







更新与2020-04-11
目前爬过的站点
b站,网易云音乐
B站
需求:
1.爬取外挂字幕
2.爬取up主信息
3. 获取弹幕https://api.bilibili.com/x/v1/dm/list.so?oid=122426590
4. 获取弹幕发送者的信息
网上爬取b站资料虽然很多,但是不如自己实操来的舒服。
B站防爬的策略
对于未登陆的请求,我给你缓存里面的数据,这样你伤不到我筋骨[筋骨就是关系型数据库]
只有登陆以后,我才给你最准确的数据
对于登陆的账号,不好意思,我是有请求次数和频率限制的
1. 爬取B站外挂cc字幕
import requests
url = "https://www.bilibili.com/video/BV1t7411z7ko?from=search"
payload = {}
headers = {
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1'
}
response = requests.request("GET", url, headers=headers, data = payload)
print(response.text.encode('utf8'))
一个问题是怎么把html中的指定字符提取出来?换一种问法就是爬虫获取网页后,想要获取网页中<script></script>下的某个变量的内容。
1.提取script中的内容,这一步容易
2.获取内容里面的指定模块,最后还是到了正则的地步
'window.__INITIAL_STATE__={"performance":{"startApiTime":0,"endApiTime":0},"common":{"userInfo":{"isLogin":false,"face":"//static.hdslb.com/images/member/noface.gif","vipStatus":0,"vipType":0},"performance":{"startAPITime":0,"endAPITime":0},"locsData":{}},"space":{"mid":0,"info":{"vip":{},"sys_notice":{}}},"flow":{},"video":{"aid":85551510,"bvid":"BV1t7411z7ko","p":1,"isClient":false,"viewInfo":{"bvid":"BV1t7411z7ko","aid":85551510,"videos":1,"tid":182,"tname":"影视杂谈","copyright":2,"pic":"http://i0.hdslb.com/bfs/archive/1c204a74f34ed7fcf47826b124ce672523e94635.jpg","title":"沉睡魔咒2花絮视频(外挂英文字幕)(Maleficent.Mistress.of.Evil.2019.Digital.Extras)","pubdate":1580278708,"ctime":1580278708,"desc":"www.youtube.com\nMaleficent.Mistress.of.Evil.2019.Digital.Extras.1080p.AMZN.WEB-DL.DDP5.1.H.264-N","state":0,"attribute":16640,"duration":1500,"rights":{"bp":0,"elec":0,"download":1,"movie":0,"pay":0,"hd5":1,"no_reprint":0,"autoplay":1,"ugc_pay":0,"is_cooperation":0,"ugc_pay_preview":0,"no_background":0},"owner":{"mid":38428817,"name":"浪迹48","face":"http://i1.hdslb.com/bfs/face/b597b49c23a41261cb8a798