







本篇文章记录MySQL相关知识点,包括基础语法以及个人扩展。
基础知识点
前引:本篇知识小结是本人总结《MySQL必知必会》一书的笔记,如有内容不符的内容,烦请联系。内容较少的章节合并到了相邻章节。扩充内容补充到了相似章节。
第一章 了解SQL:概念篇
数据库:是一个以某种有组织的方式存储的数据的集合。(通常理解为保存有组织的数据的容器)
数据库软件应该称为DBMS(数据库管理系统),数据库是通过DBMS创建和操作的容器。
表:是一种结构化的文件,可以用来存储某种特定类型的数据。
SQL指结构化查询语言,是一种专门用来与数据库通信的语言。
SQL使我们有能力访问数据库
SQL是一种ANSI的标准计算机语言
RDBMS:指的是关系型数据库管理系统,是SQL的基础,同样是所有现代数据库的基础,比如:SQL server,DB2,Oracle,MySQL等
RDBMS中的数据存储在被称为表的数据库对象中,表是相关数据项的集合,它由列和行组成。
现代的SQL服务器构建在rdbms之上
DBMS数据库管理系统:是一种可以访问数据库中数据的计算机程序,使我们有能力在数据库中提取,修改或者存储信息,不同的dbms提供不同的函数供查询,提交以及修改数据。
关系型数据库管理系统也是一种数据库管理系统,其数据库是根据数据间的关系来组织和访问数据的。
可以把SQL分为两个部分:数据操作语言DML 和数据定义语言DDL
DML:select update delete insert into
DDL:create alter database/table drop table create index drop index
第二章 什么是MySQL:
数据的所有存储,检索,管理和处理实际上是由数据库软件DBMS完成的。
DBMS可分为两类:一类是基于共享文件系统的DBMS,另一类为基于客户机-服务器的DBMS。(MySQL,Oracle,SQLserver等),这里客户机可以理解为:安装有sql yog的计算机(本人选的是这个),服务器是指在电脑上安装的有MySQL管理系统的计算机(自己测试通常是在一台电脑上)。
命令行登录:mysql -hlocalhost -u root -p 之后键入密码。(注意已经配置过环境变量了,否则需要找到安装路径bin目录下执行该命令)
第三章 使用MySQL
use 数据库名
show databases;
show tables;
show columns from 表名;等同于:describe customers
show create customers
show create database newdb 显示创建语句。show create table 表名;
第四章 检索数据
select *
from products;一般来说除非确实需要每个列,否则最好别使用通配符 *
select distnct id
from table;
distinct 关键字应用于所有列而不是他的前置列,Distinct 后面可以跟多个字段滤重,跟单个一样也是保证唯一性。
limit 检索的时候是从第0行开始的,不是第一行。
count(),count*和1的区别:没有区别,count(列名)和count1有些区别,有主键,count(主键)快,没有主键count1快。Count(列名)会去除空值,要注意
第五章 排序检索数据--order by
通常排序的列是显示所选择的列,但是并不一定是这样,用非检索的列排序数据也是合法的。
默认是升序排列 ASC ,降序 DESC 需要指定。升序降序结合使用的时候是不一样的,要注意。
第六章 过滤数据--where
= <> != < <= > >= between 常用操作符,MySQL的between是包含两端的,有的不包括,请注意。
空值 is not null is null
And :第一个和第二个条件都成立
Or:第一个和第二个只要成立一个条件即可成立
and 用来指示检索所有给定的条件。
or 任意条件满足即可成立。注意:and的优先级要比or高,当组合使用的时候记得加上括号。
where (id=12 or id=13)and salary=20
in 在某个范围之内,与or差不多,
两者的差别:
当使用多个候选清单的时候 in 更直观,
in的操作符更少,计算次序更容易管理
in最大的优点是可以包含子查询
第八章 通配符过滤数据-- like _
like 匹配多个,_ 下划线匹配一个,最好不要把like放在开头位置
第九章 正则表达式
正则表达式的作用是匹配文本,将一个正则表达式与一个文本串进行比较。
where name regexp '100'
where name regexp '.100' .表示匹配任意一个字符。
请注意:like '100' 和 regexp '100'
like 表示匹配整个列,如果被匹配的文本在列值中出现则like不会返回它。
后者会在列值中进行匹配。
默认不区分大小写 如果要区分 where name regexp binary '100'
or 匹配:| regexp '100|200'
[]匹配:regexp '[123] ton' 123任意一个都可以。等同于[1|2|3],[^123]匹配除了123之外的字符
where name regexp '[1-5] ton' 范围性匹配。
注意当匹配特殊字符的时候需\\ 为前导。where ’\\.‘
转义字符多数使用 单个\ ,MySQL本身使用两个\\
第十章 计算字段--
concat(name,'hh',salary)
trim rtrim ltrim 去掉左右两边的空格。
第十一章 使用数据处理函数--
length() 返回长度
lower() 小写
upper()大写
sunstring()截取

![]() 编辑
编辑
切记日期要为 yyyy-MM-dd 格式的
第十二章 汇总数据聚合函数
AVG()
count():count(*)对表中的数据计数,不管是不是包含空值,count(列名)计数会忽略空值。
max()
min()
sum():会忽略列值为 null 的行。
group by having where 和 having 的 区别:where 在数据分组前过滤,having 在数据分组后过滤。
order by
第十五章 表连接--
笛卡尔积:表连接没有关联条件时候会产生。
常用 inner join left join right join
组合查询:union 使用场景
在单个查询中从不同的表中返回类似结构的组合查询
对单个表执行多个查询,按单个查询返回数据。
union 会自动去除重复行 ,union all 不会
第十八章 全文本搜索-
innodb不支持全文本搜索,myisam支持。
数据插入:
insert into table
values('11','aa','2000'),('12','ab','3000')
insert into table (id,name,salary)
values('11','aa','2000'),('12','ab','3000')
插入的时候如果带有列名 可不按顺序也不影响,表结构改变也不影响。最好不要使用不带列名的插入。
insert into newtable (cust_id,cust_name,cust_aa)
select cust_id,cust_name,cust_aa from table;
列名不一定要一样,因为插入只是负责把新数据插入到指定的列,跟别的没有关系。
更新数据:update
update table
set id=99
where name='aa'
更新多个列:
update table
set id=99,
salary='50'
where name='aa';
ignore 关键字,当要更新多行的时候,如果其中的一行或者多行出现一个错误,则整个更新被取消,包括之前更新过的值。 发生错误也要更新可使用 update ignore table 。
如果想删除整列数据 可以把该列置为空 null
删除一行 :delete from table where id='20' delete删除表中数据而不删除表本身。
如果要删除所有行 可使用 truncate table ,他的速度更快。(它实际上是删除原来的表并重新创建一个新表,而不是逐行删除表中数据。)
Delete from table where 列名称=值
DELETE FROM orders WHERE company='nw'
删除所有行:delete from table 保留表结构
Truncate table 表名
Drop table 表名
区别:
truncate 是整体删除(速度快),delete是逐条删除(数度慢)
truncate 删除不记录MySQL日志,不可恢复数据,delete记录服务器日志,这也是truncate比delete效率高的原因。
Truncate不激活trigger触发器,但是会重置identity(标识列,自增字段)相当于自增列会被置为初始值,
Delete identity 还是会累加。
第二十一章 创建和操纵表-
create table if not exists customers
create table customers
(
cust_id int not null auto_increment,
cust_name char(50) not null,
cust_address char(50) null,
primary key (cust_id)
)ENGINE=InnoDB;
不要把null与空串混淆,null是没有值,他不是空串,,如果指定‘ ’,(两个单引号,其间没有字符),这在not null中是允许的,,空串是一个有效的值,他不是无值。
创建由多个列组成的主键:create table 表名
order_num int not null,
item_price decimal(8,2) not null,
primary key(order_num,order_item)
)ENGINE=InnoDB;
AUTO_INCREMENT:代表自动增量,每插入一行会自动增加。
每个表只允许一个AUTO_INCREMENT,而且它必须被索引,
如果在插入值的时候指定这个值,那么后续的增量将从这个值开始。后面你可能不知道最后这个值是谁,可用 select last_insert_id() 查询最后一个 AUTO_INCREMENT值。
指定默认值:prod_id int not null default 1
mysql有多种引擎,这些引擎都隐藏在MySQL服务器内,不同的存储引擎具有各自不同的功能和特性,为不同的任务选择正确的引擎能获得良好的功能和灵活性。
innodb 是一个可靠的事物处理引擎,它不支持全文本搜索。
memory在功能上等同于myisam,但是由于数据是存储在内存而不是磁盘中,速度很快(特别适合临时表);
mysiam是一个性能及高的引擎,它支持全文本搜索,但不支持事物处理。
所支持的引擎的完整列表以及不同请参阅:http://dev.mysql.com/doc/refman/5.0/en/storage_engines.html
