







lec 1:Regression
1.5 Linear neural networks for regression线性神经网络的回归

1.5.1 Linear regression
输入特征的仿射变换Affine transformation(特征的加权和的线性变换和附加偏差的变换)

损失函数为平方误差squared error:
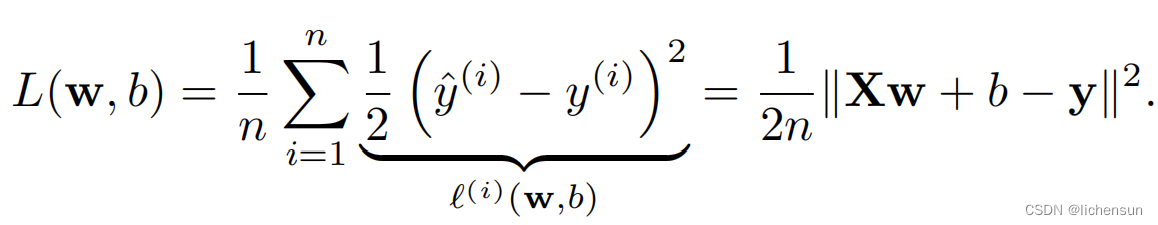

当训练模型时,找到在所有训练例子中使平均损失最小的参数(w∗,b∗):


即使我们不能解析地求解模型,我们仍然可以使用梯度下降算法来训练模型(迭代更新参数的方向,逐步降低损失函数)。
损失函数的导数是数据集中每个示例的损失的平均值。非常慢,因为我们必须通过整个数据集来进行更新。
1.5.2 Minibatch stochastic gradient descent 小批量随机梯度下降
策略:做一小批(Minibatch)观察。大小(size)取决于许多因素(内存、加速器的数量、图层的选择、总数据集的大小)。32到256之间,2^m(2的m次幂)这样的形式是一个好的开始。
●小批量随机梯度下降(SGD):
初始化参数。在每次迭代t中,
用|B|训练示例随机抽样一个小批量Bt;
计算小批量w.r.t.的平均损失梯度因素;
使用η作为学习速率,执行更新:

小批量处理的大小和学习率是由用户定义的。这种在训练循环中没有更新的可调参数被称为超参数(hyperparameters)。
经过多次迭代训练后,我们记录了估计的参数(ˆw,ˆb)。这些不是损失的最小化。
1.5.3 Maximum likelihood estimation最大似然估计
最小化平方误差损失相当于线性模型在加性高斯噪声下的最大似然估计:

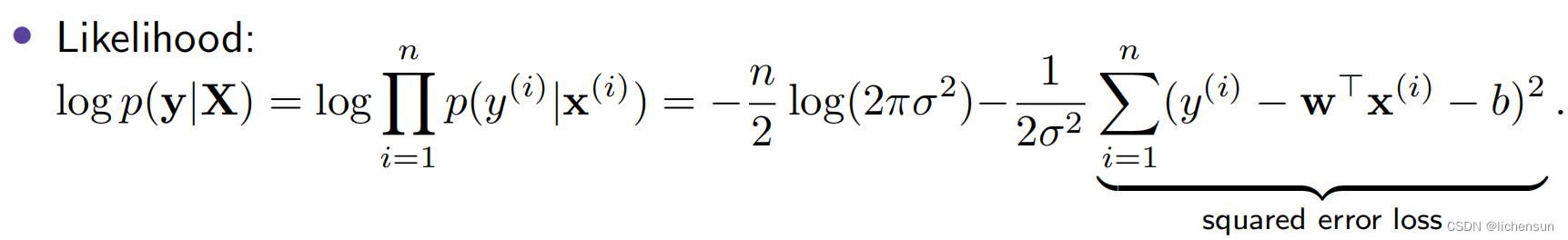
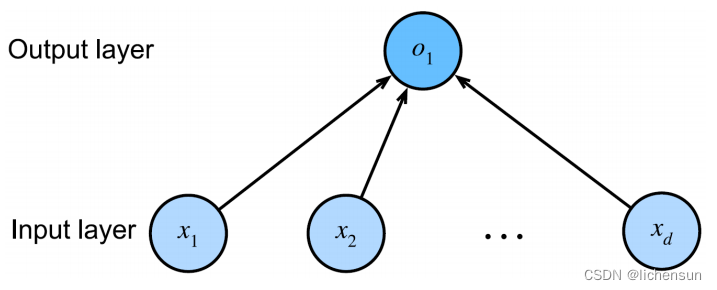
线性回归是一个单层全连接的神经网络,有d个输入:x1,……,xd 和一个单一的输出。
1.5.4 Synthetic data合成数据
从标准正态set(X∈R^1000×2)中生成1000个examples,用于训练集和验证集。
设置w = [2,−3.4]^T,b=4.。绘制ε~N(0,0.01²)。
#Synthetic data
import random
import torch
from d2l import torch as d2l
data = d2l.SyntheticRegressionData(w=torch.tensor([2,-3.4]), b=4.2,
noise=0.01, num_train=1000, num_val=1000, batch_size=32)模型训练需要多次传递一个数据集,每次使用一个小批处理来更新模型。数据处理器生成批量大小(batch_size)的小批量。每个小批处理都是一个特征和标签的元组。
在训练train模式下,我们以随机的顺序读取数据。在验证test模式下,按预定义的顺序读取数据可能对调试很重要。
X, y = next(iter(data.train_dataloader())) # inspect first minibatch
X.shape, y.shape # X: [32, 2], y: [32, 1]
len(data.train_dataloader()) # no. of batches: 321.5.5 Implementing linear regression 线性回归的实现
使用具有学习率lr=0.03和max_epochs=3的小批量SGD训练线性回归模型。在每个epoch中,我们遍历整个训练数据集,并通过每个示例传递一次。在每个epoch结束时使用验证数据集来测量模型的性能。
通过从N(0,0.01²)采样来初始化权重,并将偏差设置为0。
model = d2l.LinearRegression(lr=0.03)
trainer = d2l.Trainer(max_epochs=3)
trainer.fit(model, data)
w, b = model.get_w_b()
#compute differences
data.w - w.reshape(data.w.shape)
data.b - b
# error in estimating w: tensor([0.0025, -0.0070])
# error in estimating b: tensor([0.0096])
图中结果表明:估计的参数接近于真值。
•对于深度模型,不存在参数的唯一解。在机器学习中,我们不太关心恢复真正的基础参数,而是更关心能够导致准确预测的参数。
1.5.6 Generalization泛化
机器学习的基本问题是:发现能够泛化的模式。拟合更接近训练数据而不是基本分布的现象是过拟合overfitting,而对抗过拟合的技术被称为正则化regularization。
在标准的监督学习中,我们假设训练数据和测试数据是从相同的分布中独立地抽取的。
训练误差Training error:根据训练集计算的统计量,

泛化错误Generalization error:一个期望的w.r.t.基础分布,
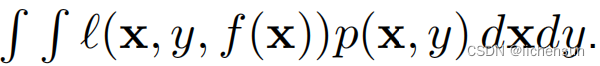
通过将模型应用于独立的测试集来估计泛化误差.
当我们有简单的模型和丰富的数据时,训练误差和泛化误差往往会很接近。当我们使用更复杂的模型或更少的例子时,我们期望训练误差会减少,但泛化差距会增加。
深度神经网络在实践中可以很好地推广,但它们太强大了,我们无法仅根据训练错误就得出结论。我们必须依靠验证(保留数据)错误来证明泛化。
——————————————————————————————————————————
当训练误差和验证误差很大,且它们之间的差距很小时,可能会出现不拟合的情况underfitting(模型表达不足)。
训练误差显著低于验证误差表示过拟合。
使用一个d度的多项式: 来估计给定单一特征x的标签y。
来估计给定单一特征x的标签y。
高阶多项式的训练误差总是较低的。一个具有d = n的多项式可以完美地拟合训练集。

随着我们增加训练数据时,泛化误差通常会减少。如果有更多的数据,我们可以拟合更复杂的模型。只有当有成千上万的训练例子可用时,深度学习才优于线性模型。
当训练数据稀缺时,我们可能没有足够的保留数据。在K倍交叉验证中,数据被分成K个不重叠的子集。模型训练和验证执行K次,每次在K−1个子集上进行训练,并对未使用的子集进行验证。训练和验证误差的估计是平均了K个实验的结果。
1.5.7 Weight decay 权重衰减
权重衰减可以通过限制参数采取的值来缓解过拟合。为了将w缩小到零,将其范数作为惩罚项(penalty term)添加到最小化损失的问题中:

正则化常数λ≥0是使用验证集选择的一个超参数。越小的λ对应于约束越小的w。我们通常不规范(正则化)偏差项b。
w的小批量SGD更新变为:

 从上述方程式中生成数据,为了使过拟合效果更明显,设置n = 20和d = 200。
从上述方程式中生成数据,为了使过拟合效果更明显,设置n = 20和d = 200。
定义其中的类、数据和权重衰减:
#如何使用权重衰减(weight decay)来正则化模型
#定义了一个L2正则化项的函数l2_penalty,用来计算权重w的L2范数的平方除以2
def l2_penalty(w):
return (w**2).sum() / 2
#创建数据集data
data = Data(num_train=20, num_val=100,num_inputs=200, batch_size=5)
trainer = d2l.Trainer(max_epochs=10)
#创建了一个WeightDecay模型对象model,并将权重衰减参数wd设置为0,学习率lr设置为0.01。(对照)
model = WeightDecay(wd=0, lr=0.01)
#通过将model.board.yscale设置为'log',可以在训练过程中将损失函数的值以对数尺度显示
#有助于观察权重衰减的效果。
model.board.yscale='log'
trainer.fit(model, data)
l2_penalty(model.get_w_b()[0]) # 0.1318
#重新创建了一个WeightDecay模型对象model,将权重衰减参数wd设置为3,学习率lr设置为0.01(实验)
model = WeightDecay(wd=3, lr=0.01)
model.board.yscale='log'
trainer.fit(model, data)
l2_penalty(model.get_w_b()[0]) # 0.0145 比0.1318降低很多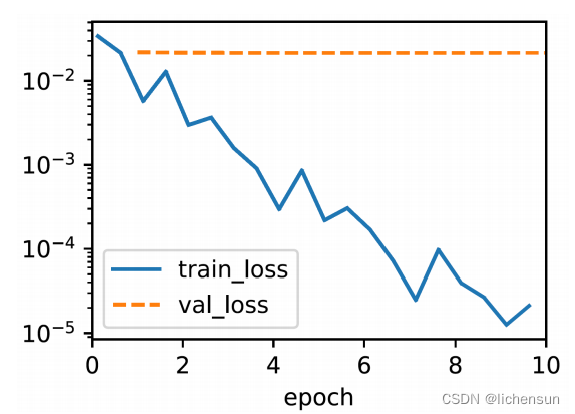

在没有使用权值衰减时,我们非常糟糕的过拟合了。
随着权值的衰减,训练误差增加,而验证误差减小。
lec2:Multilayer Perceptrons 多层感知器
2.1 Linear neural networks for classification用线性神经网络进分类
◆图像分类:
- 每个输入都是一个2×2的灰度图像。
- 每个像素用一个标量表示,给出四个特征x1,x2,x3,x4。
- 每张图片都属于三类:猫、鸡、狗。
- 使用一个热编码表示标签:y是一个3-dim向量,(1、0、0)表示猫,(0、1、0)表示鸡,(0、0、1)表示狗。
- 线性模型:

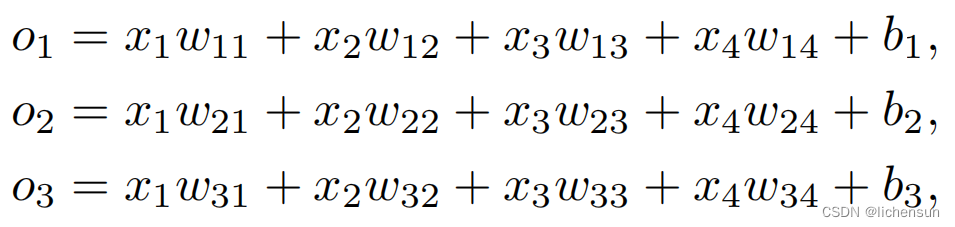
- 相应的神经网络与单层完全连接。
- 给定一个合适的损失函数,我们可以最小化o和y之间的差值。将分类作为回归问题处理得很好,但是输出oi不能等于1或在[0,1]中。
要实现此目标,使用softmax函数:

为了提高效率,在小批量中向量化计算。对于小批量X(n×d维:n examples with d inputs)以及输出中的q个类别,
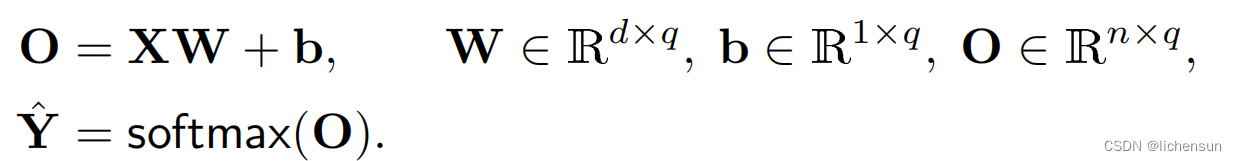
利用最大似然估计来优化从特征x到概率ˆy的映射精度。

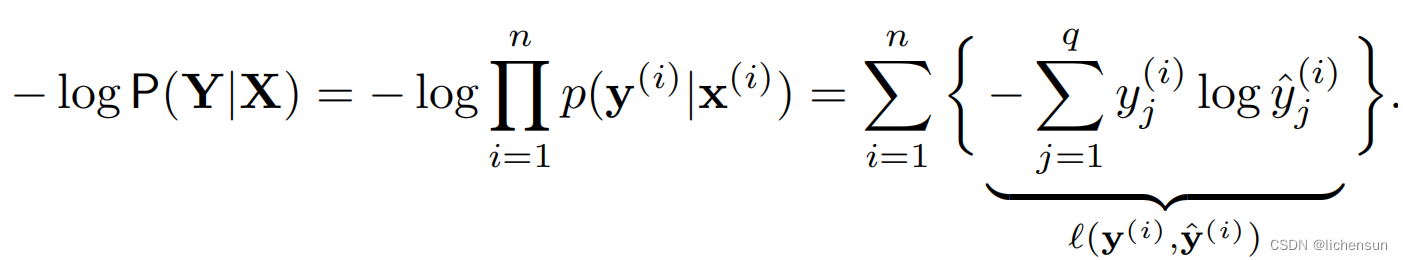
2.1.1 Softmax and cross-entropy lossSoftmax和交叉熵损失
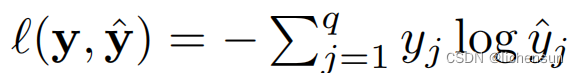
由于y是长度为q的独热向量,除一项外,所有j的和都消失了。
插入softmax的定义,

导数是模型分配的概率与观测值之间的差值。
对于一个分布P,它的熵是:![]()
从P到Q的交叉熵是: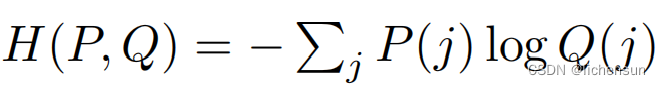
当P=Q时,交叉熵是最低的。
2.1.2 Image classification dataset 图像分类数据集
#使用了PyTorch和d2l库来加载FashionMNIST数据集
import torch; import torchvision
from torchvision import transforms
from d2l import torch as d2l
d2l.use_svg_display() # output graphics in SVG format 设置d2l库使用SVG格式输出图形。
data = d2l.FashionMNIST(resize=(32, 32)) # upscale to 32 x 32 via interpolation
len(data.train) # 60000
len(data.val) # 10000
data.train[0][0].shape # [1, 32, 32]
batch = next(iter(data.val_dataloader())) # 1st batch of validation set
data.visualize(batch) # 1: white, 0:black约定:将图像存储为c×h×w张量,其中c为颜色通道数,h是高度,w是宽度。

2.1.3 Implement softmax regression 实现softmax回归
- 将每张28×28像素的图像折叠起来,作为长度为784的输入向量。
- 输出的个数为10,等于类的数目。
- 权重构成一个784×10矩阵加上一个1×10行的偏差向量。
- 用高斯噪声和偏差将权值初始化为零。
- 训练模型使用10个epoch。epoch数目,小批量大小和学习率都是超参数hyperparameters,并应根据实践中的验证集进行选择。然后在测试集上评估模型的最终结果。
#训练一个Softmax回归模型来对FashionMNIST数据集中的图像进行分类
from torch import nn
from torch.nn import functional as F
data = d2l.FashionMNIST(batch_size=256)
#构建一个具有10个输出类别的Softmax回归模型,并设置学习率为0.1
model = d2l.SoftmaxRegression(num_outputs=10, lr=0.1)
trainer = d2l.Trainer(max_epochs=10)
trainer.fit(model, data)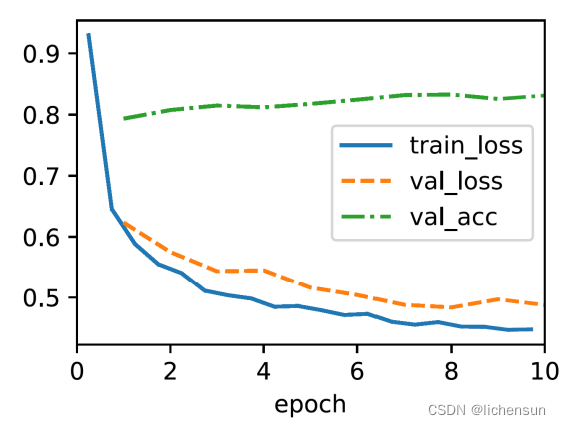
2.1.4 Prediction 预测
使用训练好的模型对一些图像进行分类。
#从验证集中获取第一个批次数据,
#然后使用训练好的Softmax回归模型对这批数据进行预测,
#并可视化预测结果中被错误分类的样本
X, y = next(iter(data.val_dataloader())) # 1st batch of validation set, batch_size=256
model(X).shape # torch.Size([256, 10])
#对每个样本,选择具有最高概率的类别作为预测结果
preds = model(X).argmax(axis=1) # find class with highest prob for each eg
#返回一个形状为[256]的张量 表示每个样本的预测类别
preds.shape # torch.Size([256])
#找出预测错误的样本,返回一个布尔型张量,形状与preds和y相同,对应位置为True表示预测错误
wrong = (preds != y) # find egs whose classes are predicted wrongly
#根据预测错误的布尔掩码,从原始数据中提取预测错误的样本
#分别存储为X(图像数据)、y(真实标签)、preds(预测标签)
X, y, preds = X[wrong], y[wrong], preds[wrong]
#将真实标签和预测标签拼接成字符串列表,用于可视化时显示每个样本的真实类别和预测类别。
labels = [a + '\n' + b for a, b in zip(data.text_labels(y), data.text_labels(preds))]
#可视化
data.visualize([X, y], labels=labels)通过比较实际的标签(文本输出的第一行)与模型的预测(文本输出的第二行),可视化一些错误标记的图像。

2.2 Multilayer perceptrons 多层感知器
- 最简单的深度网络是多层感知器(由多层神经元组成,每个神经元都与下面和上面的一层完全相连)。
- 线性模型暗示了单调性(一个特征的增加必须导致输出的增加/减少),但其他特征是固定的。
- 有时这是有道理的,但违反单调性的例子却很丰富。在对猫和狗的图像进行分类时,增加一个像素的强度是否总是增加/减少图像描绘一只狗的可能性?
- 如何用简单的转换来解决这个问题并不明显,因为任何像素的重要性都以复杂的方式取决于周围的像素。
- 通过合并隐藏层,将完全连接的层相互叠加,克服了线性模型的局限性。每一层都输入到它上面的一层中,直到我们生成输出。这是多层感知器(MLP)的架构。
2.2.1 Incorporating hidden layers 合并隐藏层
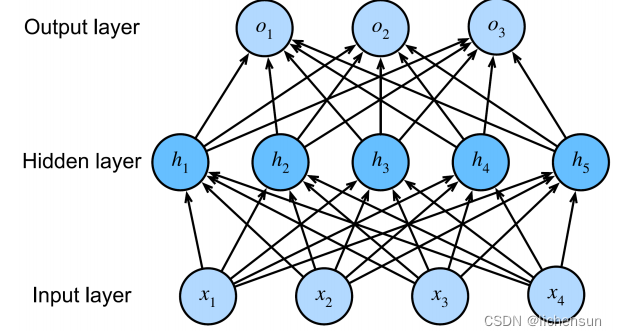
- 这个MLP有4个输入,3个输出,隐藏层有5个隐藏单元。
- 输入层不涉及计算。产生输出需要计算隐藏层和输出层。因此,在这个MLP中的层是2。这两层都是完全连接的。
- 总共有n个例子,每个例子都有d个输入。
- 对于具有h隐藏单元的单隐藏层MLP,
 表示隐藏层的输出。
表示隐藏层的输出。
- 添加隐藏层不会获得任何好处。上面的MLP仍然是一个线性模型!
- 为实现多层结构潜力,关键成分是在仿射变换后对每个隐藏单元应用非线性激活函数σ(·)。
- 有了激活函数,我们就不能再把MLP分解成线性模型了:

- 定义σ(·),以按元素的方式应用于其输入。
- 为了构建更通用的MLPs,堆栈隐藏层,
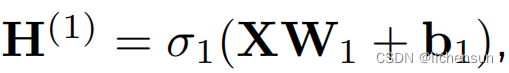
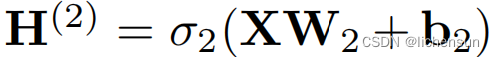 ,...,一个接一个地产生更具表现力的模型。
,...,一个接一个地产生更具表现力的模型。 - 一个单一的隐层网络可以通过给定足够的节点和正确的权值集来建模任何函数,但我们不应该用它来解决每个问题,因为我们可以使用更深(相对于更宽)的网络来更紧凑地近似许多函数。
2.2.2 Activation functions 激活函数
激活函数增加了非线性,是将输入信号转换为输出的可微算符。
★ReLU (整流线性单元rectified linear unit) function
- ReLU(x) = max(x, 0).
- 最流行的选择(简单实现,在各种预测任务上具有良好的性能)。
- 当x<0时,导数为0,当x>0时为1。在0处不可微,但我们说导数在x=值0处是0。
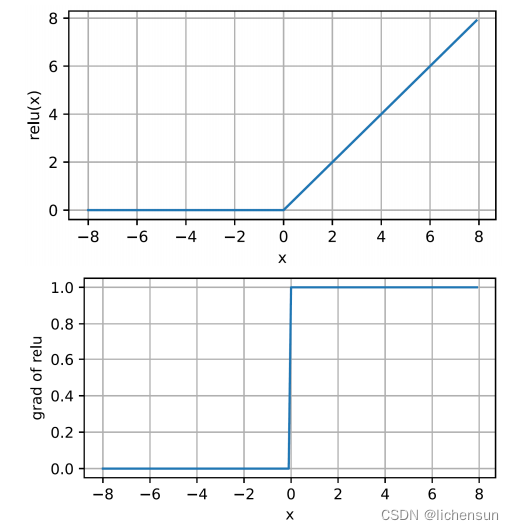
- 它的导数表现得很好(消失或让参数通过)。这使得优化表现得更好,并缓解了困扰早期神经网络的梯度消失的问题。
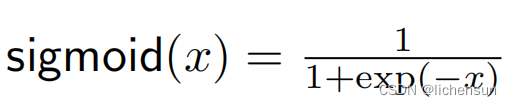

- 将R中的任何输入压缩为(0,1)中的值。
- 在早期的神经网络中,科学家们对模拟是否点火的生物神经元很感兴趣。
- 对阈值激活的平滑近似(输入<阈值时为0,输入>阈值时为1)。
-
当输入接近于0时,接近一个线性变换。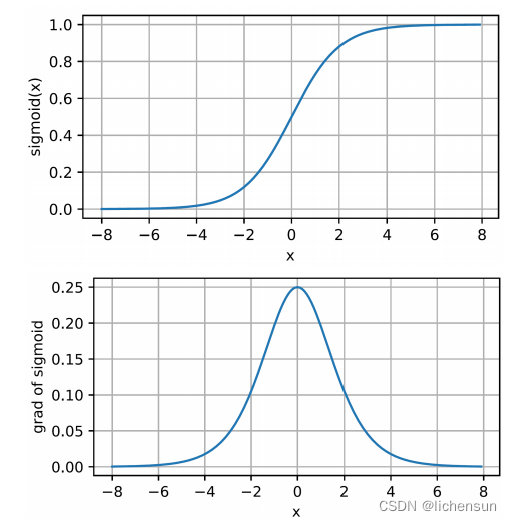
- 给优化带来了挑战,因为它的梯度为大的积极和消极的参数消失,导致难以摆脱的高原。
- 当我们想将输出解释为二进制分类中的概率(softmax的特殊情况)时,作为输出单元上的激活函数使用。
★Tanh (双曲切线hyperbolic tangent) function
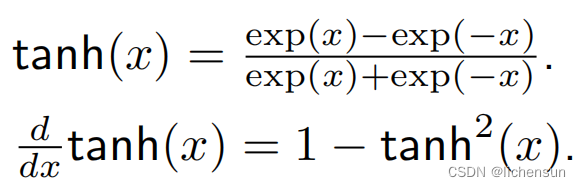
- 将R中的任何输入压缩为(−1,1)中的值。
- 当输入接近0时接近线性变换。
- 形状与s型相似,但tanh对原点呈点对称。
- 当输入接近于0时,导数接近于最大值1。当输入在任何一个方向上远离0时,导数趋于0。
2.2.3 Implement MLPs 实现MLPs
mlp的实现并不比线性模型复杂多少。关键的区别在于:连接多个层并应用激活函数。
时尚-MNIST有10个class。每幅图像都有一个28×28 = 784的灰度像素值网格。
MLP:一个隐藏层和256个隐藏单元。不的层和宽度是可调的。
选择宽度为2^m形式(由于硬件中的内存分配,计算效率高)。
class MLP(d2l.Classifier):
def __init__(self, num_outputs, num_hiddens, lr):
#调用父类(Classifier类)的初始化方法,确保正确初始化。
super().__init__()
#保存模型的超参数,以便在需要时进行访问和记录。
self.save_hyperparameters()
#定义了一个包含两个隐藏层的神经网络模型
#包括一个Flatten层(用于将输入数据展平)、两个LazyLinear层(延迟初始化的全连接层)、一个ReLU激活函数层。
self.net = nn.Sequential(nn.Flatten(), nn.LazyLinear(num_hiddens),
nn.ReLU(), nn.LazyLinear(num_outputs))
data = d2l.FashionMNIST(batch_size=256)
#创建一个MLP模型对象,指定输出类别数为10,隐藏层单元数为256,学习率为0.1。
model = MLP(num_outputs=10, num_hiddens=256, lr=0.1)
trainer = d2l.Trainer(max_epochs=10)
trainer.fit(model, data)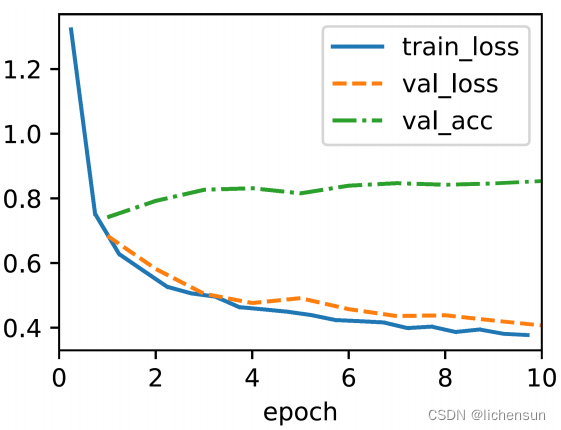
2.3 Forward and backward propagation 正向传播和反向传播
在训练神经网络时,在初始化模型参数后,交替进行正传播和反向传播。
前向传播:按从输入层到输出层的顺序计算和存储神经网络的中间变量。
反向传播:利用链规则从输出到输入层计算参数的梯度。存储了计算梯度时所需的中间偏导数。
神经网络有一个隐藏层,无偏差和输入![]()
有向图:可视化变量的依赖性。

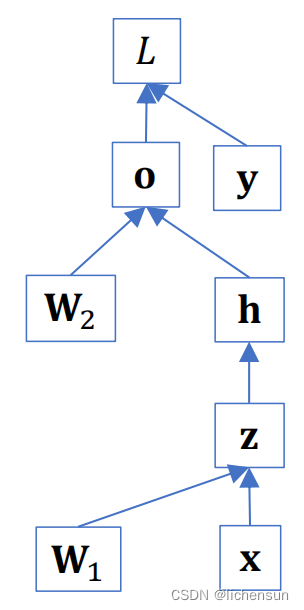
反向传播的目标:计算梯度
从结果开始,并努力走向参数。v(·)从左到右依次向量化一个矩阵。
![]()

反向传播重用正向传播中存储的中间值,以避免重复计算。
需要保留中间值,直到反向传播完成为止。
因此,训练需要更多的记忆,而不是预测。
中间值的大小大致与图层和批处理的大小成正比。因此,使用更大的批处理规模来训练更深层次的网络会更容易导致内存耗尽错误。
2.4 Numerical stability and initialization 数值稳定性和初始化
初始化对于神经网络学习中的数值稳定性至关重要。
它与非线性激活函数的选择有关,并决定了算法收敛的速度。
糟糕的选择会导致在训练时的梯度爆炸/消失。
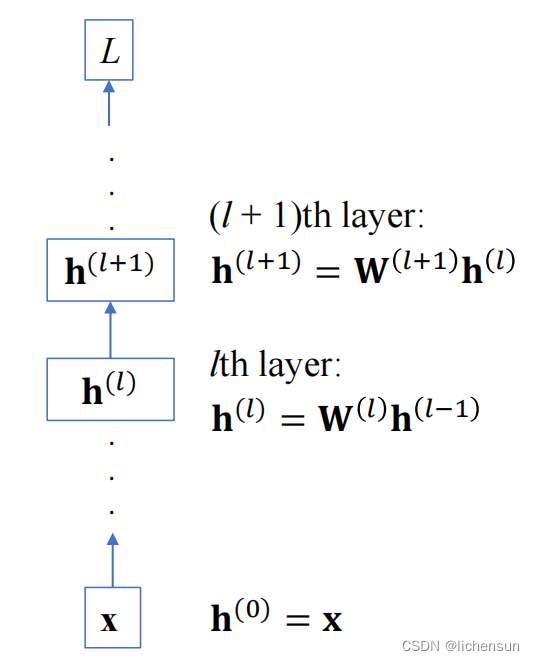
考虑具有L层、输入x和输出o的深度网络。对于每个层ℓ,定义由权重Wℓ参数化的转换fℓ,具有隐藏层输出![]() 令
令![]() 那么,
那么,![]()
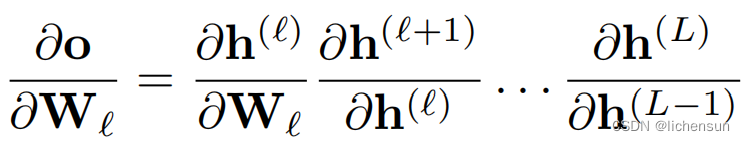
易受数值下积问题的许多项可能很大或很小。
不可预测的幅度梯度威胁着算法的稳定性。参数更新可能过大(爆炸梯度问题)或过小(消失梯度问题),使得学习变得不可能。

![]()
2.4.1 Motivation of Xavier initialization
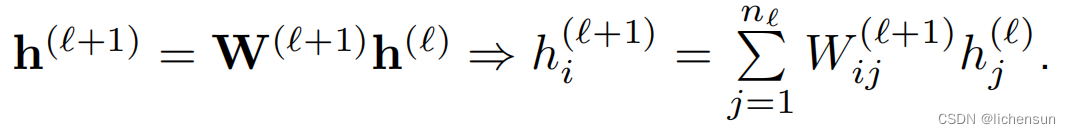
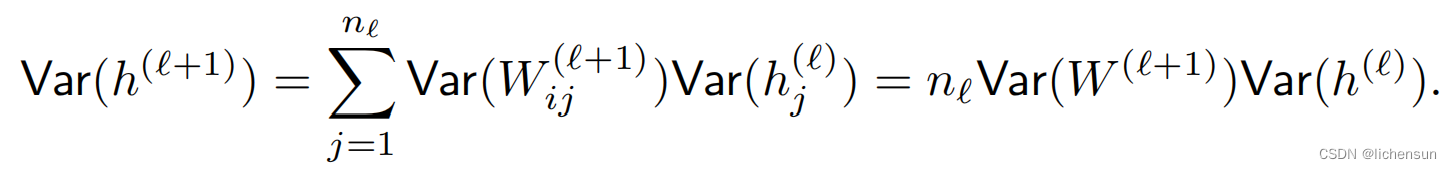
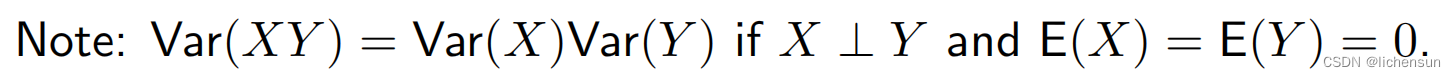
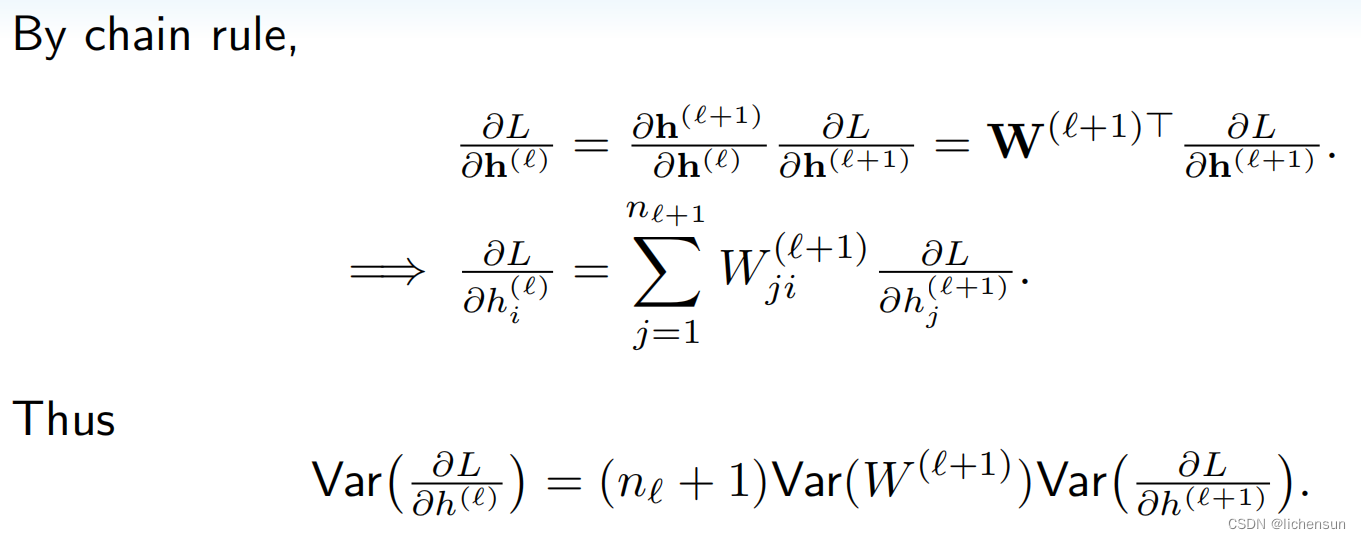
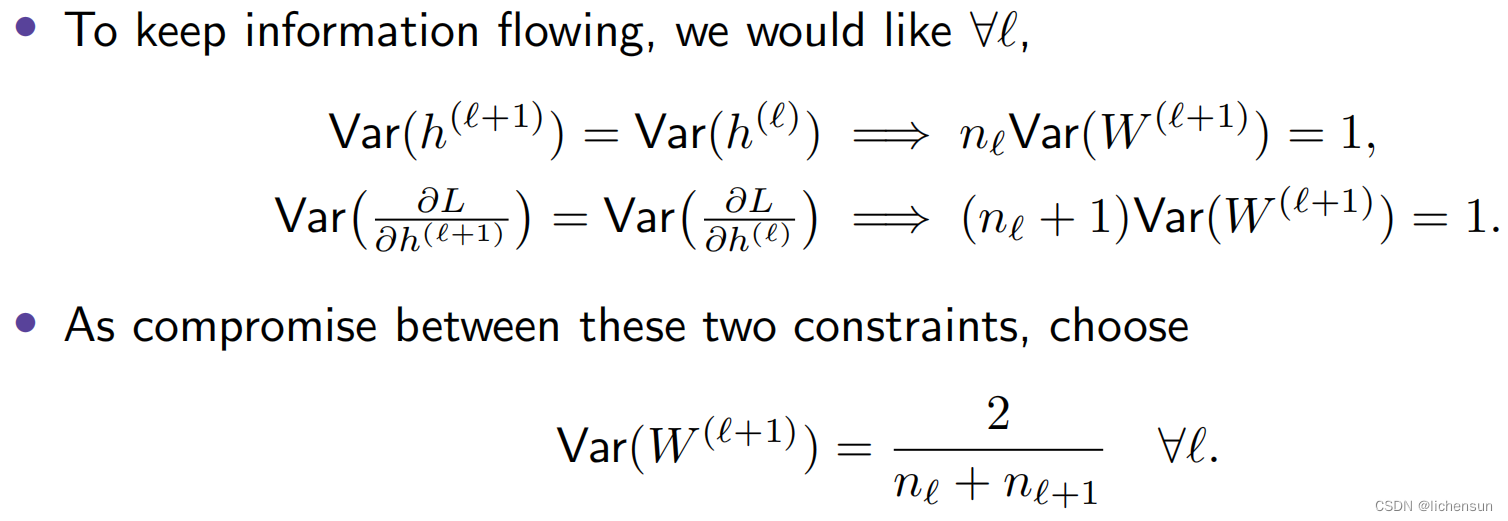
2.5 Generalization in deep learning 深度学习中的泛化
2.6 Dropout
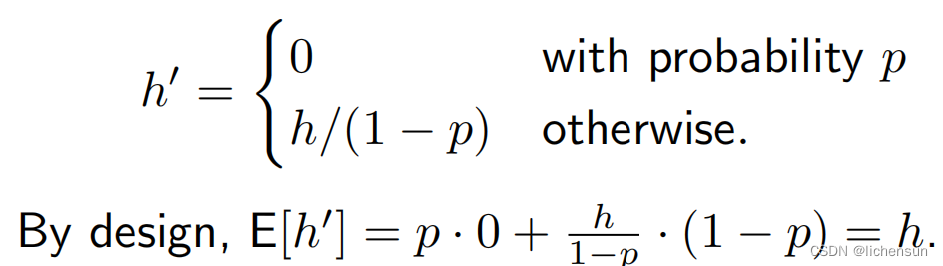
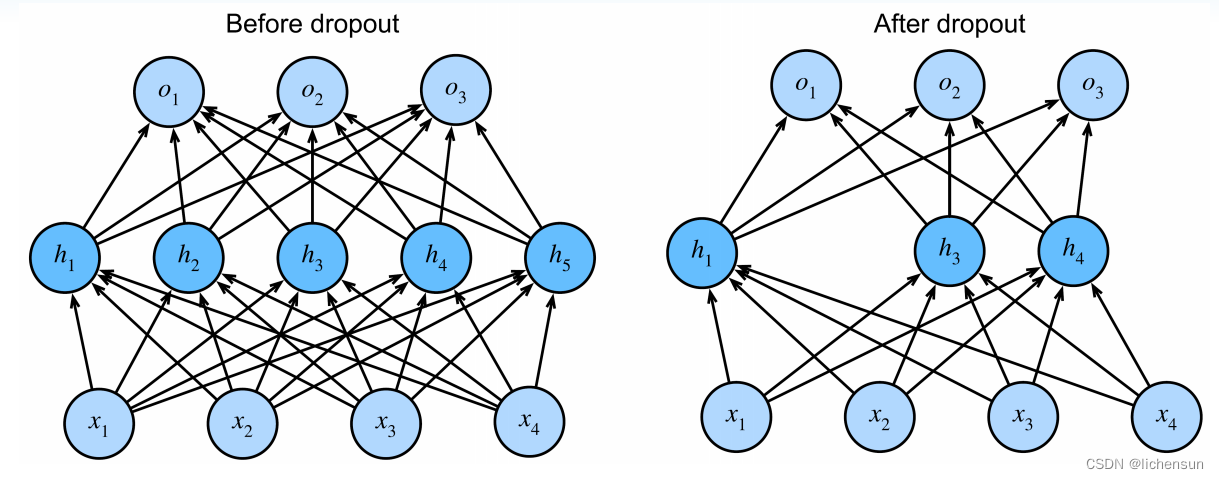
2.6.1 Implementing dropout
#定义一个带有Dropout层的MLP模型,并在FashionMNIST数据集上进行训练,用于图像分类任务
#Dropout层有助于减少过拟合
#加载数据集
data = d2l.FashionMNIST(batch_size = 256)
#定义了一个字典hparams,包含了模型的超参数
hparams = {'lr':0.1, 'num_outputs':10, 'num_hiddens_1':256,'num_hiddens_2':256, 'dropout_1':0.5, 'dropout_2':0.5}
#定义分类器模型
class DropoutMLP(d2l.Classifier):
def __init__(self, num_outputs, num_hiddens_1, num_hiddens_2, dropout_1, dropout_2, lr):
super().__init__()
self.save_hyperparameters()
#定义了一个包含两个隐藏层和两个Dropout层的神经网络模型
#具体结构为:Flatten层、LazyLinear层(隐藏层1)、ReLU激活函数、Dropout层、LazyLinear层(隐藏层2)、ReLU激活函数、Dropout层、LazyLinear层(输出层)。
self.net = nn.Sequential(nn.Flatten(),
nn.LazyLinear(num_hiddens_1), nn.ReLU(), nn.Dropout(dropout_1),
nn.LazyLinear(num_hiddens_2), nn.ReLU(), nn.Dropout(dropout_2),
nn.LazyLinear(num_outputs))
model = DropoutMLP(**hparams)
trainer = d2l.Trainer(max_epochs=10)
trainer.fit(model, data)
2.7 Predict house prices on Kaggle
import pandas as pd
data = KaggleHouse(batch_size=64)
data.raw_train.shape # (1460, 81)
data.raw_val.shape # (1459, 80)
data.raw_train.iloc[:4, [0, 1, 2, 3, -3, -2, -1]]
#Discrete values: Replace by one-hot encoding.
data.preprocess()
data.train.shape
#Use cross-validation (CV) to select model design
trainer = d2l.Trainer(max_epochs=10)
models = k_fold(trainer, data, k=5, lr=0.01)
# Compute predictions for validation set based on each trained model
preds = [model(torch.tensor(data.val.values, dtype=torch.float32)) for model in models]

练习:Fashion-MNIST数据包含属于10个类别的28x28幅灰度图像,这些图像在被输入包含256个隐藏单元的MLP中之前首先被压平。MLP中有多少参数?
在将图像输入到包含256个隐藏单元的MLP之前,图像被压平为大小为784的向量。
MLP的参数数量取决于其架构。假设MLP包含一个输入层(784个输入单元)、一个隐藏层(256个隐藏单元)和一个输出层(10个输出单元,对应10个类别)。对于具有一个隐藏层的MLP,其参数数量可以计算为:
- 输入层到隐藏层的权重矩阵:784(输入单元) × 256(隐藏单元) = 200704个参数
- 输入层到隐藏层的偏置:256个参数
- 隐藏层到输出层的权重矩阵:256(隐藏单元) × 10(输出单元) = 2560个参数
- 隐藏层到输出层的偏置:10个参数
因此,MLP总共有200704 + 256 + 2560 + 10 = 203530个参数。
练习:包含256个隐藏单元的单隐层MLP被应用于Fashion-MNIST数据。如果Xavier的初始化使用均匀分布U(-a,a)初始化输出层中的权重,那么a的值是多少?