e487d46f1015cb080.jpg"},"stat":{"aid":85551510,"view":444,"danmaku":0,"reply":1,"favorite":12,"coin":1,"share":0,"now_rank":0,"his_rank":0,"like":10,"dislike":0,"evaluation":""},"dynamic":"#沉睡魔咒##美国##幕后#","cid":146221803,"dimension":{"width":1920,"height":1080,"rotate":0},"no_cache":false,"pages":[{"cid":146221803,"page":1,"from":"vupload","part":"Maleficent.Mistress.of.Evil.2019.Digital.Extras.1080p.AMZN.WEB-DL.DDP5.1.H.264-N","duration":1500,"vid":"","weblink":"","dimension":{"width":1920,"height":1080,"rotate":0}}],"subtitle":{"allow_submit":false,"list":[{"id":22065421844742148,"lan":"en-US","lan_doc":"英语(美国)","is_lock":false,"subtitle_url":"http://i0.hdslb.com/bfs/subtitle/8f14fe24ea2d3e916a96981eb04c64e66c01ddbf.json","author":{"mid":0,"name":"","sex":"","face":"","sign":"","rank":0,"birthday":0,"is_fake_account":0,"is_deleted":0}}]}},"playUrlInfo":[{"order":1,"length":1499499,"size":86942682,"ahead":"","vhead":"","url":"http://upos-hz-mirrorakam.akamaized.net/upgcxcode/03/18/146221803/146221803-1-16.mp4?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfq9rVEuxTEnE8L5F6VnEsSTx0vkX8fqJeYTj_lta53NCM=&uipk=5&nbs=1&deadline=1586955867&gen=playurl&os=akam&oi=2887205243&trid=eac79dcb0e44409aaa41d85d14200d3bh&platform=html5&upsig=9f43ee76aff41f51531ccd5eba798866&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,platform&hdnts=exp=1586955867~hmac=fe20fe9d65e4af0ee332512430e5b3780290fc773540e2dd5d0b89a1c9d81237&mid=0&logo=80000000","backup_url":null}],"playState":"init","error":0,"isNew":false},"tag":{"tagInfo":{},"tagSimilar":[]}}'

最后获取到的字幕地址
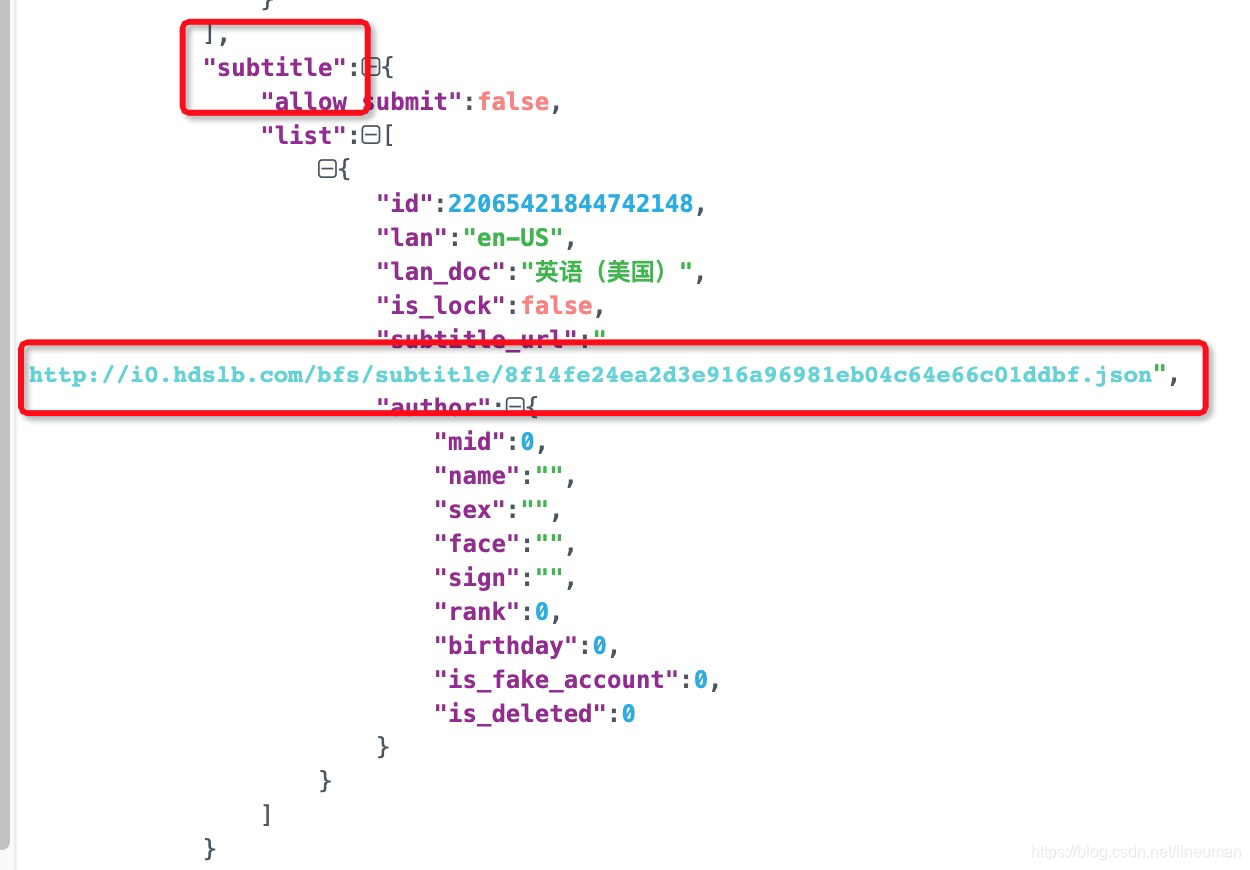
2.爬取up主信息
https://space.bilibili.com/7
https://space.bilibili.com/12
我想要做的就是看看b站用户名称的规律,所以我要获取所有用户的昵称信息。
发现user_id好像是自增的,那么是否可以暴力遍历,获取到所有用户的user_id呢?