引擎类型可以混用,但是有一个大缺陷,外键不能跨引擎,即使用一个引擎的表不能引用具有使用不同引擎的表的外键。
更新表:
alter table 表名 add 列名 char(20);
alter table 表名 drop column 列名;
添加外键:
alter table 表名
add constraint 外键名
foreign key (order_num) references orders (order_num);
重命名表:rename table customer to newtables
多个表重新命名:中间用逗号隔开即可。
第二十二章 使用视图-
视图是虚拟的表。与包含数据的表不一样,视图只包含使用时动态检索数据的查询。
视图重用sql语句。
简化复杂的SQL操作。
使用表的部分数据而不是整个表。
保护数据,可以给用户授予表的特定部分的访问权限,而不是整个表的访问权限。
更改数据格式和表示。视图可返回与底层表的表示和格式不同的数据。视图本身不包含数据。
视图的规则和限制:
与表名一样,视图必须唯一命名。
创建的视图数目没有限制
视图可以嵌套
视图不能索引,也不能有关联的触发器或默认值。
查询时视图可以和表一起使用。
create view
show create view viewname
更新视图:先删除 drop view viewname,再创建,或者 直接用 create or replace view
视图可以更新基本的表,但是基本上不建议这样使用。
第二十三章 使用存储引擎-
存储过程:简单来说就是为以后的使用而保存的一条或者多条MySQL语句的集合。
使用的理由:
通过把处理封装在容易使用的单元中,简化了复杂的操作。
由于不要求反复建立一系列处理步骤,保证了数据的完整性。
简化对变动的管理,如果表名,列名或者业务逻辑有变化,只需要更改存储过程的代码,使用他们的人员甚至不需要知道这些变化。
提高性能,存储过程要比使用单独的SQL语句要快。
但是存储过程的编写要比基本的sql语句复杂。
执行存储过程:
call 存储过程名(@pricelow,
@pricehigh,
@priceaverage);
存储过程可以显示结果也可以不显示。
create procedure 存储过程名()
begin
select avg(prod_price) as 别名
from table;
end;
可以变更分隔符:delimiter //
create procedure 存储过程名()
begin
select avg(prod_price) as 别名
from table;
end//
delimiter ;
使用存储过程:call 存储过程名();
实际上存储过程是一种函数。
删除:drop procedure 存储过程名 不加括号
如果在删除的过程中不存在会报错,可用 drop procedure if exists
变量:内存中一个特定的位置,用来临时存储数据。
create procedure 名(
out p1 declmal(8,2),
out p2 decimal(8,2)
)
begin
select min(prod-price)
into p1
from products;
select max(prod-price)
into p2
from products;
end;
执行:call 名(@pricelow,
@pricehigh);
所有MySQL变量都必须以@开始。
select @pricelow;
--
create procedure 名(
in onumber int,
out ototal decimal(8,2)
)
begin
select sum(iten*quantity)
from tabel
where order_num=onumber
into ototal;
end;
调用:call ordertotal(2005,@total);
select @total
显示存储过程名:show create procedure 名;
show procedure status ;显示所有的存储过程列表。
可加过滤条件:show procedure status like '名'
游标:有时,需要在检索出来的行中前进或者后退一行或者多行,这就是使用游标的原因。游标是一个存储在MySQL服务器上的数据库查询,他不是一条select语句,而是被该语句检索出来的结果集。MySQL游标只能用于存储过程和函数。
创建游标:create procedure 名()
begin
declare 游标名 cursor
for
select order_num from orders;
end;存储过程完成后游标就消失了,因为他局限于存储过程。
打开:open 游标名
close 游标名;
触发器:是MySQL响应一下任意语句而执行的一条MySQL语句。delete insert update,其他不支持。
创建触发器:唯一的触发器名
触发器关联的表
触发器应该响应的活动(delete,insert,update)
触发器核实执行(处理之前或者之后)
create trigger 触发器名 after insert on 表名
for each row select 'aaaaa'
只有表才支持触发器,视图临时表不支持。
触发器按每个事件每次定义,每个表每个事件每次只允许一个触发器,每个表最多支持6个,之前和之后。单一触发器不能和多个事件或者多个表关联。
drop trigger 触发器名。触发器不能更新或覆盖,为了修改一个触发器,必须先删除然后再创建。
第二十六章 管理事物处理
事务处理:并非所有的引擎都支持事物处理,它用来维护数据库的完整性,它保证成批的sql操作要么完全执行,要么完全不执行。
事务:指一组SQL语句。
回退:指撤销指定SQL语句的过程
提交:指将未存储的SQL语句结果写入数据库表
保留点:指事务处理中设置的临时占位符,你可以对它发布回退。(与回退整个事务处理不同)。
管理事务处理的关键在于将SQL语句组分解为逻辑块,并明确规定数据何时应该回退,何时不应该回退。
start transaction
rollback;
commit;
事务处理块中,提交不会隐含的进行,未进行明确的提交,使用commit语句。
start transaction;
delete from 表 where order_num=20010;
delete from 表2 where order_num=20010;
commit;
隐含事务关闭 当commit 或者 rollback语句执行后,事务会自动关闭。
使用保留点:复杂的事务会使用,复杂的事务处理可能需要部分提交或回退。
创建占位符:savepoint deletel;
每个保留点都取标识它的唯一名字,以便在回退时,MySQL知道回退到何处,
rollback to delete1;
保留点越多越好,更加的灵活。保留点在事务处理完成后自动释放,也可以用 release savepoint 明确的释放保留点。
修改是否自动提交:set autocommit=0; 他是针对每个连接的而不是服务器。
第二十七章 全球化和本地化
字符集:为字母和符号的集合。
编码:为某个字符集成员的内部表示。
校对:为规定字符如何比较的指令。
使用何种字符集和校对的决定在服务器,数据库和表级进行。
show character set ; 查看所有可用的字符集。和默认的校对。
show collation;显示所有的校对,以及他们适用的字符集。
create table table
(
lie int,
lie varchar(20)
)default character set hebrew
collate hebrew_general_ci;
第二十八章 安全管理-
USE mysql;
SELECT USER FROM USER;
CREATE USER ben IDENTIFIED BY 'root'
RENAME USER ben TO benben;
set password for ben=password('new')
set password =password('new') 不指定用户名时更新当前用户的口令。
DROP USER benben;
SHOW GRANTS FOR ben;
GRANT SELECT ON newdb.* TO ben;
SHOW GRANTS FOR ben;
REVOKE SELECT ON newdb.* TO ben;
新建连接 :IP 可以用本机local host 或者通过ipconfig 查看即可。
grant 和 revoke可在几个层次上控制访问权限:
整个服务器,使用grant all 和 revoke all;
整个数据库:使用 on databases.*
特定的表:on database.table
特定的列
特定的存储过程
grant select ,insert on 库名.* to 用户名;
第二十九章 数据库维护-
首先刷新未写入数据 flush tables
ANALYZE TABLE orders 检查表键是否正常
CHECK TABLE orders,orderitems;--检查
mysql -u root -p
show global variables like "%datadir%"; 查看安装目录
链接补充:MySQL :: MySQL Documentation
以下内容是一些基础的补充:仅供参考
可以把SQL分为两个部分:数据操作语言DML 和数据定义语言DDL
DML:select update delete insert into
DDL:create alter database/table drop table create index drop index
Distinct 后面可以跟多个字段滤重,跟单个一样也是保证唯一性。
第三十章 约束-
约束:用于限制表的数据的类型,在创建表的时候添加,或者建表之后添加。
Not null,nuique,primary key,foreign key,check,default
Not null约束:不能为空值
Create table ss
(
Id int ,
Nam varchar(255) not null
)
Unique约束:唯一标识数据库表中的每条记录
Unique和主键约束均为列或列集合提供了唯一性的保证,主键拥有自动定义的unique约束。每个表可以有多个unique约束,但是每个表只能有一个主键约束。
Create table sd
(
Id int not null,
Lastname varchar(20)
Unique (int)
)
如果需要命名unique约束,以及定义多个unique约束:有重复值的时候无法给该字段添加唯一约束
Create table zs1
(
Id int,
Af varchar(23) not null,
Adddd varchar(25)
Constraint 约束名 unique (id,af)
)
表创建完成的时候添加约束:(多个)
Alter table zs1 add unique(id)
