







一个学期已经结束了,通过这篇文章总结一下自己在CE方面所学习的内容。
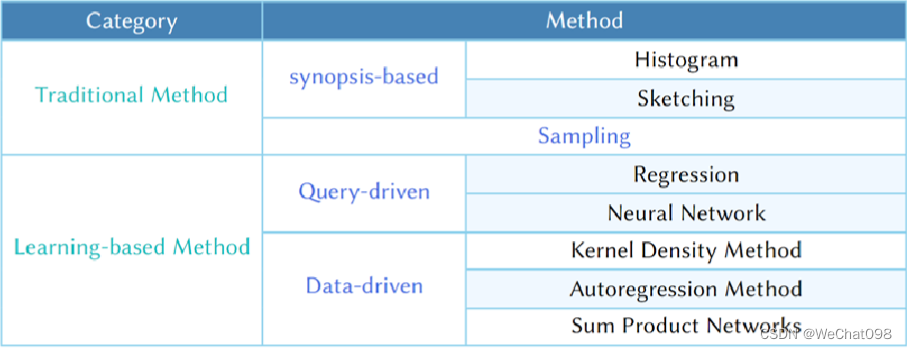
由于大数据技术的飞速发展,使数据库在查询方面面临很大的挑战。原来数据量不大的时候,查询可以在很快的时间内得到结果,但是现在动辄就是上万上千万甚至上亿的数据集,其执行时间可能根据处理查询方式的不同而存在很大的差异,从几分之一秒到几个小时不等。查询优化应运而生,查询优化是许多数据库领域的一个重要课题,查询优化是一个自动化的过程,它的目的是希望通过最少的时间来处理给定的查询。其中不同的查询处理策略对应不同的执行时间。 经过几十年的研究,最开始都是基于单表的研究,现在大家基于单表的研究基本上都可以取得比较好的结果,现在更多是基于多表的研究,但是基于多表的研究比单表要复杂很多,其中主要表现在相关性方面。 本文将方法大致分为两类,传统的方法和基于学习的方法,传统的方法中包含基于概要的方法和采样的方法。而对于后者基于学习的方法中也可以分为两类,查询驱动和数据驱动,其中基于查询驱动的方法包括基于回归的方法和NN网络的方法,而对于数据驱动中主要包含核密度估计的方法、自回归方法以及和乘网络的方法。
1. CE的定义
给定一个数据表 T,以及查询 Q,基数估计便是需要估计查询结果的大小。等价地,基数估计也可以表达为对查询选择性 (selectivity)的估计,这样最终的查询基数可通过选择性和整表大小的乘积得到。
2.方法分类及介绍
已经存在的的这些模型,分为传统的方法和基于Learning的方法:传统方法是依赖数学模型。learning的方法底层当然也是数学模型,因为learning的本质还是数学。但得益于AI/CV/NLP领域的快速发展,近几年涌现出来的各种各样的强大模型 也给数据库带来了新的思考机会。
Learning的基数估计基本可以分为三个方向:query-driven, data-driven and hybrid-driven (combine data and query)。
Query-driven就是从过去的查询query的样本总学习。思想就是有监督学习,当收集到了足够多的历史查询样本和其对应的cardinlity结果作为label。就可以借助当前各种强大模型去build up监督学习的模型。SIGMOD/VLDB在过去4年中涌现出来很多这个方向的paper。其实在近些年慢慢就越来越少出现基于query的文章了,因为基于Query的模型有自己天然的弱点,就是不能将表中间的附带的信息融入进去。
Data-driven就是从dataset中建立数据分布模型。思想就是无监督学习,但可以对一个数据集build up一个足够复杂的数据模型,从一定程度上也就描述出了之前提到的多表之间的数据相关性,模型可以意识到table A的一个key可能匹配table B的10w行数据。这个方向在SIGMOD/VLDB上 我觉得阿里达摩院的研究挺好的。
Hybrid-driven 比较好懂了, 就是把query样本的信息 和 dataset的信息同时利用起来。
2.1 基于回归的方法
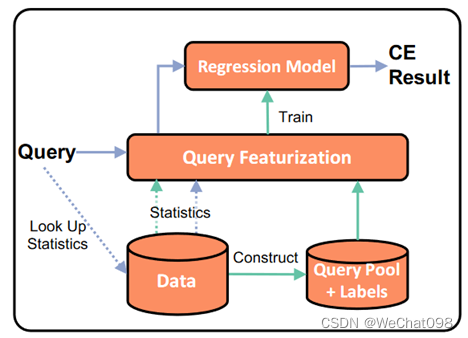
在训练阶段,首先构建一个查询池并获取每个查询对应的标签,然后通过查询特征化模块,将每个查询转换成特征向量。这些特征向量不仅包含查询信息,还可以选择性地包含数据中的一些统计信息。通过以上的这些信息得到一个学习器,最后通过这个学习器估计query 的果。 回归方法主要有四种:MSCN[4]、LW-XGB[1]、LW-NN[1]、DQM-Q[5],下面分别介绍这四种回归方法并介绍了每一种方法的具体执行方法。
2.1.1 MSCN[4]方法
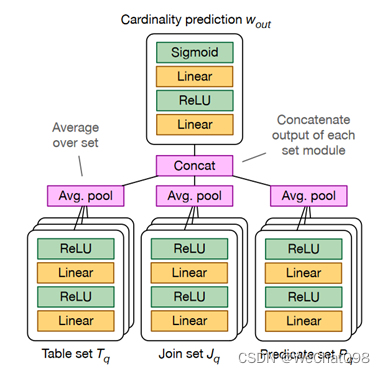
MSCN[4]是多集卷积网络的专用深度神经网络模型,MSCN[4] 可以支持连接基数估计。它将查询表示为包含三个模块(表、连接和谓词模块)的特征向量。每个模块都是一个双层神经网络,不同模块的输出被连接起来并送入最终输出网络,该网络也是一个双层神经网络。MSCN[4] 使用物化样本丰富训练数据。谓词将在样本和位图上进行评估,其中每个位表表示样本中的元组是否满足谓词,这被证明是非常有必要的[8,9]。
2.1.2 LW-XGB/NN[1]方法
