









从识别手写数字的案例开始认识神经网络,并了解如何在tensorflow中一步步建立卷积神经网络。
安装tensorflow
tensorflow库,只支持Python 3.5及以上,所以要先确保电脑里的Python版本至少为3.5。
具体安装细节参考http://blog.csdn.net/goodshot/article/details/61926805
数据来源
kaggle新手入门的数字识别案例,包含手写0-9的灰度值图像的csv文件,下载地址:https://www.kaggle.com/c/digit-recognizer/data
文件里共有42000个数字图像,每个图像的属性为长28像素,宽28像素,共784个像素,这个矩阵可表示为一个28*28=784的数组。每个像素值的大小表示该像素的颜色明暗,值位于0-255之间,值越大表明颜色越深。csv文件的第一列是数字的真实标签。
Python实现CNN
导入各个模块和设置参数:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.cm as cm
%matplotlib inline
import tensorflow as tf
#参数设置
learning_rate=1e-4
training_iterations=2000
dropout=0.5
batch_size=50
#所有的训练样本分批训练的效率最高,每一批的训练样本数量就是batch
validation_size=2000
image_to_display=10数据准备:
data=pd.read_csv('.../train.csv')
images=data.iloc[:,1:].values
images=images.astype(np.float)
#对训练数据进行归一化处理,[0:255]=>[0.0:1.0]
images=np.multiply(images,1.0/255.0)
#print('images({0[0]},{0[1]})'.format(images.shape))可以查看数据格式,输出结果为'data(42000,784)'
image_size=images.shape[1]
image_width=image_height=np.ceil(np.sqrt(image_size)).astype(np.uint8)
#定义显示图片的函数
def display(img):
#从784=>28*28
one_img=img.reshape(image_width,image_height)
plt.axis('off')
plt.imshow(one_img,cmap=cm.binary)
display(images[10])
#显示数据表格中第十条数据代表的数字,结果如下图
labels_flat=data.iloc[:,0].values.ravel()
labels_count=np.unique(labels_flat).shape[0]
#定义one-hot编码函数
def dense_to_one_hot(labels_dense, num_classes):
num_labels = labels_dense.shape[0]
index_offset = np.arange(num_labels) * num_classes
labels_one_hot = np.zeros((num_labels, num_classes))
labels_one_hot.flat[index_offset + labels_dense.ravel()] = 1
return labels_one_hot
labels = dense_to_one_hot(labels_flat, labels_count)
labels = labels.astype(np.uint8)
#print(labels[10])的输出结果为'[0 0 0 0 0 0 0 0 1 0]',代表数据集中第10个数字的实际值为'8'
#将数据拆分成用于训练和验证两部分
validation_images=images[:validation_size]
#将训练的数据分为train和validation,validation的部分是为了对比不同模型参数的训练效果,如:learning_rate, training_iterations, dropout
validation_labels=labels[:validation_size]
train_images = images[validation_size:]
train_labels = labels[validation_size:]定义权重、偏差、卷积图层、池化图层:
#定义weight
def weight_variable(shape):
initial=tf.truncated_normal(shape,stddev=0.1)
return tf.Variable(initial)
#定义bias
def bias_variable(shape):
initial=tf.constant(0.1,shape=shape)
return tf.Variable(initial)
#定义二维的卷积图层
def conv2d(x,W):
return tf.nn.conv2d(x,W,strides=[1,1,1,1],padding='SAME')
#定义池化图层
def max_pool_2x2(x):
return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')权重weight和偏置bias其实可以写成python的输入量,但是TensorFlow有更好的处理方式,将weight和bias设置成为变量,即计算图中的一个值,这样使得它们能够在计算过程中使用,甚至进行修改。shape表示weight和bias的维度。
卷积使用1步长(strides[1, x_movement,y_movement, 1]),0边距(padding)的模板,保证输出和输入是同一个大小。padding:边距处理,“SAME”表示输出图层和输入图层大小保持不变,设置为“VALID”时表示舍弃多余边距(会丢失信息)。
池化用简单传统的2x2大小的模板做max pooling, 取切片中的最大值 。
占位符:
x=tf.placeholder(tf.float32,shape=[None,image_size])
y_=tf.placeholder(tf.float32,shape=[None,labels_count])我们通过为输入图像和目标输出类别创建节点,来开始构建计算图。
这里的x和y并不是特定的值,相反,他们都只是一个占位符,可以在TensorFlow运行某一计算时根据该占位符输入具体的值。
输入图片x是一个2维的浮点型张量。这里,它的shape为[None, 784],其中784是一张展平的数字图片的维度。None表示无论输入多少样本数据都可以,在这里作为第一个维度值,用以指代batch的大小,意即x的数量不定。输出类别值y_也是一个2维张量,其中每一行是一个10维的one-hot向量,用于代表对应某一数字图片的类别。
第一层卷积:
W_conv1=weight_variable([5,5,1,32])
#即输入图像的厚度由1增加到32
b_conv1=bias_variable([32])
#bias的厚度与weight输出通道数量相同
image=tf.reshape(x,[-1,image_width,image_height,1])
h_conv1=tf.nn.relu(conv2d(image,W_conv1)+b_conv1)
#图层的大小为28*28*32
h_pool1=max_pool_2x2(h_conv1)
#图层的大小为14*14*32第一层卷积层由一个卷积和一个最大池化完成。卷积在每个5x5的patch中算出32个特征。卷积的权重张量形状是[5, 5, 1, 32],前两个维度是patch的大小,接着是输入的通道数目,最后是输出的通道数目。 而对于每一个输出通道都有一个对应的偏置量。