Alter table zs1 add constraint 约束名 unique (id,af)
撤销约束:
Alter table zs1 drop index 约束名
Alter table zs1 drop constraint 约束名
单个约束撤销的时候直接加上约束的字段即可。
Primary key 约束:标识唯一记录,不包含空值,和unique的区别是 主键不能为空值,nuique可以。
Create table zs1 mysql
(
Id int,
Nnn varchar(25)
Primary key (id)
)
Create table zs1
(
Id int,
Nn varchar(25) primary key
)
主键包含多个字段:
Create table zs1
(
Id int,
Nn varchar(25)
Ab int
Constraint 约束名 primary key (id,nn)
)
建表之后创建:
Alter table zs1 add primary key (id)
Alter table zs1 add constraint 约束名 primary key (d,nn)
如果在建表之后添加主键,必须把主键列声明为不包含null(在表首次创建的时候)
撤销主键约束:
Alter table zs1 drop primary key --mysql
Alter table zs1 drop constraint 约束名 –oracle
Foreign key:一个表中的字段是主键,在另一个表中是外键,外键约束用于预防破坏表之间连接的动作。也能防止非法数据插入外键列,因为它必须指向那个表中的值之一。
Create table zs2 --mysql
(
Id int ,
Orid int,
Idp int,
Primary key (id),
Foreign key (idp) referenecs zs1(id)
)
Create table zs3 – oracle
(
Id int primary key,
Idd int ,
Ida int froeign key references zs1(id)
)
外键包含多个:
Create table zs4
(
Id int ,
Idd int ,
Qq int,
Primary key (id),
Constraint 约束名 foreign key (idd)
References zzs1(id)
)
Alter table zs1 add froeign key(id) references zs2(idp)
Alter table zs1 add constraint 约束名 foreign key (id) references zs2(idp)
撤销外键:
Alter table zs1 drop foreign key 约束名
Alter table zs1 drop constraint 约束名
Check约束:用于限制列中的值的范围,如果对单个列定义check约束,那么该列只允许特定的值,对一个表定义check约束,那么此约束会在特定的列中对值进行限制。
Create table zs1 --mysql
(
Id int,
Na varchar(25),
Check (id>0)
)
Create table zs1 --oracle
(
Id int check (id>0),
Na varchar(25),
)
多个check约束:
Create table zs1
(
Id int,
Nn int,
City int,
Constraint 约束名 check (id>0 and city=’assa’)
)
撤销约束:
Alter table zs1 drop constraint 约束名
Alter table zs1 drop check 约束名
Default约束:
Create table zs1
(
Id int,
Nn int,
Nam varchar(25) default ‘asasa’
)
Alter table zs1 --mysql
Alter city set default ‘aaa’
Alter table zs1 --oracle
Alter column city set default ‘saaa’
撤销default约束:
Alter table zs1 -- mysql
Alter city drop default
Alter table zs1 --oracle
Alter column city drop default
第三十一章 索引
index---索引是对数据库表中一列或者多列的值进行排序的结构。缩短查询的时间。 主键,唯一,联合索引。
创建索引,在不读取整个表的情况下,索引使数据库应用程序可以更快的查找数据。
索引会加速查询,但是更新数据慢。理想的做法是在常常被搜索的列(以及表)上面创建索引。
Create table zs1 --建表时侯
(
Id int,
Name int,
Asas int
Index(id)
);
Create index 索引名
On zs1 (id)
Create index 索引名
On zs1 (id desc)
索引不止一个:
Create index 索引名
On zs1 (id ,nn)
删除索引:不同的数据库可能不一样
Drop index 索引名 on zs1
Drop index zs1.id --sqlserver
Drop index id –oracle
Alter table zs1 drop index 索引名
--删除表--
Drop table zs1 表的一切都会删除
Drop database 数据库名
Truncate table zs1 仅仅删除表中的数据,保留结构之类的
--修改表—
添加列
Alter table zs1 add 列名 数据类型
删除列:alter table zs1 drop column 列名 –注意某些数据库不支持这种写法
改变列的数据类型:alter table zs1 alter column 列名 数据类型 --MySQL要用modify
--auto-increment会在新纪录插入表中时生成一个唯一的数字
我们通常希望在每次插入新纪录时,自动的创建主键字段的值,我们可以在表中创建一个auto-increment字段,
Create table zs1 主键自增 –MySQL语法
(
Id int not null auto_increment,
Nn varchar(25),
Add varchar(25)
Primary key (id)
)
Alter table zs1 auto_increment =100 更改起始值
当插入数据的时候手动更改自增的值,后面再次插入以上一条数据的序列值为准累加。
SQL server 语法:
Create table zs1
(
Id int primary key identity,
Lastname int
)
Access的语法:
Create table zs1
(
Id int primary key autoincrement,
Laname varchar(255)
)
要规定 "P_Id" 列以 20 起始且递增 10,请把 autoincrement 改为 AUTOINCREMENT(20,10)
Oracle语法:
Create sequence sqq
Minvalue 1
Start 1
Increment by 1
Cache 10
Insert into table zs1 (id,name,sex) values (sqq.nextval,’aa’,’man’) 这个相对复杂一下,需要注意
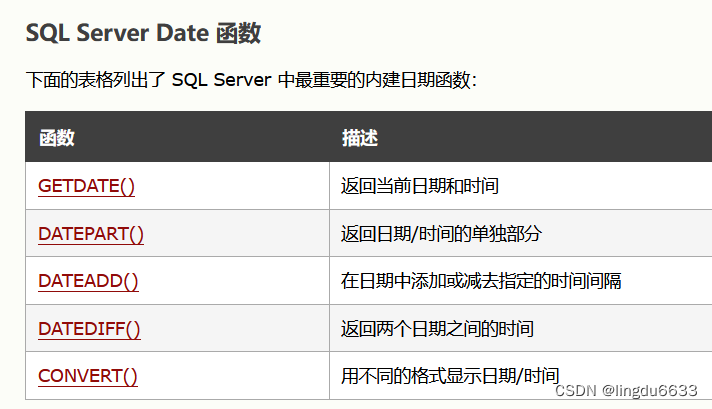
--date函数---
--date 函数—

![]() 编辑
编辑
![]() 编辑
编辑
MySQL日期类型:
Date 格式:YYYY-MM-DD
Datetime 格式:YYYY-MM-DD HH:MM:SS
Timestamp 格式:YYYY-MM-DD HH:MM:SS
Year 格式:YYYY或者YY
Sql server日期格式:
- DATE - 格式 YYYY-MM-DD
- DATETIME - 格式: YYYY-MM-DD HH:MM:SS
- SMALLDATETIME - 格式: YYYY-MM-DD HH:MM:SS
- TIMESTAMP - 格式: 唯一的数字
----null 值---
Null 值是遗漏的未知数据,默认的,表可以存放null值,null值用作未知的或不适用的值的占位符。无法比较null和0;他们是不等价的。
无法用运算符来比较测试空值,必须使用 is null 和 is not null
关于 null 的函数:
Isnull(),nvl(),ifnull(),coalesce()
Isnull(列,0) nvl(列,0) ifnull(列,0) coalesce(列,0)
--数据类型---
Char(size):保存固定长度的字符串(可包含字母,数字以及特殊字符),在括号中指定字符串的长度,最多255个字符。
Varchar(size):保存可变长度---------指定字符串的最大长度,最多255个字符。
Tinytext:存放最大长度为255个字符的字符串
Text: 存放最大长度为65535个字符的字符串
Int(size)
Tinyint:-128-127
Float(size,d):带有浮动小数点的小数字,括号中规定最大位数,d规定小数点最大位数。
Decimal(size,d):作为字符串存储的double类型,允许固定的小数点。
Date() 不带时间
Datetime():带有时间
Timestamp:时间戳 带有时间,
Time:时间
Year:年
---本书实例建表语句如下:
########################################
# MySQL Crash Course
# http://www.forta.com/books/0672327120/
# Example table creation scripts
########################################
########################
# Create customers table
########################
CREATE TABLE customers
(
cust_id INT NOT NULL AUTO_INCREMENT,
cust_name CHAR(50) NOT NULL ,
cust_address CHAR(50) NULL ,
cust_city CHAR(50) NULL ,
cust_state CHAR(5) NULL ,
cust_zip CHAR(10) NULL ,
cust_country CHAR(50) NULL ,
cust_contact CHAR(50) NULL ,
cust_email CHAR(255) NULL ,
