







由于目前的Web开发中AJAX、Javascript、CSS的大量使用,一些网站上的重要数据是由Ajax或Javascript动态生成的,并不能直接通过解析html页面内容就能获得(例如采用mechanize、lxml、Beautiful Soup )。要实现对这些页面数据的爬取,爬虫必须支持Javacript、DOM、HTML解析等一些浏览器html、javascript引擎的基本功能。
正如Web Browser Programming in Python总结的,在python程序中,有如下一些项目提供能类似功能:Pyv8 PythonWebKit PyWebKitGtk Python-Spidermonkey Selenium Windmill HulaHop Pamie Pyjamas 等等
其中Pyv8主要是Google Chrome V8 Javascript引擎的Python封装,侧重在Javacript操作上,并不是完整的Web Browser 引擎,而诸如PythonWebKit、Python-Spidermonkey、PyWebKitGtk等几个主要在Linux平台上比较方便,而HulaHop、Pamie处理MS IE 。因此从跨平台、跨浏览器、易用性等角度考虑,以上方案并不是最好的。
Selenium、Windmill 原本主要用于Web自动化测试上,对跨操作系统、跨浏览器有较好的支持。其对Javacript、DOM等操作的支持主要依赖操作系统本地的浏览器引擎来实现,因此爬虫所必须的大部分功能,Selenium、Windmill 都有较好的支持。在性能要求不高的情况下,可以考虑采用Selenium、Windmill的方案,从评价来看,Windmill比Selenium功能更加全面。
selenium是一个web的自动化测试工具,和其它的自动化工具相比来说其最主要的特色是跨平台、跨浏览器。支持windows、linux、MAC,支持ie、ff、safari、opera、chrome等。此外还有一个特色是支持分布式测试用例的执行,可以把测试用例分布到不同的测试机器的执行,相当于分发机的功能。
Selenium 自动化WEB访问的实现:

3. 点击右侧的红色按钮开始录制。需要注意的是启动selenium IDE后工具默认的就是开始录制

4. 打开百度输入”selenium ide”点击查询,整个步骤录制后如下。
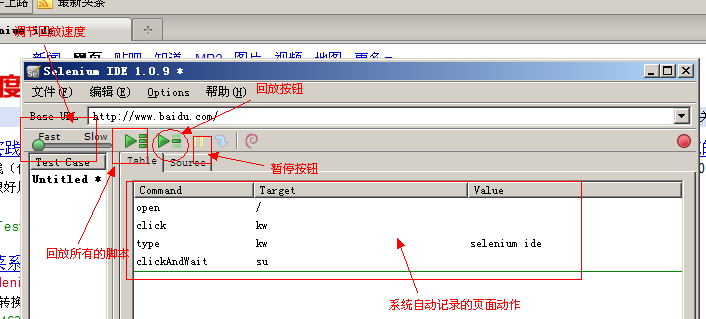
5. 可以点击回放一下。脚本回放成功为淡绿色,验证信息回放成功为深绿色

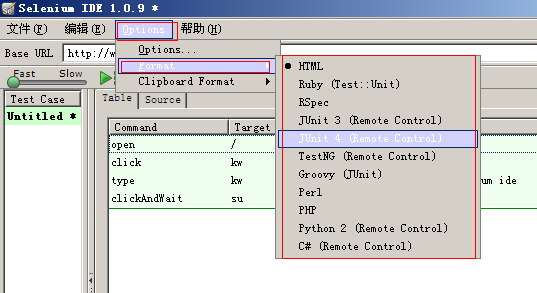
6. 工具默认将操作步骤记录为html格式,点击optionsèformat可以选择你要转化的语言。从这儿可以看出selenium的强大之处
7. 转化之后再source面板可以看到转化后的代码,如下图
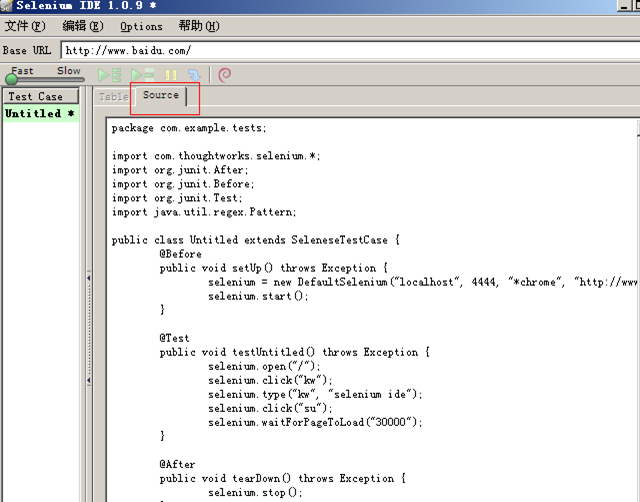
注意:有些版本selenium安装后,option->format中并没有显示可用的语言,需要修改下一个默认配置,具体官网上有详细截图说明
由此可以叫快捷获取到简单python实现登录的源代码,但真正需要python来实现,需要搭建python+selenium的测试环境:
1、下载并安装python(http://www.python.org/getit/,selenium暂时不支持python3,这里使用2.7.3版本)。
2、下载并安装setuptools(http://pypi.python.org/pypi/setuptools,这里使用setuptools-0.6c11.win32-py2.7版本)。
3、下载pip(http://pypi.python.org/pypi/pip,这里使用pip-1.2.1.tar.gz版本),解压缩之后,使用cmd命令:python setup.py install(如果python命令使用不成功,请配置下python的环境变量),打开cmd命令,进入python的scripts目录(比如c:\python27\scripts),输入easy_install pip。
4、安装selenium(http://pypi.python.org/pypi/selenium),联网的话直接使用pip安装,命令进入python的scripts目录,执行:pip install -U selenium;没联网的话,解压缩selenium-2.28.0.tar.gz. 把selenium整个文件夹放入Python27\Lib\site-packages目录下。
5、打开python的idle,运行如下脚本,看运行是否成功。
# coding=gbk
from selenium import webdriver
browser = webdriver.Firefox() # 打开火狐浏览器
browser.get("http://www.baidu.com") # 登录百度首页
以下是在网上找到一个基于selenium2的demo,用python脚本实现google搜索
#!/usr/bin/python
# -*- coding: gb2312 -*-
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support.ui import WebDriverWait # available since 2.4.0
import time
# Create a new instance of the Firefox driver
driver = webdriver.Chrome()
# go to the google home page
driver.get("http://www.google.com")
# find the element that's name attribute is q (the google search box)
inputElement = driver.find_element_by_name("q")
# type in the search
inputElement.send_keys("Cheese!")
# submit the form. (although google automatically searches now without submitting)
inputElement.submit()
# the page is ajaxy so the title is originally this:
print driver.title
try:
# we have to wait for the page to refresh, the last thing that seems to be updated is the title
WebDriverWait(driver, 10).until(lambda driver : driver.title.lower().startswith("cheese!"))
# You should see "cheese! - Google Search"
print driver.title
finally:
driver.quit()
#==================================















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