在调用数据前,需要将原图变换为4维:第一维的-1表示数据是黑白的,其第2、第3维对应图片的宽、高,最后一维代表图片的颜色通道数(因为是灰度图所以这里的通道数为1,如果是RGB彩色图,则为3);注意这里的reshape是tf里的属性,而不是numpy里的。
第二层卷积:
W_conv2=weight_variable([5,5,32,64])
#输入图像的厚度由32增加到64
b_conv2=bias_variable([64])
#bias的厚度与weight相同
h_conv2=tf.nn.relu(conv2d(h_pool1,W_conv2)+b_conv2)
#图层的大小为14*14*64
h_pool2=max_pool_2x2(h_conv2)
#图层的大小为7*7*64第二层卷积切片的patch为5*5大小,输入32个通道,输出64个通道。第一层卷积输出32个通道,第二层卷积输出64个通道,32和64的数值是主观自定义的。
全连接层:
#第一层全连接层
W_fc1=weight_variable([7*7*64,1024])
b_fc1=bias_variable([1024])
h_pool2_flat=tf.reshape(h_pool2,[-1,7*7*64])
h_fc1=tf.nn.relu(tf.matmul(h_pool2_flat,W_fc1)+b_fc1)
#增加dropout,避免过拟合
keep_prob=tf.placeholder(tf.float32)
h_fc1_drop=tf.nn.dropout(h_fc1,keep_prob)
#第二层全连接层
W_fc2=weight_variable([1024,labels_count])
b_fc2=bias_variable([labels_count])
y=tf.nn.softmax(tf.matmul(h_fc1_drop,W_fc2)+b_fc2)
#训练输出的y为1*10的向量在卷积层之后,首先加入一个有1024个神经元的全连接层,用于处理整个图片。当然,需要先将池化层输出的张量reshape成1024维(数值1024是主观选择的,无相关控制因素)
dropout本质上主要是屏蔽神经元的输出,keep_prob是不屏蔽的比例,例如:每次随机删除20%,那么keep_prob就是0.8
代价函数、训练模型、评估模型:
#代价函数
cross_entropy = -tf.reduce_sum(y_*tf.log(y))
#优化函数
train_step = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy)
#评估模型
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, 'float'))
predict=tf.argmax(y,1)为了进行训练,会用更加复杂的AdamOptimizer来做梯度最速下降。
tf.argmax(y,1)输出参数指定的维度中的最大值的索引,tf.argmax(y_,1)是实际的标签,通过tf.equal方法可以比较预测结果与实际结果是否相等,输出布尔值。
tf.cast将布尔值转换成浮点数,如:[True, False, True, True]会转换成[1,0,1,1],其平均值0.75代表了预测的准确比例
定义next_batch函数,以便自动更迭下一个batch的数据样本:
epochs_completed = 0
index_in_epoch = 0
num_examples = train_images.shape[0]
# serve data by batches
def next_batch(batch_size):
global train_images
global train_labels
global index_in_epoch
global epochs_completed
start = index_in_epoch
index_in_epoch += batch_size
if index_in_epoch > num_examples:
# finished epoch
epochs_completed += 1
# shuffle the data
perm = np.arange(num_examples)
np.random.shuffle(perm)
#np.random.shuffle表示将括号内数组随机打乱
train_images = train_images[perm]
train_labels = train_labels[perm]
# start next epoch
start = 0
index_in_epoch = batch_size
#在开发一个程序时候,与其让它运行时崩溃,不如在它出现错误条件时就崩溃(返回错误)
end = index_in_epoch
return train_images[start:end], train_labels[start:end]初始化tensorflow框架的变量:
sess = tf.Session()
sess.run(tf.initialize_all_variables())Tensorflow依赖于一个更高效的C++后端来进行数值计算,与后端的这个连接叫做session。由于来回切换Python内、外环境需要不小的开销,所以我们借助python构建可以在外部运行的计算图,然后在session中启动它,让它在Python外部运行。
为了方便下文,也可以写成sess = tf.InteractiveSession(),意味着将自己作为默认构建的session,tensor.eval()和operation.run()就会调用这默认的session
训练和评估模型:
train_accuracies = []
validation_accuracies = []
x_range = []
for i in range(training_iterations):
batch_xs, batch_ys = next_batch(batch_size)
if i % 100 == 0:
train_accuracy = accuracy.eval(session = sess, feed_dict={x: batch_xs, y_: batch_ys, keep_prob: 1.0})
#如果初始化时是sess = tf.InteractiveSession(),那么这句和validation_accuracy里的session = sess就可以省略了
validation_accuracy = accuracy.eval(session = sess,feed_dict={ x: validation_images[0:batch_size], y_: validation_labels[0:batch_size], keep_prob: 1.0})
validation_accuracies.append(validation_accuracy)
train_accuracies.append(train_accuracy)
x_range.append(i)
print('train_accuracy / validation_accuracy => %.2f / %.2f for step %d'%(train_accuracy, validation_accuracy, i))
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys, keep_prob: dropout})一次training_iteration的样本数量就是batch_size的大小,所以i每加1,next_batch函数就作用一次,batch_xs, batch_ys就变更为下一个50的测试样本。
训练中间过程的日志如下:
WARNING:tensorflow:From :3 in .: initialize_all_variables (from tensorflow.python.ops.variables) is deprecated and will be removed after 2017-03-02.