PRIMARY KEY (cust_id)
) ENGINE=INNODB;
#########################
# Create orderitems table
#########################
CREATE TABLE orderitems
(
order_num INT NOT NULL ,
order_item INT NOT NULL ,
prod_id CHAR(10) NOT NULL ,
quantity INT NOT NULL ,
item_price DECIMAL(8,2) NOT NULL ,
PRIMARY KEY (order_num, order_item)
) ENGINE=INNODB;
#####################
# Create orders table
#####################
CREATE TABLE orders
(
order_num INT NOT NULL AUTO_INCREMENT,
order_date DATETIME NOT NULL ,
cust_id INT NOT NULL ,
PRIMARY KEY (order_num)
) ENGINE=INNODB;
#######################
# Create products table
#######################
CREATE TABLE products
(
prod_id CHAR(10) NOT NULL,
vend_id INT NOT NULL ,
prod_name CHAR(255) NOT NULL ,
prod_price DECIMAL(8,2) NOT NULL ,
prod_desc TEXT NULL ,
PRIMARY KEY(prod_id)
) ENGINE=INNODB;
######################
# Create vendors table
######################
CREATE TABLE vendors
(
vend_id INT NOT NULL AUTO_INCREMENT,
vend_name CHAR(50) NOT NULL ,
vend_address CHAR(50) NULL ,
vend_city CHAR(50) NULL ,
vend_state CHAR(5) NULL ,
vend_zip CHAR(10) NULL ,
vend_country CHAR(50) NULL ,
PRIMARY KEY (vend_id)
) ENGINE=INNODB;
###########################
# Create productnotes table
###########################
CREATE TABLE productnotes
(
note_id INT NOT NULL AUTO_INCREMENT,
prod_id CHAR(10) NOT NULL,
note_date DATETIME NOT NULL,
note_text TEXT NULL ,
PRIMARY KEY(note_id),
FULLTEXT(note_text)
) ENGINE=MYISAM;
#####################
# Define foreign keys
#####################
ALTER TABLE orderitems ADD CONSTRAINT fk_orderitems_orders FOREIGN KEY (order_num) REFERENCES orders (order_num);
ALTER TABLE orderitems ADD CONSTRAINT fk_orderitems_products FOREIGN KEY (prod_id) REFERENCES products (prod_id);
ALTER TABLE orders ADD CONSTRAINT fk_orders_customers FOREIGN KEY (cust_id) REFERENCES customers (cust_id);
ALTER TABLE products ADD CONSTRAINT fk_products_vendors FOREIGN KEY (vend_id) REFERENCES vendors (vend_id);
--------基础篇完结:内容穿插可能不规范后续会优化整理
扩展篇:
扩展一:mysql_存储过程+重点sql记录
一: 存储过程例题
-- 用户变量只在当前链接有效
SET @aqq=10;
SELECT @aqq
-- 局部变量,仅仅在begin end中有效
DECLARE 变量名 类型;
-- 创建:create procedure 存储过程名(参数列表)
BEGIN
存储过程体
END
注意参数包含3部分:
参数模式 参数名 参数类型
IN aa VARCHAR
参数模式:
INT 输入
OUT 输出
INOUT 输入输出
如果过程体只有一句话,BEGIN END 可以省略
每个SQL语句的结尾必须加分号。
存储过程的结尾可以使用 DELIMITER 重新设置
-- 调用 call 存储过程名(参数)
-- 第一种 空参列表
SELECT * FROM aa01
DELIMITER $
CREATE PROCEDURE myp1()
BEGIN
INSERT INTO aa01(a1,a2)
VALUES(55,55),(66,66);
END $
mysql -uroot -proot
-- 调用
CALL myp1()$
-- 第二种 in 模式参数列表
DELIMITER $
CREATE PROCEDURE myp2( IN tt INT)
BEGIN
SELECT * FROM aa01
WHERE a1=tt;
END $
CALL myp2(11)
DELIMITER $
CREATE PROCEDURE myp44( IN t1 INT,IN t2 INT)
BEGIN
DECLARE t3 VARCHAR(20) DEFAULT '';#声明并初始化
SELECT COUNT(*) INTO t3
FROM aa01
WHERE a1=t1 AND a2=t2;
SELECT IF(t3>0,100,200);#使用
END $
-- 3 out 模式的
DELIMITER $
CREATE PROCEDURE myp5( IN t1 INT,OUT t2 INT)
BEGIN
SELECT a2 INTO t2
FROM aa01
WHERE a1=t1 ;
END $
CALL myp5(33,@tt)$
SELECT @tt$
-- inout模式的
DELIMITER $
CREATE PROCEDURE myp6( INOUT t1 INT,INOUT t2 INT)
BEGIN
SET t1=t1*2;
SET t2=t2*2;
END $
SET @m=10$
SET @n=10$
CALL myp6(@m,@n)$
SELECT @m,@n$
-- 例题
-- 删除
DROP PROCEDURE fms_p2;
-- 查看
DESC myp2;
SHOW CREATE PROCEDURE myp2;
-- 分组拼接函数记录
SELECT * FROM aa01
INSERT INTO aa01 VALUES(11,22),(11,33),(22,11),(22,22),(33,22)
SELECT a1,GROUP_CONCAT('_' ,a2)
FROM aa01
GROUP BY a1
-- 游标测试
DELIMITER $
CREATE PROCEDURE myy1()
BEGIN
DECLARE done INT ;
DECLARE a1 VARCHAR(100);
DECLARE a2 VARCHAR(100);
DECLARE a3 VARCHAR(100);
DECLARE a4 VARCHAR(100);
DECLARE a5 VARCHAR(100);
#定义游标
DECLARE my_cur CURSOR FOR
SELECT n_nu,ods_name,stg_name,prov_name,serv_name FROM fms_table;
DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET done = 1;
#打开游标
OPEN my_cur;
#遍历游标
read_loop:LOOP
FETCH my_cur INTO a1,a2,a3,a4,a5;
IF done=1 THEN
LEAVE read_loop;
END IF;
CALL fms_p3 (a1,a2,a3,a4,a5,'fms_table','fms_result_01');
END LOOP;
CLOSE my_cur;
END $
DELIMITER ;
CALL myy1()$
DROP PROCEDURE myy1;
SELECT * FROM fms_result_01
二:用存储过程实现表之间数据流转练习
CREATE TABLE fms_01( #定义临时表
n_id INT,
n_name VARCHAR(20),
n_date VARCHAR(20),
n_pro VARCHAR(20)
)
CREATE TABLE fms_table( #定义接口清单表
n_nu VARCHAR(100),
stg_name VARCHAR(100),
prov_name VARCHAR(100),
serv_name VARCHAR(100)
)
INSERT INTO fms_table VALUES('001','fms_01','fms_02','fms_03') #接口清单数据
DROP TABLE fms_result_01
CREATE TABLE fms_result_01( #定义接口入库结果清单表
n_nu VARCHAR(100),
stg_name VARCHAR(100),
prov_name VARCHAR(100),
serv_name VARCHAR(100),
n_sum INT
)
SELECT * FROM fms_result_01
INSERT INTO fms_result_01 (stg_name) -- where n_nu='001'
SELECT 'wewe'
INSERT INTO fms_02
SELECT * FROM fms_02
INSERT INTO fms_02 VALUES(01,'aa','20231005','10000'),(02,'bb','20231005','10000'),(03,'bb','20231008','10000')
CREATE TABLE fms_12 LIKE fms_02; #复制一个空表
SELECT * FROM fms_01;
SELECT * FROM fms_04;
