







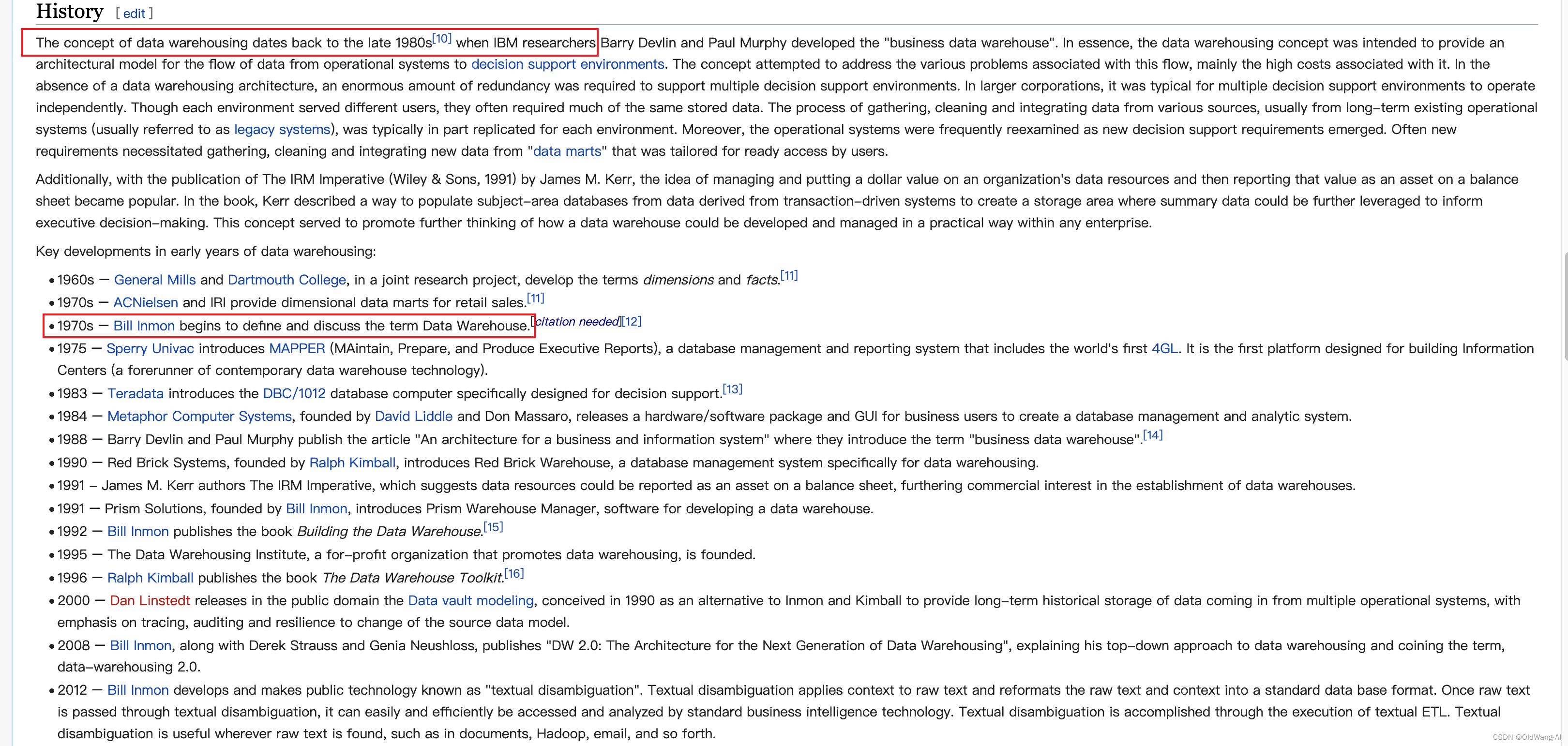
根据维基百科Data warehouse中的描述,数据仓库可以追溯到上个世纪70、80年代:
Bill Inmon在他的书《数据仓库》中说:
数据仓库是伴随着信息与决策支持系统的发展过程产生的,这种宽广的视野将有助于对数据仓库有一个更清晰的认识。
而,决策支持系统是信息技术长期复杂演化的产物,伴随着打孔卡、穿孔纸带、磁带、直接存取存储设备(DASD)等存储技术的发展而不断演化,随着DASD的发展,出现了一种称为数据库管理系统(Database Management System)的新型系统软件,它的目的是使程序员可以更方便地在DASD上存储和访问数据。这时候,人们把数据库做为所有处理工作的单一数据源,而不再需要顺序访问大量磁带了。70年代中期,在线事务处理(Online Transaction Processing,OLTP)使得访问数据可以更快速地进行,从而为商业和处理开辟了一种全新的视野。到了80年代,随着个人计算机(PC)和编程语言的发展,除了高性能在线事务处理之外,利用数据可以做更多的事情了,这种处理数据的系统就被称为决策支持系统。
这时,出现了以前无法想象的事情:企业各个部门开始各自直接控制数据和系统(以前都是留给专职数据处理人员),人们不断从大型在线事务处理系统“抽取”数据,分析并生成报表。对于一个公司或组织,存在各种数据库,这样就形成了一个失控的抽取处理模式,Bill Inmon称为:自然演化式体系结构,数据仓库就是解决这种失控问题的体系结构。这里,需要注意数据仓库的用户是谁,数据仓库的用户称为决策支持系统分析员,他首先是个商务人员,其次才是技术人员,他的主要工作是定义和发现在企业决策中使用的信息,他的想法通常是:给我看一下我想要的东西,然后我才能告诉你我真正想要什么。换句话说,他在发现模式下工作。
类似的,Kimball将企业所需的信息分成两个目的:操作型记录的保持和分析型决策的制定。操作性系统(operational systems)保存数据,而数据仓库系统使用数据。
亚马逊AWS官方博客上称这个时代为传统数据仓库时代,并把Inmon和Kimbal的方法分别称为自顶向下的和自底向上的。
到了1993年,被称为数据库之父的E.F. Codd在文章《Providing OLAP to User-Analysts:An IT Mandate》中定义了什么是OLAP。
2000年以后,互联网公司开始面对海量的数据处理需求。2005年,Mike Stonebrake在论文《“One Size Fits All”:An Idea Whose Times Has Come and Gone》中指出,OLTP和数据仓库最大的架构区别在于,数据仓库使用列(column)存储而不是行(row)存储,列存储更适合于全表扫描、多表联合查询。















 591
591











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