![]()
lec3:Optimization Algorithms 优化算法
3.1 Optimization and deep learning最优化和深度学习
在深度学习中,大多数目标函数都是复杂的,并且没有解析解。必须使用数值优化算法。
挑战:局部最小值,鞍点saddle points,消失的梯度。
3.1.1 Optimization challenges in deep learning 深度学习中的优化挑战
- 对于任何目标函数f (x),如果f(x0)在x0附近的任何其他点上都小于f (x),则f(x0)是一个局部最小值。
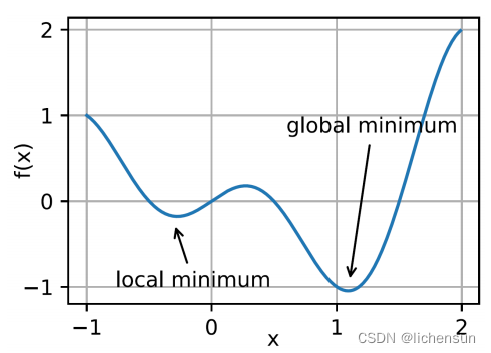
- 如果f(x0)是整个域上的f (x)的最小值,则f(x0)是全局最小值global minimum。
- 深度学习模型的目标函数通常有许多局部最优性。
- 当一个优化问题的数值解接近局部最优时,当目标函数的梯度趋近于零时,最终迭代的数值解可以局部最小化而不是全局最小化。
- 一些噪声可能会使参数超出局部最小值。这是小批量SGD的一个有益特性,在小批量上的梯度变化可以从局部最小值去除参数。
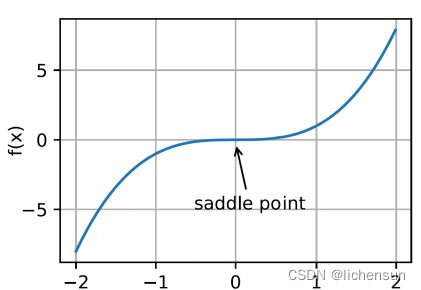
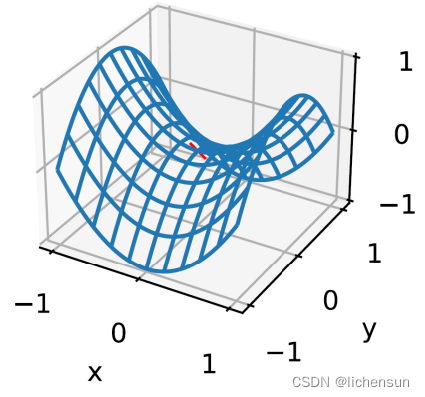
- 鞍点是指函数的所有梯度消失但不是全局或局部最小值的任何位置。
- f (x) = x^3的第1阶和第2阶导数在x = 0处消失。优化可能在这一点上停滞,但它不是一个最小值。
- 鞍点在更高的偏差中甚至更加阴险。f(x,y)= x²−y²在(0.0)处有鞍点。这是一个最大的w.r.t. y和最小值w.r.t. x.
- 假设一个标量函数的输入是k-dim向量,所以它的黑森矩阵有k个特征值。
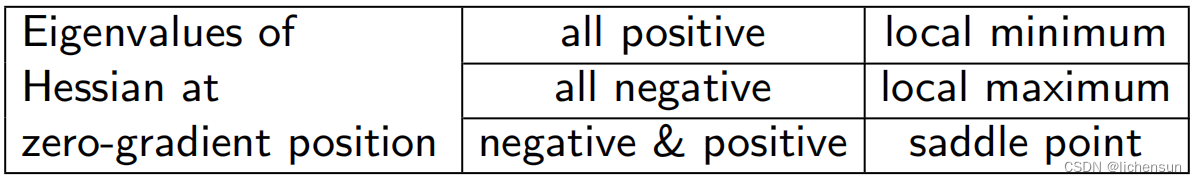
- 对于高暗淡的问题,至少有一些特征值为负的可能性相当高,这使得鞍点比局部极小值更有可能。
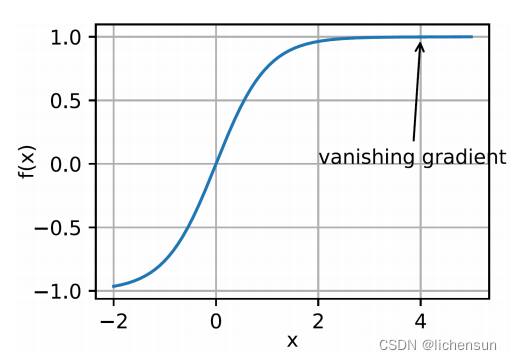
- 最隐蔽的问题是梯度的消失。
- 回想激活函数,f (x) = tanh (x)。f ' (x) = 1−tanh² (x)和f ’ (4) = 0.0013。
- 如果我们从x = 4开始,优化在我们取得进展之前会停滞很长一段时间。
- 因此,在引入ReLU之前,训练深度学习模型是很棘手的。
- 在深度学习中,没有必要找到最好的解决方案。局部最优解或近似解仍然很有用。
- 凸性Convexity 在设计优化算法时是至关重要的,因为它在这种情况下更容易分析和测试算法。深度学习中的优化问题大多是非凸的,但在局部极小值附近表现出凸问题的性质。
3.2.1 Convex sets and functions 凸图集和函数
![]()

深度学习问题通常被定义在像R^d这样的凸集上。
给定凸集X,映射f: X→R是凸的,如果∀λ∈[0,1],∀x,x’∈X,

3.3 Gradient descent 梯度下降
- 设f: R→R为连续可微的。通过泰勒扩展:
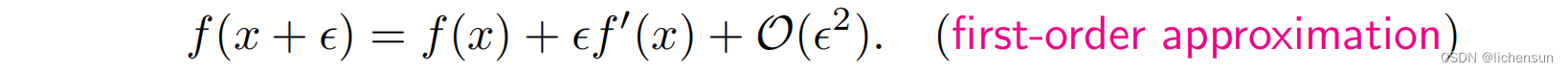
- 选择步长η > 0,然后令e=−ηf'(x)。插入泰勒扩展公式:
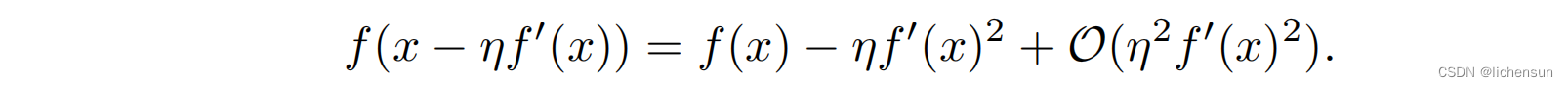
- 如果f ’(x) ≠0,如果我们在负梯度的方向上迈出一小步f (x)可能降低,则:
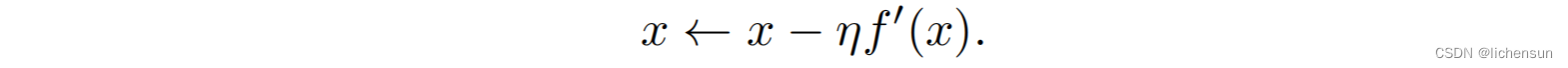 选择足够小的η,使高阶项变得无关紧要。
选择足够小的η,使高阶项变得无关紧要。 - 在梯度下降中,我们选择一个初始值x,一个常数η > 0,并迭代x,直到达到停止条件(梯度的幅度很小或迭代的次数已经达到了一定的值)。
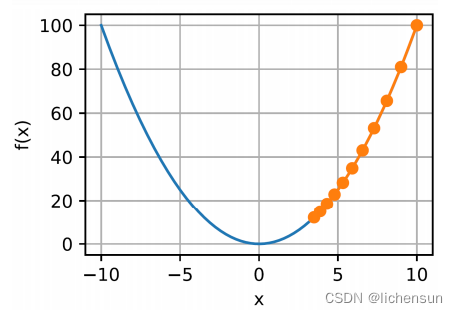
- 使用f (x) = x²来说明梯度下降,它在x = 0处最小化。
- 小的学习率导致x更新非常慢。对于η = 0.05,经过10步后,我们仍然远未得到最优解。
-
#简单的梯度下降算法,用于最小化一个简单的二次函数 def f(x): #表示要最小化的目标函数,这里是一个简单的二次函数 return x ** 2 # Obj fn def f_grad(x): #目标函数的梯度函数f_grad(x),这里是二次函数的导数 return 2 * x # Grad of obj fn def gd(eta, f_grad): # Gradient descent #梯度下降算法函数gd,其中eta是学习率,f_grad是目标函数的梯度函数 x = 10.0 # Initial value results = [x] # append iterates for i in range(10): # 10 epochs x -= eta * f_grad(x) results.append(float(x)) print(f'epoch 10, x: {x:f}') return results gd(0.2, f_grad), f #学习率0.2 epoch 10, x: 0.060466 gd(0.05, f_grad), f #学习率0.05 epoch 10, x: 3.486784
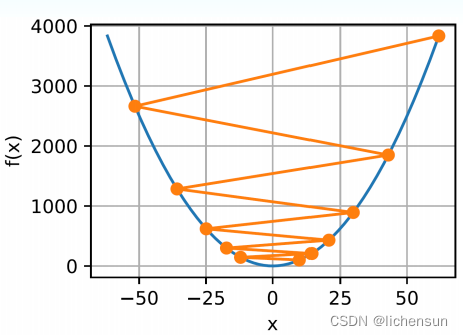
如果学习率过高,|ηf'(x)|对于一阶Taylor展开可能太大,O(η²f'(x)²)成为显著的→不能保证x的迭代会降低f (x)。
3.3.1 Learning rate 学习率
当η = 1.1时,x超冲最优解x = 0并逐渐发散。
对于某个常数c,非凸函数f (x) = x·cos(cx)有无穷多个局部极小值。
根据所选择的学习速率,我们最终可能会得到许多解决方案中的一个。
较高的学习率会导致较低的局部最低学习率。
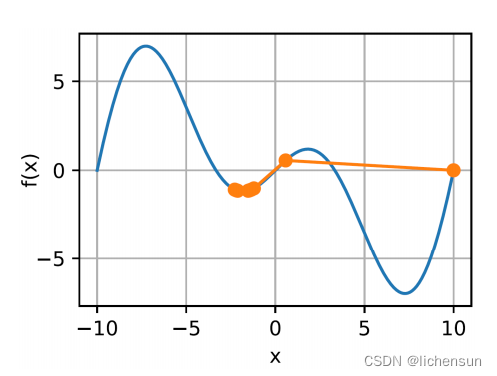
3.3.2 Multivariate gradient descent 多元梯度下降
考虑x = [x1,……,xd]^T和f: R d→R.梯度: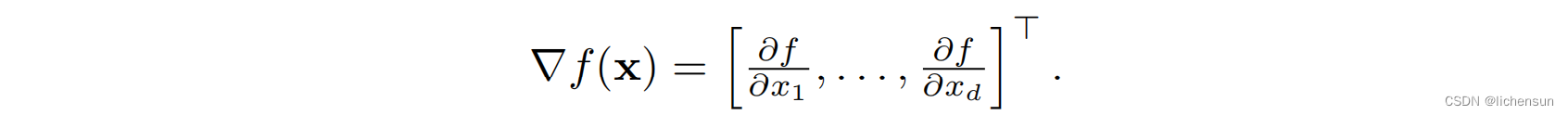

最陡下降方向为负梯度,−∇f(x)。选择合适的学习率η > 0: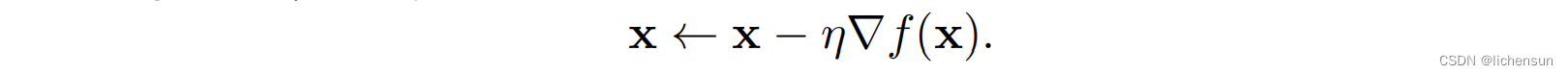
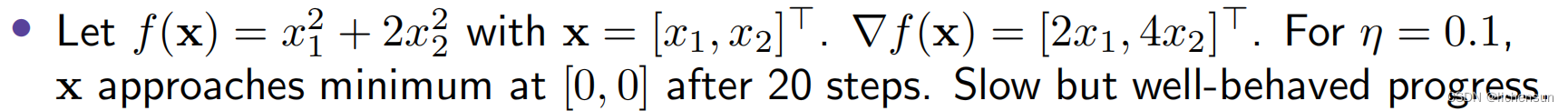
#在二维空间中使用梯度下降算法优化的示例
from d2l import torch as d2l
def f_2d(x1, x2):
return x1**2 + 2 * x2**2
def f_2d_grad(x1, x2):
return (2*x1, 4*x2)
def gd_2d(x1, x2, s1, s2, f_grad):#当前位置(x1, x2)和步长(s1, s2)
g1, g2 = f_grad(x1, x2)
return (x1 - eta*g1, x2 - eta*g2, 0, 0)
eta = 0.1#学习率
d2l.show_trace_2d(f_2d, d2l.train_2d(gd_2d, f_grad=f_2d_grad))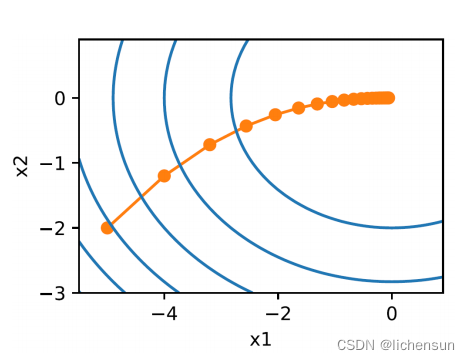
3.3.3 Adaptive methods 自适应方法
获得正确的学习速度“是一个棘手的问题。进展太小,进展太大,解决方案就会出现分歧。我们能自动确定η吗?
二阶方法不仅关注目标函数的值和梯度,还关注它的曲率。由于计算成本的原因,它们不能直接应用于深度学习,但为设计优化算法提供了直觉。
- 二阶泰勒展开:

