







 本文探讨了文件的逻辑结构,包括无结构文件、有结构文件、顺序文件等类型,并深入讨论了索引文件及其优化方法——多级索引表。
本文探讨了文件的逻辑结构,包括无结构文件、有结构文件、顺序文件等类型,并深入讨论了索引文件及其优化方法——多级索引表。
文件的逻辑结构

类比数据结构中的逻辑结构和物理结构
无结构文件
因为文件内部的数据其实就是一系列字符流,没有明显的结构特性。因此也不需要探讨无结构文件的逻辑结构问题;
有结构文件
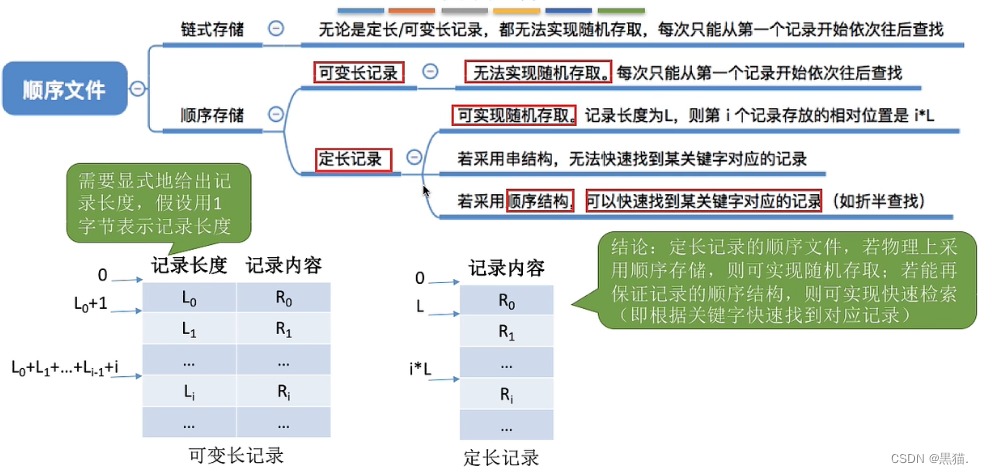
又叫做“记录式文件”,记录可分为定长记录和可变长记录,
定长记录

可变长记录
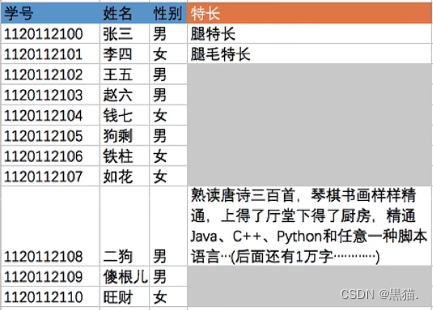
如下表,有的记录很少几乎没有,但是有的记录非常长;

顺序文件
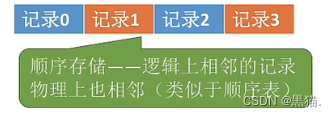
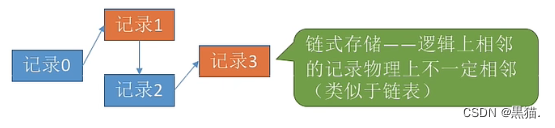
文件中的记录一个接一个的顺序排列(逻辑上),记录是定长的或可变长的。各个记录在物理上可以顺序存储或链式存储。

根据记录是否按照关键字的顺序来排列,还可以分为串结构和顺序结构;

链式存储类似链表,无法实现随机存取,每次检索时都要从第一个文件一次向后查找
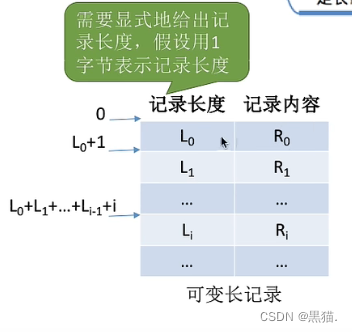
如果是可变长文件,如图l0,l1,l2…并不会呈现出某种规律性,因此也只能从第一个文件一次向后查找
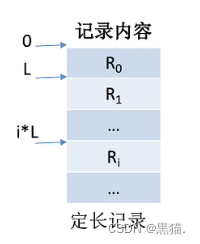
可以实现随机存取
串结构,这些记录的顺序和关键字的顺序没有什么关系,因为他并不是按照关键字的顺序来排列的,所以只能采用逐个遍历的方式缓慢查找;
顺序结构,这些记录的顺序和关键字的顺序存在一定的关系,此时说明这些文件是按照某种关键字的顺序来排列的,此时可以通过诸如二分法,哈希表等方式来快速的查找某一个关键字对应的记录
通常,考试当中提到的顺序文件都是指“采用顺序存储方式的顺序文件”;