由于 LW-XGB[1]方法和 NN[1]方法在实现的时候基本相似,所以这里将两者放在一起进行说明。LW-XGB/NN[1]方法引入了一种轻量级的选择性估计方法。它的特征向量由两部分组成:范围特征和CE 特征。范围特征表示一组范围谓词。CE 特征代表启发式估计器(例如,假设所有列都是独立的)。 这里面的 CE 特征可以从数据库系统中可用的统计信息中廉价地导出。LW-NN[1] (LW-XGB[1]) 使用生成的特征训练神经网络(梯度提升树)模型。与最小化均值 q 误差的 MSCN[4] 不同,它们最小化对数转换标签的均方误差(MSE),这等于最小化 q 误差的几何均值,对较大的误差具有更多的权重,并且也可以有效地计算。
2.1.3 DQM-Q[5]方法
DQM-Q[5]提出了一种不同的特征化方法。它使用单热编码对分类列进行编码,并通过自动离散化[10]将数值属性视为分类属性。DQM-Q[5]训练神经网络模型。当真实世界的查询工作负载可用时,DQM-Q[5] 能够扩充训练集并使用扩充集训练模型。
2.2 联合分布的方法
联合分布的方法在训练阶段,首先将数据转换为可用于训练联合分布模型的格式。在推理阶段,给定一个查询,然后生成一个或多个对模型的请求,并将模型推理结果组合成最终的 CE 结果。为了处理数据更新,联合分布方法需要更新或重新训练联合分布模型。 联合分布方式有 Naru[6]、DeepDB[7]、DQM-D[5]三种。与直方图和抽样等传统方法相比,这些新方法采用更复杂的模型来进一步捕获数据中的附加信息,例如列之间的细粒度相关性或条件概率。接下来将详细介绍联合分布的三种方法。
2.2.1 Naru[6]和DQM-D[5]方法
由于 Naru[6]和 DQM-D[5]方法有一定的相似性,所以这里就主要讲述 Naru[6]方法。Naru[6]使用乘积规则将联合分布分解为条件分布。Naru[6]采用最先进的深度自回归模型,如MADE 和Transformer 来近似联合分布。联合分布可以直接返回结果给点查询。为了支持范围查询,作者采用了基于抽样的方法,该方法以自适应方式运行重要性抽样。具体来说,Naru[6]使用了一种名为渐进采样的新型近似技术,它根据条件概率分布的每个内部输出逐列对值进行采样。
2.2.2 Sum-Product Network 方法
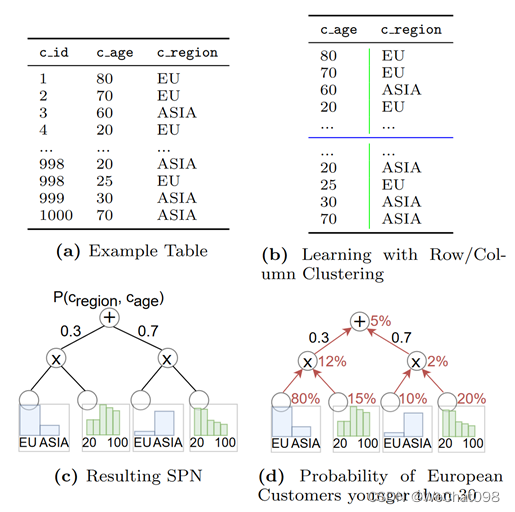
这个模型通过构建Sum-Product Network(SPN 树)来捕获联合概率分布[11],它的关键思想是递归地将表拆分为不同的行簇和列簇。通过行簇和列簇计算得到CE,在对行进行分割的时候可以使用 K-means 进行,在对列进行分割的时候需要考虑一些因素,也就是相关性,表中的有些列可能是相关的,这里使用皮尔逊相关性系数计算得到最后的结果,对比计算表中的任意两列,比较其中相关性最大的两列,然后将它们合并起来。
3、以上提到的这些是在现在已经应用的模型,目前的话觉得这些模型还是处于预研的状况,暂时还不能用于工用,离嵌入MySQL,PostgreSQL可能还是有一段距离的。
组内导师的指导方向还是很清晰明朗的。说一下大概的路线吧,开始是从清华大学李国良老师的AI Meets DB综述开始,全方面的讲述了 AI4DB and DB4AI的林林总总,之后将文中出现的模型找出来,看看所在的文章,在学习了这些模型之后,又看了一些范围稍微小点的综述,比如说是 Are We Ready For Learned Cardinality Estimation?" Proc. VLDB Endow. 14, 9 (2021), 1640–1654.,这篇详细讲述了上面提到的这些模型,并且指出了一些研究方向。之后比较好的一篇综述是 Leis, Viktor, Andrey Gubichev, Atanas Mirchev, Peter Boncz, Alfons Kemper, and Thomas Neumann. "How good are query optimizers, really?."Proceedings of the VLDB Endowment9, no. 3 (2015): 204-215.虽说是稍微早点的文章,但是看着觉得还是很有见解的。
想试试朝增量式更新的方向,但是在Are we ready文章出来之后就已经有做过相关的方向,也就是在之前文章中提到的FSPN,基于DeepDB中的SPN,其中提到了增量式更新,可能仅仅只是提到了这个,感觉并没有应用到这个方向,但是得到的效果还是挺好的。
4、寒假的话,打算先做其他的,打算把代码能力再提升一点,要不然在有想法的时候总是捉襟见肘。另外的话打算水一些算法吧,找一下之前的感觉,最后看看之前和师兄了解的方向。
