






概述:
HA(High Available),高可用集群,是减少服务中断时间为目的的服务器集群技术。是保证业务连续性的有效解决方案。
集群,简单的来说就是一组计算机。一般有两个或者两个以上的计算机组成,这些组成集群的计算机被称为节点。
其中由两个节点组成的集群被称为双机热备,即使用两台服务器互相备份,当其中一台服务器出现问题时,
另一台服务器马上接管服务,来保护用户的业务程序对外不间断提供的服务,当然集群系统更可以支持两个以上的节点,
提供比双机热备更多、更高级的功能,把因软件/硬件/人为造成的故障对业务的影响降低到最小程度。
在集群中为了防止服务器出现“脑裂”的现象,集群中一般会添加Fence设备,有的是使用服务器本身的的硬件接口称为内部Fence,
有的则是外部电源设备称为外部Fence,当一台服务出现问题响应超时的时候,Fence设备会对服务器直接发出硬件管理指令,将服务器重启或关机,并向其他节点发出信号接管服务。
在红帽系统中我们通过luci和ricci来配置管理集群,其中luci安装在一台独立的计算机上或者节点上,luci只是用来通过web访问来快速的配置管理集群的,
它的存在与否并不影响集群。ricci是安装在每个节点上,它是luci与集群给节点通信的桥梁。
实验环境:
server1: 172.25.66.1 HA1 (高可用节点:ricci) , 管理节点(luci)
server2: 172.25.66.2 HA2 (高可用节点:ricci)
物理机: 172.25.66.254 fence端
防火墙状态:关闭
1.配置fence
1.配置yum源
#1.查看镜像文件
[root@foundation66 ~]# cd /var/www/html/rhel6.5
[root@foundation66 rhel6.5]# ls
#2.配置yum源
[root@server1 ~]# vim /etc/yum.repos.d/rhel-source.repo
#################
[HighAvailability] #高可用
name=HighAvailability
baseurl=http://172.25.66.254/rhel6.5/HighAvailability
gpgcheck=0
[LoadBalancer] #负载均衡
name=LoadBalancer
baseurl=http://172.25.66.254/rhel6.5/LoadBalancer
gpgcheck=0
[ResilientStorage] #存储
name=ResilientStorage
baseurl=http://172.25.66.254/rhel6.5/ResilientStorage
gpgcheck=0
[ScalableFileSystem] #文件系统
name=ScalableFileSystem
baseurl=http://172.25.66.254/rhel6.5/ScalableFileSystem
gpgcheck=0

#清理缓存
[root@server1 ~]# yum clean all

#3.列出yum源的详细信息,检测yum源是否配置成功
[root@server1 ~]# yum repolist

#4.传输yum源文件
[root@server1 ~]# scp /etc/yum.repos.d/rhel-source.repo root@172.25.66.2:/etc/yum.repos.d/
#清理缓存
[root@server2 ~]# yum clean all

#列出yum源的详细信息
[root@server2 ~]# yum repolist

2.安装ricci、luci软件并设定ricci用户密码
在server1上:
#1.安装软件,luci:图形管理界面 ricci:
[root@server1 ~]# yum install -y luci ricci
#查看到自动生成了ricci用户
[root@server1 ~]# cat /etc/passwd

#2.设定用户密码
[root@server1 ~]# passwd ricci

#3.开启ricci服务
[root@server1 ~]# /etc/init.d/ricci start

#4.开启luci服务
[root@server1 ~]# /etc/init.d/luci start

#查看端口
[root@server1 ~]# netstat -tnlp

#5.设定开机自动启动
[root@server1 ~]# chkconfig ricci on
[root@server1 ~]# chkconfig luci on
在serve2上:
#1.安装ricci软件
[root@server2 ~]# yum install -y ricci
#可查看到自动生成了ricci用户
[root@server2 ~]# cat /etc/passwd

#2.设定用户密码
[root@server2 ~]# passwd ricci

#3.开启ricci服务
[root@server2 ~]# /etc/init.d/ricci start

#4.设定开机自动启动
[root@server2 ~]# chkconfig ricci on
3.登陆并添加集群
输入: https:/172.25.66.1:8084 (luci的端口为8084)


登陆:(用server1的root用户登陆,因为luci图形管理器在server1结点上)

添加集群:




集群添加好后server1和server2会自动重启,从而断开ssh连接


4.检测集群是否添加成功
在server1上:
#1.重新连接
[root@foundation66 images]# ssh root@172.25.66.1
#2.查看集群配置
[root@server1 ~]# cat /etc/cluster/cluster.conf

注意:成功添加集群的前提是:必须先做好server1和server2主机上的解析
# 注意:一定要做好解析,因为写的都是主机名,而不是ip
[root@server1 ~]# cat /etc/hosts

#3.查看集群的状态
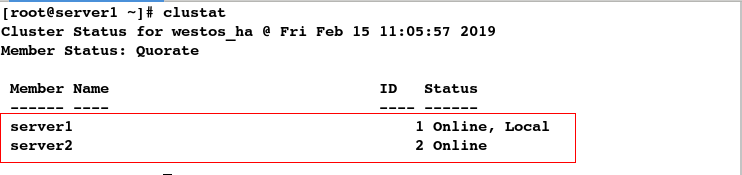
[root@server1 ~]# clustat
在server2上:
#1.重新连接
[kiosk@foundation66 ~]$ ssh root@172.25.66.2
#2.查看集群配置
[root@server2 ~]# cat /etc/cluster/cluster.conf

