







导语:
本次任务的主题是“实战案例–天池学习赛 工业蒸汽量预测”。
天池幸福感预测学习赛为长期赛,地址:https://tianchi.aliyun.com/competition/entrance/231693/information
学习链接:
集成学习: EnsembleLearning项目-github.
1. 基本思路
数据分成训练数据(train.txt)和测试数据(test.txt),其中字段”V0”-“V37”,这38个字段是作为特征变量,”target”作为目标变量。选手利用训练数据训练出模型,预测测试数据的目标变量,排名结果依据预测结果的MSE(mean square error)。
1.1 原始数据
经过数据基本信息查看,原始数据是没有缺失值和异常值的,所以我们第一种方案是直接对原始数据进行建模分析,采用RFR、LGB、XGB、GBDT、Ridge回归进行建模,然后再stack集成,但结果发现stack集成的效果极差!
实验记录:
随机森林线下0.1265,线上0.1325;LGB线下0.1114,线上0.1340
虽然线下stack的mse结果已经小于0.1了,但是线上的测试集的表现却极差;不只是stack出现了此类问题,在线下就连LGB单模效果比RFR好,但却在线上有反常的现象,可是线下数据已经经过5折交叉验证,应该说能很好地估计测试集了,说明另有原因。 这里主要考虑数据分布的问题,我们通过核密度检验,去除那些训练集和测试集分布不一致的特征,再看看效果。
1.2 去除分布不一致特征
分布检验_v2:
这里因为是传感器的数据,即连续变量,所以使用 kdeplot(核密度估计图) 进行数据的初步分析,即EDA。我们去除那些训练集和测试集分布不一致的特征,这可是导致线上线下差异较大的原因!
但从结果来看,即使使用10折交叉验证,还是没有改善线上线下不一致的问题!
1.3 特征工程
考虑对特征进行boxcox变换,改善正态性;
画相关系数矩阵图,去除相关性较低的特征;
去除outlines。
5折交叉验证建模:
5个模型采用平均效果最好:简单平均效果,线上0.1221!
stack集成学习之后,线上0.1278,还没有平均效果好。 是不是说明数据量较小的情况下,stack学不到规律?
2. 代码
import warnings
warnings.filterwarnings("ignore")
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
from scipy import stats
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV, RepeatedKFold, cross_val_score,cross_val_predict,KFold
from sklearn.metrics import make_scorer,mean_squared_error
from sklearn.linear_model import LinearRegression, Lasso, Ridge, ElasticNet
from sklearn.svm import LinearSVR, SVR
from sklearn.neighbors import KNeighborsRegressor
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor,AdaBoostRegressor
from xgboost import XGBRegressor
import lightgbm as lgb
import xgboost as xgb
from sklearn.ensemble import GradientBoostingRegressor as gbr
from sklearn.linear_model import Ridge
from sklearn.linear_model import Lasso
from sklearn.linear_model import LinearRegression as lr
from sklearn.kernel_ridge import KernelRidge as kr
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import KFold, StratifiedKFold,GroupKFold, RepeatedKFold
from sklearn.preprocessing import PolynomialFeatures,MinMaxScaler,StandardScaler
##数据准备
data_train = pd.read_csv('train.txt',sep = '\t')
data_test = pd.read_csv('test.txt',sep = '\t')
#合并训练数据和测试数据
data_train["oringin"]="train"
data_test["oringin"]="test"
data_all=pd.concat([data_train,data_test],axis=0,ignore_index=True)
#显示前5条数据
data_all.head()
#查看统计特征
data_all.describe()
# function to get training samples
def get_training_data():
# extract training samples
from sklearn.model_selection import train_test_split
df_train = data_all[data_all["oringin"]=="train"]
#df_train["label"]=data_train.target1
# split SalePrice and features
y = df_train.target
X = df_train.drop(["oringin","target"],axis=1)
X_train,X_valid,y_train,y_valid=train_test_split(X,y,test_size=0.3,random_state=2021)
return X_train,X_valid,y_train,y_valid
