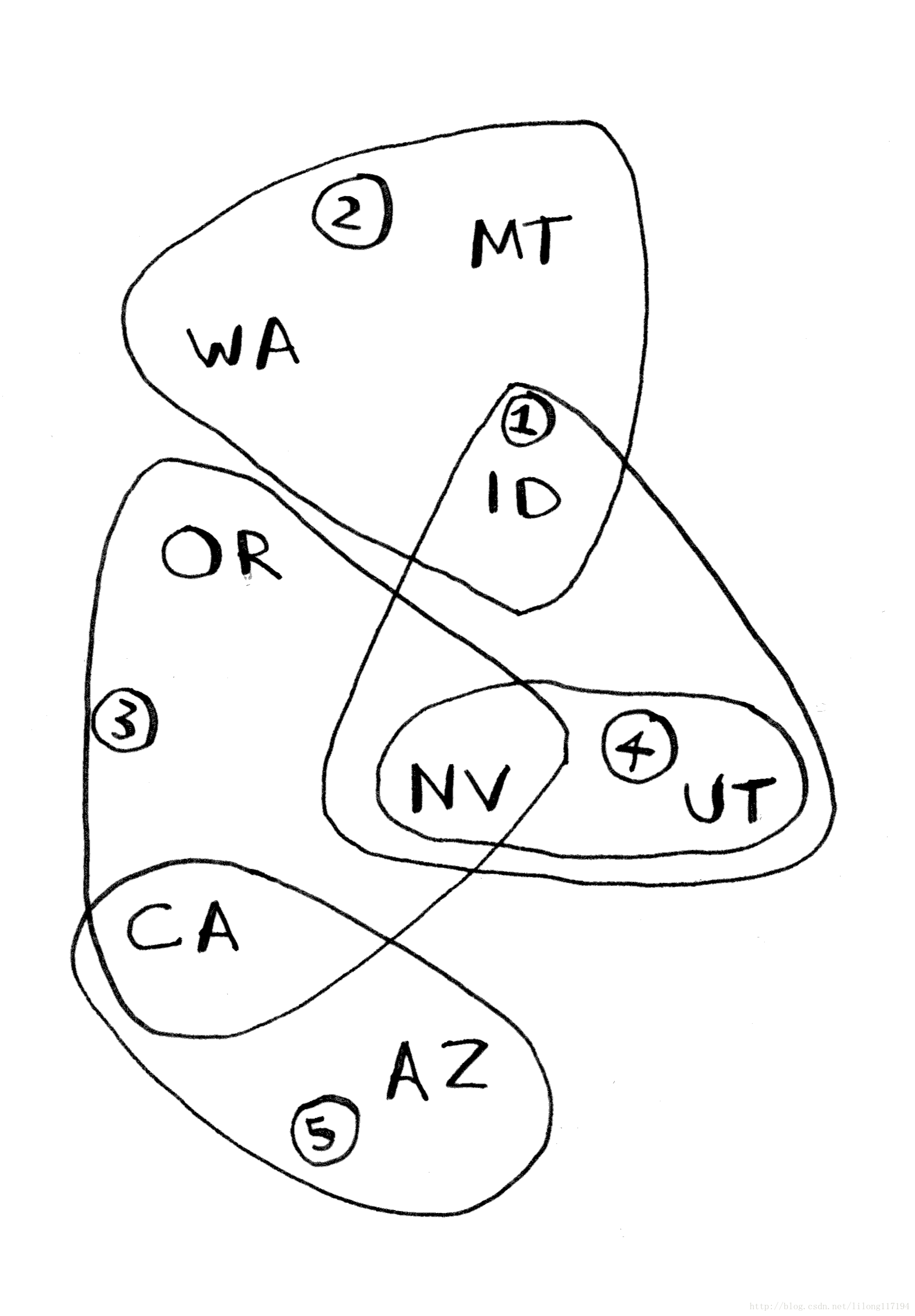
这样的话要遍历所有的可能的子集合组合,就有 2n ,其中n为广播台数目,用大O表示法运行时间为 O(2n) 。如果广播台很多,就成了一个NP难问题,而贪婪算法可以得到非常接近的解:
- 选出这样一个广播台,即它覆盖了最多的州。即便这个广播台覆盖了一些已覆盖的州,也没有关系
- 重复第一步,直到覆盖所有的州
这是一种近似算法,因为获得精确解需要的时间太长,而贪婪算法可以很好的近似。。
而贪婪算法的运行时间为
O(n2)
,减少的时间不止一点点。。
# coding=utf-8
# 要覆盖的州
states_needed = set(["mt", "wa", "or", "id", "nv", "ut", "ca", "az"])
# 广播台清单
stations = {}
stations["kone"] = set(["id", "nv", "ut"])
stations["ktwo"] = set(["wa", "id", "mt"])
stations["kthree"] = set(["or", "nv", "ca"])
stations["kfour"] = set(["nv", "ut"])
stations["kfive"] = set(["ca", "az"])
final_stations = set() # 存储最终选择的广播台
while states_needed: # 只要没有全部覆盖完
best_station = None
states_covered = set() # 存储已经覆盖的州
for station, states in stations.items(): # items()存储键值(广播台和相应的覆盖州)
covered = states_needed & states # 集合的交集,判断还未覆盖的州与此广播台的交集个数
if len(covered) > len(states_covered): # 如果当前广播台州交集的个数大于当前要覆盖的州
best_station = station # 就替换为最优的广播台
states_covered = covered # 替换已经覆盖的州
states_needed -= states_covered # 从要覆盖的州中减去已经覆盖过的(集合相减)
print 'states_needed:',states_needed
final_stations.add(best_station) # 添加最优的广播台
print final_stations
结果:
========== RESTART: C:\Users\LiLong\Desktop\Algorithm\set_cover.py ==========
states_needed: set(['ut', 'ca', 'az', 'or', 'nv'])
states_needed: set(['ut', 'az'])
states_needed: set(['ut'])
states_needed: set([])
set(['ktwo', 'kthree', 'kone', 'kfive'])
>>> 得到了最终选的广播台集合是:’ktwo’, ‘kthree’, ‘kone’, ‘kfive’这4个
这只是个很简单的NP难得例子,还有其他的很多,有待进一步学习。。
参考:《算法图解》

















 1832
1832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