#3.查看集群的状态
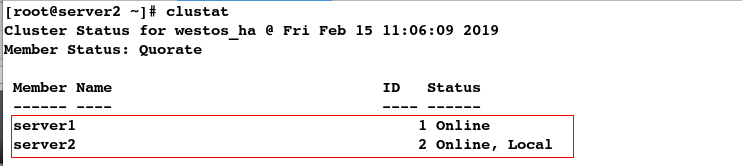
[root@server2 ~]# clustat
5.添加fence设备



6.安装fence和配置fence
在物理机上:
#1.安装fence
[root@foundation66 ~]# yum install -y fence-virtd.x86_64 fence-virtd-libvirt.x86_64 fence-virtd-multicast.x86_64
#2.配置fence
[root@foundation66 ~]# fence_virtd -c



7.生成key并发送key
在物理机上:
[root@foundation66 ~]# ll -d /etc/cluster
ls: cannot access /etc/cluster: No such file or directory
#1.建立目录
[root@foundation66 ~]# mkdir /etc/cluster
[root@foundation66 ~]# cd /etc/cluster/
#2.dd截取,生成key
[root@foundation66 cluster]# dd if=/dev/urandom of=/etc/cluster/fence_xvm.key bs=128 count=1
1+0 records in
1+0 records out
128 bytes (128 B) copied, 0.000204459 s, 626 kB/s
[root@foundation66 cluster]# ls
fence_xvm.key
# cat无法查看key
[root@foundation66 cluster]# cat fence_xvm.key

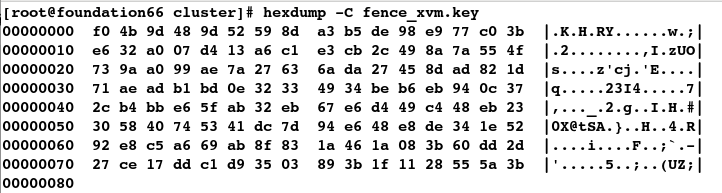
# hexdump方式便可查看key
[root@foundation66 cluster]# hexdump -C fence_xvm.key
#3.发送key
[root@foundation66 cluster]# scp fence_xvm.key root@172.25.66.1:/etc/cluster
root@172.25.66.1's password:
fence_xvm.key 100% 128 334.6KB/s 00:00
[root@foundation66 cluster]# scp fence_xvm.key root@172.25.66.2:/etc/cluster
root@172.25.66.2's password:
fence_xvm.key 100% 128 296.6KB/s 00:00
#4.查看key是否发送成功
[root@server1 ~]# cd /etc/cluster/
[root@server1 cluster]# ll
total 12
-rw-r----- 1 root root 322 Feb 15 11:09 cluster.conf
drwxr-xr-x 2 root root 4096 Sep 16 2013 cman-notify.d
-rw-r--r-- 1 root root 128 Feb 15 11:23 fence_xvm.key

[root@server2 ~]# cd /etc/cluster/
[root@server2 cluster]# ll
total 12
-rw-r----- 1 root root 322 Feb 15 11:09 cluster.conf
drwxr-xr-x 2 root root 4096 Sep 16 2013 cman-notify.d
-rw-r--r-- 1 root root 128 Feb 15 11:23 fence_xvm.key

8.关联HA结点和fence设备
关联server1结点:(HA1)






关联server2结点:(HA2)





9.开启fence服务
在物理机上:
[root@foundation66 cluster]# systemctl status fence_virtd.service

#开启fence服务
[root@foundation66 cluster]# systemctl start fence_virtd.service
[root@foundation66 cluster]# systemctl status fence_virtd.service

10.测试fence
#1.使server2重启
[root@server1 ~]# fence_node server2
fence server2 success
发现此时server2会重启

#2.重新连接
[kiosk@foundation66 ~]$ ssh root@172.25.66.2
root@172.25.66.2's password:
Last login: Fri Feb 15 11:02:19 2019 from 172.25.66.254
#3.查看集群状态,server2恢复正常
[root@server2 ~]# clustat
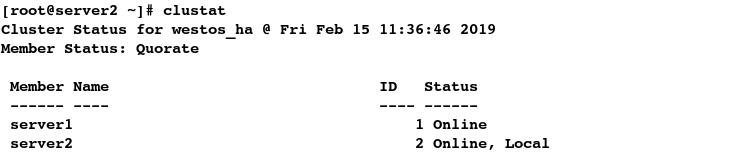
2.配置失败回切
1.配置故障切换


2.配置资源

添加vip:


添加脚本:设定自动启动(我这里用的是apache,也可以用nginx启动脚本)


