







ufldl学习笔记与编程作业:Multi-Layer Neural Network(多层神经网络+识别手写体编程)
ufldl出了新教程,感觉比之前的好,从基础讲起,系统清晰,又有编程实践。
在deep learning高质量群里面听一些前辈说,不必深究其他机器学习的算法,可以直接来学dl。
于是最近就开始搞这个了,教程加上matlab编程,就是完美啊。
新教程的地址是:http://ufldl.stanford.edu/tutorial/
本节学习地址:http://ufldl.stanford.edu/tutorial/supervised/MultiLayerNeuralNetworks/
神经网络一般求解过程:
1 正向传播,把每一层的激活值求出来,还有总的cost。
基本上,隐藏层的激活值都是加权和再加上bias,再激活函数比如sigmoid。
输出层的激活值,也许不叫激活值,叫特征值更好。以softmax为例,是将上一层的激活值作为特征输入X,将权重W作为theta参数,根据公式算出h。
2 反向传播。
先计算输出层的残差。这个可以根据损失函数直接求导。
由l+1层的残差和l层的激活值,即可求得l层的W和b的梯度。
由l+1层的残差和l层的W,还有l层激活函数的偏导数,即可求得l层的残差。
4 更新参数W和b
5 加入权重衰减项防止过拟合。求cost和梯度的时候,需要做相应的调整。
下面是supervised_dnn_cost.m的代码:
function [ cost, grad, pred_prob] = supervised_dnn_cost( theta, ei, data, labels, pred_only)
%SPNETCOSTSLAVE Slave cost function for simple phone net
% Does all the work of cost / gradient computation
% Returns cost broken into cross-entropy, weight norm, and prox reg
% components (ceCost, wCost, pCost)
%% default values
po = false;
if exist('pred_only','var')
po = pred_only;
end;
%% reshape into network
numHidden = numel(ei.layer_sizes) - 1;
numSamples = size(data, 2);
hAct = cell(numHidden+1, 1);
gradStack = cell(numHidden+1, 1);
stack = params2stack(theta, ei);
%% forward prop
%%% YOUR CODE HERE %%%
for l=1:numHidden %隐藏层特征计算
if(l == 1)
z = stack{l}.W*data;
else
z = stack{l}.W*hAct{l-1};
end
z = bsxfun(@plus,z,stack{l}.b);
hAct{l}=sigmoid(z);
end
%输出层(softmax)特征计算
h = (stack{numHidden+1}.W)*hAct{numHidden};
h = bsxfun(@plus,h,stack{numHidden+1}.b);
e = exp(h);
pred_prob = bsxfun(@rdivide,e,sum(e,1)); %概率表
hAct{numHidden+1} = pred_prob;
%[~,pred_labels] = max(pred_prob, [], 1);
%% return here if only predictions desired.
if po
cost = -1; ceCost = -1; wCost = -1; numCorrect = -1;
grad = [];
return;
end;
%% compute cost 输出层softmax的cost
%%% YOUR CODE HERE %%%
ceCost =0;
c= log(pred_prob);
%fprintf("%d,%d\n",size(labels,1),size(labels,2)); %60000,1
I=sub2ind(size(c), labels', 1:size(c,2));%找出矩阵c的线性索引,行由labels指定,列由1:size(c,2)指定,生成线性索引返回给I
values = c(I);
ceCost = -sum(values);
%% compute gradients using backpropagation
%%% YOUR CODE HERE %%%
% Cross entroy gradient
%d = full(sparse(labels,1:size(c,2),1));
d = zeros(size(pred_prob));
d(I) = 1;
error = (pred_prob-d); %输出层的残差
%梯度,残差反向传播
for l = numHidden+1: -1 : 1
gradStack{l}.b = sum(error,2);
if(l == 1)
gradStack{l}.W = error*data';
break;%l==1时,即当前层是第一层隐藏层时,不需要再传播残差
else
gradStack{l}.W = error*hAct{l-1}';
end
error = (stack{l}.W)'*error .*hAct{l-1}.* (1-hAct{l-1});%后面部分是激活函数偏导数
end
%% compute weight penalty cost and gradient for non-bias terms
%%% YOUR CODE HERE %%%
wCost = 0;
for l = 1:numHidden+1
wCost = wCost + .5 * ei.lambda * sum(stack{l}.W(:) .^ 2);%所有权值的平方和
end
cost = ceCost + wCost;
% Computing the gradient of the weight decay.
for l = numHidden : -1 : 1
gradStack{l}.W = gradStack{l}.W + ei.lambda * stack{l}.W;%softmax没用到权重衰减项
end
%% reshape gradients into vector
[grad] = stack2params(gradStack);
end
原来训练集是60000条,有点费时间,我改了run_train.m代码,把训练集改了10000条。
当然影响了准确度。
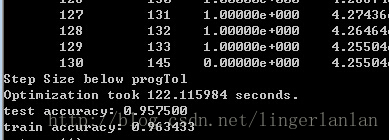
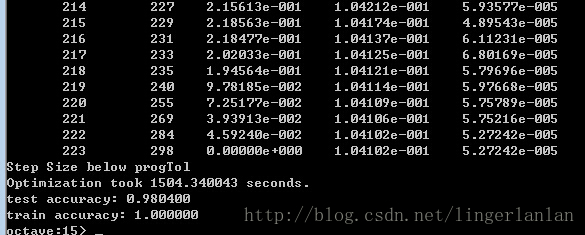
恢复源代码,拿60000条做训练集,结果如下:
本文作者:linger
本文链接:http://blog.csdn.net/lingerlanlan/article/details/38464317















 1031
1031

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