SELECT * FROM fms_log_01;
TRUNCATE TABLE fms_02
-- 1,实现表数据传输
DELIMITER $
CREATE PROCEDURE fms_p1( IN tname_0 VARCHAR(100),IN tname_1 VARCHAR(100))
BEGIN
DECLARE su_m INT DEFAULT -1;#声明并初始化
DECLARE aa VARCHAR(200);
-- set aa=tname_1;
SET @sql1 = CONCAT( ' insert into ' ,tname_1, ' SELECT * FROM ' ,tname_0);
PREPARE stmt FROM @sql1;
EXECUTE stmt;
END $
DROP PROCEDURE fms_p1;
CALL fms_p1 ('fms_01','fms_02')$
-- 2.实现表数据传输,写入日志表
DELIMITER $
CREATE PROCEDURE fms_p2( IN tname_0 VARCHAR(100),IN tname_1 VARCHAR(100),IN tname_2 VARCHAR(100))
BEGIN
DECLARE su_m INT DEFAULT -1;#声明并初始化
DECLARE aa VARCHAR(200);
-- set aa=tname_1;
SET @sql1 = CONCAT( ' insert into ' ,tname_1, ' SELECT * FROM ' ,tname_0);
PREPARE stmt FROM @sql1;
EXECUTE stmt;
SET @sql2 = CONCAT( ' insert into ', tname_2, ' (su_m) ',' select count(*) from ' ,tname_1);
PREPARE stmt FROM @sql2;
EXECUTE stmt;
END $
DROP PROCEDURE fms_p2;
CALL fms_p2 ('fms_01','fms_02','fms_log_01')$
INSERT INTO fms_log_01 (su_m) SELECT COUNT(*) FROM fms_log_01
SELECT * FROM fms_log_01
-- 3.实现三个表表数据传输,写入日志表并记录
DELIMITER $
CREATE PROCEDURE fms_p3(IN n_nu VARCHAR(100),IN tname_1 VARCHAR(100),IN tname_2 VARCHAR(100),IN tname_3 VARCHAR(100),IN tname_4 VARCHAR(100),IN tname_5 VARCHAR(100),IN tname_6 VARCHAR(100))
BEGIN
DECLARE aa INT DEFAULT -1;
SET @sql0 = CONCAT( ' insert into ' ,tname_6, ' (n_nu,stg_name,prov_name,serv_name) ', ' SELECT n_nu,stg_name,prov_name,serv_name FROM ' ,tname_5);
PREPARE stmt FROM @sql0;
EXECUTE stmt;
SET @sql1 = CONCAT( ' insert into ' ,tname_2, ' SELECT * FROM ' ,tname_1);
PREPARE stmt FROM @sql1;
EXECUTE stmt;
SET @sql2 = CONCAT( ' insert into ' ,tname_3, ' SELECT * FROM ' ,tname_1);
PREPARE stmt FROM @sql2;
EXECUTE stmt;
SET @sql3 = CONCAT( ' insert into ' ,tname_4, ' SELECT * FROM ' ,tname_1);
PREPARE stmt FROM @sql3;
EXECUTE stmt;
SET @sql4 = CONCAT(' SELECT count(*) into @aa FROM ' ,tname_4);
PREPARE stmt FROM @sql4;
EXECUTE stmt;
SET @sql5 = CONCAT( ' update ',tname_6, ' set n_sum= ' ,@aa , ' where n_nu= ',n_nu);
PREPARE stmt FROM @sql5;
EXECUTE stmt;
END $
-- 4.实现三个表表数据传输,写入日志表并记录,接着循环
DELIMITER $
CREATE PROCEDURE fms_p3(IN n_nu VARCHAR(100),IN tname_1 VARCHAR(100),IN tname_2 VARCHAR(100),IN tname_3 VARCHAR(100),IN tname_4 VARCHAR(100),IN tname_5 VARCHAR(100),IN tname_6 VARCHAR(100))
BEGIN
DECLARE aa INT DEFAULT -1;
DECLARE bb INT DEFAULT 0;
SET @sql0 = CONCAT( ' insert into ' ,tname_6, ' (n_nu,ods_name,stg_name,prov_name,serv_name,n_num) ', ' SELECT n_nu,ods_name,stg_name,prov_name,serv_name,-1 FROM ' ,tname_5,' where n_nu= ',n_nu);
PREPARE stmt FROM @sql0;
EXECUTE stmt;
SET @sql1 = CONCAT( ' insert into ' ,tname_2, ' SELECT * FROM ' ,tname_1);
PREPARE stmt FROM @sql1;
EXECUTE stmt;
SET @sql2 = CONCAT( ' insert into ' ,tname_3, ' SELECT * FROM ' ,tname_1);
PREPARE stmt FROM @sql2;
EXECUTE stmt;
SET @sql3 = CONCAT( ' insert into ' ,tname_4, ' SELECT * FROM ' ,tname_1);
PREPARE stmt FROM @sql3;
EXECUTE stmt;
SET @sql4 = CONCAT(' SELECT count(*) into @aa FROM ' ,tname_4);
PREPARE stmt FROM @sql4;
EXECUTE stmt;
SET @sql5 = CONCAT( ' update ',tname_6, ' set n_sum= ' ,@aa , ' where n_nu= ',n_nu);
PREPARE stmt FROM @sql5;
EXECUTE stmt;
END $
SELECT * FROM fms_result_01
TRUNCATE TABLE fms_result_01
UPDATE fms_result_01 SET n_sum=10
WHERE n_nu='001'
DROP PROCEDURE fms_p3;
CALL fms_p3 ('001','fms_01','fms_02','fms_03','fms_04','fms_table','fms_result_01')$
SELECT * FROM fms_result_01
SELECT * FROM fms_01
TRUNCATE TABLE fms_result_01
ALTER TABLE fms_result_01 ADD ods_name VARCHAR(50) AFTER n_nu;
INSERT INTO fms_table VALUES('011','fms_11','fms_12','fms_13','fms_14')
CREATE TABLE fms_11 SELECT * FROM fms_01;
-- 5 游标实现循环读取然后执行存储过程
DELIMITER $
CREATE PROCEDURE myy1()
BEGIN
DECLARE done INT ;
DECLARE a1 VARCHAR(100);
DECLARE a2 VARCHAR(100);
DECLARE a3 VARCHAR(100);
DECLARE a4 VARCHAR(100);
DECLARE a5 VARCHAR(100);
#定义游标
DECLARE my_cur CURSOR FOR
SELECT n_nu,ods_name,stg_name,prov_name,serv_name FROM fms_table;
DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET done = 1;
#打开游标
OPEN my_cur;
#遍历游标
read_loop:LOOP
FETCH my_cur INTO a1,a2,a3,a4,a5;
IF done=1 THEN
LEAVE read_loop;
END IF;
CALL fms_p3 (a1,a2,a3,a4,a5,'fms_table','fms_result_01');
END LOOP;
CLOSE my_cur;
END $
DELIMITER ;
CALL myy1()$
DROP PROCEDURE myy1;
-- 6 增加健壮性 ,结果表添加入出接口数量,初始数量标识,时间戳。
ALTER TABLE fms_result_01 MODIFY r_num INT;
ALTER TABLE fms_result_01 ADD d_date DATETIME ;
SELECT * FROM fms_result_01
DESC fms_result_01
-- 6
DELIMITER $
CREATE PROCEDURE fms_p3(IN n_nu VARCHAR(100),IN tname_1 VARCHAR(100),IN tname_2 VARCHAR(100),IN tname_3 VARCHAR(100),IN tname_4 VARCHAR(100),IN tname_5 VARCHAR(100),IN tname_6 VARCHAR(100))
BEGIN
DECLARE aa INT DEFAULT -1;
DECLARE bb INT DEFAULT -1;
SET @sql0 = CONCAT( ' insert into ' ,tname_6, ' (n_nu,ods_name,stg_name,prov_name,serv_name,d_date) ', ' SELECT n_nu,ods_name,stg_name,prov_name,serv_name,now() FROM ' ,tname_5,' where n_nu= ',n_nu);