- 正在区分“w.r.t.”和忽略高阶项,

- 凸函数:f(x)=coxh(cx)用于某个常数c。经过几次迭代后,可以达到x = 0处的全局最小值。
- 非凸函数: f (x) = x cos(cx)对于某个常数c. η = 1不导致收敛,但η = 0.5导致一个局部最小值。
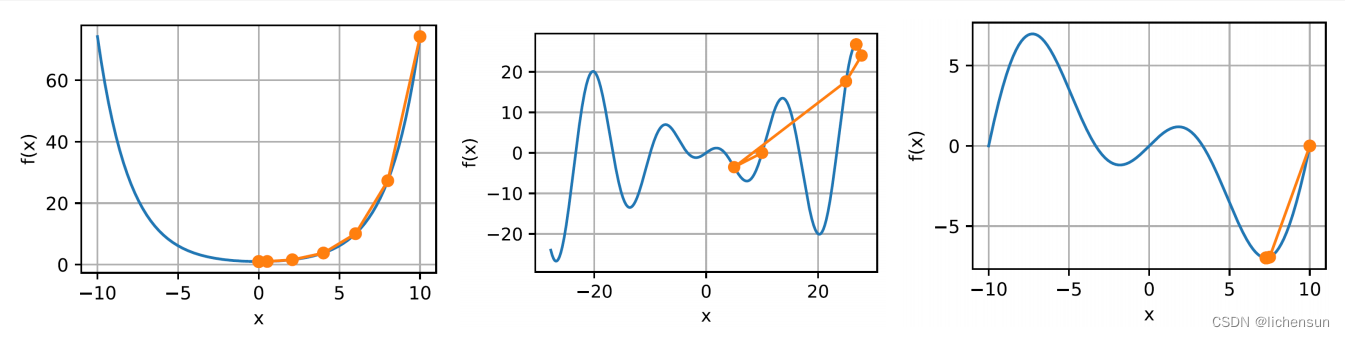
- 对于f (x) = x²/2、∇f (x) = x和H = 1。因此,=−x和一步就足以收敛。泰勒展开式在这里是精确的。
- 计算和存储整个黑森是非常昂贵的。预处理只计算导致更新的对角线项:
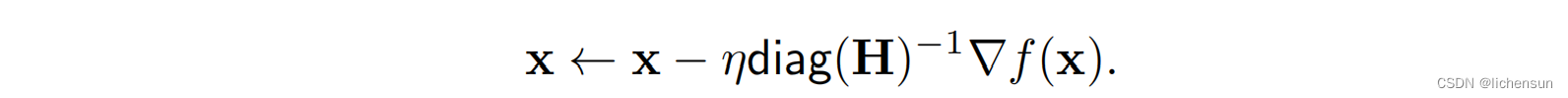
- 预处理为x的每个变量选择不同的学习速率。
- 梯度下降的关键问题是:目标超调或进展不足。一个简单的解决方法是使用行搜索。使用由∇f(x)给出的方向,并执行二进制搜索,以确定哪个学习率η最小化f(x−η∇f(x))。
- 该算法收敛速度快,但对于深度学习不可行,因为每个行搜索步骤都需要在整个数据集上评估目标函数(代价昂贵)
3.4 Stochastic gradient descent 随机梯度下降
在深度学习中,目标函数是训练集中每个例子的损失函数的平均值。设fi (w)为损失函数w.r.t,其中一个训练集有n个例子,其中w.r.t为参数向量。然后将目标函数及其梯度为
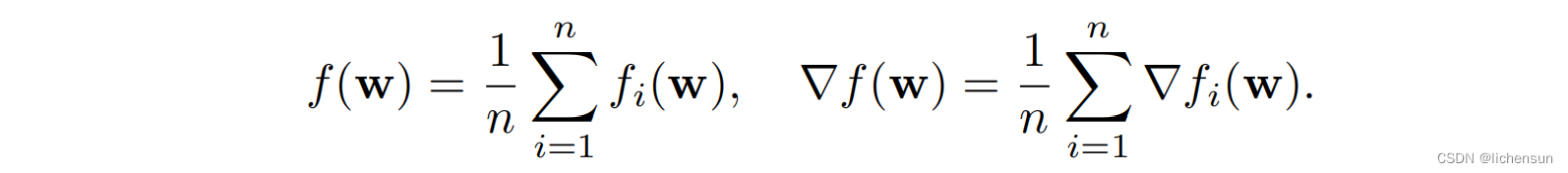
如果使用梯度下降法,计算代价随n呈线性增长。
随机梯度下降(SGD)降低了计算成本。在每次迭代中,采样一个索引i∈{1,…,n}均匀随机并更新: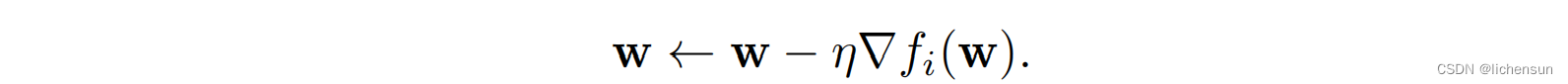 其中,η是学习速率。∇fi(w)是全梯度∇f(w)的无偏估计为
其中,η是学习速率。∇fi(w)是全梯度∇f(w)的无偏估计为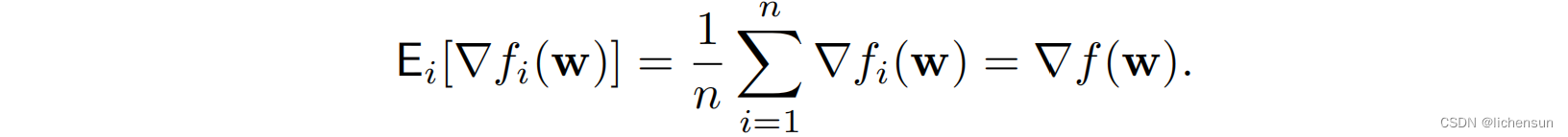 通过在梯度中加入均值为0和方差为1的随机噪声,比较SGD和梯度下降来模拟SGD。
通过在梯度中加入均值为0和方差为1的随机噪声,比较SGD和梯度下降来模拟SGD。
def f(x1, x2):
return x1**2 + 2*x2**2
def f_grad(x1, x2):
return 2*x1, 4*x2
def sgd(x1, x2, s1, s2, f_grad): # Simulate noisy gradient 噪声
g1, g2 = f_grad(x1, x2)
g1 += torch.normal(0,1,(1,)).item()
g2 += torch.normal(0,1,(1,)).item()
eta_t = eta*lr()
return (x1 - eta_t*g1, x2 - eta_t*g2, 0, 0)
def constant_lr():
return 1
lr = constant_lr
eta = 0.1
d2l.show_trace_2d(f, d2l.train_2d(sgd, steps=50, f_grad=f_grad))
# epoch 50, x1: -0.005771, x2: -0.055682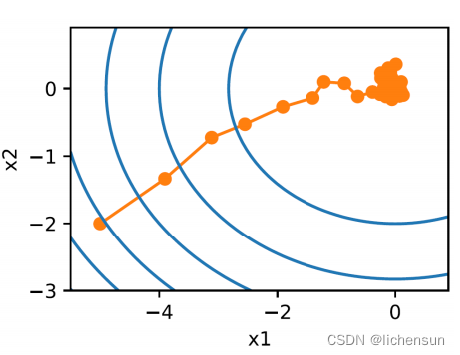
由于梯度的随机性,SGD中变量的轨迹比梯度下降更大。即使接近最小值,我们仍然受到瞬时梯度∇fi(x)注入的不确定性。
3.4.1 Dynamic learning rate 动态学习率
- 如果η太小,我们最初就不会取得有意义的进展。如果η太大,解决方案就不好了。为了解决这些问题,随着优化的进展,动态地降低学习速率。
- 需要弄清楚η衰减的速度会有多快。如果速度太快,我们就会过早地停止优化。如果速度太慢,我们就会在优化上浪费时间。
- 长期调整η的策略:
当进度停滞时,降低学习率(训练深度网络的常见策略)。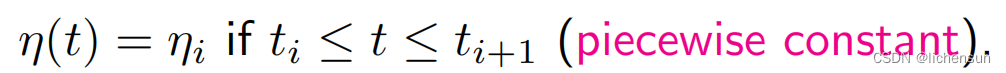
通常会导致在算法尚未收敛之前过早停止。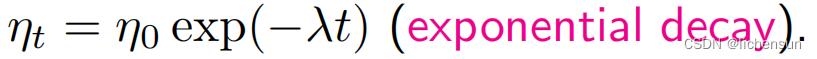
流行的选择是α = 0.5。
指数衰减:参数的方差显著减少,但即使经过1000次迭代,也不能收敛到最优解(0,0)

多项式衰减:仅50步收敛得更好

3.5 Minibatch stochastic gradient descent 小批量随机梯度下降
有两个极端:(1)我使用完整的数据集来计算梯度和更新参数。(2)一次处理一个培训实例。
- 当数据相似时,梯度下降不是数据效率,而SGD则不是计算效率,因为cpu/gpu不能利用矢量化的能力。
- 处理单个观测需要许多单个矩阵向量/向量向量乘法。在计算梯度以更新参数时,费用昂贵:
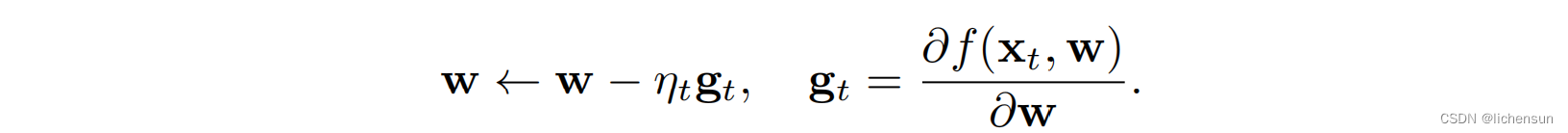
- 通过将gt替换为一个小批观测来提高计算效率:
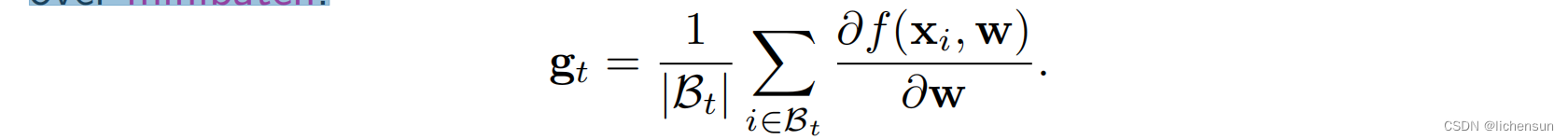
- 由于Bt的所有元素都是从训练集中均匀随机抽取的,因此对梯度的期望保持不变。方差减少了一个因子|Bt|,因此更新更可靠地与全梯度对齐。
- 选择一个足够大的小批量,以提供良好的计算效率,同时适应GPU的内存。
- 使用来自NASA数据集的第1个1500个例子来比较优化算法。对数据进行预处理(将平均值和方差调整为1)。
- 用小批量SGD初始化和训练一个线性回归模型:
批处理梯度下降:每个历元会更新一次参数。经过6个步骤后,进度将停止。
*SGD(批处理大小= 1):在处理一个示例后更新参数(每个历元1500次更新)。目标函数的下降在一个时期之后就会减慢。SGD比梯度下降消耗更多的时间,尽管两者都在一个历元中处理了1500个例子,因为参数更新得更频繁,而且处理单个观测结果的效率较低。
*小批SGD(批大小= 100):每个历元的时间比SGD短。
*小批处理SGD(批处理大小= 10):每个历元的时间增加了,因为每个批处理的工作负载的执行效率较低。 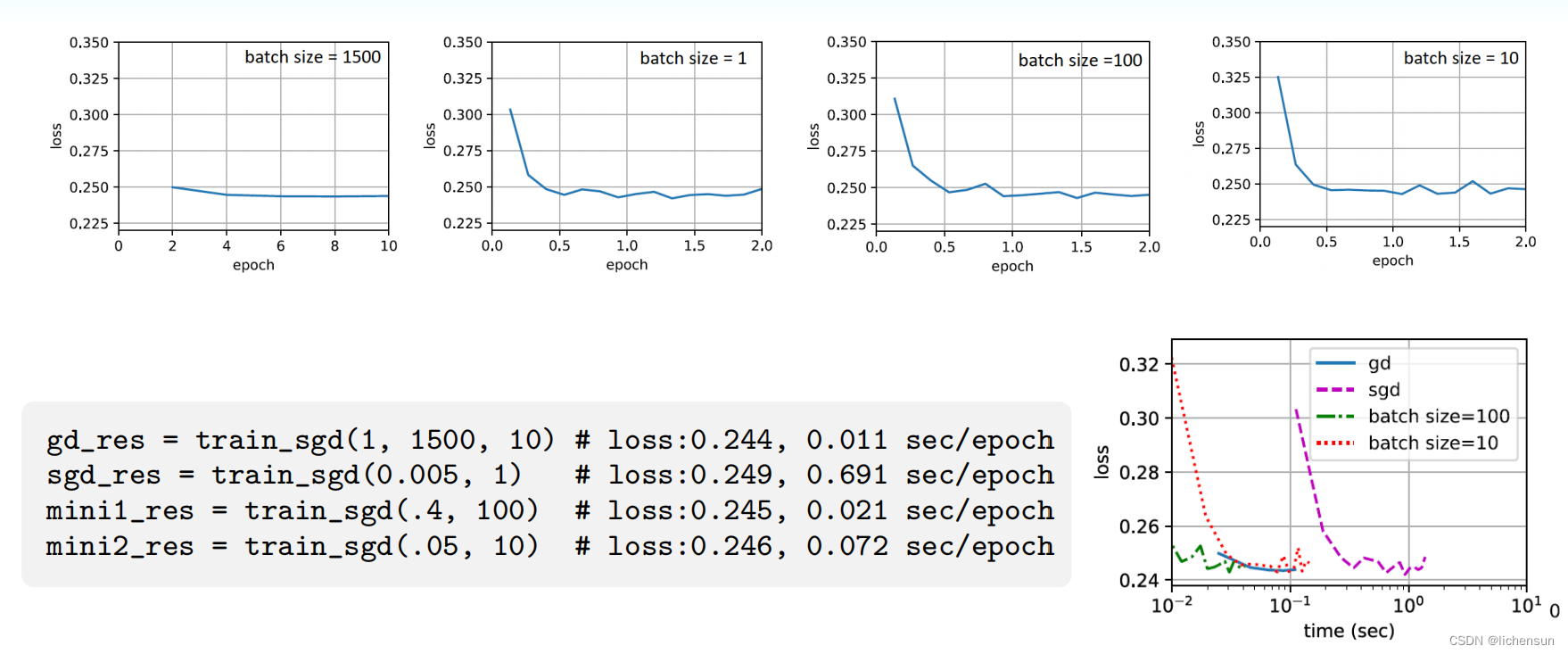
- SGD的收敛速度比梯度下降速度快。处理的例子,但使用更多的时间达到相同的损失,因为计算梯度实例不是那么有效。
- 小批量SGD可以权衡收敛速度和计算效率。
3.6 Momentum
在小批量SGD中,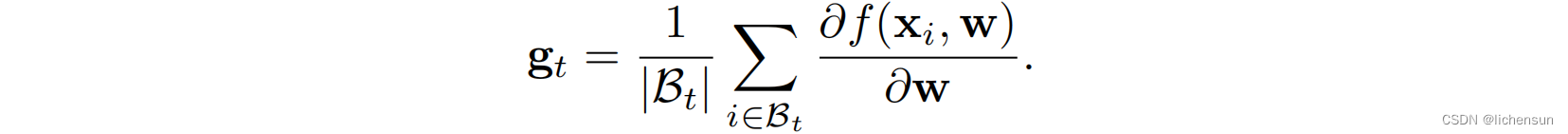
为了从小批上平均梯度之外的方差减少中获益,用过去梯度上的平均梯度代替瞬时梯度:
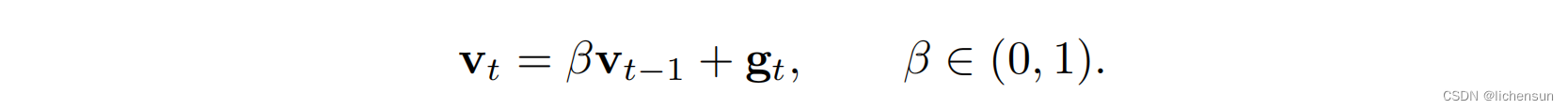
速度vt累积过去的梯度,类似于一个重球滚动目标函数景观整合过去的力。(较大的β相当于长期的平均值。)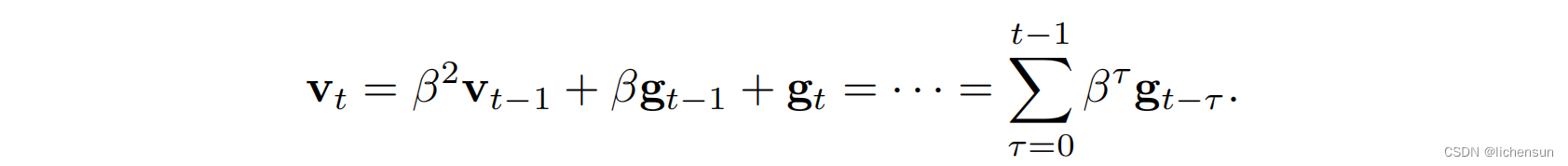
新的梯度不再指向最陡的下降方向,而是指向过去梯度的加权平均方向(更稳定)。产生不计算成本的平均收益的好处。
3.6.1 An ill-conditioned problem

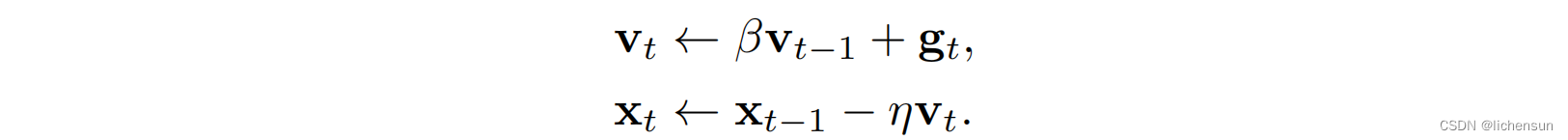

3.7 Adagrad
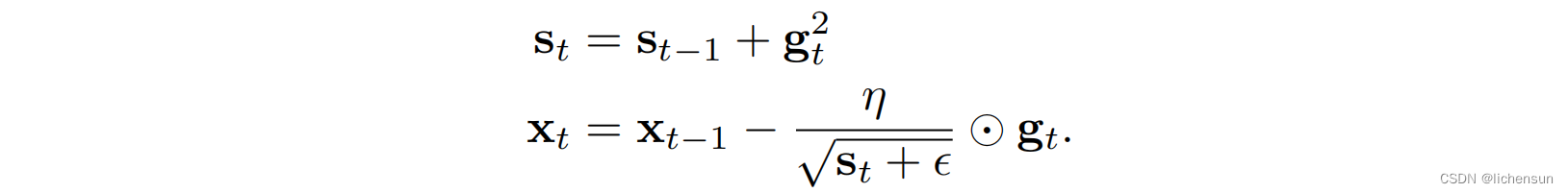
![]()
η = 0.4:迭代轨迹更平滑,但由于st的累积效应,学习率持续衰减,因此后期运动量不大。
η = 2:更好的行为。学习率的下降是积极的,即使是在无噪声的情况下。需要确保参数适当地收敛。

3.8 RMSProp
- Adagrad的关键问题是:在固定的O(t^−0.5)时间表下,学习率下降。这对于深度学习中的非凸问题可能不是理想的。
- Adagrad的坐标自适应Coordinate-wise adaptivity 是可取的,但梯度gt的平方导致st无线性增长。
- RMSProp通过一个泄漏的(指数加权移动的)平均值来解决这个问题:
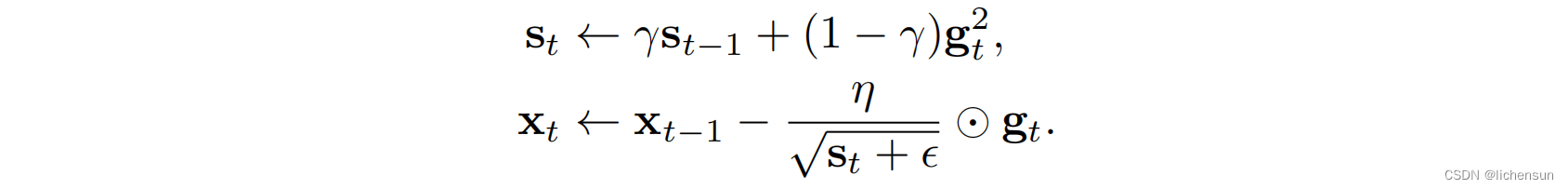
- 常数>0通常设置为10−6,以防止除以零或过大的步长。扩展:
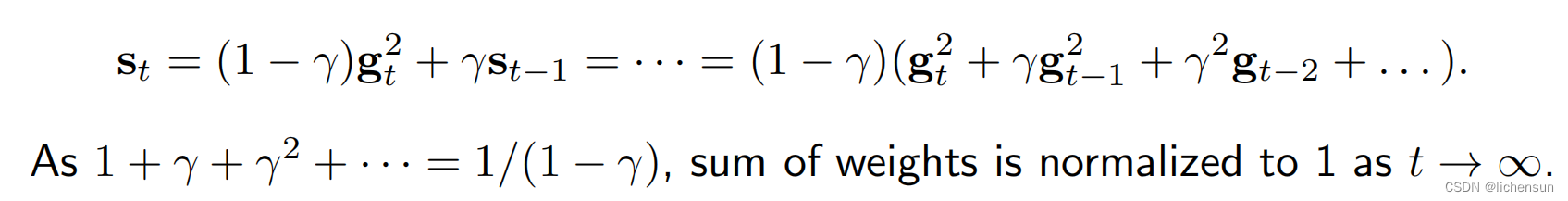
-
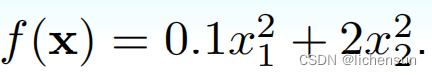