3.配置apache服务
在server1上:
#1.安装apache
[root@server1 ~]# yum install -y httpd
#2.编写默认发布文件
[root@server1 ~]# cd /var/www/html/
[root@server1 html]# ls
[root@server1 html]# vim index.html
[root@server1 html]# cat index.html
server1
#3.开启apache服务
[root@server1 html]# /etc/init.d/httpd start
Starting httpd: httpd: Could not reliably determine the server's fully qualified domain name, using 172.25.66.1 for ServerName
[ OK ]

在server2上:
#1.安装apache
[root@server2 ~]# yum install -y httpd
#2.编写默认发布文件
[root@server2 ~]# cd /var/www/html/
[root@server2 html]# ls
[root@server2 html]# vim index.html
[root@server2 html]# cat index.html
server2
#3.开启apache服务
[root@server2 html]# /etc/init.d/httpd start
Starting httpd: httpd: Could not reliably determine the server's fully qualified domain name, using 172.25.66.2 for ServerName
[ OK ]

测试apache服务是否配置成功:
[root@foundation66 ~]# curl 172.25.66.1
server1
[root@foundation66 ~]# curl 172.25.66.2
server2

4.关闭apache服务
[root@server1 html]# /etc/init.d/httpd stop
Stopping httpd: [ OK ]
[root@server2 html]# /etc/init.d/httpd stop
Stopping httpd: [ OK ]
5.资源整合

注意:直接点击刚才添加过的vip:172.25.66.100/24和刚才添加过的启动脚本httpd即可将资源整合




Submit提交后,发现apache服务和vip在server2结点上
#1.查看apahce服务的状态
[root@server1 html]# /etc/init.d/httpd status
httpd is stopped
[root@server2 html]# /etc/init.d/httpd status
httpd (pid 10481) is running...
[root@foundation66 ~]# curl 172.25.66.1
curl: (7) Failed connect to 172.25.66.1:80; Connection refused
[root@foundation66 ~]# curl 172.25.66.2
server2
#2.查看集群的状态
[root@server1 html]# clustat

#3.查看vip
[root@server1 html]# ip a

#查看vip,发现vip在server2结点上
[root@server2 html]# ip a

6.模拟结点server2结点的脑裂:(内核崩溃)
注意:vip在哪个结点上就使哪个结点内核崩溃


脑裂后,发现server2结点自动重启,vip漂移到 server1结点上
[root@server1 html]# ip a

[root@foundation66 ~]# curl 172.25.66.100
server1
5秒钟后发现vip又自动回切到server2结点上
#1.重新登陆
[kiosk@foundation66 ~]$ ssh root@172.25.66.2
#2.查看vip,发现vip回切到server2结点上
[root@server2 ~]# ip a

3.添加存储
实验环境:
server3 服务端 :共享设备(scsi)
server1,server2 客户端 :发现设备 登陆(iscsi)
1.添加设备

[root@server3 ~]# fdisk -l

2.安装软件
#在服务端安装scsi
[root@server3 ~]# yum install -y scsi-*
#在客户端安装iscsi
[root@server1 html]# yum install -y iscsi-*
[root@server2 ~]# yum install -y iscsi-*
3.在服务端共享设备
#1.共享设备
[root@server3 ~]# vim /etc/tgt/targets.conf
#################
<target iqn.2019-02.com.example:server.target1>
backing-store /dev/vda
</target>

#2.开启服务
[root@server3 ~]# /etc/init.d/tgtd start
Starting SCSI target daemon: [ OK ]
#3.查看进程
[root@server3 ~]# ps ax

4.在客户端发现设备并登陆
在server1上:
#1.发现设备
[root@server1 html]# iscsiadm -m discovery -t st -p 172.25.66.3
Starting iscsid: [ OK ]
172.25.66.3:3260,1 iqn.2019-02.com.example:server.target1
#2.登陆设备
[root@server1 html]# iscsiadm -m node -l
Logging in to [iface: default, target: iqn.2019-02.com.example:server.target1, portal: 172.25.66.3,3260] (multiple)
Login to [iface: default, target: iqn.2019-02.com.example:server.target1, portal: 172.25.66.3,3260] successful.

#3.查看设备
[root@server1 html]# fdisk -l

在server2上:
#1.发现设备
root@server2 ~]# iscsiadm -m discovery -t st -p 172.25.66.3
Starting iscsid: [ OK ]
172.25.66.3:3260,1 iqn.2019-02.com.example:server.target1
#2.登陆设备
[root@server2 ~]# iscsiadm -m node -l
Logging in to [iface: default, target: iqn.2019-02.com.example:server.target1, portal: 172.25.66.3,3260] (multiple)
Login to [iface: default, target: iqn.2019-02.com.example:server.target1, portal: 172.25.66.3,3260] successful.

