







- Abekawa T, Abekawa T. Framework of automatic text summarization using reinforcement learning[C]// Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. Association for Computational Linguistics, 2012:256-265.
Abstract
- reinforcement learning can be adapted to automatic
summarization problems naturally and simply, and other summarizing techniques, such as sentence compression, can be easily adapted as actions of the framework.
强化学习这个框架可以很好得适用自动摘要,句子压缩等领域。
实验证明了,强化学习可以找到一个很好的次优解,性能优于ILP方法,可以在相关条件下选择特征和分数计算函数
Relatedwork
- One of the most well-known extractive approaches
is maximal marginal relevance (MMR),
>>最大边缘相关总结 - Greedy MMR-style algorithms are widely used; however, they cannot take into account the whole quality of the summary due to their greediness
贪心MMR没有考虑整个摘要的质量 - Global inference algorithms for the extractive
approach have been researched widely in recent
years
全局推理算法得到了广泛的研究,这些算法把问题归于ILP问题(NP-hard)来优化分数 - Define the problem as:
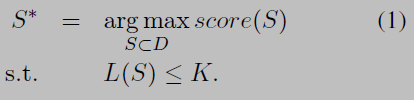
Motivation
- We can regard the extractive approach as a search
problem.
抽取式摘要可看做是一个搜索问题,该问题很难,因为在抽取未完成的时,分数函数是不可用的,这就需要我们遍历所有的组合,此时就需要全局推理算法
本文中不需要考虑分数函数的分解形式
Models of Extractive Approach for Reinforcement Learning
Reinforcement Learning
- Reinforcement learning is a powerful method of solving planning problems, especially problems formulated as Markov decision processes (MDPs)
强化学习是解决规划问题的强有力的手段,比如马尔科夫决策过程
State
- A state denotes a summary
定义state变量 s = (S, A, f)
A: the history of actions A that the agent executed to achieve this state
历史路径,到达此状态S经过的之前的历史状态
f ∈ {0, 1} :enotes whether s is a terminal state or not 标记是否是中止状态
初始化: s0 = (∅, ∅, 0). - 状态s的d维特征表示:
超过长度限制的摘要被限制为单个特征,表示这不是一个摘要。注意state的feature取决于摘要的特征,而不是执行action到达这个state。
特征表示的生成函数极为重要,可以减少搜索空间,并使学习变得高效
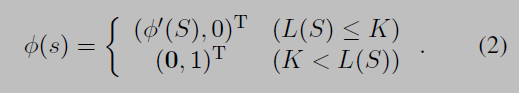
Action
insert_i 插入x_i 文本单元
finish 结束操作
A = {insert1, insert2, · · · , insertn, finish}.
Reward
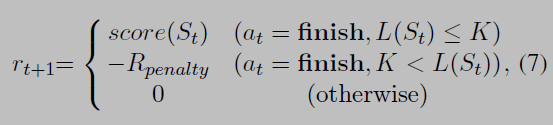
The most important point of this definition is that the agent receives nothing under the condition where the next state is not terminated.
只有在下一个状态是结束的时候,agent才能获得奖励,这使得我们只需要考虑最后摘要的分数
Value Function Approximation
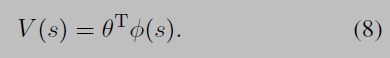
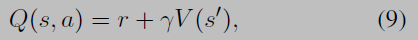
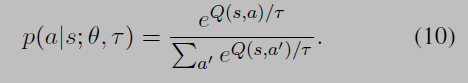
Temperature τ decreases as learning progresses, which causes the policy to be greedier. This softmax selection strategy is called Boltzmann selection.
Learning Algorithm
The goal of learning is to estimate θ.
We use the TD (λ) algorithm with function approximation

Models of Combined Approach for Reinforcement Learning
Even other summarization systems can be similarly adapted to ASRL.















 730
730











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