3.9 Adam
- Adam是一种流行的鲁棒和有效的优化算法,但有时Adam会由于方差控制差而产生分歧。
- Adam使用泄漏平均来获得梯度的动量和第二阶矩的估计值:
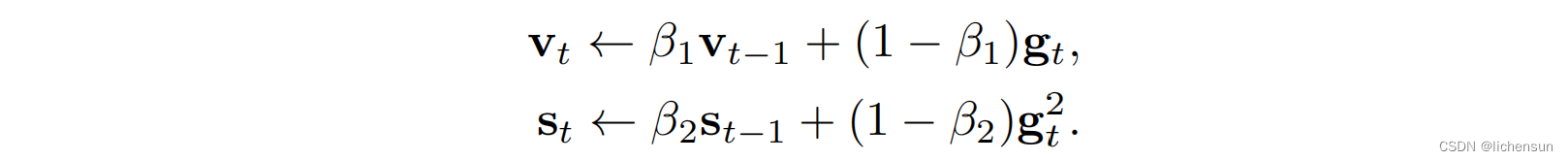 β1和β2的常见选择分别为0.9和0.999。因此,方差估计比动量项移动得要慢得多。
β1和β2的常见选择分别为0.9和0.999。因此,方差估计比动量项移动得要慢得多。 - 如果我们初始化v0 = s0 = 0,最初会有显著的偏向于较小的值。假设E(gt)是静止的,
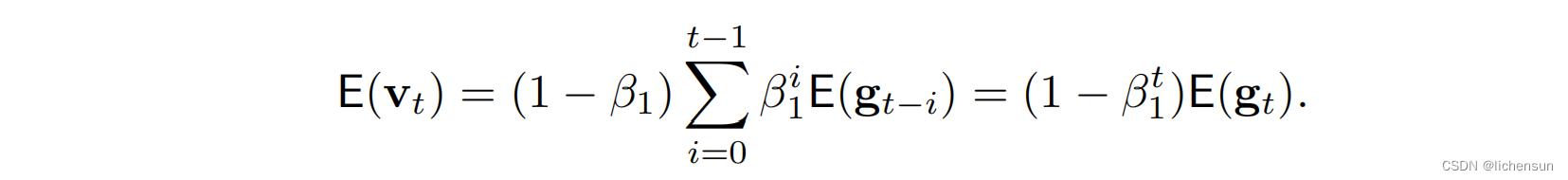
- 类似的论证也适用于st。因此,重整化的状态变量是
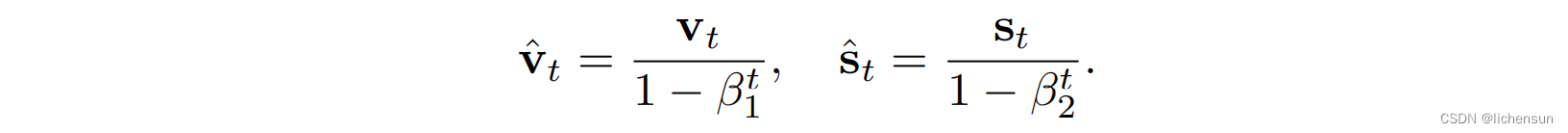
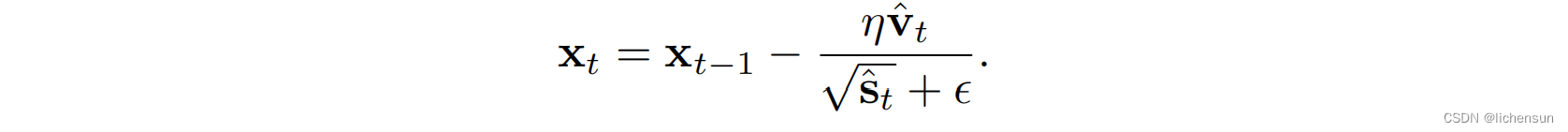 更新使用了动量ˆvt而不是梯度本身,以及一个类似于RMSProp的重新缩放。
更新使用了动量ˆvt而不是梯度本身,以及一个类似于RMSProp的重新缩放。- 选择=10^−6在数值稳定性和保真度之间的权衡.
- 显式学习率η(通常设置为0.001)允许我们控制步长来解决收敛性的问题。
- 调用方法:trainer = torch.optim.Adam
练习:
lec4:Builder’s Guide and Convolutions
4.1 Layers and modules 层和模块
- 软件工具在深度学习中至关重要。计算的关键组成部分:
模型构建,参数访问和初始化,设计自定义层和块,写模型到磁盘,加速gpu。 - MLP有来自所有层的参数组合。深度学习模型可以有数百个层,通常具有重复的模式。一次实现一层这样的网络可能会变得单调乏味。
- 一个神经网络模块可以描述一个层、一个具有多层的组件module或整个模型。模块可以递归地组合成更大的工件。
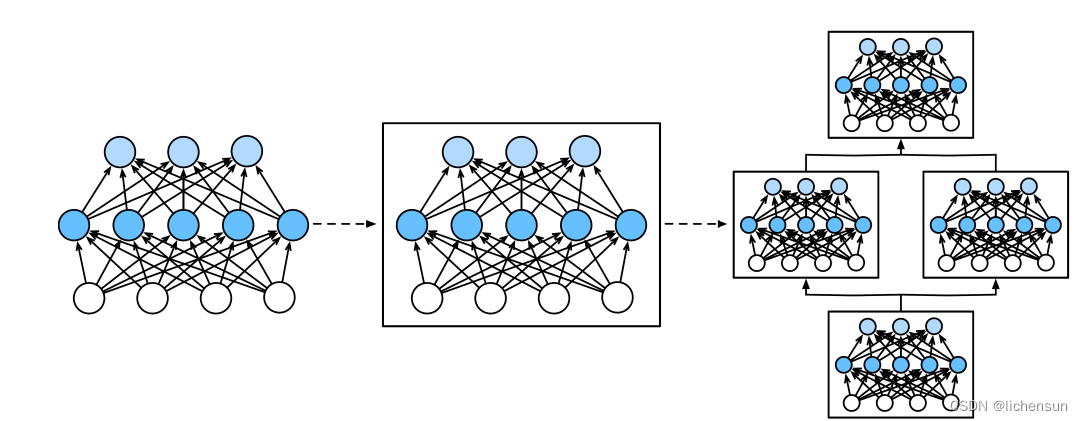 图:将多层组合成模块,形成较大模型的重复模式。
图:将多层组合成模块,形成较大模型的重复模式。- 在编程过程中,一个模块由一个类class来表示。
-
nn.Sequential 是PyTorch中的一个类,它将一个有序的模块列表连接在一起。
-
下面的代码生成一个具有完全连接的隐藏层(256个单元)和ReLU激活的网络,然后是一个完全连接的输出层(10个单元)。
import torch from torch import nn from torch.nn import functional as F from d2l import torch as d2l net = nn.Sequential(nn.LazyLinear(256), nn.ReLU(), nn.LazyLinear(10)) X = torch.rand(2, 20) net(X).shape # torch.Size([2, 10]) -
要实现您自己的模块,请注意基本功能:
1。将输入数据作为参数输入到正向传播方法中。
2.使用前向传播的方法生成输出。
3.通过反向传播来计算梯度。
4.存储正向传播所需的参数。
5.初始化模型参数。class MLP(nn.Module): def __init__(self): super().__init__() # call parent class nn.Module’s __init__method self.hidden = nn.LazyLinear(256) self.out = nn.LazyLinear(10) def forward(self, X): # forward propagation, take X as input return self.out(F.relu(self.hidden(X))) net = MLP() net(X).shape # torch.Size([2, 10]) -
顺序 Sequential类使模型构建变得容易,但并非所有的架构都是依赖于预定义的神经网络层的简单链。在需要灵活性时,定义您自己的块。
4.1.1 Executing code in forward propagation 在正向传播中执行代码
#包含固定权重的多层感知机(MLP)模型
class FixedHiddenMLP(nn.Module):
def __init__(self):
super().__init__() # rand_weight is initialized randomly and
self.rand_weight = torch.rand((20, 20)) # thereafter constant (not model parameter)
#rand_weight,表示固定的权重参数,不会通过反向传播更新。
#创建一个LazyLinear层,表示具有20个输出单元的全连接层,这个层的权重会被训练更新。
self.linear = nn.LazyLinear(20) # never updated by backpropagation
def forward(self, X):#前向传播方法
X = self.linear(X)
#将全连接层的输出与固定权重rand_weight相乘,并加上偏置1,然后应用ReLU激活函数。
X = F.relu(X @ self.rand_weight + 1)
X = self.linear(X) # reuse fc layer (shared weights)
while X.abs().sum() > 1: # test if L1 norm > 1 对X进行操作,使其L1范数不超过1。
X /= 2 # divide by 2 until L1 norm is not > 1
return X.sum() # return sum of entries of X
net = FixedHiddenMLP()
type(net.linear.weight) # torch.nn.parameter.Parameter
type(net.linear.bias) # torch.nn.parameter.Parameter
#torch.nn.parameter.Parameter,表示这是一个可训练的参数。
type(net.rand_weight) # torch.Tensor
#torch.Tensor,表示这是一个固定的张量参数,不会通过反向传播更新。我们可以混合和匹配的各种方式组装模块在一起。
#创建一个Sequential模型chimera,包含两个子模型:
#一个是具有20个输出单元的LazyLinear层,另一个是前面定义的FixedHiddenMLP模型。
chimera = nn.Sequential(nn.LazyLinear(20), FixedHiddenMLP())
chimera(X)4.2 Parameter management 参数管理


4.2.1 Tied parameters

4.3.1 Built-in initialization 内置初始化




4.3.2 Custom initialization 自定义初始化
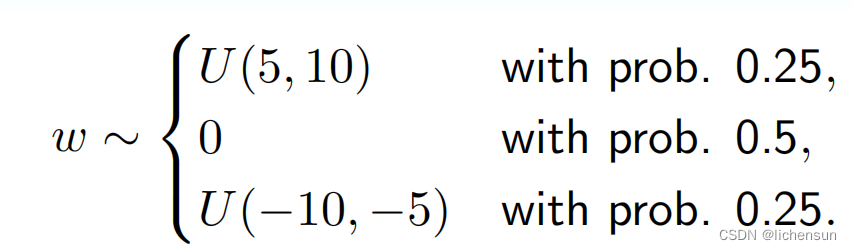

4.3.3 Lazy initialization
不直观的事情:
- 定义的网络架构没有指定输入dim,
- 添加了图层而不指定前一层的输出dim,
- 在确定模型中参数的数目之前初始化了参数。
代码运行是因为框架延迟初始化,等待我们通过模型传递数据,以动态推断每一层的大小。
能够在编写代码时,在不知道dim的情况下设置参数,这大大简化了模型的规范和修改。
首先,网络不知道输入层的权重,因为输入模糊是未知的,所以框架没有初始化任何参数。
数据通过网络并识别所有参数形状后,框架初始化参数。
net = nn.Sequential(nn.LazyLinear(256),
nn.ReLU(),
nn.LazyLinear(10))
net[0].weight
# <UninitializedParameter>
X = torch.rand(2, 20)
net(X)
net[0].weight.shape
# torch.Size([256, 20])4.4 Custom layers and layers with parameters 自定义图层和带有参数的图层
如果在深度学习框架中不存在一个自定义custom层,则必须构建它。
CenteredLayer类(无参数)从其输入中减去平均值。
class CenteredLayer(nn.Module):
def __init__(self):
super().__init__()
def forward(self, X):
return X - X.mean()
layer = CenteredLayer()
layer(torch.tensor([1.0, 2, 3, 4, 5]))
# tensor([-2., -1., 0., 1., 2.])现在定义通过训练可调节参数的层。使用内置函数来创建参数,这些参数可以管理访问、初始化、共享、保存和加载模型参数。
class MyLinear(nn.Module):
def __init__(self, in_units, units):
super().__init__()
self.weight = nn.Parameter(torch.randn(in_units, units))
self.bias = nn.Parameter(torch.randn(units,))
def forward(self, X):
linear = torch.matmul(X, self.weight.data) + self.bias.data
return F.relu(linear)
linear = MyLinear(5, 3) # instantiate MyLinear class
net = nn.Sequential(MyLinear(64,8), MyLinear(8,1)) # construct models using custom layers
net(torch.rand(2, 64))4.5 File I/O 文件输入输出
训练结束后,保存学习到的模型以供以后使用(例如,进行预测)。对于长时间的训练过程,定期保存中间结果是很好的。
加载和存储权重向量和整个模型。
# save a tensor
x = torch.arange(4)
torch.save(x, ‘x-file’) # save requires input variable to be saved and a name
x2 = torch.load(‘x-file’) # load data from stored file
x2 # tensor([0, 1, 2, 3])# save a list of tensors
y = torch.zeros(4)
torch.save([x, y], ‘x-files’)
x2, y2 = torch.load(‘x-files’)
(x2, y2) # (tensor([0, 1, 2, 3]), tensor([0., 0., 0., 0.]))# save a dictionary that maps from strings to tensors
mydict = {‘x’: x, ‘y’: y}
torch.save(mydict, ‘mydict’)
mydict2 = torch.load(‘mydict’)
mydict2深度学习框架提供了加载和保存整个网络的功能。这保存了模型参数,而不是整个模型。
我们需要单独指定MLP的体系结构,因为模型包含任意的代码。要恢复模型,请以代码和加载参数生成体系结构。