# extract test data (without SalePrice)
def get_test_data():
df_test = data_all[data_all["oringin"]=="test"].reset_index(drop=True)
return df_test.drop(["oringin","target"],axis=1)
from sklearn.metrics import make_scorer
# metric for evaluation
def rmse(y_true, y_pred):
diff = y_pred - y_true
sum_sq = sum(diff**2)
n = len(y_pred)
return np.sqrt(sum_sq/n)
def mse(y_ture,y_pred):
return mean_squared_error(y_ture,y_pred)
# scorer to be used in sklearn model fitting
rmse_scorer = make_scorer(rmse, greater_is_better=False)
#输入的score_func为记分函数时,该值为True(默认值);输入函数为损失函数时,该值为False
mse_scorer = make_scorer(mse, greater_is_better=False)
1.原始数据,未经任何处理_v1:
#数据划分
df_train = data_all[data_all["oringin"]=="train"]
X_train = df_train.drop(["oringin","target"],axis=1)
y_train = df_train.target
df_test = data_all[data_all["oringin"]=="test"].reset_index(drop=True)
X_test = df_test.drop(["oringin","target"],axis=1)
print(X_train.shape)
print(X_test.shape)
%%time
#RandomForestRegressor随机森林
folds = KFold(n_splits=5, shuffle=True, random_state=2021)
oof_rfr_v1 = np.zeros(len(X_train))
predictions_rfr_v1 = np.zeros(len(X_test))
for fold_, (trn_idx, val_idx) in enumerate(folds.split(X_train, y_train)):
print("fold n°{}".format(fold_+1))
tr_x = X_train.iloc[trn_idx]
tr_y = y_train.iloc[trn_idx]
rfr_v1 = RandomForestRegressor()
#verbose = 0 为不在标准输出流输出日志信息
#verbose = 1 为输出进度条记录
#verbose = 2 为每个epoch输出一行记录
rfr_v1.fit(tr_x,tr_y)
oof_rfr_v1[val_idx] = rfr_v1.predict(X_train.iloc[val_idx])
predictions_rfr_v1 += rfr_v1.predict(X_test) / folds.n_splits
print("CV score: {:<8.8f}".format(mse(y_train, oof_rfr_v1)))
%%time
#LGB默认参数
LGB = lgb.LGBMRegressor( objective='mse',metric= 'mse')
folds = KFold(n_splits=5, shuffle=True, random_state=4) #交叉切分:5
oof_lgb_v1 = np.zeros(len(X_train))
predictions_lgb_v1 = np.zeros(len(X_test))
for fold_, (trn_idx, val_idx) in enumerate(folds.split(X_train, y_train)):
print("fold n°{}".format(fold_+1))
LGB.fit(X_train.iloc[trn_idx], y_train.iloc[trn_idx])
oof_lgb_v1[val_idx] = LGB.predict(X_train.iloc[val_idx])
predictions_lgb_v1 += LGB.predict(X_test) / folds.n_splits
print("CV score: {:<8.8f}".format(mse(y_train, oof_lgb_v1)))
%%time
#xgboost
xgb_v1_params = {'eta': 0.02, #lr
'max_depth': 5,
'min_child_weight':3,#最小叶子节点样本权重和
'gamma':0, #指定节点分裂所需的最小损失函数下降值。
'subsample': 0.7, #控制对于每棵树,随机采样的比例
'colsample_bytree': 0.3, #用来控制每棵随机采样的列数的占比 (每一列是一个特征)。
'lambda':2,
'objective': 'reg:linear',
'eval_metric': 'rmse',
'silent': True,
'nthread': -1}
folds = KFold(n_splits=5, shuffle=True, random_state=2021)
oof_xgb_v1 = np.zeros(len(X_train))
predictions_xgb_v1 = np.zeros(len(X_test))
for fold_, (trn_idx, val_idx) in enumerate(folds.split(X_train, y_train)):
print("fold n°{}".format(fold_+1))
trn_data = xgb.DMatrix(X_train.iloc[trn_idx], y_train.iloc[trn_idx])