[1] A. Dutt, C. Wang, A. Nazi, S. Kandula, V. R. Narasayya, and S. Chaudhuri.
Selectivity estimation for range predicates using lightweight models. Proc.
VLDB Endow., 12(9):1044–1057, 2019
[2] Z. Yang, E. Liang, A. Kamsetty, C. Wu, Y. Duan, P. Chen, P. Abbeel, J. M. Heller-
stein, S. Krishnan, and I. Stoica. Deep unsupervised cardinality estimation. Proc.
VLDB Endow., 13(3):279–292, 2019
[3] A. Dutt, C. Wang, A. Nazi, S. Kandula, V. R. Narasayya, and S. Chaudhuri.
Selectivity estimation for range predicates using lightweight models. Proc.
VLDB Endow., 12(9):1044–1057, 2019
[4] A. Kipf, T. Kipf, B. Radke, V. Leis, P. A. Boncz, and A. Kemper. Learned
cardinal-ities: Estimating correlated joins with deep learning. In CIDR 2019, 9th
BieNN[1]ialConference on INNovative Data Systems Research, Asilomar, CA,
USA, January13-16, 2019, Online Proceedings. www.cidrdb.org, 2019
[5] S. Hasan, S. Thirumuruganathan, J. Augustine, N. Koudas, and G. Das. Deep
learning models for selectivity estimation of multi-attribute queries. In Pro-
ceedings of the 2020 International Conference on Management of Data,
SIGMODConference 2020, online conference [Portland, OR, USA], June 14-19,
2020, pages1035–1050. ACM, 2020
[6] Z. Yang, E. Liang, A. Kamsetty, C. Wu, Y. Duan, P. Chen, P. Abbeel, J. M. Heller-
stein, S. Krishnan, and I. Stoica. Deep unsupervised cardinality estimation. Proc.
VLDB Endow., 13(3):279–292, 2019
[7] B. Hilprecht, A. Schmidt, M. Kulessa, A. Molina, K. Kersting, and C. BiNNig.
DeepDB: Learn from data, not from queries! Proc. VLDB Endow.,
13(7):992–1005,2020.
[8] A. Kipf, T. Kipf, B. Radke, V. Leis, P. A. Boncz, and A. Kemper. Learned
cardinal-ities: Estimating correlated joins with deep learning. In CIDR 2019, 9th
BieNNialConference on INNovative Data Systems Research, Asilomar, CA, USA,
January13-16, 2019, Online Proceedings. www.cidrdb.org, 2019
















 298
298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