PREPARE stmt FROM @sql0;
EXECUTE stmt;
SET @sql1 = CONCAT( ' insert into ' ,tname_2, ' SELECT * FROM ' ,tname_1);
PREPARE stmt FROM @sql1;
EXECUTE stmt;
SET @sql2 = CONCAT( ' insert into ' ,tname_3, ' SELECT * FROM ' ,tname_1);
PREPARE stmt FROM @sql2;
EXECUTE stmt;
SET @sql3 = CONCAT( ' insert into ' ,tname_4, ' SELECT * FROM ' ,tname_1);
PREPARE stmt FROM @sql3;
EXECUTE stmt;
SET @sql4 = CONCAT(' SELECT count(*) into @aa FROM ' ,tname_2);
PREPARE stmt FROM @sql4;
EXECUTE stmt;
SET @sql5 = CONCAT( ' update ',tname_6, ' set r_num= ' ,@aa , ' where n_nu= ',n_nu);
PREPARE stmt FROM @sql5;
EXECUTE stmt;
SET @sql6 = CONCAT(' SELECT count(*) into @bb FROM ' ,tname_4);
PREPARE stmt FROM @sql6;
EXECUTE stmt;
SET @sql7 = CONCAT( ' update ',tname_6, ' set n_sum= ' ,@bb , ' where n_nu= ',n_nu);
PREPARE stmt FROM @sql7;
EXECUTE stmt;
END $
DROP PROCEDURE fms_p3
-- 7 游标遍历调用上面存储过程
DELIMITER $
CREATE PROCEDURE myy1()
BEGIN
DECLARE done INT ;
DECLARE a1 VARCHAR(100);
DECLARE a2 VARCHAR(100);
DECLARE a3 VARCHAR(100);
DECLARE a4 VARCHAR(100);
DECLARE a5 VARCHAR(100);
#定义游标
DECLARE my_cur CURSOR FOR
SELECT n_nu,ods_name,stg_name,prov_name,serv_name FROM fms_table;
DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET done = 1;
#打开游标
OPEN my_cur;
#遍历游标
read_loop:LOOP
FETCH my_cur INTO a1,a2,a3,a4,a5;
IF done=1 THEN
LEAVE read_loop;
END IF;
CALL fms_p3 (a1,a2,a3,a4,a5,'fms_table','fms_result_01');
END LOOP;
CLOSE my_cur;
END $
DELIMITER ;
CALL myy1()$
DROP PROCEDURE myy1;
三:二例题改写成Gbase存储过程语法
-- 1.1创建清单表
CREATE TABLE prod.dataman.fms_list(
n_id int PRIMARY KEY COMMENT '优先级编号',
n_nu VARCHAR(64) DEFAULT NULL COMMENT '接口号',
ods_name VARCHAR(100) DEFAULT NULL COMMENT '临时表表名'
stg_name VARCHAR(100) DEFAULT NULL COMMENT 'stg表名',
prov_name VARCHAR(100) DEFAULT NULL COMMENT 'prov表名',
serv_name VARCHAR(100) DEFAULT NULL COMMENT 'serv表名',
sys_flag VARCHAR(100) DEFAULT NULL COMMENT '系统标识'
) ENGINE=EXPRESS DEFAULT CHARSET=utf8 TABLESPACE='sys_tablespace' COMMENT = '定义资金清单表';
-- 清单表插入数据
insert into fms_list values
(1,'fms08085','prod.boncres.a_70005_fms_08085','prod.stgdb.TSFMS_D_M_FI_FD_A08085_DEPO_ACCT_CHK_MGT_TRI_10000','prod.provdb.TO_D_FI_FD_DEPO_ACCT_CHK_MGT_TRI_10000','prod.servdb.TO_D_FI_FD_DEPO_ACCT_CHK_MGT_TRI','fms'),
(2,'fms08073','prod.boncres.a_70005_fms_08073','prod.stgdb.TSFMS_D_M_FI_FD_A08073_INTERE_ACCRUED_APPLY_10000','prod.provdb.TO_D_FI_FD_INTERE_ACCRUED_APPLY_10000','prod.servdb.TO_D_FI_FD_INTERE_ACCRUED_APPLY','fms')
call prod.dataman.test_fms_p3('fms08073','prod.boncres.a_70005_fms_08073','prod.stgdb.TSFMS_D_M_FI_FD_A08073_INTERE_ACCRUED_APPLY_10000','prod.provdb.TO_D_FI_FD_INTERE_ACCRUED_APPLY_10000','prod.servdb.TO_D_FI_FD_INTERE_ACCRUED_APPLY','prod.dataman.fms_list','prod.dataman.fms_result')
-- 1.2创建结果表
CREATE TABLE prod.dataman.fms_result(
n_nu VARCHAR(64) COMMENT '接口号',
ods_name VARCHAR(64) DEFAULT NULL COMMENT '临时表表名',
r_num int COMMENT '总数',
stg_name VARCHAR(100) DEFAULT NULL COMMENT 'stg表名',
prov_name VARCHAR(100) DEFAULT NULL COMMENT 'prov表名',
serv_name VARCHAR(100) DEFAULT NULL COMMENT 'serv表名',
n_sum int COMMENT 'serv总数',
d_date VARCHAR(100) DEFAULT NULL COMMENT '执行完成时间戳'
) ENGINE=EXPRESS DEFAULT CHARSET=utf8 TABLESPACE='sys_tablespace' COMMENT = '定义资金结果表';
-- 2.1 创建数据流转的存储过程
delimiter //
CREATE DEFINER = "df_lisj" @"%" PROCEDURE "test_fms_p3"(
IN nn_nu VARCHAR,
- - 传 入 接 口 号 IN tname_ods VARCHAR,
- - 传 入 临 时 表 表 名 IN tname_stg VARCHAR,
- - 传 入 stgdb 正 式 表 表 名 IN tname_prov VARCHAR,
- - 传 入 provdb 表 表 名 IN tname_serv VARCHAR,
- - 传 入 servdb 表 表 名 IN tname_list VARCHAR,
- - 传 入 清 单 表 表 名 IN tname_result varchar - - 传 入 结 果 日 志 表 表 名
) BEGIN
/*-------------------------------------------------------------------- 该存储过程实现从临时表到正式表三层的功能 --------------------------------------------------------------------*/
DECLARE aa INT DEFAULT -1;
- - 定 义 变 量 接 收 入 接 口 的 数 据 总 量 DECLARE bb INT DEFAULT -1;
- - 定 义 变 量 接 收 出 接 口 的 数 据 总 量 DECLARE V_SQL TEXT;
- - 定 义 变 量 接 收 拼 接 后 的 sql 语 句 # 将 清 单 表 插 入 结 果 表
set
V_SQL = ' insert into ' || tname_result || '(n_nu,ods_name,stg_name,prov_name,serv_name,d_date,is_flag)' || ' SELECT n_nu,ods_name,stg_name,prov_name,serv_name,now(),1 FROM ' || tname_list || ' where n_nu= ''' || nn_nu || '''';
SET
@SQL_STR = V_SQL;
PREPARE STMT
FROM
@SQL_STR;
EXECUTE STMT;
# 从 临 时 表 插 入 数 据 到 stg 层
SET
V_SQL = 'insert into ' || tname_stg || ' SELECT * FROM ' || tname_ods;
SET
@SQL_STR = V_SQL;
PREPARE STMT
FROM
@SQL_STR;
EXECUTE STMT;
# 从 临 时 表 插 入 数 据 到 prov 层
SET
V_SQL = 'insert into ' || tname_prov || ' SELECT * FROM ' || tname_ods;
SET
@SQL_STR = V_SQL;
PREPARE STMT
FROM
@SQL_STR;
EXECUTE STMT;
# 从 临 时 表 插 入 数 据 到 serv 层
SET
V_SQL = 'insert into ' || tname_serv || ' SELECT * FROM ' || tname_ods;
SET
@SQL_STR = V_SQL;
PREPARE STMT