由于这两个实例具有相同的模型参数,因此,相同输入的计算结果应该是相同的。
4.6 GPUs
d2l.num_gpus() # get no. of available GPUs
# 1
d2l.try_gpu() # return gpu(i) if exists, otherwise return cpu()
# device(type='cuda', index=0) # allow code to run even if no gpu
x = torch.tensor([1, 2, 3])
x.device # query device where tensor is located
# device(type='cpu')要在多个条件下操作,它们必须在同一台设备上。例如,要求和两个张量,两者都必须生活在同一设备上——否则框架就不知道在哪里执行计算或存储结果。
要在GPU上存储一个张量,请在创建它时指定一个存储设备。
X = torch.ones(2, 3, device = d2l.try_gpu())
X # tensor([[1., 1., 1.], [1., 1., 1.]],
# device='cuda:0')
Y = torch.rand(2, 3, device=d2l.try_gpu())
Y
# tensor([[0.2162, 0.0825, 0.3135],
# [0.1838, 0.2508, 0.6614]], device='cuda:0')
X + Y
# tensor([[1.2162, 1.0825, 1.3135],
# [1.1838, 1.2508, 1.6614]], device='cuda:0')人们使用gpu来加速机器学习,但在设备之间(gpu、CPU)之间传输数据比计算要慢得多。
并行化也更加困难,因为我们必须等待数据的发送或接收,然后才能继续进行更多的操作。
net = nn.Sequential(nn.LazyLinear(1))
net = net.to(device = d2l.try_gpu()) # put model parameters on GPU
net(X) # tensor([[0.3431], [0.3431]], device=‘cuda:0’, grad_fn=<AddmmBackward0>)
net[0].weight.data.device # device(type=‘cuda’, index=0)4.7 From fully connected layers to convolutions 从全连接的层到卷积
通过将图像平坦,将向量输入完全连接的MLP,忽略像素之间的空间关系。卷积神经网络(CNNs)利用附近的像素是相关的知识,并且在计算机视觉中无处不在。
除了精度外,cnn的计算效率也很高。它们比完全连接的架构使用更少的参数,并且易于在GPU核心上并行化。
MLP适用于表格数据(∼行示例,∼列的特性),在那里我们不假设任何关于特征如何交互的结构,但是无结构的网络对于高暗淡的数据会变得笨拙。
例如,根据100万像素照片的注释数据集来区分猫和狗。每个输入有10^6个dims,一个带有10^6个隐藏单元的完全连接层有O(10^12)参数。还可能需要一个大的数据集。该网络的学习参数可能是不可行的。
由于用来检测对象的方法不应该考虑其在图像中的位置,CNN使用空间不变性来学习具有较少参数的表示。
适合于计算机视觉的神经网络架构:
1.平移不变性——网络的最早层应该对同一补丁做出类似的响应,无论它出现在图像中的哪个位置。
2.局部性原则——网络最早的层应该集中在局部区域,而忽略远处区域的图像内容。局部表示可以被聚合,从而最终在整个图像级别上进行预测。
3.随着我们的进行,更深的层应该捕获更长范围的图像特征。
考虑MLP与双dim图像X为输入,隐藏表示H为相同形状的矩阵。设【X】i、j和【H】i、j表示位置(i、j)处的像素。
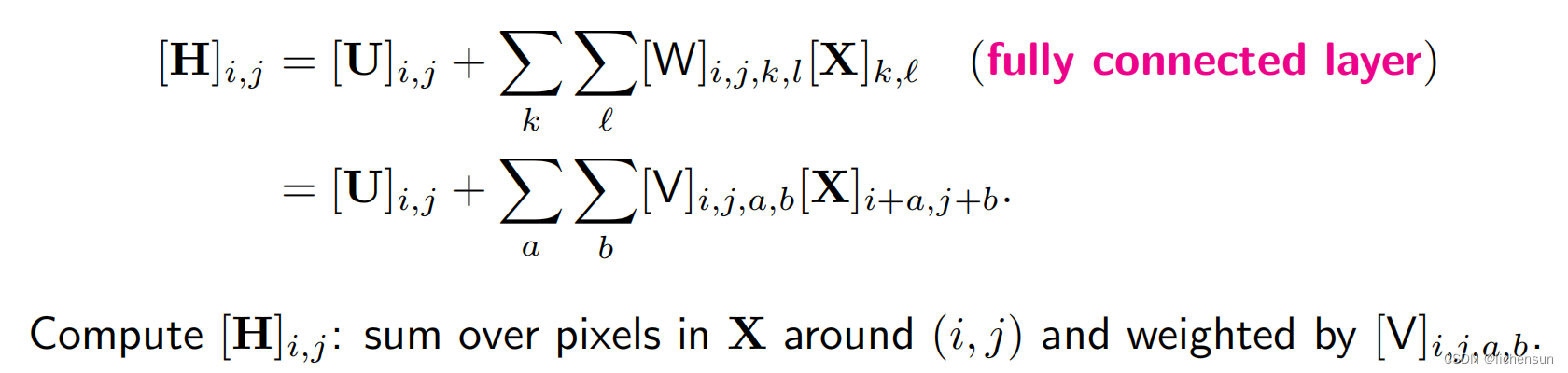
4.7.1 Constraining the MLP 约束MLP
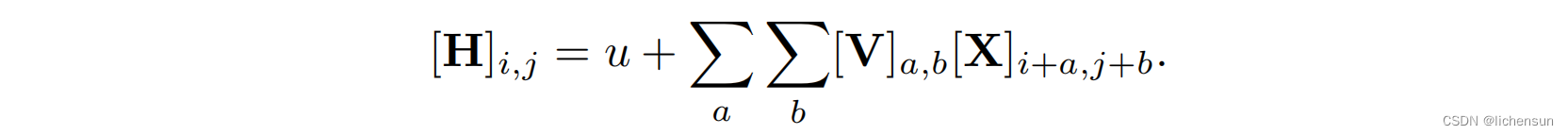
(i, j) (V)附近的(i + a, j + b)加权到H
[V]ab需要的系数比[V]abij需要的系数少,因为它不再依赖于位置(i,j)。不参数从O(10^12)减少到O(10^6)。
不需要寻找远离(i,j)来获得关于[H]i,j的相关信息。
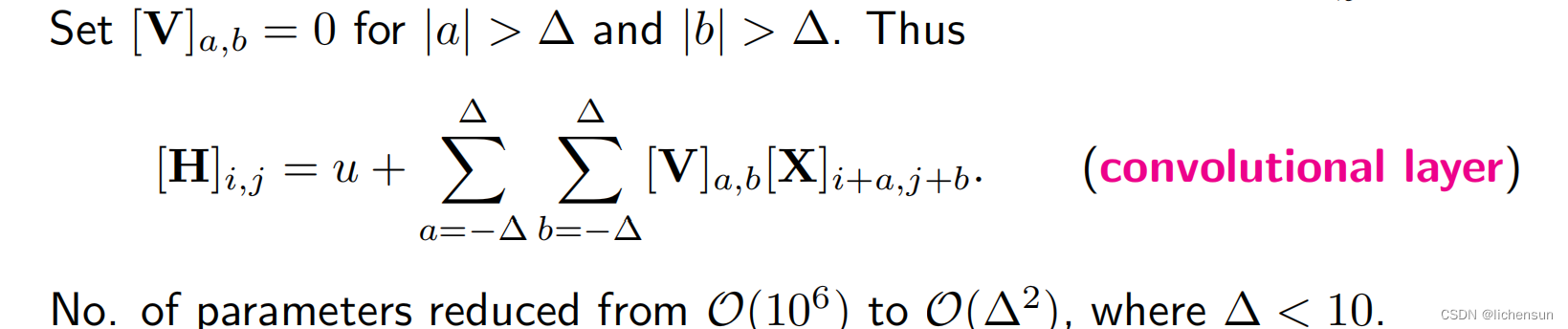
cnn是一种包含卷积层的神经网络。V被称为卷积核或滤波器。
表示一层的参数数量从数十亿减少到几百。降低价格:特征是平移不变的,层在确定隐藏激活时只能包含局部信息。
当这种偏差与现实一致时(例如,当图像是平移不变的时),我们得到了样本有效的模型,可以很好地推广到不可见的数据。
为了让更深的层表示图像更大、更复杂的方面,反复交错非线性和卷积层。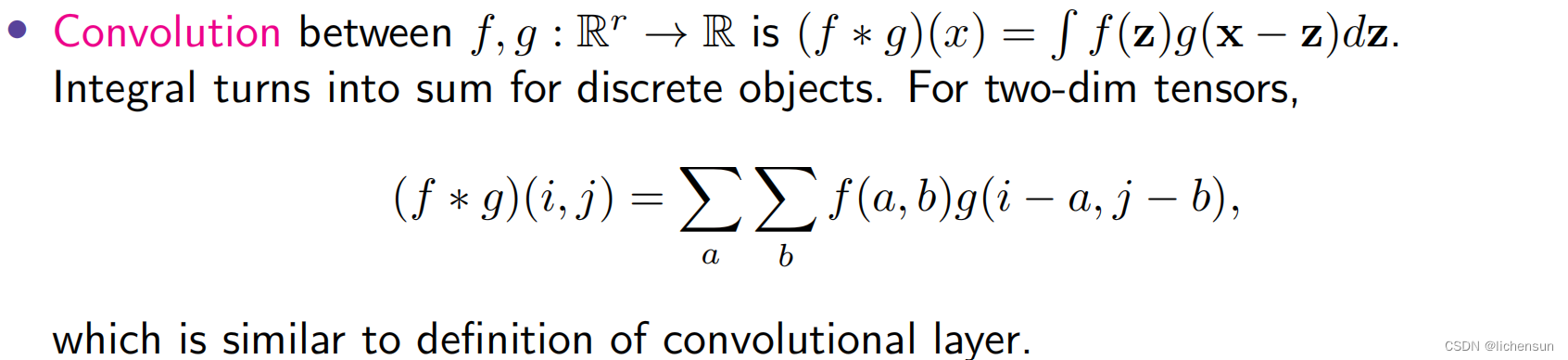
4.7.2 Channels
- 与单色图像不同,彩色图像有3个通道:红色、绿色、蓝色,不是2dim,而是三阶张量(高度、宽度、通道),例如形状为1024×1024×3。前两个轴涉及空间关系,而第三个轴为每个像素位置分配一个多维表示。
- 在每个空间位置上,我们都有一个相似的隐藏表示向量。可以把隐藏的表示看作是相互堆叠的双模糊网格,称为通道channels或特征地图feature maps。
- 为了在输入和隐藏表示中都支持多个通道,卷积层被定义为
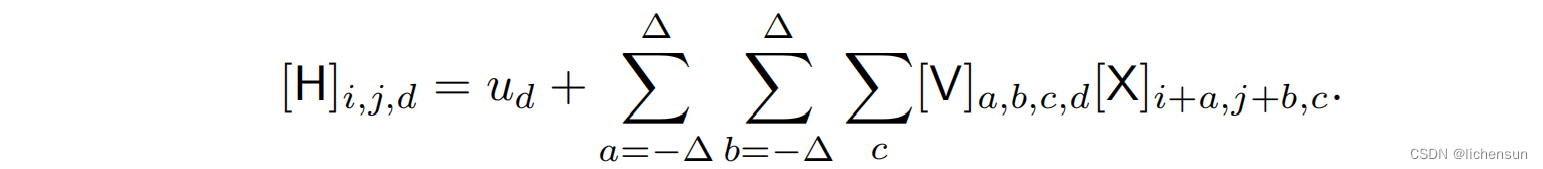 其中d索引H中的输出通道,V是该层的内核或滤波器。
其中d索引H中的输出通道,V是该层的内核或滤波器。 - 在卷积层中,输入和核通过互相关组合起来产生输出。
- 首先,忽略通道,考虑2dim的数据和隐藏表示。
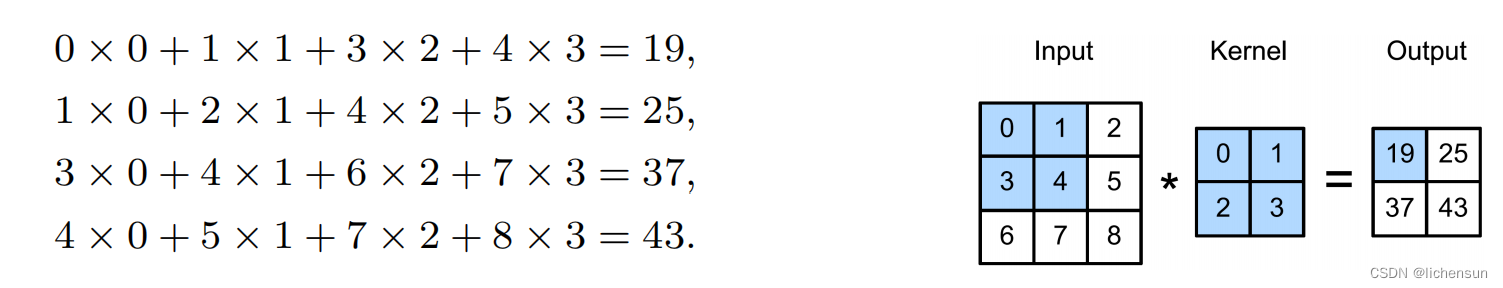
图:输入为3×3张量,核或卷积窗口convolution window为2×2。从位于输入张量左上角的卷积窗口开始,然后从左到右,从上到下滑动。
在每个位置,该窗口的输入与核元素相乘,求和得到相应位置的输出。
沿着每个轴,输出大小略小于输入大小,因为我们只能计算内核完全适合于图像内的位置的互相关。
如果输入大小为nh×nw,卷积核大小为kh×kw,则输出大小为![]()
X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]]) # input
K = torch.tensor([[0.0, 1.0], [2.0, 3.0]]) # kernel
d2l.corr2d(X, K) # tensor([[19., 25.], [37., 43.]])4.8.2 Object edge detection 目标边缘检测
- 构造一个6×8的图像。中间的4列是黑色(0),其余的是白色(1)。
- 构造一个1×2的内核。
- 与输入的互相关:如果水平相邻的元素相同,则输出为0,否则为非零。
- 我们检测到白色到黑色1,−1到黑色到白色。所有其他输出均为0。将内核应用到转置的图像:所有输出都为零。内核只检测垂直边。
-
X = torch.ones((6, 8)) X[:, 2:6] = 0 X # tensor([[1., 1., 0., 0., 0., 0., 1., 1.], # [1., 1., 0., 0., 0., 0., 1., 1.], # [1., 1., 0., 0., 0., 0., 1., 1.], # [1., 1., 0., 0., 0., 0., 1., 1.], # [1., 1., 0., 0., 0., 0., 1., 1.], # [1., 1., 0., 0., 0., 0., 1., 1.]]) K = torch.tensor([[1.0, -1.0]]) Y = d2l.corr2d(X, K) Y # tensor([[ 0., 1., 0., 0., 0., -1., 0.], # [ 0., 1., 0., 0., 0., -1., 0.], # [ 0., 1., 0., 0., 0., -1., 0.], # [ 0., 1., 0., 0., 0., -1., 0.], # [ 0., 1., 0., 0., 0., -1., 0.], # [ 0., 1., 0., 0., 0., -1., 0.]]) d2l.corr2d(X.t(), K) # tensor([[0., 0., 0., 0., 0.], # [0., 0., 0., 0., 0.], # [0., 0., 0., 0., 0.], # [0., 0., 0., 0., 0.], # [0., 0., 0., 0., 0.], # [0., 0., 0., 0., 0.], # [0., 0., 0., 0., 0.], # [0., 0., 0., 0., 0.]])4.8.3 Learning a kernel 学习内核
- 不可能手动指定每个过滤器对于更大的内核和连续的卷积层应该做什么。
- 从输入输出对中学习内核:构造具有1个输出通道和1 x 2个内核的卷积层。为了简单起见,忽略bias。
-
conv2d = nn.LazyConv2d(1, kernel_size=(1, 2), bias = False) X = X.reshape((1, 1, 6, 8)) # change input & output format: Y = Y.reshape((1, 1, 6, 7)) # (batchsize, channel, height, width) lr = 3e-2 # batchsize = no. of channels = 1 for i in range(10): l = (conv2d(X) - Y) ** 2 # sq error of Y & output conv2d.zero_grad() # reset grad to zero l.sum().backward() # calculate gradient conv2d.weight.data[:] -= lr * conv2d.weight.grad # update kernel if (i + 1) % 2 == 0: # print at even iterations print(f‘epoch {i + 1}, loss {l.sum():.3f}’) conv2d.weight.data.reshape((1, 2)) # epoch 2, loss 4.213 # error dropped to almost 0 # epoch 4, loss 0.783 # after 10 iterations # epoch 6, loss 0.163 # epoch 8, loss 0.040 # epoch 10, loss 0.012 # tensor([[ 0.9800, -0.9995]]) # close to previous kernel4.8.4 Feature map and receptive field 特征图和接受域
卷积层输出被称为特征映射,因为它被认为是在后续层的空间维度中的学习表示(特征)。
任何元素x的接受域都是指在正向传播过程中影响x计算的所有元素(来自之前的所有层)。
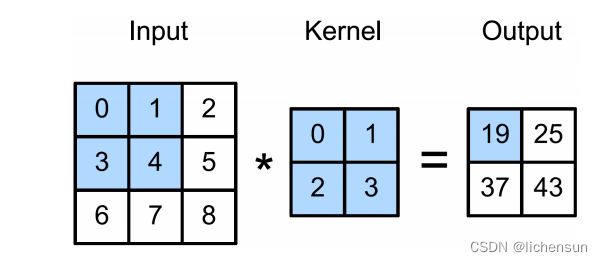
例如,给定2×2内核,阴影输出元素(19)的接受域是输入的阴影部分的4个元素。
设Y为2×2的输出。考虑一个更深层次的CNN,它有一个额外的2×2卷积层,以Y作为输入,输出单个元素z。Y上z的感受域包含Y的所有4个元素,而输入上z的感受域包含所有9个输入元素。
当一个特征图中的任何元素都需要一个更大的接受域来检测一个更广泛的区域内的输入特征时,我们就可以建立一个更深层次的网络。
总的来说,较低的层次会响应纹理、边缘和相关的形状。
练习:一个1024×1024图像的卷积层,它有3个输入通道,10个输出通道,卷积核的窗口是5x5,这层中有多少参数?
因此,该卷积层的参数数量可以计算为:
参数数量=(输入通道数×卷积核宽度×卷积核高度+1)×输出通道数参数数量=(输入通道数×卷积核宽度×卷积核高度+1)×输出通道数
其中,加1是因为每个输出通道还有一个偏置项。将给定的值代入公式,可以得到:
参数数量=(3×5×5+1)×10=(75+1)×10=76×10=760参数数量=(3×5×5+1)×10=(75+1)×10=76×10=760
因此,这个卷积层有760个参数。
lec5:Convolutional neural networks
卷积神经网络
5.1 Padding and stride
在CNN中,经过多次连续卷积后,输出会比输入小得多。例如,10层5×5卷积将240×240图像减少到200×200像素,切割出30%的图像。
为了更多地控制输出大小,使用填充padding和分层卷积strided convolutions。
应用卷积层时图像周长perimeter 像素的损失:图描述了像素利用作为卷积核大小和图像中位置的函数。角落的像素很少使用。

在输入图像的边界周围添加额外的填充filler像素。将额外的像素设置为零。
垫Pad 3 x 3的输入,将其大小增加到5 x 5。输出大小增加到4 x 4。

5.1.1 Padding填充
如果我们添加ph行的填充(∼一半在上,一半在下)和pw列的填充(∼一半在左,一半在右),输出形状为:
输出的高度和宽度分别增加了ph和pw。
输入和输出相同大小:设置ph = kh−1,pw = kw−1。
①在构建网络时,更容易预测每层的输出形状。
②如果kh为奇数,则在位于高度的两侧填充ph/2行。
③如果kh为偶数,顶部填充ph/2行,底部填充ph/2c行。
④以相同的方式填充宽度的两侧。
CNN通常使用高度和宽度都为奇数(1、3、5或7)的卷积核。
#使用PyTorch中的nn.LazyConv2d模块来进行二维卷积操作
import torch
from torch import nn
from d2l import torch as d2l
#创建了一个随机初始化的8x8的张量X
X = torch.rand(size=(8, 8))
#形状变换为(1, 1, 8, 8),表示(batch_size, channels, height, width)的形状。
X = X.reshape((1, 1) + X.shape) # torch.Size([1, 1, 8, 8])
#创建了一个nn.LazyConv2d对象conv2d,指定输入通道数为1,卷积核大小为3x3,填充(padding)为1
#即在图像周围补充1个像素。对输入X进行卷积操作conv2d(X),输出的形状为(1, 1, 8, 8),与输入形状相同
conv2d = nn.LazyConv2d(1, kernel_size=3, padding=1) # 3 x 3 kernel, padding: 1 (all sides)
conv2d(X).shape # torch.Size([1, 1, 8, 8])
#创建了一个nn.LazyConv2d对象conv2d,指定输入通道数为1,卷积核大小为(5, 3),填充(padding)为(2, 1)
#即在高度上补充2个像素,在宽度上补充1个像素。输出的形状仍然为(1, 1, 8, 8),与输入形状相同。
conv2d = nn.LazyConv2d(1, kernel_size=(5,3), padding=(2,1)) # (5-1)/2 =2, (3-1)/2=1
conv2d(X).shape # torch.Size([1, 1, 8, 8])case1:8×8→(四周+1pixel)→10×10
case2:8×8→(上下各加2pixel,左右各加1pixel)→12×10
5.1.2 Stride步幅
当计算互相关cross-correlation时,从输入张量左上角的卷积窗口开始,然后向下和向右滑动所有位置,每次一个元素。
为了提高计算效率或降采样,一次移动窗口为多个元素,跳过中间位置。如果卷积内核很大,因为它捕获了一个大面积的底层图像。
No. of rows and columns traversed per slide: stride步幅。
到目前为止,我们用步幅为1来表示高度和宽度。

垂直3步,水平2步。
当生成第一列的第2个元素时,卷积窗口会向下滑动3行。
当生成第一行的第2个元素时,卷积窗口会向右滑动2列。当卷积窗口继续向右滑动2列时,就没有输出。
当高度步幅为sh,宽度步幅为sw时,输出形状为:
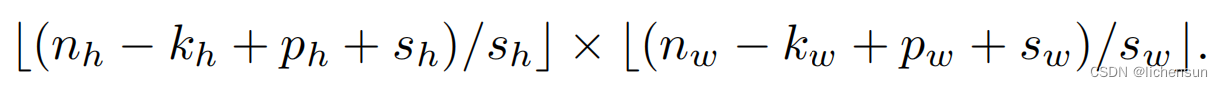
如果 并且
并且
输出是![]()
如果输入的高度和宽度可按高度和宽度上的步幅整除,则输出形状为![]()
>将高度和宽度上的步幅设置为2,从而将输入的高度和宽度减半:
conv2d = nn.LazyConv2d(1, kernel_size=3, padding=1, stride=2) # (8-3+1+2)/2 = 4
conv2d(X).shape
# output:
# torch.Size([1, 1, 4, 4])>更复杂的例子:
conv2d = nn.LazyConv2d(1, kernel_size=(3,5), padding=(0,1), stride=(3,4))
conv2d(X).shape # floor((8-3+0+3)/3)=2, floor((8-5+1+4))/4)=2
# output:
# torch.Size([1, 1, 2, 2])5.2channels
5.2.1 Multiple input channels 多输入通道
如果卷积核的窗口是kh×kw,我们需要一个包含每个输入通道的kh×kw张量的核(当输入通道的数目 ci > 1)。连接ci张量得到一个ci×kh×kw卷积核。
由于输入核和卷积核都有ci通道,对每个通道的2维输入张量和2维卷积核张量进行互相关,并将ci个结果(通道之和sum over channels)相加得到2维张量。

#定义了一个函数corr2d_multi_in,用于计算多输入通道的二维互相关运算。
#函数接受两个输入:X表示输入张量,K表示卷积核张量,两者都是三维张量。
#函数的实现通过使用zip(X, K)将输入张量和卷积核张量按通道组合起来,
#然后对每对通道进行二维互相关运算,并将结果求和。
#最终返回的是一个二维张量,表示所有通道的互相关运算结果的和。
def corr2d_multi_in(X, K):
return sum(d2l.corr2d(x, k) for x, k in zip(X, K))
#输入X是一个形状为(2, 3, 3)的张量,表示有两个通道,每个通道的大小为3x3。
X = torch.tensor([[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]],
[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0]]])
#卷积核张量K是一个形状为(2, 2, 2)的张量,表示有两个通道,每个通道的卷积核大小为2x2。
K = torch.tensor([[[0.0, 1.0], [2.0, 3.0]], [[1.0, 2.0], [3.0, 4.0]]])
#调用corr2d_multi_in(X, K)将对X的每个通道与K的对应通道进行二维互相关运算
#并将结果相加,最终返回一个形状为(2, 2)的张量,表示最终的互相关运算结果。
corr2d_multi_in(X, K) # tensor([[ 56., 72.], [104., 120.]])到目前为止,我们只有一个输出通道,但在每一层都有多个通道是必要的。随着我们在网络中的深入,我们增加信道维度,降采样downsampling以权衡空间分辨率换取更大的信道深度。
让ci和co分别我输入通道和输出通道的个数,kh和kw分别为内核的高度和宽度。为了获得多个通道的输出,为每个输出通道创建一个ci×kh×kw核张量,并将它们连接concatenate 到输出通道维度上,得到一个![]() 卷积核。
卷积核。
每个输出通道的互相关结果是由输出通道的卷积核计算,并从输入张量的所有通道获取输入。
通过将K的核张量与K+1和K+2连接起来,构造具有3个输出通道的平凡卷积核。
#定义了一个函数corr2d_multi_in_out,用于计算多输入通道和多输出通道的二维互相关运算。
def corr2d_multi_in_out(X, K): # calculate output of multiple channels
#使用torch.stack将每个卷积核对应的互相关运算结果堆叠起来
#最终得到一个四维张量,表示多输出通道的互相关运算结果。
return torch.stack([corr2d_multi_in(X, k) for k in K], 0)
K = torch.stack((K, K + 1, K + 2), 0)
K.shape # torch.Size([3, 2, 2, 2])
X.shape # torch.Size([2, 3, 3])
#调用corr2d_multi_in_out(X, K)将对X的每个通道与K的对应通道进行二维互相关运算,并将结果堆叠起来
#最终返回一个形状为(3, 2, 2)的张量,表示三个输出通道的互相关运算结果。
corr2d_multi_in_out(X, K) # output contains 3 channels
# tensor([[[ 56., 72.], [104., 120.]], # result of 1st channel is consistent
# [[ 76., 100.], [148., 172.]],
# [[ 96., 128.], [192., 224.]]])5.2.3 1 x 1 convolutional layer 1×1卷积层
1 x 1的卷积最初可能没有意义,因为卷积关联了相邻的像素,但在深度网络中很流行。
由于使用最小窗口,1 x 1卷积不能识别高度和宽度维度上相邻元素之间的交互模式。在信道维度上只进行1 x 1卷积的计算。

图:使用1 x 1卷积核计算3个输入通道和2个输出通道计算互相关。输入和输出具有相同的高度和宽度。输出中的每个元素都是由输入图像中相同位置的元素的线性组合推导出来的。
一个1 x 1的卷积层构成一个在每个像素位置应用的全连接层fully connected layer,将ci输入值转换为co输出值,权重在像素位置之间绑定。它需要共同的权重(加上偏差)。
使用完全连接的图层实现1×1卷积。需要对矩阵乘法前后的数据形状进行调整。
X = torch.normal(0, 1, (3, 3, 3)) # X.shape: torch.Size([3, 3, 3])
K = torch.normal(0, 1, (2, 3, 1, 1)) # K.shape: torch.Size([2, 3, 1, 1])
#函数corr2d_multi_in_out_1x1,用于实现1x1卷积操作。
#1x1卷积是指卷积核大小为1x1的卷积操作,通常用于调整通道数或者进行特征融合。
#函数接受两个输入:X表示输入张量,K表示卷积核张量,两者都是四维张量。
def corr2d_multi_in_out_1x1(X, K):
#函数首先获取输入张量X的通道数c_i,以及卷积核张量K的输出通道数c_o
c_i, h, w = X.shape
c_o = K.shape[0]
#将输入张量Xreshape为(c_i, h * w)的形状,其中h * w表示每个通道展平后的长度
#将卷积核张量Kreshape为(c_o, c_i)的形状,以便进行矩阵乘法操作
X = X.reshape((c_i, h * w)) # X.shape: torch.Size([3, 9])
K = K.reshape((c_o, c_i)) # K.shape: torch.Size([2, 3])
#使用torch.matmul进行矩阵乘法,得到一个形状为(c_o, h * w)的中间结果张量Y
Y = torch.matmul(K, X) # Y.shape: torch.Size([2, 9])
#将Yreshape为(c_o, h, w)的形状,即为最终的输出张量。
return Y.reshape((c_o, h, w)) # Y.shape: torch.Size([2, 3, 3]) 即返回形状为(2, 3, 3)当执行1×1卷积时,上述函数相当于之前实现的互相关函数corr2d_multi_in_out
#使用corr2d_multi_in_out_1x1和corr2d_multi_in_out两个函数分别计算输入X和卷积核K的卷积结果
#并将结果分别存储在Y1和Y2中。
Y1 = corr2d_multi_in_out_1x1(X, K)
Y2 = corr2d_multi_in_out(X, K)
#使用torch.abs计算Y1和Y2之间的绝对差值,并使用sum将所有元素相加得到总的差值
#使用assert语句检查总的差值是否小于1e-6,如果满足条件,则不会抛出异常,表示两种卷积方法得到的结果在误差范围内一致。
assert float(torch.abs(Y1 - Y2).sum()) < 1e-65.3 Pooling 池化
终极任务经常会问一些关于图像的全局问题(它是否包含一只猫?)。因此,最后一层final layer的单位应该对整个输入都很敏感。
通过逐步聚合信息,我们学习了一个全局表示global representation,同时在处理的中间层保留了卷积层的优势。
网络越深,每个隐藏节点所敏感的感受域就越大。降低空间分辨率加速了这一过程,因为卷积核覆盖了一个更大的有效区域。
当检测低级特征(边)时,表示应该对平移不变。在现实中,物体很难出现在同一个地方。相机的振动可能会使一切改变一个像素。池化层Pooling layers降低了卷积层对位置和空间降样本表示的敏感性。
与卷积层一样,池运算符由一个固定形状的窗口组成,根据其步幅滑动到所有输入区域上,为池窗口pooling window遍历的每个位置计算输出。
与卷积层不同,池化层没有参数。池运算符计算池窗口中元素的最大(最大池max-pooling)或平均(平均池average pooling)。
5.3.1 Maximum pooling and average pooling 最大池化和平均池化
平均池化类似于对图像的降采样。由于我们结合了来自多个相邻像素的信息,因此我们对相邻像素进行平均,以获得信噪比更好的图像。
最大池化通常是首选的,因为它从图像中选择更亮的像素。平均池化平滑的图像和尖锐的特征可能不会被识别出来。