索引文件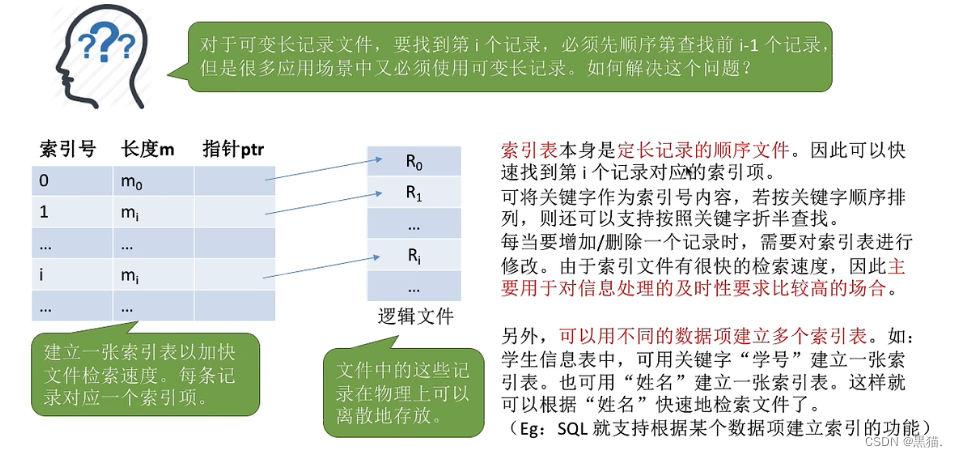
为文件建立索引表,将关键字作为索引号内容(如果关键字按照某种顺序排列,还可以实现支持按照关键字索引的折半查找);
同时索引表本身是顺序表,具有非常快的检索速度(如果关键字排列还能更快);
同时每当对一个记录的删除或增加时都要对索引表进行更新;
每一个文件的记录对应一个索引表项;
**除了用关键字作为索引号来建立索引表,也可以用别的不同的数据项作为索引号来建立索引表(可以建立多个索引表)
索引顺序文件
索引顺序文件的索引项并不需要按照关键字的顺序来进行排列,因此更方便对新表项的插入操作;
索引顺序文件的索引表就是一个定长记录的串结构的顺序文件
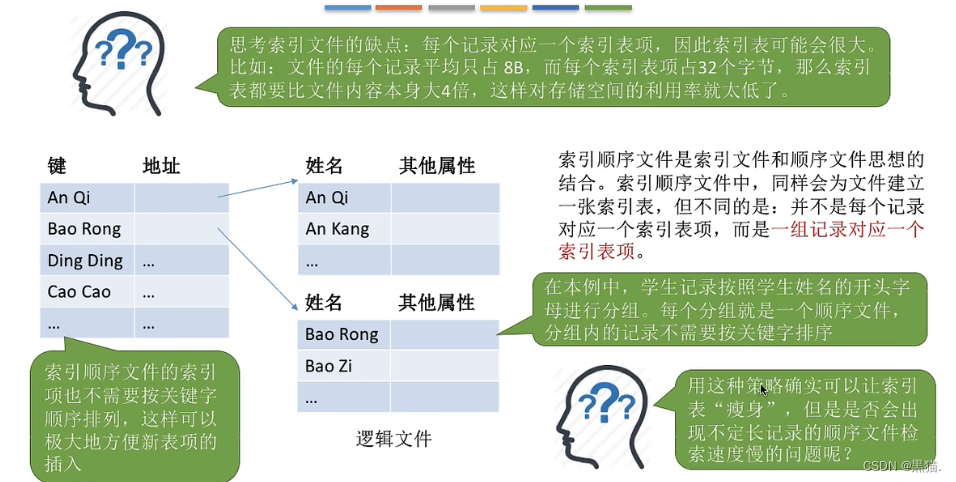
这样设计的结构会不会造成检索速度慢的问题呢?

rt,

但是假设当有1e6(100w个)个记录的时候,假设可以将这10w个记录分成 根号 100w=1000组,每组1000个记录,则需要先顺序查找索引表找到分组(平均需要500次),找到分组后再在对应的分组中查找这个记录,(平均也需要500次),加起来就是1000次,仍然很多;
此时可以采用多级索引表的结构

先建立一个低级索引表,每个索引表对应100个表项(就是低级索引表中的一行),每个表项又对应一个分组,每个分组当中又是100个记录,则会有100张低级索引表;因此我们再为这100张低级索引表建立一张顶级的索引表, 这样就形成了两级索引顺;
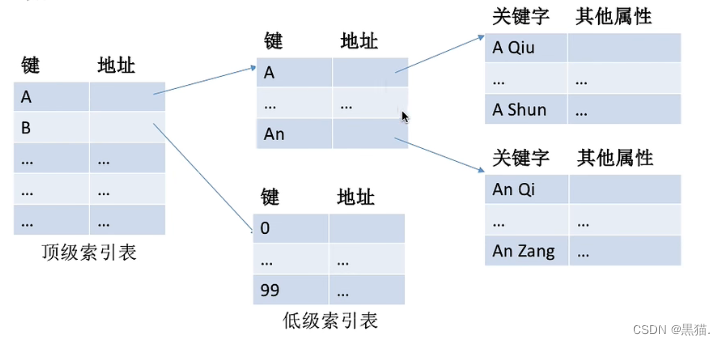
那么在多级索引表中查找一个记录需要多少次呢?
首先在顶级索引表中查询属于那个低级索引表,需要(1+…+100)/100=50次,找到所属的低级索引表之后,需要在低级索引表中查找对应的记录所属的分组,需要50次,找到分组之后,需要在分组中查找对应的记录,平均需要50次,因此总共需要50+50+50=150次相对于100w次,检索速度提高了非常之多;同时也满足了不会十分占用内存的需求;




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