#3.查看设备
[root@server2 ~]# fdisk -l

问题:若分区被破坏,该如何恢复数据呢?
解决方案:只划分一个分区或是不分区
只划分一个分区:(在server1或server2上均可做此实验)
#1.创建分区
[root@server2 ~]# fdisk -cu /dev/sdb


#2.查看分区
[root@server2 ~]# cat /proc/partitions

#3.格式化
[root@server2 ~]# mkfs.ext4 /dev/sdb1

#4.挂载
[root@server2 ~]# mount /dev/sdb1 /mnt
[root@server2 ~]# df

#5.测试:发现可读可写
[root@server2 ~]# cd /mnt
[root@server2 mnt]# touch file
[root@server2 mnt]# rm -rf file
[root@server2 mnt]# cd
#6.卸载
[root@server2 ~]# umount /mnt
模拟分区被破坏:
#1.备份
[root@server2 ~]# dd if=/dev/sdb of=mbr bs=512 count=1
1+0 records in
1+0 records out
512 bytes (512 B) copied, 0.00183908 s, 278 kB/s
[root@server2 ~]# ls
anaconda-ks.cfg install.log install.log.syslog mbr
#2.破坏分区
[root@server2 ~]# dd if=/dev/zero of=/dev/sdb bs=512 count=1
1+0 records in
1+0 records out
512 bytes (512 B) copied, 0.00210575 s, 243 kB/s
#3.查看分区,发现消失
[root@server2 ~]# fdisk -l

#4.查看分区,发现分区/dev/vdb1还存在
[root@server2 ~]# cat /proc/partitions

此时分区尚且可以使用
#1.此时还可以挂载分区
[root@server2 ~]# mount /dev/sdb1 /mnt
[root@server2 ~]# df

#2.也可读可写
[root@server2 ~]# cd /mnt
[root@server2 mnt]# touch file
[root@server2 mnt]# rm -rf file
[root@server2 mnt]# cd
[root@server2 ~]# umount /mnt
但当系统重启后,分区便无法再继续使用
#1.重启系统
[root@server2 ~]# reboot
#2.重新连接
[kiosk@foundation66 ~]$ ssh root@172.25.66.2
#3.查看分区,发现分区消失
[root@server2 ~]# fdisk -l

#4.查看分区,发现分区消失
[root@server2 ~]# cat /proc/partitions

#5.挂载失败
[root@server2 ~]# mount /dev/sdb /mnt
mount: you must specify the filesystem type
恢复分区:
#1.恢复分区数据
[root@server2 ~]# dd if=mbr of=/dev/sdb
1+0 records in
1+0 records out
512 bytes (512 B) copied, 0.0339798 s, 15.1 kB/s
#2.查看分区,发现分区恢复
[root@server2 ~]# fdisk -l

#3.查看分区,发现分区未恢复
[root@server2 ~]# cat /proc/partitions

#4.进入分区,p查看分区
[root@server2 ~]# fdisk -cu /dev/sdb

#5.此时发现分区被恢复
[root@server2 ~]# cat /proc/partitions

如果未备份分区的情况下,分区被破坏便将无法恢复数据,故而最好的方式便是不分区
#删除分区
[root@server2 ~]# fdisk -cu /dev/sdb

#查看分区
[root@server2 ~]# cat /proc/partitions

5.配置mysql缓存
(1).后台管理存储
#1.安装mysql服务
[root@server1 html]# yum install -y mysql-server
#数据库存储数据目录为/var/lib/mysql/
[root@server1 ~]# ll /var/lib/mysql/
total 0
#安装mysql服务
[root@server2 ~]# yum install -y mysql-server
#2.格式化
[root@server1 ~]# mkfs.ext4 /dev/sdb

#3.将共享设备挂载到数据库的存储数据的目录上
[root@server1 ~]# mount /dev/sdb /var/lib/mysql/
#4.查看是否挂载成功
[root@server1 ~]# df

#发现数据不允许mysql用户可写
[root@server1 ~]# ll -d /var/lib/mysql/
drwxr-xr-x 3 root root 4096 Feb 15 17:10 /var/lib/mysql/
#5.更改文件的所有用户及组
[root@server1 ~]# chown mysql.mysql /var/lib/mysql/
[root@server1 ~]# ll -d /var/lib/mysql/
drwxr-xr-x 3 mysql mysql 4096 Feb 15 17:10 /var/lib/mysql/
#6.开启数据库服务
[root@server1 ~]# /etc/init.d/mysqld start

#7.查看到mysql.sock套接字(程序访问的入口)
[root@server1 ~]# cd /var/lib/mysql/
[root@server1 mysql]# ll
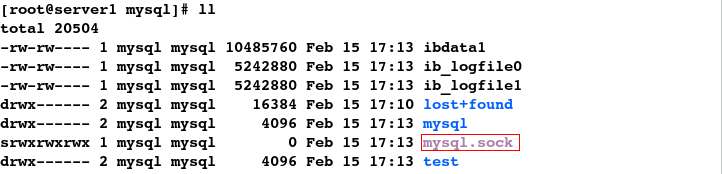
#8.发现此时无法卸载设备
[root@server1 mysql]# cd
[root@server1 ~]# umount /var/lib/mysql/

#9.发现此时可以登陆数据库
[root@server1 ~]# mysql

#10.将数据库服务关闭
[root@server1 ~]# /etc/init.d/mysqld stop
Stopping mysqld: [ OK ]
#11.查看到mysql.sock套接字消失
[root@server1 ~]# ll /var/lib/mysql/
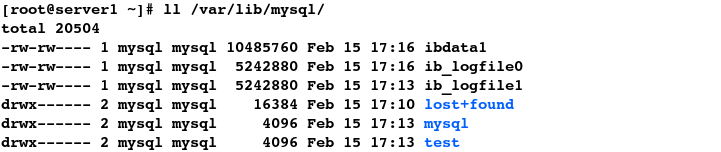
#12.此时便可以成功卸载设备
[root@server1 ~]# umount /var/lib/mysql/
(2).图形界面管理存储
1.关闭apache服务