val_data = xgb.DMatrix(X_train.iloc[val_idx], y_train.iloc[val_idx])
watchlist = [(trn_data, 'train'), (val_data, 'valid_data')]
xgb_v1 = xgb.train(dtrain=trn_data, num_boost_round=3000, evals=watchlist, early_stopping_rounds=600, verbose_eval=500, params=xgb_v1_params)
oof_xgb_v1[val_idx] = xgb_v1.predict(xgb.DMatrix(X_train.iloc[val_idx]), ntree_limit=xgb_v1.best_ntree_limit)
predictions_xgb_v1 += xgb_v1.predict(xgb.DMatrix(X_test), ntree_limit=xgb_v1.best_ntree_limit) / folds.n_splits
print("CV score: {:<8.8f}".format(mse(y_train, oof_xgb_v1)))
%%time
#GradientBoostingRegressor梯度提升决策树
folds = KFold(n_splits=5, shuffle=True, random_state=2021)
oof_gbr_v1 = np.zeros(len(X_train))
predictions_gbr_v1 = np.zeros(len(X_test))
for fold_, (trn_idx, val_idx) in enumerate(folds.split(X_train, y_train)):
print("fold n°{}".format(fold_+1))
tr_x = X_train.iloc[trn_idx]
tr_y = y_train.iloc[trn_idx]
gbr_v1 = gbr(n_estimators=500, learning_rate=0.01,subsample=0.7,max_depth=9, min_samples_leaf=20,
max_features=0.2,verbose=1)
gbr_v1.fit(tr_x,tr_y)
oof_gbr_v1[val_idx] = gbr_v1.predict(X_train.iloc[val_idx])
predictions_gbr_v1 += gbr_v1.predict(X_test) / folds.n_splits
print("CV score: {:<8.8f}".format(mse(y_train, oof_gbr_v1)))
%%time
#Ridge回归
folds = KFold(n_splits=5, shuffle=True, random_state=2021)
oof_ridge_v1 = np.zeros(len(X_train))
predictions_ridge_v1 = np.zeros(len(X_test))
for fold_, (trn_idx, val_idx) in enumerate(folds.split(X_train, y_train)):
print("fold n°{}".format(fold_+1))
tr_x = X_train.iloc[trn_idx]
tr_y = y_train.iloc[trn_idx]
ridge_v1 = Ridge(alpha=1)
ridge_v1.fit(tr_x,tr_y)
oof_ridge_v1[val_idx] = ridge_v1.predict(X_train.iloc[val_idx])
predictions_ridge_v1 += ridge_v1.predict(X_test) / folds.n_splits
print("CV score: {:<8.8f}".format(mse(y_train, oof_ridge_v1)))
%%time
train_stack_v1 = np.vstack([oof_lgb_v1,oof_xgb_v1,oof_gbr_v1,oof_rfr_v1,oof_ridge_v1]).transpose()
# transpose()函数的作用就是调换x,y,z的位置,也就是数组的索引值
test_stack_v1 = np.vstack([predictions_lgb_v1, predictions_xgb_v1,predictions_gbr_v1,predictions_rfr_v1,predictions_ridge_v1]).transpose()
#交叉验证:5折,重复2次
folds_stack = RepeatedKFold(n_splits=5, n_repeats=2, random_state=2021)
oof_stack_v1 = np.zeros(train_stack_v1.shape[0])
predictions_lr_v1 = np.zeros(test_stack_v1.shape[0])
for fold_, (trn_idx, val_idx) in enumerate(folds_stack.split(train_stack_v1,y_train)):
print("fold {}".format(fold_))
trn_data, trn_y = train_stack_v1[trn_idx], y_train.iloc[trn_idx].values
val_data, val_y = train_stack_v1[val_idx], y_train.iloc[val_idx].values
#Kernel Ridge Regression
lr_v1 = kr()
lr_v1.fit(trn_data, trn_y)
oof_stack_v1[val_idx] = lr_v1.predict(val_data)
predictions_lr_v1 += lr_v1.predict(test_stack_v1) / 10
print("CV score: {:<8.8f}".format(mse(y_train, oof_stack_v1)))
##简单加权平均效果