FROM
@SQL_STR;
EXECUTE STMT;
#
set
ttt = 'lihao';
# stg 表 条 数 记 录
SET
V_SQL = 'SELECT count(*) into @aa FROM ' || tname_stg;
SET
@SQL_STR = V_SQL;
PREPARE STMT
FROM
@SQL_STR;
EXECUTE STMT;
set
aa = @aa;
# 条 数 插 入 到 结 果 表 中 # V_SQL = 'update ' || tname_6 || 'set r_num= ' || @aa || ' where n_nu= ''' || n_nu || '''';
#
set
ttt = 'lihao';
set
V_SQL = 'update prod.dataman.fms_result set r_num= ' || aa || ' where n_nu= ''' || nn_nu || '''';
# V_SQL = 'update ' || tname_6 || 'set r_num= ' || @aa || '' || 'where n_nu= ''' || nn_nu || '''';
#
set
ttt = V_SQL;
SET
@SQL_STR = V_SQL;
PREPARE STMT
FROM
@SQL_STR;
EXECUTE STMT;
# serv 表 条 数 记 录
SET
V_SQL = 'SELECT count(*) into @bb FROM ' || tname_serv;
SET
@SQL_STR = V_SQL;
PREPARE STMT
FROM
@SQL_STR;
EXECUTE STMT;
set
bb = @bb;
# 条 数 插 入 到 结 果 表 中
set
# V_SQL = 'update prod.dataman.fms_result set r_num= ' || aa || ' where n_nu= ''' || nn_nu || '''';
V_SQL = 'update prod.dataman.fms_result set n_sum= ' || bb || ' where n_nu= ''' || nn_nu || '''';
SET
@SQL_STR = V_SQL;
PREPARE STMT
FROM
@SQL_STR;
EXECUTE STMT;
end //
delimiter ;
-- 2.2 创建遍历清单表的存储过程
delimiter //
CREATE DEFINER = "df_lisj" @"%" PROCEDURE "test_fms_p4"()
BEGIN DECLARE v_done INT default 0;
DECLARE a1 VARCHAR(100);
DECLARE a2 VARCHAR(100);
DECLARE a3 VARCHAR(100);
DECLARE a4 VARCHAR(100);
DECLARE a5 VARCHAR(100);
DECLARE v_error INT default 0;
DECLARE my_cur CURSOR FOR
SELECT
n_nu,
ods_name,
stg_name,
prov_name,
serv_name
FROM
prod.dataman.fms_list;
DECLARE CONTINUE HANDLER FOR SQLSTATE '02000'
set
v_done = 1;
declare continue HANDLER FOR sqlexception
set
v_error = 1;
update
prod.dataman.fms_result
set
is_flag = 0;
OPEN my_cur;
repeat FETCH my_cur INTO a1,
a2,
a3,
a4,
a5;
IF not v_done THEN CALL test_fms_p3 (
a1,
a2,
a3,
a4,
a5,
'prod.dataman.fms_list',
'prod.dataman.fms_result'
);
END IF;
until v_done
end repeat;
CLOSE my_cur;
end //
delimiter ;
扩展二:MySQL存储引擎
1--MySQL存储引擎
存储引擎是MySQL中具体与文件打交道的子系统,它是根据根据MySQL公司提供的文件访问层抽象接口定制的一种文件访问机制,这种机制就叫做存储引擎。
简单来说:存储引擎是MySQL将数据存储在文件系统中的存储方式或者存储格式。它决定着一个表是如何存储和索引数据,以及是否支持事务。(扩充:存储引擎就是表类型,或者数据的存储结构,由实际业务决定。)
SHOW ENGINES 查看所有支持的存储引擎
SHOW TABLE STATUS FROM dazs_01 WHERE NAME='表名' 查看表的存储引擎。
定义存储引擎:engine=memory
修改:alter table 表名 engine=myisam;
通过修改 /etc/my.cnf 配置文件,指定默认存储引擎并重启服务,但是之前的存储引擎不会改变。windows在my.ini中修改配置。
存储引擎:是MySQL中特有的一个术语,实际上是一个表存储或组织数据的方式
不同的存储引擎表的存储数据的方式不同。
mysql默认的存储引擎是:InnoDB
默认的字符编码是:utf-8
支持9大引擎 常用3个。
innoDB :
默认的存储引擎,同时又是一个重量级的存储引擎
支持事务,支持数据库崩溃后自动恢复机制
非常安全
最大的特点就是支持事务,已保证数据安全。
Myisam :
它管理的表有以下特征:
使用三个文件表示每个表:
格式文件-存储表结构的定义
数据文件:存储表行的内容
索引文件:存储表上索引(索引:是一本书的内容,缩小扫描范围,)
特点:可被转换为压缩,只读表来节省空间
不支持事务,安全性低
memory:
查询效率高,不需要和硬盘交互,表数据和索引都是在内存之中
不安全,关机后数据消失
innodb存储引擎的具体架构如下:上半部分是实例层(计算层),位于内存中,下半部分是物理层,位于文件系统中。
实例层分为线程和内存。innodb重要的线程有master thread,是innodb 的主线程,复负责调度其它各线程。
buf_dump_thread 负责将buffer pool 中的内容dump到物理文件中,以便再次启动MySQL时,可以快速加热数据。
page_cleaner_thread 负责将buffer pool 中的脏页刷新到磁盘。可以通过参数设置开启多个 page_cleaner_thread.
purge_thread 负责将不再使用的undo日志进行回收。
read_thread 处理用户的读请求,并负责将数据页从磁盘上读取出来,可以通过参数设置线程数量。
write_thread 负责将数据页从缓冲区写入磁盘,也可以通过参数设置线程数量,page_cleaner线程发起刷脏页操作后,write_thread 就开始工作了。
redo_log_thread 负责把日志缓冲中的内容刷新到redo log 文件中。
insert_buffer_thread 负责把insert 中内容刷新到磁盘。
innodb 的内存架构主要分为三大块,缓冲池(buffer pool),重做缓冲池(redo log buffer)和额外内存池。
缓冲池
InnoDB为了做数据的持久化,会将数据存储到磁盘上。但是面对大量的请求时,CPU的处理速度和磁盘的IO速度之间差距太大,为了提高整体的效率, InnoDB引入了缓冲池。
当有请求来查询数据时,如果缓存池中没有,就会去磁盘中查找,将匹配到的数据放入缓存池中。同样的,如果有请求来修改数据,MySQL并不会直接去修改磁盘,而是会修改已经在缓冲池的页中的数据,然后再将数据刷回磁盘,这就是缓冲池的作用,加速读,加速写,减少与磁盘的IO交互。
缓冲池说白了就是把磁盘中的数据丢到内存,那既然是内存就会存在没有内存空间可以分配的情况。所以缓冲池采用了LRU算法,在缓冲池中没有空闲的页时,来进行页的淘汰。但是采用这种算法会带来一个问题叫做缓冲池污染。
当你在进行批量扫描甚至全表扫描时,可能会将缓冲池中的热点页全部替换出去。这样以来可能会导致MySQL的性能断崖式下降。所以InnoDB对LRU做了一些优化,规避了这个问题。
MySQL采用日志先行,在真正写数据之前,会首先记录一个日志,叫Redo Log,会定期的使用CheckPoint技术将新的Redo Log刷入磁盘,这个后面会讲。
除了数据之外,里面还存储了索引页、Undo页、插入缓冲、自适应哈希索引、InnoDB锁信息和数据字典。
扩展三:重点sql记录
hive int转varchar cast(cast(1 as string) as varchar)
insert overwrite 后面不能跟字段
statis_date='${taskid}'
--截取拼接字符串
'h'||substring_index(subsstring_index(sms_zd,'?',1),'https',-1)asnewl
--where后面跟两个条件
where(sms_zdlike'channelCode%转换短链%'orsms_dxlike'from%转换短链%')
--casewhen
nvl(count(casewhensubstr(head_flag,1,4)='ngsh'andreco_acti_amt>0thenreco_serial_numberelsenullend),0)
--百分比
round(sum(nvl(a.day_contact_count,0))/sum(nvl(a.day_target_cust_count,0)),4)*100
一次写入,每次跑都清空表然后新建,之后插入数据:
drop table if exists temp_mk_ceshi1202;
create table temp_mk_ceshi1202(
prov_code varchar(20),
ct int)
;
insert into table csap700.temp_mk_ceshi1202
select
'200'asprov_code,
count(*)cnt
frommmmmm
;
insert into table csap700.temp_mk_ceshi1202
select
'280'asprov_code,
count(*)cnt
frommmmmm
;
带分区的,先删除分区,再添加分区,之后写入。
alter table csap700.ssss drop if exists partition(statis_date='变量');
alter table csap700.ssss add if not exists partition(statis_date='变量');
insert into table csap700.ssss partition(statis_date='变量')
select......