Instructions for updating:
Use tf.global_variables_initializer instead.
train_accuracy / validation_accuracy => 0.10 / 0.14 for step 0
train_accuracy / validation_accuracy => 0.80 / 0.78 for step 100
train_accuracy / validation_accuracy => 0.94 / 0.90 for step 200
train_accuracy / validation_accuracy => 0.92 / 0.88 for step 300
train_accuracy / validation_accuracy => 0.86 / 0.92 for step 400
train_accuracy / validation_accuracy => 0.98 / 0.90 for step 500
train_accuracy / validation_accuracy => 0.94 / 0.94 for step 600
train_accuracy / validation_accuracy => 0.88 / 0.90 for step 700
train_accuracy / validation_accuracy => 0.96 / 0.90 for step 800
train_accuracy / validation_accuracy => 0.98 / 0.92 for step 900
train_accuracy / validation_accuracy => 1.00 / 0.94 for step 1000
train_accuracy / validation_accuracy => 1.00 / 0.96 for step 1100
train_accuracy / validation_accuracy => 0.94 / 0.96 for step 1200
train_accuracy / validation_accuracy => 1.00 / 0.94 for step 1300
train_accuracy / validation_accuracy => 0.94 / 0.98 for step 1400
train_accuracy / validation_accuracy => 1.00 / 0.98 for step 1500
train_accuracy / validation_accuracy => 0.92 / 1.00 for step 1600
train_accuracy / validation_accuracy => 0.96 / 0.98 for step 1700
train_accuracy / validation_accuracy => 0.96 / 0.98 for step 1800
train_accuracy / validation_accuracy => 0.98 / 0.98 for step 1900
#训练和验证的准确率,并作图显示
if(validation_size):
validation_accuracy = accuracy.eval(session = sess,feed_dict={x: validation_images, y_: validation_labels, keep_prob: 1.0})
print('validation_accuracy => %.4f'%validation_accuracy)
plt.plot(x_range, train_accuracies,'-b', label='Training')
plt.plot(x_range, validation_accuracies,'-g', label='Validation')
plt.legend(loc='lower right', frameon=False)
plt.ylim(ymax = 1.1, ymin = 0.7)
plt.ylabel('accuracy')
plt.xlabel('step')
plt.show()validation_accuracy => 0.9825
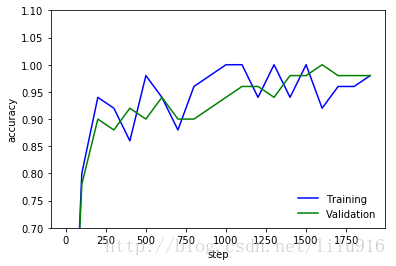
#导入测试数据
test_images=pd.read_csv('D://test.csv').values
test_images=test_images.astype(np.float)
#对测试数据进行归一化处理,从[0:255]=>[0:1]
test_images=np.multiply(test_images,1.0/255.0)
print('test_images({0[0]},{0[1]})'.format(test_images.shape))validation数据得到的模型精准度为0.9825,在训练迭代200次之后,数据的validation和train的精确度都高于90%,之后再波动上升。
使用训练好的模型识别数字:
predict_labels=np.zeros(test_images.shape[0])
for i in range(test_images.shape[0]//batch_size):
predict_labels[i*batch_size : (i+1)*batch_size] = predict.eval(session=sess,feed_dict={x: test_images[i*batch_size : (i+1)*batch_size],keep_prob: 1.0})
#显示实际数字图片和模型识别出的数字
display(test_images[image_to_display])
print('predict_label[{0}] is {1}'.format(image_to_display,predict_labels[image_to_display]))predict_label[10] is 5.0

我们从测试的数据集中画出了第10位手写数字是5,然后通过训练好的模型,识别出的数字也是5,准确的识别出来了,表明我们的识别手写数字模型训练的很成功。
留有的疑问:
在最后一段识别的代码块中,predict_labels的语句应该也可以写成:
predict_labels=sess.run(predict,feed_dict={x:test_images,keep_prob=1.0})这句应该与下一句都能设置predict_labels,但在Jupyter notebook里运行总是报错’invalid syntax’,还请各位大神不吝赐教。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