y_mean = (0.3*oof_lgb_v1+0.3*oof_xgb_v1+0.2*oof_gbr_v1+0.1*oof_rfr_v1+0.1*oof_ridge_v1)
predictions_y_mean = (0.3*predictions_lgb_v1+0.3*predictions_xgb_v1+0.2*predictions_gbr_v1+0.1*predictions_rfr_v1+0.1*predictions_ridge_v1)
mse(y_train,y_mean)
2. 分布检验_v2:
for column in data_all.columns[0:-2]:
#核密度估计(kernel density estimation)是在概率论中用来估计未知的密度函数,属于非参数检验方法之一。通过核密度估计图可以比较直观的看出数据样本本身的分布特征。
g = sns.kdeplot(data_all[column][(data_all["oringin"] == "train")], color="Red", shade = True)
g = sns.kdeplot(data_all[column][(data_all["oringin"] == "test")], ax =g, color="Blue", shade= True)
g.set_xlabel(column)
g.set_ylabel("Frequency")
g = g.legend(["train","test"])
plt.show()
for column in ["V5","V9","V11","V14","V17","V21","V22"]:
g = sns.kdeplot(data_all[column][(data_all["oringin"] == "train")], color="Red", shade = True)
g = sns.kdeplot(data_all[column][(data_all["oringin"] == "test")], ax =g, color="Blue", shade= True)
g.set_xlabel(column)
g.set_ylabel("Frequency")
g = g.legend(["train","test"])
plt.show()
data_all.drop(["V5","V9","V11","V14","V17","V21","V22"],axis=1,inplace=True)
print(data_all.shape)
#数据划分
df_train = data_all[data_all["oringin"]=="train"]
X_train = df_train.drop(["oringin","target"],axis=1)
y_train = df_train.target
df_test = data_all[data_all["oringin"]=="test"].reset_index(drop=True)
X_test = df_test.drop(["oringin","target"],axis=1)
print(X_train.shape)
print(X_test.shape)



从以上的图中可以看出特征"V5",“V9”,“V11”,“V14”,“V17”,“V21”,"V22"中训练集数据分布和测试集数据分布不均,所以我们删除这些特征数据,在进行建模。
3. 特征工程_v3:
#查看特征之间的相关性
data_train1=data_all[data_all["oringin"]=="train"].drop("oringin",axis=1)
plt.figure(figsize=(20, 16)) # 指定绘图对象宽度和高度
colnm = data_train1.columns.tolist() # 列表头
mcorr = data_train1[colnm].corr(method="spearman") # 相关系数矩阵,即给出了任意两个变量之间的相关系数
mask = np.zeros_like(mcorr, dtype=np.bool) # 构造与mcorr同维数矩阵 为bool型
mask[np.triu_indices_from(mask)] = True # 角分线右侧为True
cmap = sns.diverging_palette(220, 10, as_cmap=True) # 返回matplotlib colormap对象,调色板
g = sns.heatmap(mcorr, mask=mask, cmap=cmap, square=True, annot=True, fmt='0.2f') # 热力图(看两两相似度)
plt.show()
#较相关性小的特征(小于阈值)删去,降维
threshold = 0.1
corr_matrix = data_train1.corr().abs()
drop_col=corr_matrix[corr_matrix["target"]<threshold].index
data_all.drop(drop_col,axis=1,inplace=True)
print(data_all.shape)
#归一化
cols_numeric=list(data_all.columns)
cols_numeric.remove("oringin")
def scale_minmax(col):
return (col-col.min())/(col.max()-col.min())
scale_cols = [col for col in cols_numeric if col!='target']
data_all[scale_cols] = data_all[scale_cols].apply(scale_minmax,axis=0)
data_all[scale_cols].describe()
# 进行Box-Cox变换
cols_transform=data_all.columns[0:-2]
for col in cols_transform:
# transform column
data_all.loc[:,col], _ = stats.boxcox(data_all.loc[:,col]+1)
print(data_all.target.describe())