--或者直接按照下面这样写
insert overwrite table csap700.ssss partition(statis_date='变量');
--正则表达式
select *
from ( select staff_id,caller_num,case when caller_num like '%%\_%%' then 1
when caller_num rlike '.*[a-zA-Z]+.*' then 2
when caller_num rlike '[0-9]+' then 3
when caller_num is null then 4 else 5 end aa
from csap.tb_dwd_mk_itmk_contact_dtl_day
where statis_date='20230128'
and head_flag like 'ngsh%'
) a
where aa=2
selectsubstring_index(substring_index(ewrew#sfsdf#https://dev.coc.10086.cn/coc3/canvas/rightsmarket-h5-canvas/online/
zero?channelCode=渠道码
,?,1),#,-2);
SELECTSUBSTRING_INDEX(SUBSTRING_INDEX(aa,?,1),#,-1)ASs
FROMas1114
replace(replace(ziduan,char(10),),char(13),)
selectreplace(replace(fusion_strategy_id,char(10),''),char(13),''),
replace(replace(fusion_strategy_name,char(10),''),char(13),''),
replace(replace(fusion_strategy_name_css,char(10),''),char(13),''),
replace(replace(prov_code,char(10),''),char(13),''),
selectreplace(replace(id,char(10),''),char(13),''),
replace(replace(fusion_strategy_id,char(10),''),char(13),''),
insert into csap700.tb_dim_mk_quanyi_all_day values
('571','浙江','20220606164227504583'),
('571','浙江','20220513113906133894'),
('971','青海','20221104170708652519'),
case when substr(staffid,1,2)='BJ' then '100'
when substr(staffid,1,2)='GD' then '200'
when substr(staffid,1,2)='SH' then '210'
when substr(staffid,1,2)='TJ' then '220'
when substr(staffid,1,2)='CQ' then '230'
when substr(staffid,1,2)='LN' then '240'
when substr(staffid,1,2)='JS' then '250'
when substr(staffid,1,2)='HB' then '270'
when substr(staffid,1,2)='SC' then '280'
when substr(staffid,1,2)='SN' then '290'
when substr(staffid,1,2)='HE' then '311'
when substr(staffid,1,2)='SX' then '351'
when substr(staffid,1,2)='HA' then '371'
when substr(staffid,1,2)='JL' then '431'
when substr(staffid,1,2)='HL' then '451'
when substr(staffid,1,2)='NM' then '471'
when substr(staffid,1,2)='SD' then '531'
when substr(staffid,1,2)='AH' then '551'
when substr(staffid,1,2)='ZJ' then '571'
when substr(staffid,1,2)='FJ' then '591'
when substr(staffid,1,2)='HN' then '731'
when substr(staffid,1,2)='GX' then '771'
when substr(staffid,1,2)='JX' then '791'
when substr(staffid,1,2)='GZ' then '851'
when substr(staffid,1,2)='YN' then '871'
when substr(staffid,1,2)='XZ' then '891'
when substr(staffid,1,2)='HI' then '898'
when substr(staffid,1,2)='GS' then '931'
when substr(staffid,1,2)='NX' then '951'
when substr(staffid,1,2)='QH' then '971'
when substr(staffid,1,2)='XJ' then '991' else '000' end ppp
扩展四:MySQL性能优化
第六节schema设计与管理:
6.1选择优化的数据类型:
MySQL支持的数据类型很多,选择正确的数据类型对于获得高性能至关重要。
--更小的通常更好:因为占用磁盘,内存和cpu缓存的空间更少,并且处理时需要的CPU周期也更少。
--简单为好:简单数据类型的操作通常需要更少的cpu周期,整形要比字符类型数据操作代价更低,因为字符集和排序规则是字符型数据的比较更为复杂。
--尽量避免存储null:因为可以为null的列使得索引,索引统计和值的比较都更为复杂。可为空的null的列会使用更多的存储空间,在MySQL里面也需要特殊处理。通常把null改为not null的提升较小,(调优时),所以不是首选。
6.2整数类型:
整数,实数(带小数),如果存储整数可用:tinyint,smallint,mediumint,int或者bigint,他们分别使用 8,16,24,32,64位存储空间,可以存储的值的范围从-2(n--1)到2(n-1)-1次方,N代表存储空间的位数。
整数类型有可选的unsigned属性,表示不允许负值,这大致可以使正数的上限提高一倍。tinyint unsigned 范围 0-255,tinyint 范围 -128-127.有符号类型和无符号类型使用相同的存储空间,并具有相同的性能,可根据数据实际情况选择合适的类型。
6.3实数类型:
浮点类型通常比decimal使用更少的空间来存储相同范围的值。float使用4字节的存储空间,double占用8字节,比float具有更大对的精度和更大的值范围。与整数类型一样,你只能选择存储类型,MySQL会使用double进行浮点类型的内部计算。尽量只对小数进行精确计算时才使用decimal,或者用bigint代替,然后根据小数位数乘以10的倍数,然后将结果存储在bigint里面,这样可以同时避免浮点存储计算不精确和decimal精确计算代价高的问题。
6.4字符串类型
varchar char ,很难解释这些值是如何存储在磁盘和内存中的,因为这跟存储引擎的具体实现与关。
varchar存储可变长长度的字符串,他比固定长度更节省空间,因为他仅使用必要的空间。它需要额外使用一到两个字节存储字符串长度信息。缺点是由于行是可变长度的,在更新时可能会增长,这会导致额外的工作。
适合使用:列的最大长度远远大于平均长度,列的更新很少。
char:固定长度,适合存储非常短的字符串,或者长度都差不多的字符串。经常修改的数据,因为固定长度的行不容易出现碎片。对于非常短的列,插char比V更高效;
与他们类似的还有 binary 和 varbinary。
varchar 10 和 1000 空间开销是一样的,10有什么优势:节省内存。
BLOB和TEXT类型:都是为了存储数据很大的数据来设计的,前者二进制,没有排序规则或者字符集,后者有的。该类型不能把完整字符串放入索引,也不能使用索引进行排序。
6.5日期和时间类型:
datetime:范围 1000-9999 精度为 1毫秒,以 YYYYMMDDHHMMSS格式压缩成整数的时间和日期和时间,且与时区无关。这需要8字节的存储空间。默认情况下,MySQL可以排序,无歧义的格式显示datetime值。
timestamp:使用 4字节的存储空间,他的范围比前者小很多只能表示1970-20380119范围。比前者的特殊性:当插入数据的时候没有指定timestamp的值,MySQL会将该列的值设置为当前时间。
6.6位压缩数据类型--暂不记录
6.7 json数据类型--暂不记录
第7章创建高性能的索引:
索引:在MySQL中也叫做键,是存储引擎用于快速找到记录的一种数据结构。
优点:索引大大减少了服务器需要扫描的数据量。
索引可以帮助服务器避免排序和临时表。
索引可以将随机I/O 变为顺序I/O。
索引的选择性是指索引的基数比上总行数。0-1之间,索引的选择性越高查询效率越高,因为选择性高可以过滤更多的行。唯一索引的选择性就是1,这是最好的索引选择性,性能也是最好的。
前缀索引:只对字段的前一部分字符进行索引,缺点是会降低索引的选择性。
多列索引:把多个列当成一个索引来使用。
聚簇索引:并不是一种单独的索引类型,而是一种数据存储方式,一个表只能有一个聚簇索引。
如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为覆盖索引。















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