问题:时间成本和存储成本
- 时间成本
python遍历1亿次本身是需要时间,大概需要5秒
python发送http请求需要时间,每个请求大约需要0.1秒的时间
如果单纯的串行,大概需要的时间为100000000 * 0.1/3600/24 = 115天 - 我需要数据库来存储数据
1亿行的mysql数据会有多大呢?
如果说mysql不适合那么mongodb适合吗?
爱B站,对开发者真的是友好,看看b站限速情况吧?纳尼?好像没有限速?我终于知道b站为什么爬不垮了,肯定是用了缓存,要不然数据库受不了的。
https://api.bilibili.com/
| 说明 | 请求方法 | 地址 |
|---|---|---|
| 个人信息接口 | get | https://api.bilibili.com/x/space/acc/info?mid=${userId}&jsonp=jsonp |
| 也是个人信息接口 | get | https://api.bilibili.com/x/web-interface/card?mid={mid} |
|
for i in range(1000, 1500):
time.sleep(0.03)
url = 'https://api.bilibili.com/x/space/acc/info?mid=%s&jsonp=jsonp' % i
r = requests.get(url)
print(r.json())
返回数据格式
code=0,代表用户存在
{'code': 0, 'message': '0', 'ttl': 1, 'data': {'mid': 1905, 'name': '青梅煮酒', 'sex': '保密', 'face': 'http://i1.hdslb.com/bfs/face/9dc28e96213281004645d990ea266b491b12e5db.jpg', 'sign': 'uid能代表什么,代表我老了ॱଳ͘', 'rank': 10000, 'level': 5, 'jointime': 0, 'moral': 0, 