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
sns.distplot(data_all.target.dropna() , fit=stats.norm);
plt.subplot(1,2,2)
_=stats.probplot(data_all.target.dropna(), plot=plt)
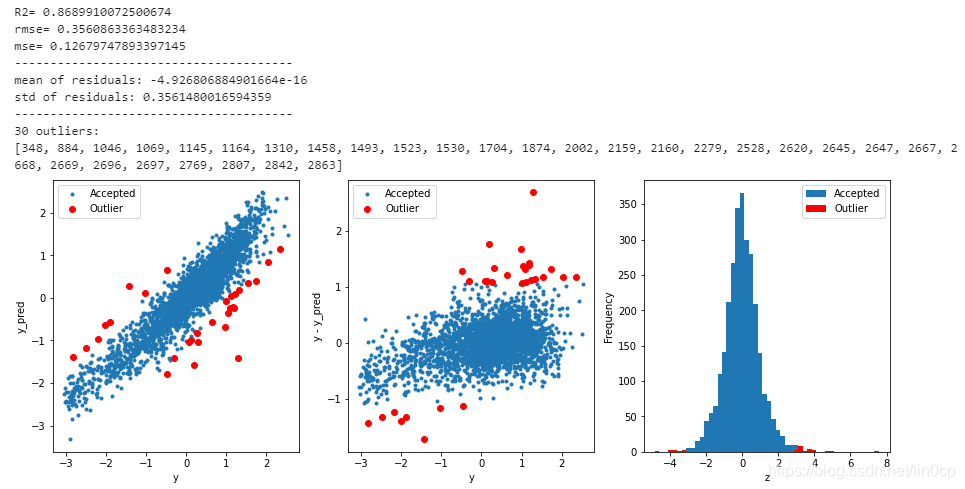
# function to detect outliers based on the predictions of a model
def find_outliers(model, X, y, sigma=3):
# predict y values using model
model.fit(X,y)
y_pred = pd.Series(model.predict(X), index=y.index)
# calculate residuals between the model prediction and true y values
resid = y - y_pred
mean_resid = resid.mean()
std_resid = resid.std()
# calculate z statistic, define outliers to be where |z|>sigma
z = (resid - mean_resid)/std_resid
outliers = z[abs(z)>sigma].index
# print and plot the results
print('R2=',model.score(X,y))
print('rmse=',rmse(y, y_pred))
print("mse=",mean_squared_error(y,y_pred))
print('---------------------------------------')
print('mean of residuals:',mean_resid)
print('std of residuals:',std_resid)
print('---------------------------------------')
print(len(outliers),'outliers:')
print(outliers.tolist())
plt.figure(figsize=(15,5))
ax_131 = plt.subplot(1,3,1)
plt.plot(y,y_pred,'.')
plt.plot(y.loc[outliers],y_pred.loc[outliers],'ro')
plt.legend(['Accepted','Outlier'])
plt.xlabel('y')
plt.ylabel('y_pred');
ax_132=plt.subplot(1,3,2)
plt.plot(y,y-y_pred,'.')
plt.plot(y.loc[outliers],y.loc[outliers]-y_pred.loc[outliers],'ro')
plt.legend(['Accepted','Outlier'])
plt.xlabel('y')
plt.ylabel('y - y_pred');
ax_133=plt.subplot(1,3,3)
z.plot.hist(bins=50,ax=ax_133)
z.loc[outliers].plot.hist(color='r',bins=50,ax=ax_133)
plt.legend(['Accepted','Outlier'])
plt.xlabel('z')
return outliers
#数据划分
df_train = data_all[data_all["oringin"]=="train"]
X_train = df_train.drop(["oringin","target"],axis=1)
# y_train = df_train.target
y_train = data_train.target
df_test = data_all[data_all["oringin"]=="test"].reset_index(drop=True)
X_test = df_test.drop(["oringin","target"],axis=1)
print(X_train.shape)
print(X_test.shape)
# find and remove outliers using a Ridge model
outliers = find_outliers(Ridge(), X_train, y_train)
X_outliers=X_train.loc[outliers]
y_outliers=y_train.loc[outliers]
X_t=X_train.drop(outliers)
y_t=y_train.drop(outliers)
##简单平均效果,线上0.1221
y_mean = (0.2*oof_lgb_v3+0.2*oof_xgb_v3+0.2*oof_gbr_v3+0.2*oof_rfr_v3+0.2*oof_ridge_v3)
predictions_y_mean = (0.2*predictions_lgb_v3+0.2*predictions_xgb_v3+0.2*predictions_gbr_v3+0.2*predictions_rfr_v3+0.2*predictions_ridge_v3)
mse(y_train,y_mean)
0.08993728011218466(线下),0.1221(线上),最好的效果
3. 总结
本次赛题的数据量偏小,模型的过拟合是最主要的问题,导致线上线下的得分差异巨大。在过滤掉一些训练集和测试集分布不一致的特征之后,这种线上线下差距得到改善。另外对模型效果有明显改善的是,对特征变量进行boxcox变换,并去除一些outlines。经实验,stack似乎不适合此类数据量较小的案例中,过拟合严重。
由于时间关系,本次实战没有对数据进行进一步的特征构建,若能深入了解工业传感器数据的特点,构建特征,挖掘有价值的信息,应该会带来性能的进一步提升。















 254
254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