2.添加资源

添加vip:

添加文件系统:

添加启动脚本:


3.添加故障切换


4.整合资源





发现新添加的vip和mysql服务都在server1结点上
#1.查看集群状态
[root@server1 ~]# clustat

#查看集群状态
[root@server2 ~]# clustat

#2.查看mysql服务的状态
[root@server1 ~]# /etc/init.d/mysqld status
mysqld (pid 29991) is running...
#查看mysql服务的状态
[root@server2 ~]# /etc/init.d/mysqld status
mysqld is stopped
#3.查看vip
[root@server1 ~]# ip a

#查看vip
[root@server2 ~]# ip a

开启apache服务后发现:mysql服务在server1结点上,apache服务在server2结点上
#1.开启apache服务(-e表示手动激活,-d表示手动关闭)
[root@server2 ~]# clusvcadm -e apache
Local machine trying to enable service:apache...Success
service:apache is now running on server2
[root@server2 ~]# clustat

#2.查看 vip
[root@server1 ~]# ip a

#查看 vip
[root@server2 ~]# ip a

手动将apache服务更改到server1结点上失败
#手动将apache服务更改到server1上,此时会时失败,由于设定了apache服务运行独占
[root@server2 ~]# clusvcadm -r apache -m server1
Trying to relocate service:apache to server1...Operation violates dependency rule
在图形上将运行独占关闭后,便可实现apache服务的转移


#1.手动将apache服务更改到server1上
[root@server2 ~]# clusvcadm -r apache -m server1
Trying to relocate service:apache to server1...Success
service:apache is now running on server1
#2.查看vip
[root@server1 ~]# ip a

排错:如果无法手动激活sql数据库服务怎么办(网页上也无法激活)?
[root@server1 ~]# clustat
Cluster Status for westos_ha @ Sat Feb 16 09:52:12 2019
Member Status: Quorate
Member Name ID Status
------ ---- ---- ------
server1 1 Online, Local, rgmanager
server2 2 Online, rgmanager
Service Name Owner (Last) State
------- ---- ----- ------ -----
service:apache server2 started
service:sql (server2) failed
#手动激活数据库服务失败
[root@server1 ~]# clusvcadm -e sql
Local machine trying to enable service:sql...Aborted; service failed
#先手动关闭数据库服务
[root@server1 ~]# clusvcadm -d sql
Local machine disabling service:sql...Success
#再重新激活数据库服务,然而仍然失败
[root@server1 ~]# clusvcadm -e sql
Local machine trying to enable service:sql...Failure
解决方案:
[root@server1 ~]# cd /var/lib/mysql/
[root@server1 mysql]# ll
total 0
[root@server1 mysql]# cat /proc/partitions
major minor #blocks name
8 0 20971520 sda
8 1 512000 sda1
8 2 20458496 sda2
253 0 19439616 dm-0
253 1 1015808 dm-1
8 16 8388608 sdb
#1.挂载
[root@server1 mysql]# mount /dev/sdb /var/lib/mysql/
[root@server1 mysql]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/vg_foundation62-lv_root 19134332 1137048 17025304 7% /
tmpfs 380152 25656 354496 7% /dev/shm
/dev/sda1 495844 33448 436796 8% /boot
/dev/sdb 8256952 170960 7666564 3% /var/lib/mysql
#2.查看数据库的存储目录
[root@server1 mysql]# cd /var/lib/mysql/
#3.发现问题:有mysql.sock套接字,但数据库的状态为关闭状态
[root@server1 mysql]# ll
total 20504
-rw-rw---- 1 mysql mysql 10485760 Feb 15 17:16 ibdata1
-rw-rw---- 1 mysql mysql 5242880 Feb 15 17:41 ib_logfile0
-rw-rw---- 1 mysql mysql 5242880 Feb 15 17:13 ib_logfile1
drwx------ 2 mysql mysql 16384 Feb 15 17:10 lost+found
drwx------ 2 mysql mysql 4096 Feb 15 17:13 mysql
srwxrwxrwx 1 mysql mysql 0 Feb 15 17:41 mysql.sock
drwx------ 2 mysql mysql 4096 Feb 15 17:13 test
[root@server1 mysql]# /etc/init.d/mysqld status
mysqld is stopped
#4.解决方案:先将套接字删除,再卸载,然后重新激活即可
[root@server1 mysql]# rm -rf mysql.sock
[root@server1 mysql]# cd
#卸载
[root@server1 ~]# umount /dev/sdb
#手动开启数据库服务
[root@server1 ~]# clusvcadm -e sql
Local machine trying to enable service:sql...Success
service:sql is now running on server1
#此时集群状态便恢复正常
[root@server1 ~]# clustat
Cluster Status for westos_ha @ Sat Feb 16 09:57:45 2019
Member Status: Quorate
Member Name ID Status
------ ---- ---- ------
server1 1 Online, Local, rgmanager
server2 2 Online, rgmanager
Service Name Owner (Last) State
------- ---- ----- ------ -----
service:apache server2 started
service:sql server1 started
4.实现数据同步
将共享设备挂载后,发现两个结点并不能实现数据同步
#1.先将apache服务移回到server2结点上
[root@server1 ~]# clusvcadm -r apache -m server2
Trying to relocate service:apache to server2...Success
[root@server1 ~]# clustat

