







DataGrip这个零件实际在Pycharm和Idea中都有,就是从里面分离出来的专门处理数据库的零件,用这两个软件也可以实现以下操作。Sqlite属轻量级数据库,几万数据量用它应该足够了,而且内嵌在python中,即使以后用来做flask的数据库也是绰绰有余。我想要实现的是,一个表是武将的名单和身份证号,另一个表是武将的身份证号和效力国家,最终要导出的是武将的信息以及效力国家,且以武将名单为准。相应csv数据如图,如果修改的话,建议先新建excel文件,再打开csv,这样身份证号的科学计数法就可以被忽略,再另存为csv,utf-8编码。
在dataGrip中,在DataBase中新建DataSource->Sqlite,直接拖csv文件即可导入。


查询的话,必须对应身份证的前18位,因为有些身份证后面会多一些数字,那么用如下语句测试身份证的前18位:Substr(列名,起始位置,终了位置),起到切片的作用
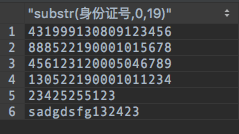
select substr(身份证号,0,19) from 三国武将效力查询结果:(第一个值,后来为了测试大小写,更改了)
最后可以用如下语句进行查询:
select * from 三国武将名单
left join 三国武将效力on
substr(三国武将名单.身份证号,0,19)=substr(三国武将效力.身份证号,0,19)*代表所有列,left join是左连接,on后面是条件,后面条件的意思是两列身份证号的前18位要对应。
结果如下,可以看到刘备的没有。

因为一个表刘备的身份证号的x是大写,另一个表是小写,所以需要在匹配的时候进行转换,用upper:
select * from 三国武将名单
left join 三国武将效力on
substr(upper(三国武将名单.身份证号),0,19)=substr(upper(三国武将效力.身份证号),0,19)结果如下:

















 3180
3180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











