







目录
估算和建模数据处理的内存需求
无论是数据处理管道还是科学计算,您通常需要了解您的进程需要多少内存:
- 如果您的内存不足,了解您是否只需要将笔记本电脑的内存从8GB升级到16GB,或者您的进程需要200GB内存并需要优化,这是很有帮助的。
- 如果您正在运行并行计算,您需要了解每个任务的内存需求,以便知道可以并行运行多少个任务。
- 如果您要扩展到多次运行,您需要估算硬件或云资源的成本。
在第一种情况下,您实际上无法测量峰值内存使用情况,因为您的进程内存不足。而在其他情况下,您可能会在不同的时间使用不同的输入,从而导致不同的内存需求。
因此,您真正需要的是一个模型,能够根据输入大小预测您的程序需要多少内存。让我们看看如何做到这一点。
测量峰值内存使用情况
在调查内存需求时,最重要的数字是峰值内存使用量。 如果您的进程在99.9%的时间内使用100MB内存,而在0.1%的时间内使用8GB内存,您仍然必须确保有8GB的内存可用。与CPU不同,如果内存不足,您的程序不会变慢——它会崩溃。
如何测量进程的峰值内存?
在Linux和macOS上,您可以使用标准的Python库模块resource:
from resource import getrusage, RUSAGE_SELF
print(getrusage(RUSAGE_SELF).ru_maxrss)
在Linux上,这将以KiB为单位测量,而在macOS上,它将以字节为单位测量,因此如果您的代码在两者上运行,您需要使其保持一致。
在Windows上,您可以使用psutil库:
import psutil
print(psutil.Process().memory_info().peak_wset)
这将返回以字节为单位的峰值内存使用量。
对于简单的情况,您可以在程序结束时打印该信息,您将获得峰值内存使用量。
估算和建模峰值内存使用情况
如果您无法实际运行程序完成,或者您期望多个输入大小对应不同的内存需求,该怎么办?这时您需要借助建模。
思路是测量一系列不同大小输入的内存使用情况。然后,您可以根据输入大小推断不同和/或更大数据集的内存使用情况。
让我们考虑一个例子,一个进行图像配准的程序,计算两幅相似图像在X、Y坐标上的偏移量。通常,我们预计内存使用量会随着图像大小的增加而增加,因此我们将调整程序以支持不同的图像大小,并在完成后报告峰值内存使用量:
import sys
from resource import getrusage, RUSAGE_SELF
import numpy as np
from skimage import data
from skimage.feature import register_translation
from scipy.ndimage import fourier_shift
from skimage.transform import rescale
# 加载并调整scikit-image中包含的示例图像大小:
image = data.camera()
image = rescale(image, int(sys.argv[1]), anti_aliasing=True)
# 将图像与自身配准;答案应始终为(0, 0),但这没关系,我们现在只关心内存使用情况。
shift, error, diffphase = register_translation(image, image)
print("Image size (Kilo pixels):", image.size / 1024)
print("Peak memory (MiB):", int(getrusage(RUSAGE_SELF).ru_maxrss / 1024))
然后,我们可以使用多个输入图像大小运行此程序:
$ python image-translate.py 1
Image size (Kilo pixels): 256.0
Peak memory (MiB): 116
$ python image-translate.py 2
Image size (Kilo pixels): 1024.0
Peak memory (MiB): 176
$ python image-translate.py 3
Image size (Kilo pixels): 2304.0
Peak memory (MiB): 277
$ python image-translate.py 4
Image size (Kilo pixels): 4096.0
Peak memory (MiB): 417
我们现在有以下内存使用:
| 千像素 | 峰值内存 (MiB) |
|---|---|
| 256 | 116 |
| 1024 | 176 |
| 2304 | 277 |
| 4096 | 417 |
建模内存使用情况
此时,我们对内存使用情况有了一个概念:有一个固定的最小值,仅用于运行Python和导入所有代码,然后随着像素数量的增加,内存似乎线性增长。
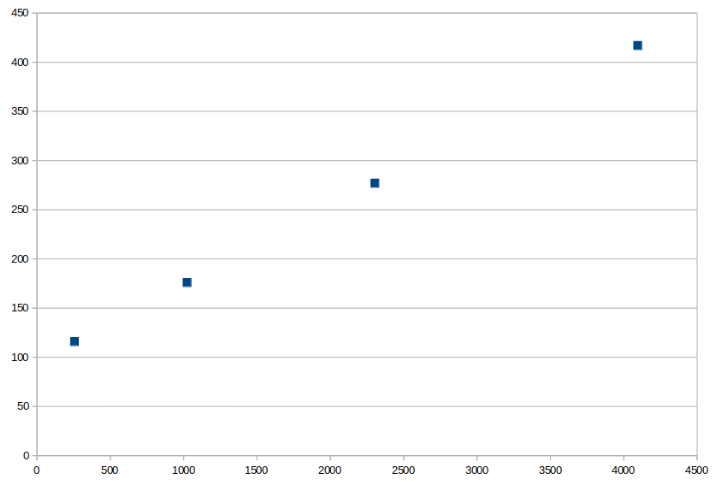
鉴于内存使用量似乎与输入呈线性关系,我们可以使用NumPy构建一个线性模型:
>>> import numpy as np
>>> np.polyfit([256, 1024, 2304, 4096], [116, 176, 277, 417], 1)
array([7.84278101e-02, 9.59186047e+01])
>>> def expected_memory_usage(image_pixels):
... return 7.84e-02 * (image_pixels / 1024) + 9.59e+01
...
>>> expected_memory_usage(256 * 1024)
115.97040000000001
>>> expected_memory_usage(4096 * 1024)
417.02639999999997
>>> expected_memory_usage(9999999 * 1024)
784095.8216
现在,您可以估算从微小到巨大的任何输入大小的内存使用量。
实际考虑
峰值驻留内存与峰值内存使用量不同
我们上面测量的是峰值时存储在RAM中的内存量。如果您的程序开始交换,将内存卸载到磁盘,峰值内存使用量可能高于驻留内存。
因此,如果您看到峰值驻留内存使用量趋于平稳,请小心,因为这可能是交换的迹象。您可以使用psutil来获取更广泛的当前内存使用情况,包括交换。但是,您需要在程序运行时在另一个线程或进程中轮询,因为这不会给您峰值值。
或者,只需确保您在具有足够RAM的计算机上收集估算值。
添加一个安全系数
虽然模型通常会给出合理的估计,但不要假设它是完全准确的。您需要将估计值增加10%或更多作为安全系数,因为实际内存使用量可能会有所不同。
换句话说,如果模型说您需要800MB内存,请确保有900MB可用。
内存使用量可能不是线性的
在许多情况下,峰值内存需求与输入大小呈线性关系。但并非总是如此:确保您的模型没有做出错误的假设,并且不会低估大输入的内存使用量。
何时考虑优化内存使用
一旦您对内存使用量如何随输入大小变化有了一个良好的估计,您就可以考虑硬件的成本估算,从而决定是否需要优化。
大数据集与比线性更快的内存需求曲线是一个糟糕的组合:至少您需要某种形式的批处理,但更改算法也可能是一个好主意。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