#2.数据库服务sql启动后会自动挂载
[root@server1 ~]# df

#3.server2结点需要手动挂载
[root@server2 ~]# mount /dev/sdb /var/lib/mysql/
[root@server2 ~]# df

#4.查看数据目录
[root@server2 ~]# cd /var/lib/mysql/
[root@server2 mysql]# ll
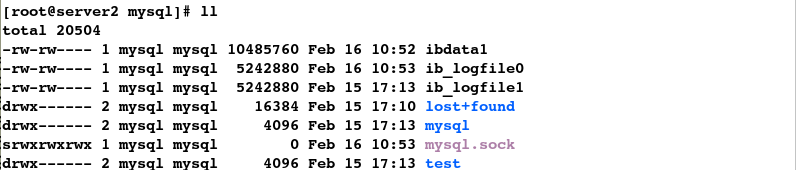
#5.复制文件到该数据目录下
[root@server2 mysql]# cp /etc/passwd .
[root@server2 mysql]# ll
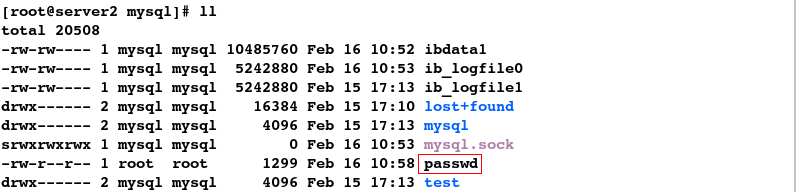
#6.发现数据并未同步,这样很不合理
[root@server1 ~]# cd /var/lib/mysql/
[root@server1 mysql]# ll
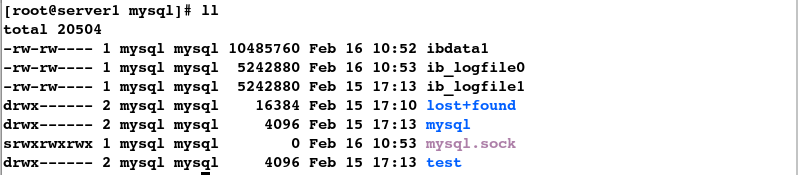
那么如何才能实现数据的同步呢?
首先,要实现存储功能除了使用iscsi技术以外,还可以使用lvm逻辑卷
1.卸载并关闭apache和sql服务
#1.卸载
[root@server2 mysql]# cd
[root@server2 ~]# umount /dev/sdb
[root@server2 ~]# df

#2.关闭apache服务
[root@server1 mysql]# clusvcadm -d apache
Local machine disabling service:apache...Success
#3.关闭sql服务;注意:关闭sql服务之前需要先卸载并关闭mysqld服务
[root@server1 ~]# /etc/init.d/mysqld stop
Stopping mysqld: [ OK ]
[root@server1 ~]# umount /dev/sdb
[root@server1 ~]# clusvcadm -d sql
Local machine disabling service:sql...Success
2.创建逻辑卷lvs
#1.查看设备
[root@server1 ~]# cat /proc/partitions

#2.创建物理卷
[root@server1 ~]# pvcreate /dev/sdb
Physical volume "/dev/sdb" successfully created
[root@server1 ~]# pvs
PV VG Fmt Attr PSize PFree
/dev/sda2 vg_foundation62 lvm2 a-- 19.51g 0
/dev/sdb lvm2 a-- 8.00g 8.00g

#发现server2结点同步有物理卷
[root@server2 ~]# pvs
PV VG Fmt Attr PSize PFree
/dev/sda2 vg_foundation62 lvm2 a-- 19.51g 0
/dev/sdb lvm2 a-- 8.00g 8.00g

#3.创建物理卷组
[root@server1 ~]# vgcreate clustervg /dev/sdb
Clustered volume group "clustervg" successfully created
[root@server1 ~]# vgs
VG #PV #LV #SN Attr VSize VFree
clustervg 1 0 0 wz--nc 8.00g 8.00g
vg_foundation62 1 2 0 wz--n- 19.51g 0

#发现server2结点同步有物理卷组
[root@server2 ~]# vgs
VG #PV #LV #SN Attr VSize VFree
clustervg 1 0 0 wz--nc 8.00g 8.00g
vg_foundation62 1 2 0 wz--n- 19.51g 0

#4.创建逻辑卷
[root@server1 ~]# lvcreate -L 4G -n demo clustervg
Logical volume "demo" created
[root@server1 ~]# lvs
LV VG Attr LSize Pool Origin Data% Move Log Cpy%Sync Convert
demo clustervg -wi-a----- 4.00g
lv_root vg_foundation62 -wi-ao---- 18.54g
lv_swap vg_foundation62 -wi-ao---- 992.00m