>最大池与2 x 2池窗口。
输出张量的高度和宽度均为2。这4个元素来自于每个池化窗口中的最大值。


#使用PyTorch中的nn.MaxPool2d和nn.AvgPool2d模块实现二维最大池化和平均池化操作。
X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]])
X = X.reshape((1,1,3,3)) # input format: (batchsize, no. of channels, height, width)
#创建了一个nn.MaxPool2d对象pool2d,指定池化核大小为2x2,步幅为1。
#调用pool2d(X)进行最大池化操作,得到tensor([[[[4., 5.], [7., 8.]]]]),表示经过最大池化后的输出。
pool2d = nn.MaxPool2d(2, stride=1) # Max-pooling
pool2d(X) # tensor([[[[4., 5.], [7., 8.]]]])
#创建了一个nn.AvgPool2d对象pool2d,指定池化核大小为2x2,步幅为1。
#调用pool2d(X)进行平均池化操作,得到tensor([[[[2., 3.], [5., 6.]]]]),表示经过平均池化后的输出。
pool2d = nn.AvgPool2d(2, stride=1) # Average pooling
pool2d(X) # tensor([[[[2., 3.], [5., 6.]]]])
#最大池化和平均池化是常用的池化操作,用于降低特征图的空间维度,减少计算量,并且具有一定的平移不变性。池化图层会改变输出端的形状。通过填充输入和调整步幅来实现期望的输出形状。
当池聚合来自一个区域的信息时,深度学习框架默认为匹配池窗口的大小和步幅matching pooling window sizes and stride。如果我们使用(3,3)池化窗口,默认情况下我们会得到一个(3,3)个步幅。可以手动指定过渡段和填充,以覆盖默认值。
#手动修改默认值
X = torch.arange(16,dtype=torch.float32).reshape((1,1,4,4))
# tensor([[[[ 0., 1., 2., 3.],
# [ 4., 5., 6., 7.],
# [ 8., 9., 10., 11.],
# [12., 13., 14., 15.]]]])
pool2d = nn.MaxPool2d(3)
pool2d(X) # tensor([[[[10.]]]])
pool2d = nn.MaxPool2d(3, padding=1, stride=2)
pool2d(X)
# tensor([[[[ 5., 7.], [13., 15.]]]])
pool2d = nn.MaxPool2d((2,3), stride=(2,3),padding=(0,1))
pool2d(X)
# tensor([[[[ 5., 7.], [13., 15.]]]])5.3.2 Multiple channels 多通道
在处理多通道输入数据时,池化层将每个输入通道单独池化,而不是像卷积层那样在通道上的输入求和。因此池化层的输出通道的大小与输入通道的大小相同。
我们将张量X和X + 1连接在通道维数上,构造一个有2个通道的输入。池化后输出通道的大小仍然是2。
X = torch.cat((X, X + 1), 1)
X
pool2d = nn.MaxPool2d(3, padding=1, stride=2)
pool2d(X)
练习:输入图像的大小为3x1024x1024,应用于其上的卷积核为5(out_channels)x3×2X2。输出的大小是多少?
5X1023X1023
(3消掉因为channels求和,1023=1024-2+1)
5.4 LeNet
现在我们有了组装全功能CNN的所有成分。之前,我们将MLP应用于Fashion-MNIST数据。
用卷积层代替全连接的层,我们保留了图像中的空间结构,并以更少的参数享受了更简洁的模型。
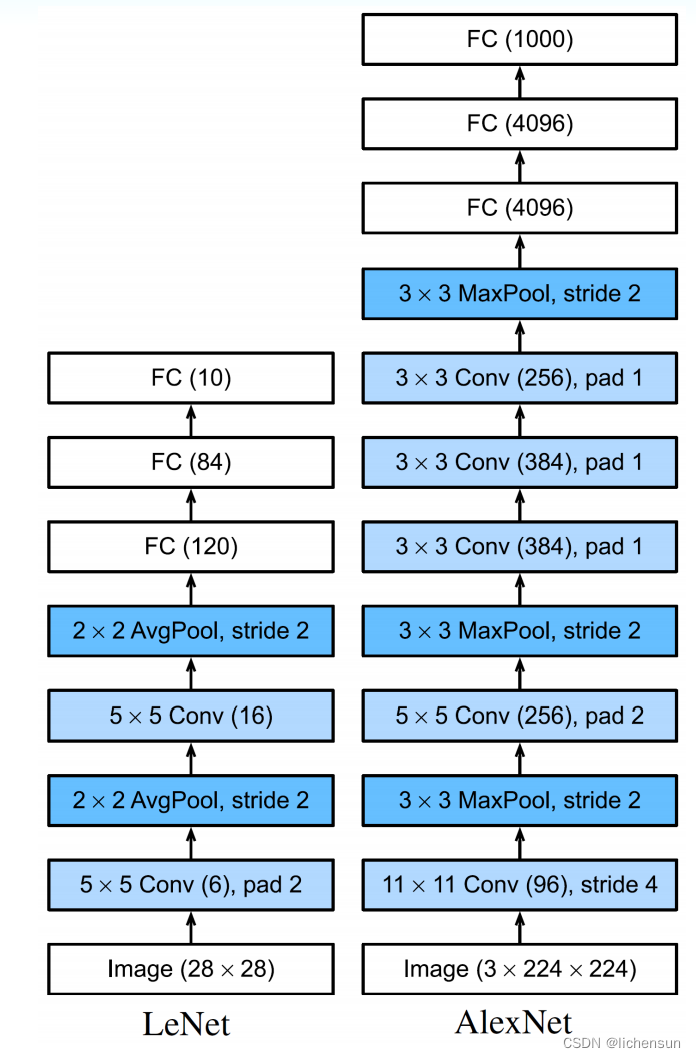
LeNet(1998)是计算机视觉中第一个引起关注的CNN之一。它是由Yann LeCun介绍的,用于识别图像中的手写数字。
LeNet-5有两部分: (i)具有2个卷积层的卷积编码器和(ii)具有3个完全连接层的密集块。

每个卷积层使用一个5 x 5的核和sigmoid激活函数。第一卷积层有6个输出通道,第二层有16个输出通道。每个2 x 2的平均池(2步)减少4倍(ReLUs,尚未发现的最大池)。
卷积块输出形状:(batch size, no. of channel, height, width).
要将输出从卷积块convolutional block传递到密集块dense block,在小批量中将每个例子变平flatten(将4维输入转换为完全连接层期望的2维输入)。2-dim表示使用第一个dim来索引小批中的示例,第2个dim来给出每个示例的向量表示。
密集块有3个完全连接的层(分别为120、84和10个输出)。
LeNet模型可以使用d2l.Lenet()来实现,它使用Xavier初始化和通过顺序块将层链连接在一起。
要可视化LeNet,将一个单通道(黑白)28x28图像的形状通过它,并在每一层打印输出形状。
#打印LeNet模型在输入为(1, 1, 28, 28)时各层的输出形状信息
model = d2l.LeNet()
model.layer_summary((1, 1, 28, 28))output:


第一个卷积层使用2的填充来补偿由5×5内核导致的高度和宽度的减少。第二个卷积层放弃了填充物。因此,高度和宽度都减少了4个像素。
当我们往层的上方走时,在第1卷积层后,通道数从1增加到6,在第2卷积层后增加16,但是每个池化层的高度和宽度都减半了。每一层完全连接的层降低维数,最终输出的维度与用于分类的类相匹配。
>>>在Fashion-MNIST上应用LeNet。与MLPs一样,损失函数是交叉熵cross-entropy的,我们通过小批量SGD将其最小化。
#应用LeNet
#使用了d2l库中的Trainer来训练LeNet模型在FashionMNIST数据集上
#创建了一个Trainer对象trainer,设置最大迭代次数为10,使用1个GPU进行训练
trainer = d2l.Trainer(max_epochs=10, num_gpus=1)
#创建了一个FashionMNIST数据集对象data,设置批量大小为128
data = d2l.FashionMNIST(batch_size=128)
#创建了一个LeNet模型对象model,并设置学习率为0.1
model = d2l.LeNet(lr = 0.1)
#调用data.get_dataloader(True)获取训练数据集的一个批量样本,
#然后将该批量样本作为参数调用model.apply_init方法,
#传入d2l.init_cnn函数,用于初始化LeNet模型的参数
model.apply_init([next(iter(data.get_dataloader(True)))[0]], d2l.init_cnn)
#使用trainer.fit方法训练模型
trainer.fit(model, data)
CNN具有更少的参数,但它们的计算成本可能比类似的深度MLPs更昂贵,因为每个参数都参与了更多的乘法。
访问GPU可以加速训练(d2l.Trainer 类处理所有细节,并在默认情况下初始化可用设备上的模型参数)。
通过对CNN基础的理解,我们研究了现代的CNN架构,它们也可以作为高级任务(分割、目标检测、风格转换)的特征生成器。
5.5 Modern convolutional neural networks 现代卷积神经网络
深度神经网络的概念很简单(将一堆层堆叠在一起),但性能因架构和超参数选择而不同。
AlexNet、VGG网络、网络网络(NiN)、谷歌网络和剩余网络(ResNet)是计算机视觉中流行的体系结构。
cnn在LeNet之后就广为人知了,但并没有立即主导该领域。在大数据集上训练cnn的可行性尚未建立,计算机视觉集中于手工工程特征提取管道。
神经网络训练的技巧(参数初始化,非压缩激活函数,有效的正则化,SGD变体)仍然缺失。
直到2012年,表示都是机械计算的,但一些研究人员认为,特征应该由多层分层组成,每个层都有可学习的参数。
对于图像来说,最低的层可以检测边缘、颜色和纹理,类似于动物的视觉系统处理其输入的方式。
5.6 Representation learning
5.6.1 Representation learning 表示学习
第一个现代CNN以其发明者之一亚历克斯·克里热夫斯基的名字命名为AlexNet ,是对LeNet的进化改进。它在2012年的ImageNet挑战中取得了优异的性能,并首次展示了学习到的特征可以超越手工设计的特征,打破了计算机视觉中的范式。

在最低层中,模型学习到了与传统过滤器相似的特征提取器。
更高的层次建立在这些表示形式之上,以代表更大的结构,比如眼睛、鼻子。
甚至更高的层次也代表了整个物体,如人、飞机、狗。
最终隐藏状态学习图像的紧凑表示,总结其内容,这样可以很容易地分离来自不同类别的数据。
AlexNet和LeNet有许多相同的架构元素,但AlexNet要大得多,接受了更多的数据和更快的gpu训练。
5.6.2 Missing ingredients 缺少成分
Data
具有许多层次的深度模型需要大量的数据才能显著优于传统方法(线性方法和核方法)。
鉴于20世纪90年代计算机的存储空间有限,研究依赖于微小的数据集。
ImageNet数据集于2009年发布,挑战研究人员从10^6个例子中学习模型,每个1000个来自1000个不同类别的物体的1000个。
这种规模是前所未有的,图像的高分辨率为224 x 224像素,具有更多的视觉细节,允许形成更高层次的特征。
相关竞赛(ImageNet大规模视觉识别)推动了计算机视觉和机器学习研究的向前发展。
5.6.4 AlexNet
AlexNet和LeNet的架构是相似的,但有显著的差异。
1.AlexNet比LeNet5更深,有8层:5个卷积层,2个完全连接的隐藏层(4096个单元)和1个完全连接的输出层。
2.AlexNet使用ReLU代替sigMIU作为激活函数。
#定义了一个AlexNet模型,继承自d2l库中的Classifier类。
#AlexNet是一个经典的卷积神经网络模型,常用于图像分类任务。
class AlexNet(d2l.Classifier):
def __init__(self, lr=0.1, num_classes=10):
#在初始化方法__init__中,调用了父类的__init__方法,并使用save_hyperparameters保存了超参数。
super().__init__()
self.save_hyperparameters()
#定义了一个包含多层卷积、激活函数、池化、全连接层和Dropout的网络结构
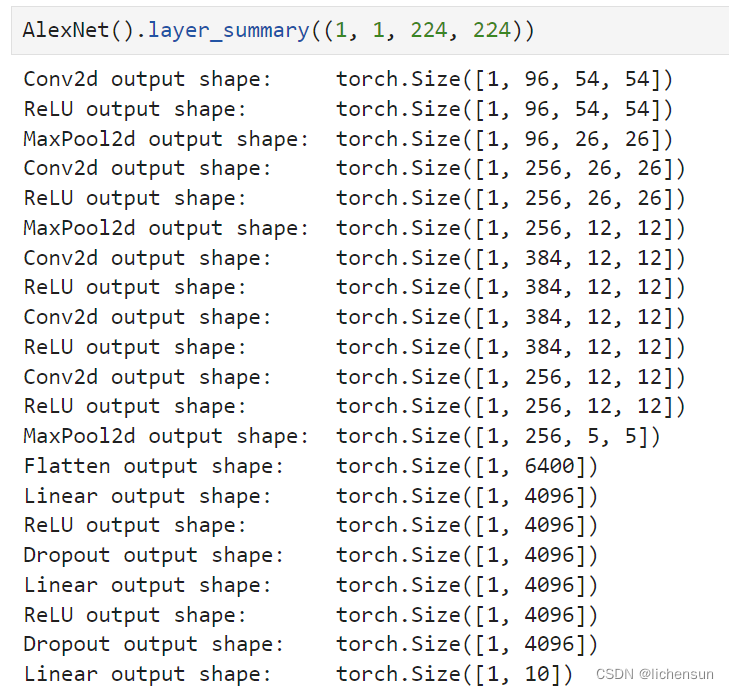
self.net = nn.Sequential(
#第一层卷积:96个输出通道,卷积核大小为11x11,步幅为4,填充为1
nn.LazyConv2d(96, kernel_size=11, stride=4, padding=1),
#ReLU激活函数;
nn.ReLU(),
#最大池化层:池化核大小为3x3,步幅为2
nn.MaxPool2d(kernel_size=3, stride=2),
#第二层卷积:256个输出通道,卷积核大小为5x5,填充为2
nn.LazyConv2d(256, kernel_size=5, padding=2),
#ReLU激活函数
nn.ReLU(),
#最大池化层:池化核大小为3x3,步幅为2
nn.MaxPool2d(kernel_size=3, stride=2),
#第三层卷积:384个输出通道,卷积核大小为3x3,填充为1
nn.LazyConv2d(384, kernel_size=3, padding=1),
#ReLU激活函数
nn.ReLU(),
#第四层卷积:384个输出通道,卷积核大小为3x3,填充为1
nn.LazyConv2d(384, kernel_size=3, padding=1),
#ReLU激活函数
nn.ReLU(),
#第五层卷积:256个输出通道,卷积核大小为3x3,填充为1
nn.LazyConv2d(256, kernel_size=3, padding=1),
#ReLU激活函数
nn.ReLU(),
#最大池化层:池化核大小为3x3,步幅为2
nn.MaxPool2d(kernel_size=3, stride=2),
#将特征图展平为一维向量
nn.Flatten(),
#全连接层:4096个神经元
nn.LazyLinear(4096),
#ReLU激活函数
nn.ReLU(),
#Dropout:丢弃概率为0.5
nn.Dropout(p=0.5),
#全连接层:4096个神经元
nn.LazyLinear(4096),
#ReLU激活函数
nn.ReLU(),
#Dropout:丢弃概率为0.5
nn.Dropout(p=0.5),
#全连接层:输出层,神经元数量为num_classes,即类别数
nn.LazyLinear(num_classes))
#使用了定义的AlexNet模型在FashionMNIST数据集上进行训练。
#首先,创建了一个AlexNet模型对象model,并设置学习率为0.01。
model = AlexNet(lr=0.01)
#创建了一个FashionMNIST数据集对象data,设置批量大小为128,
#并调整图像大小为(224, 224)以适应AlexNet的输入尺寸要求。
data = d2l.FashionMNIST(batch_size=128, resize=(224, 224))
#创建了一个Trainer对象trainer,设置最大迭代次数为10,使用1个GPU进行训练。
trainer = d2l.Trainer(max_epochs=10, num_gpus=1)
#对模型进行训练。
trainer.fit(model, data)
练习:

lec6:Modern convolutional neural networks 现代卷积神经网络
6.1 Networks using blocks (VGG)使用块的网络(VGG)
神经网络设计已经从单个神经元的思维发展到整个层和块(重复层的模式),并重新利用大型的预先训练的基础模型为不同的任务。
块的想法出现在VGG(视觉几何组)网络(2014)。
CNN的基本构件是一个序列:
- 卷积层与填充以保持分辨率,
- 非线性如ReLU,
- 池化层如最大池化以降低分辨率。
问题:空间分辨率迅速下降。
解决方案:在最大池化之间以一个块的形式使用多个卷积。
是深度网络还是宽网络表现得更好?
·比较两个连续的3 x 3卷积和单个5 x 5卷积。
·深度deep和窄层narrow网络的表现明显优于浅层网络。叠加3 x 3卷积已经成为深度网络的金标准。针对小卷积的快速实现是gpu上的主要内容。
6.1.1 VGG network VGG网络
- VGG网络有两个部分:
1. 卷积层和池化层,2。与AlexNet相同的完全连接层。 - 卷积部分连续地连接了几个VGG块。
- VGG块由3 x 3内核的卷积序列和填充padding1(保持高度和宽度),然后是2 x 2的最大池化层,步幅为2(高度和宽度减半)

- 原始VGG网络有5个卷积块(1前2各有1个卷积层,后3个各包含2个卷积层)。
- 第一个块有64个输出通道,每个后续块都加倍输出通道的个数,直到达到512个。它被称为VGG-11,因为它使用了8个卷积层和3个完全连接的层。
- arch是一个元组列表(每个块一个),其中每个元组包含: 卷积层的个数和输出通道的个数。
- 每个块的一半高度和宽度,最后达到7,然后扁平表示,由网络的全连接部分处理。
-
#定义VGG网络中的一个基本块,包含多个卷积层和ReLU激活函数,最后接一个最大池化层 def vgg_block(num_convs, out_channels): # num_convs: no. of conv layers layers = [] # out_channels: no. of output channels for _ in range(num_convs): layers.append(nn.LazyConv2d(out_channels, kernel_size=3, padding=1)) layers.append(nn.ReLU()) layers.append(nn.MaxPool2d(kernel_size=2, stride=2)) return nn.Sequential(*layers) class VGG(d2l.Classifier): # VGG-11 #VGG类继承自d2l.Classifier,并接受一个arch参数来定义VGG网络的结构 def __init__(self, arch, lr=0.1, num_classes=10): super().__init__() self.save_hyperparameters() conv_blks = [] for (num_convs, out_channels) in arch: # iterate over arch to compose blocks conv_blks.append(vgg_block(num_convs, out_channels)) self.net = nn.Sequential(*conv_blks, nn.Flatten(), nn.LazyLinear(4096), nn.ReLU(), nn.Dropout(0.5), nn.LazyLinear(4096), nn.ReLU(), nn.Dropout(0.5), nn.LazyLinear(num_classes)) self.net.apply(d2l.init_cnn) VGG(arch=((1,64), (1,128), (2,256), (2,512), (2,512))).layer_summary((1,1,224,224)) # Sequential output shape: torch.Size([1, 64, 112, 112]) # Sequential output shape: torch.Size([1, 128, 56, 56]) # Sequential output shape: torch.Size([1, 256, 28, 28]) # Sequential output shape: torch.Size([1, 512, 14, 14]) # Sequential output shape: torch.Size([1, 512, 7, 7]) # Flatten output shape: torch.Size([1, 25088]) # Linear output shape: torch.Size([1, 4096]) # ReLU output shape: torch.Size([1, 4096]) # Dropout output shape: torch.Size([1, 4096]) # Linear output shape: torch.Size([1, 4096]) # ReLU output shape: torch.Size([1, 4096]) # Dropout output shape: torch.Size([1, 4096]) # Linear output shape: torch.Size([1, 10]) model = VGG(arch=((1, 16), (1, 32), (2, 64), (2, 128), (2, 128)), lr=0.01) trainer = d2l.Trainer(max_epochs=10, num_gpus=1) data = d2l.FashionMNIST(batch_size=128, resize=(224, 224)) model.apply_init([next(iter(data.get_dataloader(True)))[0]], d2l.init_cnn) trainer.fit(model, data)
-
构建输出通道较少的网络,因为VGG-11在计算上比AlexNet要求更高。
-
验证和训练损失之间的密切匹配表明只有少量的过拟合。
6.2 Network in Network (NiN)
- LeNet、AlexNet和VGG通过卷积序列和池化层来利用空间结构来提取特征。通过全连接的层进行的后处理表示。
- 两个主要挑战:(1)完全连接的层在末端有庞大数量的参数(计算的重大障碍)。(2)不可能在网络中早期添加完全连接的层来增加非线性,因为这将破坏空间结构。
- 网络网络(NiN)块(2013)解决这些使用:
- (1)1 x 1 convolutions1 x 1卷积在通道激活之间添加局部非线性,
- (2)global average pooling全局平均池集成在最后一个表示层的所有位置(没有添加非线性是无效的)。
- 在NiN块中,初始卷积之后是1 x 1的卷积,而VGG使用3 x 3的卷积。
6.2.1 NiN model
NiN使用相同的初始卷积大小(11 x 11、5 x 5、3 x 3)和否。输出通道为AlexNet。每个NiN块后面是3 x 3的最大池化层,步幅为2。
NiN避免了完全连接层,使用NiN块。的输出通道的数目等于标签类的数目,然后是一个全局平均池化层,生成一个logits向量。
这个设计大大减少了模型参数的数量,但可能会增加训练时间。

