







前言
本篇文章实现python的scrapy框架爬取全书网小说,scrapy框架的安装我在这里就不在赘述了,建议window用户使用anaconda安装,这里比较省心一些。运行环境python3(实际python2运行页没有太大问题)
一,项目的创建
在想要创建项目的目录内,打开cmd命令行,输出代码
scrapy startproject Fiction然后进入项目内
cd Fiction创建一个爬虫项目
scrapy genspider novel quanshuwang.com完成后其项目目录是这样的
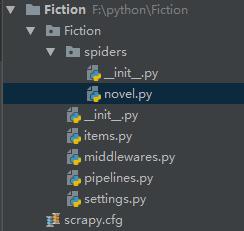
二,具体代码部分(关键部分已经给了注释)
1.items.py文件
# -*- coding: utf-8 -*-
import scrapy
class FictionItem(scrapy.Item):
name = scrapy.Field() #小说名字
chapter_name = scrapy.Field() #小说章节名字
chapter_content = scrapy.Field() #小说章节内容
2.novel.py文件
# -*- coding: utf-8 -*-
import scrapy
import re
from Fiction.items import FictionItem
from scrapy.http import Request
class NovelSpider(scrapy.Spider):
name = 'novel'
allowed_domains = ['quanshuwang.com']
start_urls = [
'http://www.quanshuwang.com/list/1_2.html',
'http://www.quanshuwang.com/list/1_3.html',
'http://www.quanshuwang.com/list/1_4.html',
'http://www.quanshuwang.com/list/1_5.html',
'http://www.quanshuwang.com/list/1_6.html',
'http://www.quanshuwang.com/list/1_7.html',
'http://www.quanshuwang.com/list/1_8.html',
'http://www.quanshuwang.com/list/1_9.html',
'http://www.quanshuwang.com/list/1_10.html',
] #全书网玄幻魔法类前10页
#获取每一本书的URL
def parse(self, response):
book_urls = response.xpath('//li/a[@class="l mr10"]/@href').extract()
for book_url in book_urls:
yield Request(book_url, callback=self.parse_read)
#获取马上阅读按钮的URL,进入章节目录
def parse_read(self, response):
read_url = response.xpath('//a[@class="reader"]/@href').extract()[0]
yield Request(read_url, callback=self.parse_chapter)
#获取小说章节的URL
def parse_chapter(self, response):
chapter_urls = response.xpath('//div[@class="clearfix dirconone"]/li/a/@href').extract()
for chapter_url in chapter_urls:
yield Request(chapter_url, callback=self.parse_content)
#获取小说名字,章节的名字和内容
def parse_content(self, response):
#小说名字
name = response.xpath('//div[@class="main-index"]/a[@class="article_title"]/text()').extract_first()
result = response.text
#小说章节名字
chapter_name = response.xpath('//strong[@class="l jieqi_title"]/text()').extract_first()
#小说章节内容
chapter_content_reg = r'style5\(\);</script>(.*?)<script type="text/javascript">'
chapter_content_2 = re.findall(chapter_content_reg, result, re.S)[0]
chapter_content_1 = chapter_content_2.replace(' ', '')
chapter_content = chapter_content_1.replace('<br />', '')
item = FictionItem()
item['name'] = name
item['chapter_name'] = chapter_name
item['chapter_content'] = chapter_content
yield item
3.pipelines.py文件
# -*- coding: utf-8 -*-
import os
class FictionPipeline(object):
def process_item(self, item, spider):
curPath = 'F:\全书网小说'
tempPath = str(item['name'])
targetPath = curPath + os.path.sep + tempPath
if not os.path.exists(targetPath):
os.makedirs(targetPath)
filename_path = 'F:\全书网小说'+ os.path.sep + str(item['name'])+ os.path.sep + str(item['chapter_name']) + '.txt'
with open(filename_path, 'w', encoding='utf-8') as f:
f.write(item['chapter_content'] + "\n")
return item
4.settings.py文件
BOT_NAME = 'Fiction'
SPIDER_MODULES = ['Fiction.spiders']
NEWSPIDER_MODULE = 'Fiction.spiders'
ROBOTSTXT_OBEY = False
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
ITEM_PIPELINES = {
'Fiction.pipelines.FictionPipeline': 300,
}三,总结
本篇文章只获取了全书网玄幻魔法类的前10页的小说,修改start_urls可以获取到剩余页面或者其他类别的小说。效果图如下:
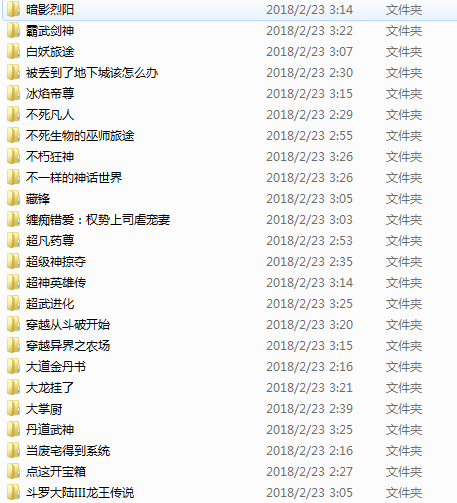
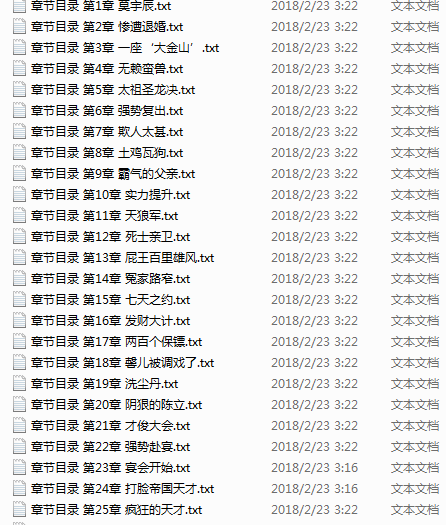















 820
820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