#发现server2结点同步有逻辑卷
[root@server2 ~]# lvs
LV VG Attr LSize Pool Origin Data% Move Log Cpy%Sync Convert
demo clustervg -wi-a----- 4.00g
lv_root vg_foundation62 -wi-ao---- 18.54g
lv_swap vg_foundation62 -wi-ao---- 992.00m

3.设备的伸缩及使用(非必要步骤)
(1).格式化设备
#格式化为ext4类型
[root@server1 ~]# mkfs.ext4 /dev/clustervg/demo

#查看设备参数
[root@server1 ~]# blkid

(2).拉伸逻辑卷设备
[root@server1 ~]# lvextend -L +4G /dev/clustervg/demo
Extending logical volume demo to 8.00 GiB
Insufficient free space: 1024 extents needed, but only 1023 available
[root@server1 ~]# lvextend -l +1023 /dev/clustervg/demo
Extending logical volume demo to 8.00 GiB
Logical volume demo successfully resized
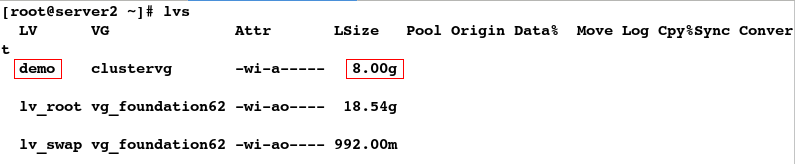
[root@server1 ~]# lvs
LV VG Attr LSize Pool Origin Data% Move Log Cpy%Sync Convert
demo clustervg -wi-a----- 8.00g
lv_root vg_foundation62 -wi-ao---- 18.54g
lv_swap vg_foundation62 -wi-ao---- 992.00m

#发现server2结点同步逻辑卷拉伸
[root@server2 ~]# lvs
LV VG Attr LSize Pool Origin Data% Move Log Cpy%Sync Convert
demo clustervg -wi-a----- 8.00g
lv_root vg_foundation62 -wi-ao---- 18.54g
lv_swap vg_foundation62 -wi-ao---- 992.00m
(3).检测文件系统并拉伸文件系统
#1.检测文件系统
[root@server1 ~]# e2fsck -f /dev/clustervg/demo

#2.拉伸文件系统
[root@server1 ~]# resize2fs /dev/clustervg/demo

(4).挂载
[root@server1 ~]# mount /dev/clustervg/demo /var/lib/mysql/
[root@server1 ~]# df

(5).卸载并删除逻辑卷
[root@server1 ~]# umount /var/lib/mysql/
[root@server1 ~]# lvremove /dev/clustervg/demo
Do you really want to remove active clustered logical volume demo? [y/n]: y
Logical volume "demo" successfully removed
[root@server1 ~]# lvs
LV VG Attr LSize Pool Origin Data% Move Log Cpy%Sync Convert
lv_root vg_foundation62 -wi-ao---- 18.54g
lv_swap vg_foundation62 -wi-ao---- 992.00m

(6).重新创建逻辑卷
[root@server1 ~]# lvcreate -L +4G -n demo clustervg
Logical volume "demo" created
[root@server1 ~]# lvs
LV VG Attr LSize Pool Origin Data% Move Log Cpy%Sync Convert
demo clustervg -wi-a----- 4.00g
lv_root vg_foundation62 -wi-ao---- 18.54g
lv_swap vg_foundation62 -wi-ao---- 992.00m

其次,mkfs.gfs2要实现数据的同步的前提是:
#1.clvmd服务为开启状态
[root@server1 ~]# /etc/init.d/clvmd status

#2.设定为3表示开启集群锁
[root@server1 ~]# vim /etc/lvm/lvm.conf

#注意:如果不是3,则需要手动设定
[root@server1 ~]# lvmconf --enable- cluster^C
4.利用gfs实现数据的同步
#1.查看集群名称
[root@server1 ~]# clustat

#2.gfs指定锁,同步数据;-p指定集群锁,-j日志数目,-t集群名称,mygfs2自定义名称
[root@server1 ~]# mkfs.gfs2 -p lock_dlm -j 2 -t westos_ha:mygfs2 /dev/clustervg/demo

#查看信息
[root@server1 ~]# gfs2_tool sb /dev/clustervg/demo all

#3.挂载
[root@server1 ~]# mount /dev/clustervg/demo /var/lib/mysql/
[root@server1 ~]# df

#4.更改文件所有用户和组
[root@server1 ~]# ll -d /var/lib/mysql/
drwxr-xr-x 2 root root 3864 Feb 16 12:05 /var/lib/mysql/
[root@server1 ~]# chown mysql.mysql /var/lib/mysql/
[root@server1 ~]# ll -d /var/lib/mysql/
drwxr-xr-x 2 mysql mysql 3864 Feb 16 12:05 /var/lib/mysql/
#5.在server2结点上也需要挂载设备
[root@server2 ~]# mount /dev/clustervg/demo /var/lib/mysql/
[root@server2 ~]# df