#Nin model
def nin_block(out_channels, kernel_size, strides, padding):
return nn.Sequential(
nn.LazyConv2d(out_channels, kernel_size, strides, padding), nn.ReLU(),
nn.LazyConv2d(out_channels, kernel_size=1), nn.ReLU(),
nn.LazyConv2d(out_channels, kernel_size=1), nn.ReLU())
class NiN(d2l.Classifier):
def __init__(self, lr=0.1, num_classes=10):
super().__init__()
self.save_hyperparameters()
self.net = nn.Sequential(
nin_block(96, kernel_size=11, strides=4, padding=0), nn.MaxPool2d(3, stride=2),
nin_block(256, kernel_size=5, strides=1, padding=2), nn.MaxPool2d(3, stride=2),
nin_block(384, kernel_size=3, strides=1, padding=1), nn.MaxPool2d(3, stride=2),
nn.Dropout(0.5), nin_block(num_classes, kernel_size=3, strides=1, padding=1),
nn.AdaptiveAvgPool2d((1, 1)), nn.Flatten()) # (1,1): output size
self.net.apply(d2l.init_cnn)
NiN().layer_summary((1, 1, 224, 224))
# Sequential output shape: torch.Size([1, 96, 54, 54])
# MaxPool2d output shape: torch.Size([1, 96, 26, 26])
# Sequential output shape: torch.Size([1, 256, 26, 26])
# MaxPool2d output shape: torch.Size([1, 256, 12, 12])
# Sequential output shape: torch.Size([1, 384, 12, 12])
# MaxPool2d output shape: torch.Size([1, 384, 5, 5])
# Dropout output shape: torch.Size([1, 384, 5, 5])
# Sequential output shape: torch.Size([1, 10, 5, 5])
# AdaptiveAvgPool2d output shape: torch.Size([1, 10, 1, 1])
# Flatten output shape: torch.Size([1, 10])
model = NiN(lr=0.05)
trainer = d2l.Trainer(max_epochs=10, num_gpus=1)
data = d2l.FashionMNIST(batch_size=128, resize=(224, 224))
model.apply_init([next(iter(data.get_dataloader(True)))[0]], d2l.init_cnn)
trainer.fit(model, data)
6.3 GoogLeNet
-
GoogLeNet赢得了ImageNet挑战赛(2014年)。CNN中区分茎stem(数据摄取)、身体body(处理)和头部head(预测)的第一个网络:
茎: 23个卷积,操作在图像和提取低级特征。
主体:卷积块。
标题:针对当前问题的特征(例如分类)。 -
谷歌通过连接多分支卷积multi-branch convolutions来设计网络体。
-
GoogLeNet中的初始块Inception block 由4个并行分支组成,它们使用适当的填充来提供输入和输出相同的高度和宽度。
-
前三个分支使用具有1 x 1,3 x 3,5 x 5窗口的卷积层来从不同的空间大小中提取信息。中间的2个分支添加了1 x 1的输入卷积来减少通道数目和模型的复杂性。

-
第4个分支使用3 x 3的最大池化层,然后是1 x 1的卷积层来更改通道的数目。沿着每个分支的输出沿着通道维度连接起来,以提供块输出。
-
GoogLeNet探索各种过滤器大小variety of filter sizes的图像,使不同程度上的细节能够被有效地识别。
-
它使用9个初始块,排列成3个组,中间有最大池化以降维,并在其头部使用全局平均池化。
-

#GoogLeNet model
class Inception(nn.Module): # c1-c4: no. of output channels for each branch
def __init__(self, c1, c2, c3, c4, **kwargs):
super(Inception, self).__init__(**kwargs)
self.b1_1 = nn.LazyConv2d(c1, kernel_size=1)
self.b2_1 = nn.LazyConv2d(c2[0], kernel_size=1)
self.b2_2 = nn.LazyConv2d(c2[1], kernel_size=3, padding=1)
self.b3_1 = nn.LazyConv2d(c3[0], kernel_size=1)
self.b3_2 = nn.LazyConv2d(c3[1], kernel_size=5, padding=2)
self.b4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.b4_2 = nn.LazyConv2d(c4, kernel_size=1)
def forward(self, x):
b1 = F.relu(self.b1_1(x))
b2 = F.relu(self.b2_2(F.relu(self.b2_1(x))))
b3 = F.relu(self.b3_2(F.relu(self.b3_1(x))))
b4 = F.relu(self.b4_2(self.b4_1(x)))
return torch.cat((b1, b2, b3, b4), dim=1)
class GoogleNet(d2l.Classifier):
def b1(self): return nn.Sequential(
nn.LazyConv2d(64, kernel_size=7, stride=2, padding=3), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
@d2l.add_to_class(GoogleNet)
def b2(self): return nn.Sequential(nn.LazyConv2d(64, kernel_size=1), nn.ReLU(),
nn.LazyConv2d(192, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
@d2l.add_to_class(GoogleNet) # 2 inception blocks
def b3(self): return nn.Sequential(
Inception(64, (96, 128), (16, 32), 32), Inception(128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
@d2l.add_to_class(GoogleNet) # 5 inception blocks
def b4(self): return nn.Sequential(Inception(192, (96, 208), (16, 48), 64),
Inception(160, (112, 224), (24, 64), 64), Inception(128, (128, 256), (24, 64), 64),
Inception(112, (144, 288), (32, 64), 64), Inception(256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
@d2l.add_to_class(GoogleNet) # 2 inception blocks
def b5(self): return nn.Sequential(Inception(256, (160, 320), (32, 128), 128),
Inception(384, (192, 384), (48, 128), 128), nn.AdaptiveAvgPool2d((1,1)), nn.Flatten())
@d2l.add_to_class(GoogleNet) # assembling into full network
def __init__(self, lr=0.1, num_classes=10):
super(GoogleNet, self).__init__()
self.save_hyperparameters()
self.net = nn.Sequential(self.b1(), self.b2(), self.b3(), self.b4(), self.b5(),
nn.LazyLinear(num_classes))
self.net.apply(d2l.init_cnn)- 第5块使用全局平均池化层来改变每个通道的高度和宽度为1(如NiN)。
- 第5块后面是一个完全连接的层,其输出的数目等于标签类的数目。
- 谷歌网计算复杂,有大的没有。任意超参数(在降维之前所选择的频道数和块数,跨通道的容量的相对划分,等)。
- 使用Fashion-MNIST数据集训练谷歌网。为了获得合理的训练时间,将输入的高度和宽度从224减少到96。
-
#train model = GoogleNet().layer_summary((1, 1, 96, 96)) # Sequential output shape: torch.Size([1, 64, 24, 24]) # Sequential output shape: torch.Size([1, 192, 12, 12]) # Sequential output shape: torch.Size([1, 480, 6, 6]) # Sequential output shape: torch.Size([1, 832, 3, 3]) # Sequential output shape: torch.Size([1, 1024]) # Linear output shape: torch.Size([1, 10]) model = GoogleNet(lr=0.01) trainer = d2l.Trainer(max_epochs=10, num_gpus=1) data = d2l.FashionMNIST(batch_size=128, resize=(96, 96)) model.apply_init([next(iter(data.get_dataloader(True)))[0]], d2l.init_cnn) trainer.fit(model, data)
谷歌网的关键特点:比以前的计算更便宜,同时提供更高的精度。标志着网络设计的开始,
·权衡评估网络的成本,
·在块水平上实验网络设计超参数。
6.4 Batch normalization 批量规范化
- 在训练之前,我们将输入特征标准化为平均单位方差为零,因为它将参数放在相似的尺度上。标准化对深度网络有用吗?
- 当我们训练MLP/CNN时,中间层的变量可能取变化很大的值。这可能会阻碍收敛性,并需要调整学习速率。自适应标准化可以防止问题的发生。
- 批处理归一化加速收敛,并提供数值稳定性和正则化,这是至关重要的,因为深度网络往往过拟合。
- 在每次迭代中,批处理归一化(BN)都被应用于单个层或所有层。设B是一个小批处理,x∈B是BN的输入。设ˆµB为样本均值,ˆσB为B的样本标准差。
 将小的常数>0添加到方差估计中,确保我们永远不会除以0。经过标准化后,小批量的均值和单位方差为零(这种选择是任意的)。通过包括刻度参数γ和移位参数β(与x的形状相同)来恢复自由度。
将小的常数>0添加到方差估计中,确保我们永远不会除以0。经过标准化后,小批量的均值和单位方差为零(这种选择是任意的)。通过包括刻度参数γ和移位参数β(与x的形状相同)来恢复自由度。
- 中间层的可变大小在训练过程中不能作为批处理标准化中心而发散,并将它们重新调整到给定的平均值和大小。批处理标准化允许更激进的学习率。
- 批量大小很重要。对大小为1的小批量应用批量归一化是无用的,因为减去平均值后,每个隐藏单位为0。
- 通过足够大的小批次(50∼100)和适当的校准,批归一化是有效和稳定的。更大的小批量,由于更稳定的估计,正则化更少。由于高差异,小批量会破坏有用的信号。
- 在训练过程中,使用整个数据集来估计均值和方差是不可行的,因为每次我们更新模型时,所有数据示例的中间变量都会发生变化。
对完全连接的图层的批量规范化
设全连通层的输入为x,仿射变换为Wx + b,激活函数为φ。一个批标准化的、完全连接的层输出h是:

- 在所有位置的卷积后和非通道非线性激活函数之前应用批归一化。假设小批有m个例子,每个通道的卷积输出有高度p和宽度q。通过每个输出通道对mpq元素进行批处理归一化。
- 在计算平均值和方差时,收集所有空间位置的值,并在给定的通道内应用相同的平均值和方差,对每个位置的值进行归一化。每个通道都有自己的比例和移位参数(标量)。
- 在卷积中,为大小为1的小批定义了批归一化,因为我们可以对图像的所有位置进行平均。这导致了层标准化,它的工作原理像批处理范数,但一次应用于一个观察。偏移量和比例因子都是标量。给定n-dim向量x,层范数为

- 层的规范化不依赖于小批量的大小,并避免了分歧。忽略,输出是与比例无关的(LN (x) = LN(αx)∀ α = 0)。
6.4.1 LeNet with batch normalization
将批处理规范化应用于LeNet模型。批处理归一化是在卷积或完全连接层之后,但在激活函数之前。
class BNLeNet(d2l.Classifier):
def __init__(self, lr=0.1, num_classes=10):
super().__init__()
self.save_hyperparameters()
self.net = nn.Sequential(nn.LazyConv2d(6, kernel_size=5), nn.LazyBatchNorm2d(),
nn.Sigmoid(), nn.AvgPool2d(kernel_size=2, stride=2),
nn.LazyConv2d(16, kernel_size=5), nn.LazyBatchNorm2d(),
nn.Sigmoid(), nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(), nn.LazyLinear(120), nn.LazyBatchNorm1d(),
nn.Sigmoid(), nn.LazyLinear(84), nn.LazyBatchNorm1d(),
nn.Sigmoid(), nn.LazyLinear(num_classes))在批归一化层中,尺度参数γ和shift参数β分别初始化为1和0。在训练过程中,该层以默认动量为0.1运行其计算均值和方差的估计,用于预测过程中的归一化。

- 训练网络在Fashion-MNIST数据集:
-
trainer = d2l.Trainer(max_epochs=10, num_gpus=1) data = d2l.FashionMNIST(batch_size=128) model = BNLeNet(lr=0.1) model.apply_init([next(iter(data.get_dataloader(True)))[0]],d2l.init_cnn) trainer.fit(model, data)
- 看看尺度参数γ,shift参数β,以及从第一批归一化层学习到的运行均值和方差:
-
model.net[1].bias # shift parameter beta # tensor([1.5203, -0.1707, 0.9045, -1.1624, 1.0029, -0.3085], device=‘cuda:0’, # requires_grad=True) model.net[1].weight # scale parameter gamma # tensor([2.0083, 1.8154, 1.4390, 1.8135, 1.9345, 1.7748], device=‘cuda:0’, # requires_grad=True) model.net[1].running_mean # tensor([ 0.1830, 0.1567, 0.2786, -0.1408, -0.0457, 0.0038], device=‘cuda:0’) model.net[1].running_var # tensor([0.1589, 0.1743, 0.1072, 0.0825, 0.1516, 0.1423], device=‘cuda:0’)6.5 Residual networks (ResNet)
- 为了设计更深层次的网络,我们需要了解添加层如何增加网络的表达性。设F是一个网络架构可以达到的函数类。给定一个具有特征X和标签y的数据集,

如果我们设计一个更强大的体系结构f0,我们可能会发现f∗f0比f∗f“更好”,但这只有在f⊆f0时才会得到保证。
- 如果我们能将一个新添加的层训练成一个恒等函数f (x) = x,那么新的模型将与原始模型一样有效。由于新模型可以更好地拟合训练集,增加一层可以减少训练误差。
- 剩余网络(ResNet)的概念:每一个额外的层都应该包含标识功能作为其元素之一。这就导致了剩余的方块。
- ResNet赢得了ImageNet挑战赛(2015年)。它的设计对深度神经网络的构建有着深远的影响。
6.5.1 Residual blocks

-
设输入为x。假设需要学习的映射是f(x)(用作顶部激活函数的输入)。
-
左图:虚线框必须直接学习f (x)。
-
右:虚线框学习剩余映射,g (x) = f (x)−x。
-
如果需要恒等映射f (x) = x,残差映射为g (x) = 0,这更容易学习(将上权值权重和偏差推至零)。
-
右图:ResNet的残余块。实线承载层输入x到加法运算符是一个剩余的连接。有了剩余块,输入可以通过跨层的剩余连接更快地向前传播。
-
残差块是多分支初始块的特殊情况:它有两个分支,其中一个是身份映射。
-
ResNet遵循了VGG的3 x 3卷积层设计。残差块有两个3 x 3的卷积层,想通数目的输出通道。

- 每个卷积层之后都是一个批处理归一化层和ReLU激活函数。然后,我们跳过这两个卷积操作,并在最终的ReLU激活之前直接添加输入。
- 这种设计要求两个卷积层的输出与输入具有相同的形状,因此可以添加它们。要改变没有。在通道中,引入1×1卷积层将输入转换为所需的形状以便添加。
-
blk = d2l.Residual(3) # 3: num_channels, strides = 1 (default) X = torch.randn(4, 3, 6, 6) # input and output of same shape, 11 conv is not needed blk(X).shape # torch.Size([4, 3, 6, 6]) blk = d2l.Residual(6, use_1x1conv=True, strides=2) # halve output height and width blk(X).shape # increase no. of output channels # torch.Size([4, 6, 3, 3]) # use 11 conv6.5.2 ResNet model

- ResNet的前两层与GoogLeNet相同: 7 x 7卷积层,64个输出通道和步幅2,然后是3 x 3最大步幅层2。差异是在ResNet中的每个卷积层之后添加批处理归一化层。
-
class ResNet(d2l.Classifier): def b1(self): return nn.Sequential(nn.LazyConv2d(64, kernel_size=7, stride=2, padding=3), nn.LazyBatchNorm2d(), nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2, padding=1))ResNet-18使用4个模块,每个模块有2个剩余块。在第一个模块中,输出通道的大小等于输入。所以不需要1 x 1的卷积层。对于接下来的3个模块的第1个残差块,与之前的模块相比,输出通道数目增加了两倍(需要1x1个卷积层),高度和宽度减半。
-
@d2l.add_to_class(ResNet) # a module def block(self, num_residuals, num_channels, first_block=False): blk = [] for i in range(num_residuals): if i == 0 and not first_block: blk.append(Residual(num_channels, use_1x1conv=True, strides=2)) else: blk.append(Residual(num_channels)) return nn.Sequential(*blk) @d2l.add_to_class(ResNet) # Add all modules, global avg pooling layer and fc output layer def __init__(self, arch, lr=0.1, num_classes=10): super(ResNet, self).__init__() self.save_hyperparameters() self.net = nn.Sequential(self.b1()) for i, b in enumerate(arch): self.net.add_module(f‘b{i+2}’, self.block(*b, first_block=(i==0))) self.net.add_module(‘last’, nn.Sequential(nn.AdaptiveAvgPool2d((1, 1)), nn.Flatten(),nn.LazyLinear(num_classes))) self.net.apply(d2l.init_cnn) class ResNet18(ResNet): # specify arch def __init__(self, lr=0.1, num_classes=10): super().__init__(((2, 64), (2, 128), (2, 256), (2, 512)), lr, num_classes)每个模块有4个卷积层(不包括1个×,1个卷积层)。结合前7个×7的卷积层和最终的全连接层,共计18个层(因此是ResNet-18)。
-
ResNet18().layer_summary((1, 1, 96, 96)) # floor((96-7+6+2)/2)=48 # Sequential output shape: torch.Size([1, 64, 24, 24]) # floor((48-3+2+2)/2)=24 # Sequential output shape: torch.Size([1, 64, 24, 24]) # Sequential output shape: torch.Size([1, 128, 12, 12]) # Sequential output shape: torch.Size([1, 256, 6, 6]) # Sequential output shape: torch.Size([1, 512, 3, 3]) # Sequential output shape: torch.Size([1, 10])观察输入形状在不同模块之间的变化。与以前的架构一样,随着通道数目的上升分辨率降低。直到一个全局平均池化层聚合了所有的特征。
-
通过使用模块中的不同数目的通道和剩余块,我们可以创建不同的ResNet模型。ResNet的架构类似于谷歌的leNet,但它更简单,更容易修改,导致了它的广泛使用。
-
在Fashoin-MNIST数据集上训练ResNet。
-
model = ResNet18(lr=0.01) trainer = d2l.Trainer(max_epochs=10, num_gpus=1) data = d2l.FashionMNIST(batch_size=128, resize=(96, 96)) model.apply_init([next(iter(data.get_dataloader(True)))[0]], d2l.init_cnn) trainer.fit(model, data)
- ResNet是一个功能强大且灵活的体系结构。情节捕获的训练损失远低于验证损失。对于网络来说,这种灵活的、更多的训练数据将有助于缩小差距和提高准确性。
- 许多现代计算机视觉网络设计中的架构在很大程度上是基于人类的创造力和在较小程度上对设计空间深度网络所提供的系统探索。
- 由于AlexNet在ImageNet上击败了传统的计算机视觉模型,通过叠加相同模式的卷积块来构建深度网络变得很流行。3 x 3卷积是由VGG网络普及的。
- NiN表明,通过添加局部非线性,并通过跨位置聚合来组合网络头部的信息。
- GoogLeNet添加了多个不同卷积宽度的分支,结合了VGG和NiN的优势。
- ResNets改变了对身份映射的归纳偏差(从f (x) = 0)。这允许了非常深的网络。















 200
200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