'silence': 0, 'birthday': '', 'coins': 0, 'fans_badge': False, 'official': {'role': 0, 'title': '', 'desc': '', 'type': -1}, 'vip': {'type': 1, 'status': 0, 'theme_type': 0}, 'pendant': {'pid': 452, 'name': '灵笼', 'image': 'http://i0.hdslb.com/bfs/face/9c5f14d6749daded668f3f66998baf4a50e7d8da.png', 'expire': 0}, 'nameplate': {'nid': 0, 'name': '', 'image': '', 'image_small': '', 'level': '', 'condition': ''}, 'is_followed': False, 'top_photo': 'http://i2.hdslb.com/bfs/space/cb1c3ef50e22b6096fde67febe863494caefebad.png', 'theme': {}, 'sys_notice': {}}}
code -404,代表用户不存在
{'code': -404, 'message': '啥都木有', 'ttl': 1, 'data': None}
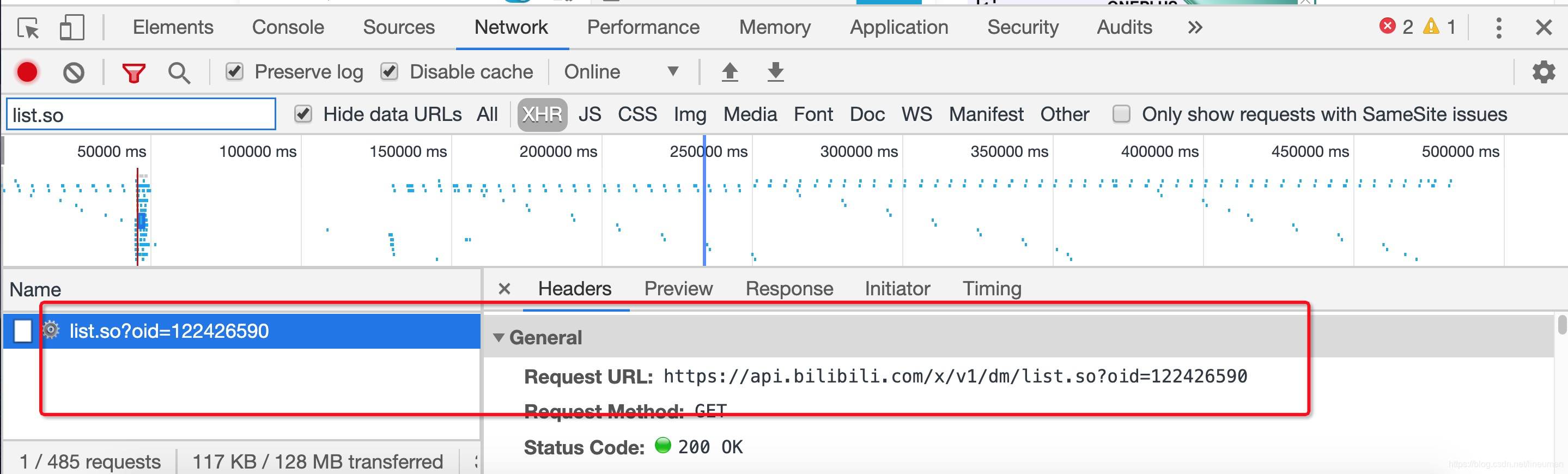
3.获取弹幕
接口地址
https://api.bilibili.com/x/v1/dm/list.so?oid=122426590
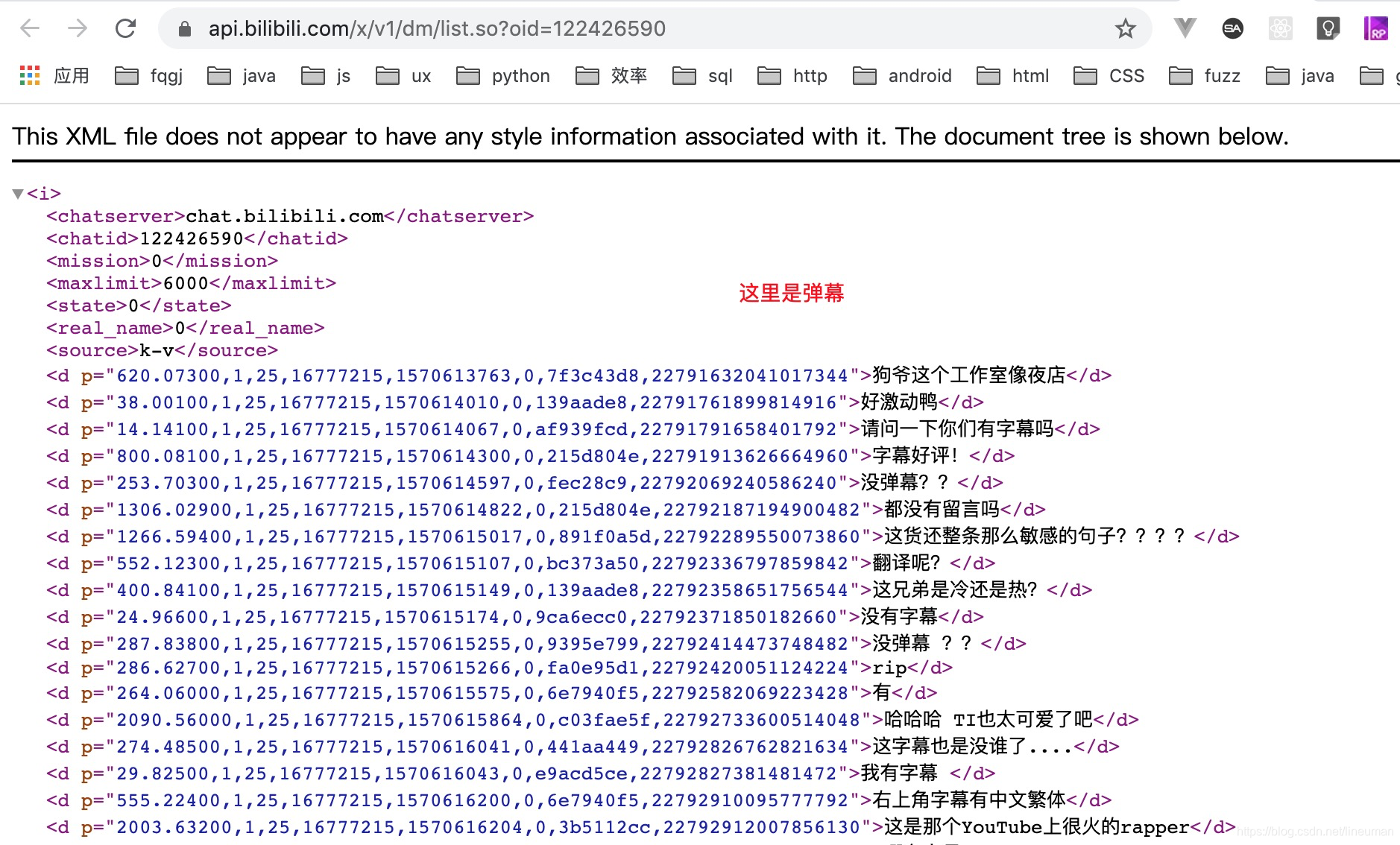
4.获取弹幕发送者信息
这个值是userId的hash得到的,可以通过彩虹表反向得到,对不起,b站可能大概也许谁知道呢修复了这个问题

import binascii
for i in range(1,100000000):