测试:
当只在server1结点上开启数据库服务,发现该结点上的套接字mysql.sock同步到了server2结点
#1.开启数据库服务
[root@server1 ~]# /etc/init.d/mysqld start

#2.可查看到mysql.sock套接字(数据库服务开启后自动生成)
[root@server1 ~]# cd /var/lib/mysql/
[root@server1 mysql]# ll

#3.查看到server2结点上的数据库服务为关闭状态,但发现数据目录中有mysql.sock套接字,这是由server1结点与server2结点发生了数据同步
[root@server2 ~]# /etc/init.d/mysqld status
mysqld is stopped
[root@server2 ~]# cd /var/lib/mysql/
[root@server2 mysql]# ll

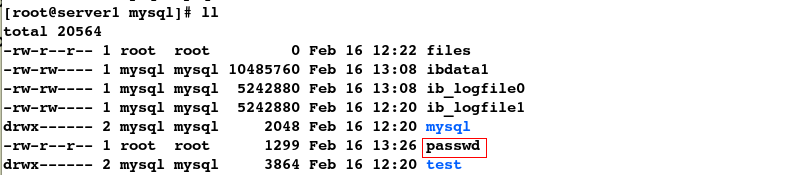
在server1结点的数据目录中直接建立文件,发现server2结点同步生成了该文件,进一步验证实现了数据同步
#1.建立文件
[root@server1 mysql]# touch files
[root@server1 mysql]# ll

#2.发现数据同步
[root@server2 mysql]# ll
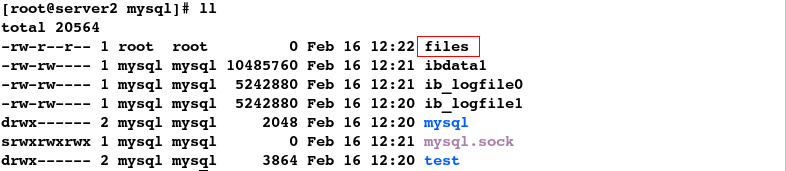
图形界面配置存储:
1.删除dbdata文件系统
注意:先删除整合资源中的文件系统,才能删掉dbdata,否则会报错:资源正在使用





可以直接在图形界面添加GFS2资源到集群中,但这样做很不方便
故而采用手动添加存储的方式
2.手动添加存储(设定自动开机挂载即可)
在server1上:
#1.关闭数据库
[root@server1 ~]# /etc/init.d/mysqld stop
Stopping mysqld: [ OK ]
[root@server1 ~]# df

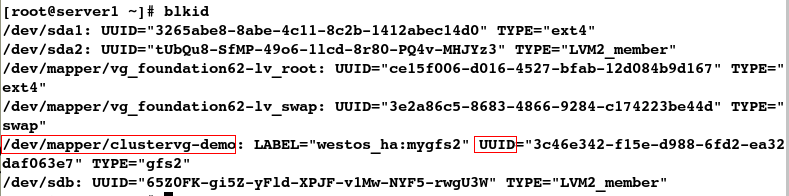
#2.查看UUID
[root@server1 ~]# blkid
#3.设定开机自动挂载
[root@server1 ~]# vim /etc/fstab
#################
UUID="3c46e342-f15e-d988-6fd2-ea32daf063e7" /var/lib/mysql gfs2 _netdev 0 0
UUID 挂载点 文件系统类型 网络设备 不检测不备份

#3.先卸载
[root@server1 ~]# umount /var/lib/mysql/
#4.检测开机自动挂载是否生效
[root@server1 ~]# mount -a
[root@server1 ~]# df

在server2上:(做相同的操作)
[root@server2 mysql]# df

#1.设定开机自动挂载
[root@server2 mysql]# vim /etc/fstab
###################
UUID="3c46e342-f15e-d988-6fd2-ea32daf063e7" /var/lib/mysql gfs2 _netdev 0 0

#2.先卸载
[root@server2 mysql]# cd
[root@server2 ~]# umount /var/lib/mysql/`在这里插入代码片`
#3.检测开机自动挂载是否生效
[root@server2 ~]# mount -a
[root@server2 ~]# df

测试:
[root@server2 ~]# cd /var/lib/mysql/
[root@server2 mysql]# ll

#1.拷贝文件
[root@server2 mysql]# cp /etc/passwd .
[root@server2 mysql]# ll
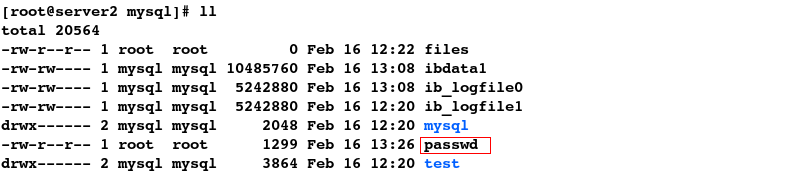
#2.查看到文件同步,即实现了数据同步
[root@server1 ~]# cd /var/lib/mysql/
[root@server1 mysql]# ll
#查看日志
[root@server1 mysql]# gfs2_tool journals /dev/clustervg/demo















 1934
1934











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