if binascii.crc32(str(i).encode("utf-8")) == 0x11ec39b9:
print(i)
京东
百度
微博
网易云音乐
网易云的用户 https://music.163.com/#/user/home?id=29879272
网易云的音乐 https://music.163.com/#/song?id=65766
第一步,查看《富士山下》
打开页面 https://music.163.com/#/song?id=65766
分析网络请求,看到有这样的请求
Request URL: https://music.163.com/weapi/song/enhance/player/url/v1?csrf_token=77b1ff400d812a327d4b8ee9f1e09b36
这个地址就是资源地址

所以重点就是分析这个接口的食用方法。
所以这里的问题就变成了API逆向解析问题。
weapi/song/enhance/player/url/v1
params
encSecKey
我们发现网易云音乐的js代码经过了混淆,非常不方便人类阅读,这真不是人干的事情啊~
浏览器断点调试原理?
获取调试过程中变量的值,你代码可以混淆,但是你变量的值是没法混淆的。

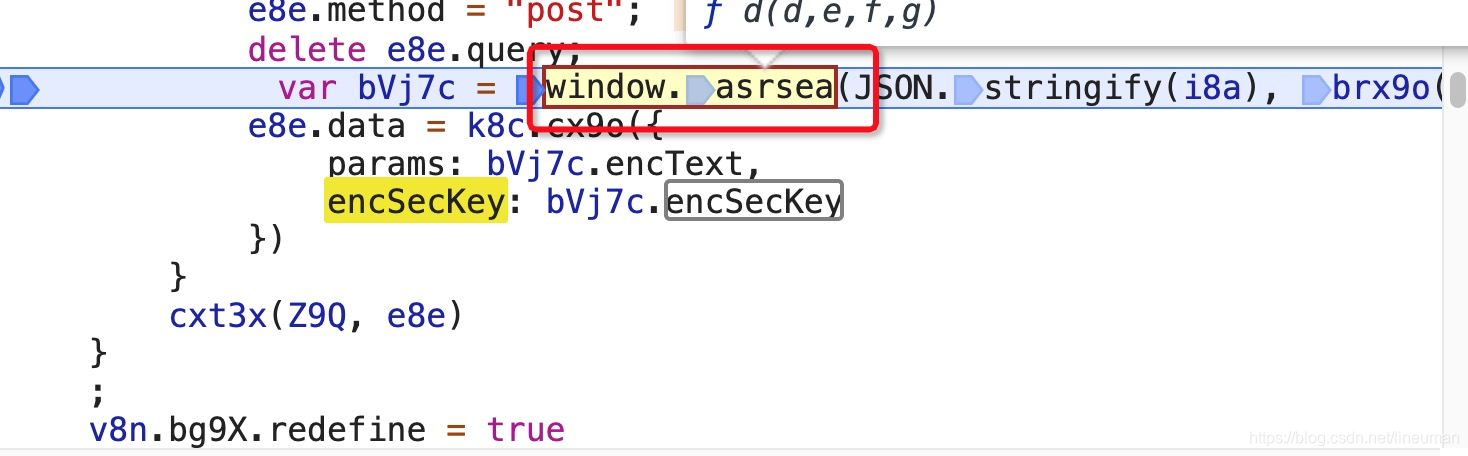
asrsea是一个d函数,d入参四个
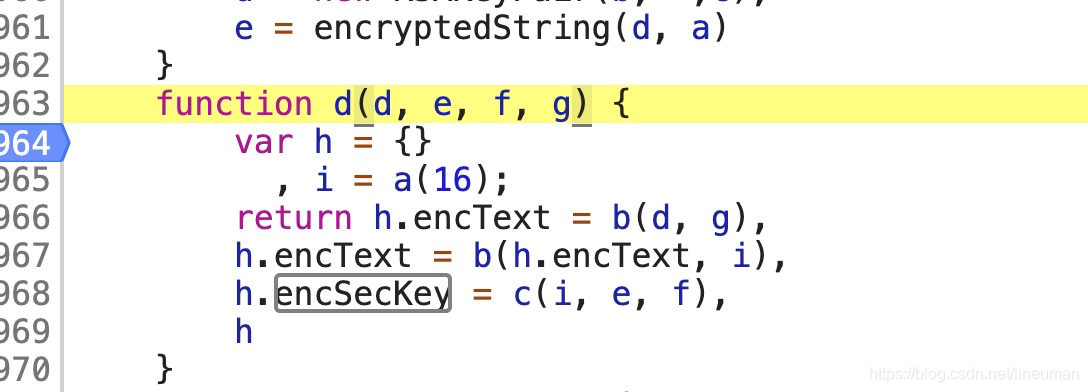
找到a函数

找到b函数
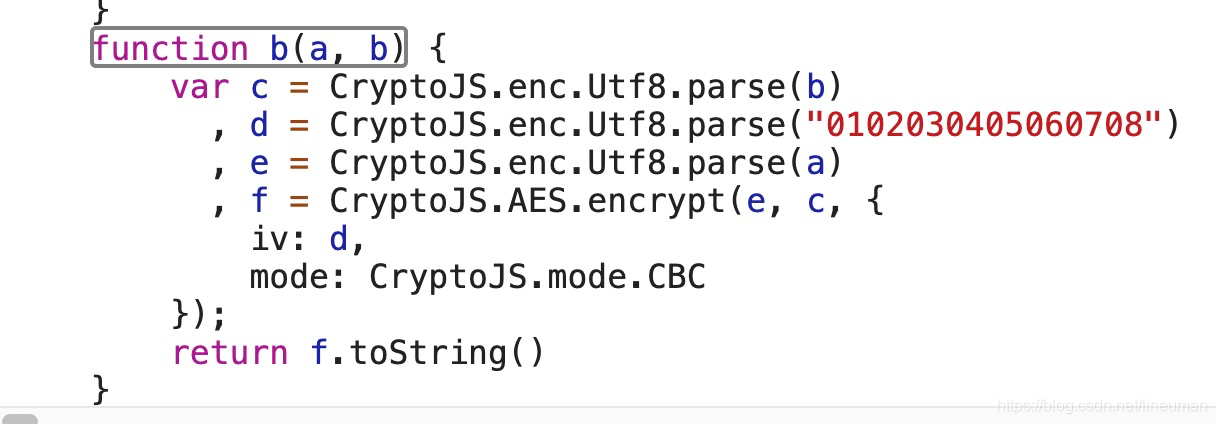
找到c函数

!function() {
function a(a) {
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d += 1)
e = Math.random() * b.length,
e = Math.floor(e),
c += b.charAt(e);
return c
}
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)
, f = CryptoJS.AES.encrypt(e, c, {
iv: d,
mode: CryptoJS.mode.CBC
});
return f.toString()
}
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
function e(a, b, d, e) {
var f = {};
return f.encText = c(a + e, b, d),
f
}
window.asrsea = d,
window.ecnonasr = e
}();
最后就变成了一个问题,python怎么获取js引擎的上下文,这样的话我不用把js转为python了。
可以通过python调用selenium,在selenium中执行js代码片段,这样的话即使js中包含三方依赖,那么也不会特别麻烦
网易云参考资料
https://blog.csdn.net/weixin_38936572/article/details/98608191
https://blog.csdn.net/weixin_44530979/article/details/87925950
https://github.com/metowolf/NeteaseCloudMusicApi/wiki/%E7%BD%91%E6%98%93%E4%BA%91%E9%9F%B3%E4%B9%90API%E5%88%86%E6%9E%90—weapi
https://www.zhihu.com/question/36081767
参考 https://juejin.im/post/5c8f15bde51d451d1118db99

喜欢一个人,就像喜欢富士山。你可以看到它,但是不能搬走它。你有什么方法可以移动一座富士山呢?回答是,你自己走过去。爱情也是如此,逛过就已经足够。 —云评论

















 9947
9947

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









